Data Warehousing, OLAP, and Data Mining: An Integrated Strategy for Use at FAA
by Yao Ma
Submitted to the Department of Electrical Engineering and Computer Science in Partial Fulfillment of the Requirements for the Degrees of
Bachelor of Science in Electrical Engineering
and Master of Engineering in Electrical Engineering and Computer Science at Massachusetts Institute of Technology
May 28, 1998
Copyright 1998 Massachusetts Institute of Technology. All rights reserved.
Author
4 5epartment of Electrical Engineering and Computer Science
May 28, 1998 Certified by
U 1 Amar Gupta
Co-Director, P ity from Inform ion Technology Initiative - T
/ Thesi§ Supervisor Accepted by
Arthur C. Smith Chairman, Department Committee on Graduate Thesis
MASSACHUSETTS INSTTi
OF TEC.NO' "4
JUL 1 4198
LIBRARIES
Data Warehousing, OLAP, and Data Mining: An Integrated Strategy for Use at FAA
by Yao Ma Submitted to the
Department of Electrical Engineering and Computer Science May 28, 1998
In Partial Fulfillment of the Requirements for the Degrees of Bachelor of Science in Electrical Engineering
and Master of Engineering in Electrical Engineering and Computer Science at Massachusetts Institute of Technology
ABSTRACT
The emerging technologies of data warehousing, OLAP, and data mining have changed the way that organizations utilize their data. Data warehousing, OLAP, and data mining have created a new framework for organizing corporate data, delivering it to business end users, and providing algorithms for more powerful data analysis. These information technologies are defined and described, and approaches for integrating them are discussed. An integrated approach for these technologies are evaluated for a specific project, the Data Library initiative at Federal Aviation Administration's (FAA) Office of Aviation Flight Standards (AFS). The focus of this project is to evaluate an original Project Implementation Plan (PIP) and Capacity Planning Document (CPD) that have been drafted by the FAA, and provide a revised overall strategy for resolving FAA data issues based on the capabilities of new technologies. The review and analysis recommends changes to the PIP and the application of emerging technologies to data analysis. Furthermore, the creation of a Knowledge Repository, containing both Data Warehouse and Data Mining components, are recommended for the FAA.
Thesis Supervisor: Amar Gupta
Title: Co-Director, Productivity from Information Technology Initiative, MIT Sloan School of Management
Table of Contents
Chapter 1. Historical Perspective ...
1.1. Background ...
1.2. Emerging Data Needs...
Chapter 2. Data Warehousing
...
2.1. Introduction ...
2.2. "Active" Information Management ...
2.3. Characteristics ... 2.3.1. Subject Oriented ... 2.3.2. Integrated ... 2.3.3. Non-Volatile ...
2.3.4. Time-Invariant...
2.4. Support Management Needs ...
2.4.1. Operational Data Store ... 2.4.2. Data Warehouse for Mangers ...
2.5. Advantages of Data Warehousing Approach.. 2.6. Disadvantages of Data Warehousing ...
2.7. Steps to a Data Warehouse....
2.7.1. Design Phase ...
2.7.2. Implementation Phase...
2.8. Data M arts ...
Chapter 3. OLAP
...
3.1. Introduction ...
3.2. Multidimensional Data Model.
3.3. Twelve OLAP Rules...3.3.1. Multidimensional Conceptual View 3.3.2. Transparency... 3.3.3. Accessibility ...
3.3.4. Consistent Reporting Performance.
3.3.5. Client-Server Architecture ...
3.3.6. Generic Dimensionality ... 3.3.7. Dynamic Sparse Matrix Handling . 3.3.8. Multi-User Support ...
3.3.9. Unrestricted Cross-Dimensional Opi 3.3.10. Intuitive Data Manipulation ... 3.3.11. Flexible Reporting ... ... 0o0
... 25
... ... ...
...
25
... 26 ... ... ... ... ... .. 28 ... 29 .. .. ... .... .. ... .... .. .. .. ... .. ... .. 30 .. .. ... .... ... .. .... .. .. ... .. ... .. .. 30 ...3 1 .. ... .. .. .. ... .. ... ... .. .. .... .. .. ..3 1 ...3 1 .. .. .. .. .... .. .. .... .. .... ... .... ...32 .. .. ... ... .. .. .... .. .. .... .. .. .. ..32 erations ... 32 ...3 3 .. .. .. .. ... .. ... ... .. ... ... .. .. ...3 3 3.3.12. Unlimited Dimensions and Aggregation Levels. ... 9
.. 9.11
.13
.13
.13
.15
.15 .16 .16 .17.17
.17 .18.19
.20
.21
.21 .22.23
.... 0..0.0.00*e000...
...
...
... 333.4. Interface for Data Warehouse..
3.5. MOLAP vs. OLAP...
Chapter 4. Data Mining ...
4.1. Introduction ...
4.2. Data M ining Tasks ...4.2.1. A ssociation ... 4.2.2. Classification ... 4.2.3. Sequential Patterns ...
4.2.4. Clustering ...
4.3. Techniques and Algorithms ...
4.3.1. Neural Networks ... 4.3.2. Decision Trees ... 4.3.3. Nearest Neighbor .... ... 4.3.4. Genetic Algorithms ...
4.4. Interaction with Data Warehousing and OLAP ...
4.4.1. Knowledge Repository ...
... 37
... 37
... 38
... 39 ... 39 ... 40 ... 4 1... 42
... 42 ... 44 ... 44 ... 45...
45
... 46Chapter 5. FAA
5.1. Introduction
5.2. Data Library
5.3. Existing Syst
Project Background ...
Initiative ...
.em s ...Chapter 6. Review of Capacity
6.1. CPD Description ...
6.2. Planning Process ...
6.3. Analysis...
Planning Document.
...
48
...
48
...
48
...
50
...
52
...
52
...
52
...
53
Chapter 7. Review of 1
7.1. PIP Description ..
7.2. Proposed PIP Chan
7.3. Acceptance Lab ..
7.4.7.5.
7.6.
Proof of Concept O
Proof of Concept D
PIP Analysis...
roject Implementation Plan
.. ges...ges ...
perational Data Store ...
ata Mining Application...
Chapter 8. Overall Strategy ...
8.1. Introduction ...
8.2. Emerging Technologies ...
8.3. A nalysis ...
8.4. Recommendations ...
.56
.56
.58
.59
.60
.60
.60
.62
.62
.62
.63
...
64
.34
.35
... ... oooooo ooo .0 0 00 . . 0* . . . . . . . . . .8.5.
Steps...66
8.5.1. Choose Applications ... 67
8.5.2. Establish Team ... 68
8.5.3. Establish Requirements ... 69
8.5.4. Implementation ... 70
8.6. Prototype Data Warehouse ...
71
8.7. Prototype Emerging Data Analysis Technologies ...
72
Chapter 9. Conclusion ... 74
List of Figures
2.1. The model of a data warehouse...14
2.2. The process of building a data warehouse...
22
2.3. Data marts are specialized data warehouses. ...
23
3.1. Multidimensional cube representing data in Table 1. ...
27
3.2. Using a ROLAP engine vs. creating an intermediate MDDB server.. .36
List of Tables
2.1. Standard Database vs. Warehouse ...
19
3.1. Data in a Relational Table ...
27
Acknowledgments
This work was conducted as a part of the Productivity from Information Technol-ogy (PROFIT) Initiative at the MIT Sloan School of Management. The author would like to acknowledge Dr. Amar Gupta, Co-Director of PROFIT, for his support and guidance in this project. The project would not have been possible without the cooperation of Ms. Arezou Johnson at the Federation Aviation Administration (FAA). Furthermore, the author would like to acknowledge the other members of the research team who contrib-uted to the strategy plan developed for the FAA. In particular, the comments and insights of Auroop Ganguly, Neil Bhandar, Angela Ge, and Ashish Agrawal benefited the strategy. The author also wishes to thank his friends for their support and assistance along the way. In particular, Connie Chieng deserves credit for her understanding and support during times of crisis and for allowing the use of her computer. Finally, the author thanks his family for the numerous years of support, without which none of this would not have been possible.
Chapter 1. Historical Perspective
1.1. Background
Corporate business computer systems have evolved through the decades from mainframes in the 1960s, mini-computers in the 1970s, PCs in the 1980s to client/server platforms in the 1990s. Despite these changes in platforms, architectures, tools and tech-nologies, a remarkable fact remains that most business applications continue to run in the mainframe environment of the 1970s. According to some estimates, more than 70 percent of business data for large corporations still reside in the mainframe environment. (Gupta 1997) One important reason is that over the years, these systems have grown to capture corporate knowledge that is extremely difficult and costly to transition over to new plat-forms or applications.
Historically, the primary emphasis of database systems development was for pro-cessing operational data. Operational data are data that are collected and that support the day-to-day operations of a business. For example, this can include a record providing data of individual accounts or a record about an existing sales order. These data represent, to administrators and salespeople, a view of the world as it exists today. Furthermore, on the back end, the data are processed and collected as transactions happen in real-time. This means that each transaction that occurs, such as a credit or debit of an account, is captured into a record in a database. All of these raw data are processed and stored by an On-Line Transaction Processing (OLTP) system that gathers the detailed data from day-to-day operations. The operational data are good for providing information to run the business on
a day-to-day level, but does not provide a systematic way to conduct historical or trend analysis to determine business strategies.
A historical trend in corporate computing is a shift in the use of technology by a more mainstream group. Up until the mid-1970s, because of the complexity of computer hardware and software, there were few business end-users. (Devlin 1997) Most managers and decision makers in organizations had little exposure to technology and could not access the stored data for themselves. One of main reasons was that database management systems (DBMS) were developed without a uniform conceptual framework and, thus, were needlessly complex. Typically business users relied on data processing experts to provide business data on reams of paper.
In the early 1970s, E.F. Codd defined a Relational Model of databases to address the shortcomings of existing database systems so that more users could directly access data through DBMS products. (Devlin 1997) This abstract model based on mathematical principal and predicate logic created a blueprint for future developers to systematically create DBMS products. The Relational Model is the most important concept in the history of database technology because it provided a structured model for databases. The result is that this concept has been applied as a powerful solution to almost all database applica-tions used today. Relational databases are at the heart of applicaapplica-tions requiring storing, updating and retrieving data, and relational systems are used for operational and transac-tion processing. For the end user, the Relatransac-tional Model allowed for simpler interfaces with the data by allowing for queries and reporting. By the mid-1980s, with the emer-gence of the PC and popular end-user applications, such as the spreadsheet, business users increasingly interacted with technology and data for themselves. (Gupta 1997)
1.2. Emerging Data Needs
The collection of data inside corporations has grown consistently and rapidly dur-ing past couple of decades. Durdur-ing the 1980's, businesses and governments worked with data in the megabytes and gigabyte range. (Codd 1993) In the 1990's, enterprises are hav-ing to manipulate data in the range of terabytes and petabytes. With this dramatic increase in the collection of data, the need for more sophisticated analysis and faster synthesis of better quality information has also grown. Furthermore, in today's dynamic and competi-tive business environment, there is much more of an emphasis on enterprise-wide use of information to formulate decisions. The increase in the number of individuals within an enterprise who need to perform more sophisticated analysis has challenged the traditional methods of collecting and using data.
Along with the increase in data collected, organizations also increased the number and types of systems that they used. Increasingly, individual departments in organizations implemented their own systems to supported their database needs. For example, inside an organization, separate systems are created to support the sales department, accounting department, and personnel department. Each department has separate applications and collects different types of data, thus, they relied upon their own independent mainframes or databases systems. Often these database technologies were purchased from different commercial vendors and utilized different data models. In this type of an environment, the proliferation of heterogeneous data formats inside an organization made it increasingly difficult for managers to analyze information from across the organization. (Hammer et. al. 1995) Furthermore, it may not even be possible for an executive to communicate with
each of these distributed or autonomous systems. Thus with the trend towards more of a need for business end users to access information from across the corporation for decision making, a new framework for organizing corporate information was needed. This new framework needed to facilitate decision support for the business analyst who is trying to analyze information from across many departments inside the organization.
Chapter 2. Data Warehousing
2.1. Introduction
In the early 1990s, William Inmon introduced a concept called a data warehouse to address many of the decision support needs of managers. (Pine Cone 1997) A data ware-house is a central repository of information that is constructed for efficient querying and analysis. A data warehouse contains diverse data collected from across an enterprise and is integrated into a consistent format. The data comes from various places inside an orga-nization, including distributed, autonomous, and heterogeneous data sources. Typically, the data sources are operational databases from existing enterprise-wide legacy systems. Information is extracted from these sources, translated into a common model and added to existing data in the data warehouse. The main advantage of a data warehouse approach is that queries can be answered and analyses can be performed in a much faster and more efficient manner since the information is directly available, with model and semantic dif-ferences already removed. With the data warehouse, query execution does not need to involve data translation and communications with multiple remote sources, thus speeding up the process analysis process. (Widom 1995)
2.2. "Active" Information Management
The key idea behind a data warehouse approach is to collect information in advance of queries. (Hammer et. al. 1995) The traditional approach to accessing informa-tion from multiple, distributed, heterogeneous databases is a "passive" approach. An
example of this "passive" approach is when a user performs a query, the system deter-mines the appropriate data sources and generates the appropriate commands for each of those sources. After the results are obtained from the various sources, the information needs to be translated, filtered and merged before a final answer can be provided to the user. A data warehousing approach is to extract, filter, and integrate the relevant data before a user needs to perform analyses on that information. In this "active" approach,
when a query arrives, there is no
Clients Clients
Data Warehouse
Flat
Files Sybase
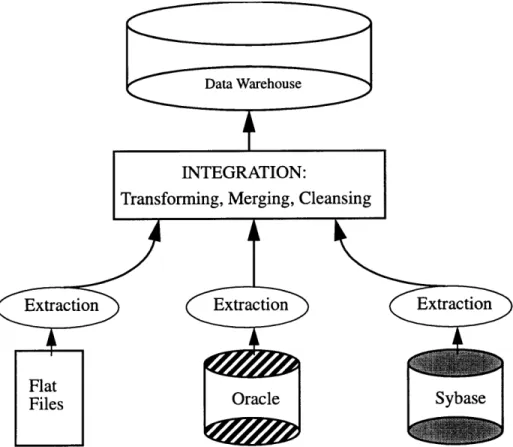
Figure 2.1. The model of a data warehouse. Heterogeneous data is integrated into the data warehouse. Cli-ents or business end users interact with the data warehouse for analysis instead of the various data sources.
need to translate the query and send it to the original data sources for execution since the information has already been collected into one location using a common data model. In the "passive" approach with multiple, distributed, heterogeneous data sources, the transla-tion process and communicatransla-tion with many remote sources can be a very complex and
time-consuming operation. In particular, the "active" or data warehousing approach can provide tremendous benefits for users who require specific, predictable portions of the
available data and to users who require high query performance. (Hammer et. al. 1995)
2.3. Characteristics
Inmon defined a data warehouse as "a subject-oriented, integrated, non-volatile, time-variant collection of data organized to support management needs." (Inmon 1995) Each of those ideas play an integral role in the concept of how a data warehouse can be "active" in supporting management's data needs and are discussed in further detail. Where appropriate, the data warehouse is contrasted with an operational database in terms of how they meet the needs of an end user. As the definition and characteristics are further elaborated upon, one can see that data warehousing is really more of a process than a spe-cific type of database product. Data warehousing is a technique for properly assembling and managing data from various sources for the purpose of answering business questions and making decisions that were not previously possible. (Page 1996)
2.3.1. Subject Oriented
Subject oriented data management means that all data related to a subject are extracted from wherever they resides in the organization and brought together into the data warehouse. A subjected-oriented data structure is independent of the processes that cre-ated and use the data on an operational basis, but rather transforms the data structure to maximize its usefulness to the a business analyst. (Inmon 1995) There can be many dif-ferent ways to classify the high level entities in a business and many subjects to orient the data by, so this process requires knowledge of what types of analysis are important to the
end users who conduct the analysis. As an example, an operational database for a bank might functionally stored data in categories such as loans, savings, credit cards, and trusts, but a business analyst will want to see information related to customers, vendors, products and activity. This transformation of data structure from functional orientation to subject orientation leads to much more useful categorizations for analysis for a business decision maker.
2.3.2. Integrated
An integrated approach ensures that the data are stored in a common data model that represents the business view of the data. (Inmon 1995) Operational data are stored in various sources throughout an organization and can have different data models. The goal of the data warehouse is to resolve these issues so that when an end user performs a query, there is no need to deal with multiple data models. This also generally means that the data in a warehouse will have an entirely different model as compared to the operational data-bases. Integrating data into one location and one data model is one of the main tasks of data warehousing. In particular, integrating data ahead of time allows a data warehouse to be an "active" solution to providing decision support.
2.3.3. Non-Volatile
A non-volatile database means that data in the warehouse does not change or get updated. (Inmon 1995) In an operational database, records can be inserted, edited or deleted to represent the existing state of the world. In a data warehouse, new data can only be appended. Much like a repository, once data are loaded into the warehouse, they are read only and can not be edited or deleted by end users. The minimum requirement that
some organizations place on the contents to stay in a data warehouse is on the order of 10 to 20 years. However, the date warehouse should be added with new contents on a regular basis to allow users to perform analysis with the most current information. Non-volatility also means that the contents of a warehouse are stable for a long period of time so that users can be confident of the data integrity when they are conducting analyses. A result of the non-volatility of the data warehouse is that the volume of data become extraordinarily large, on the order of terabytes. Wal-Mart, which has the largest existing data warehouse, has over 4 terabytes of data and 200-300 megabytes per day. (Wiener 1997)
2.3.4. Time-Variant
Time-variant data mean that the data warehouse to contains information that cov-ers a long period of time. (Inmon 1995) The time horizon for data in a warehouse can be decades whereas operational data is usually current and kept only for the past couple of months. In the operational environment, the accuracy of the data are valid at the moment of access and the data does not contain an element of time. In a data warehouse, time is an important element because it allows the end user to conduct trend analysis and historic comparisons. An example of this is the ability to determine the results of a specific quarter or year and compare them with other time periods. The data warehouse can be seen as a storage of a series of snapshots representing periods of time.
2.4. Support Management Needs
2.4.1. Operational Data Store
An operational data store is a collection of data used in the operational environment. (Zornes 1997) The majority of data in organizations are operational data,
which are data used to support the daily processing that a company performs. These data are used to help serve the clerical and administrative community in their day-to-to decisions. This may include up-to-the-second decision making such as in purchasing, sales, reordering, restocking, and manufacturing. Thus the data stored in an ODS tend be recent in nature and tend to be updated frequently. In comparison with a data warehouse, an operational data store is a database that has the characteristics of being volatile and current valued. This means that data in the ODS change to reflect the current situation so that historical analysis to support management needs is not possible.
2.4.2. Data Warehouse for Managers
The ultimate goal of a data warehouse is to provide decision support for manage-ment. The characteristics described above help resolve many problems related to using operational data as a sources for decision support. Applying those defined characteristics to the implementation helps facilitate, for managers, the ability to conduct analysis on cor-porate data collected from various sources. The warehouse database is optimized differ-ently from an operational database because it has a different focus. The operational database focuses on processing transactions and can add data quickly and efficiently, but can not deliver data that are meaningful for analysis. To retrieve information from these databases, a manager must work through the information systems department. Attempting to convey ad-hoc queries may take longer than several days for the data to be determined and retrieved. Furthermore, the data integrity and quality in operational databases is fairly low since it often changes. As these databases are updated, old data are overwritten and thus, historical data are not available. A data warehouse, the result of the data warehous-ing process, is ultimately a specialized database that provides decision support capabilities
for managers. Table 1 provides a summary of how a data warehouse compares to an oper-ational or standard database.
Table 2.1: Standard Database vs. Warehouse (Wiener 1997, Page 1996)
Standard DB Warehouse
Focus Data in Information out
Work Characteristics Updates Mostly reads
Type of Work Many small transactions Complex, long queries Data Volume Megabytes to Gigabytes Gigabytes to Terabytes
Data Contents Raw Summarized, consolidated
Data Time Frame Current data Historical snapshots
Usage Purpose Run business Analyze business
Typical User Clericalladministrator Manager/decision maker
2.5.
Advantages of Data Warehousing
From the above discussions, it can be seen that there are many advantages to the data warehousing approach. The primary advantage is that since the warehouse is designed to meet the needs of analyst, by collecting the relevant information ahead of time, it is customized for high query performance. The integration of data means that business end users do not have to understand different data models and multiple query lan-guages in order to perform analyses. Furthermore, integrating data into a common form simplifies the system design process. One example is that there is no need to perform query optimization over heterogeneous sources, a very difficult problem faced by tradi-tional approaches. (Widom 1995)
Creating a separate physical location for storing the warehouse data provides many additional benefits for the user. One result is that information in the data warehouse is accessible at anytime, even if the original sources are not available. Giving business users a separate warehouse for analysis also eases the processing burden at the local data sources. This means that the operational databases that are processing transactions can be more efficient as well. Having a separate warehouse also allows extra information to be stored, such as summarized data and historical information that were not in the original sources.
2.6. Disadvantages of Data Warehousing
As with any design approach, there are trade-offs in the data warehousing approach that must be considered. First of all, creating a data warehouse means data are physically copied from one location to another, requiring extra storage space. This is not a significant problem given that data can be summarized and that storages prices continue to fall. A more significant result of copying data from one place to another is that the data in the warehouse might become stale and inconsistent with the original sources. Since the data warehouse is updated periodically, if the analytical needs of the user are for current information, the warehouse approach may not provide up-to-date information. Having a separate warehouse also means that there must some systematic mechanism to detect changes in the data sources and to update the warehouse. (Widom 1995)
The warehousing approach also means that the data that is to be stored in the ware-house must be determined in advance. Yet, the warehouse must be able to provide answers to ad-hoc queries of users, beyond just the standard expected questions. Finally,
the business end users can only query data stored at the warehouse, so determining what this data is in advance may result in the users not being able to perform certain analyses. This means that a data warehouse may not be the best solution when client data needs are unpredictable.
2.7.
Steps to a Data Warehouse
There are two critical stages to building a data warehouse and two types of people must be involved in order to have a successful and useful data warehouse. The two stages are the design phase and the implementation phase. (Singh 1998)
2.7.1. Design Phase
In the design process, the business end users or someone who understands the needs of the users must be involved in defining what the needs are. The business users must contribute to determining the logical layout of the data because, as the end users, they know by what subjects the data should be categorized. Once the data model and data architecture has been determined, the warehouse data and their attributes need to be iden-tified. This warehouse data needs to include additional data that will be added to the ware-house. This can include summary data or metadata, which data about the data.
Determining the types of summary data to include involves trying to minimize the potential query response times. Determining the types of metadata to include involves try-ing to simplify the maintenance process. At the same time, the design process should identify the various sources throughout the organization where the warehouse data will come from, and determine a simple strategy for transferring this data. Finally, the types of hardware and software packages that will be used must be chosen.
Figure 2.2. The process of building a data warehouse involves extracting data from various sources and then transforming, merging, and cleansing the data in order to achieve integrated data. (Wiener 1997)
2.7.2. Implementation Phase
Once the design process is completed, the data warehouse needs to be loaded with the correct information. As can be seen in Figure 2.2, the first step is to work with the original data sources and extract the relevant data. This data could have been stored in dif-ferent formats so the method of extraction depends on what the sources are, but there are existing tools that will perform some extractions. Generally, the data sources are legacy systems. Since the data are in different forms, it needs transformed into a uniform model, which may include changing the existing attributes of the data. Merging the data involves determining a way to match data from different sources so that a composite view can be presented. Merging will also require removing duplicates from different sources and
elim-inating unneeded attributes. Then the data needs to be cleansed to remove inconsistencies and wrong information. The cleansing process may also include patching missing data or fixing unreadable data. Finally, the summary data that is desired needs to be aggregated and is stored into the warehouse.
2.8.
Data Marts
As an extension of the data warehousing concept, the idea that not all corporate managers conduct the same types of analysis led to data marts. In particular, a data mart is a data warehouse that is created for a specific department within an organization. (Wiener
1997) Marketing Client Finance Clients Flat Files Sybase
As an example, the finance, sales, and marketing departments can each have their own data marts. The data marts can be created by using information from the corporate data warehouse or as a replacement for one large corporate data warehouse. Data marts are created with the same process that data warehouses are, except that it will probably be smaller in scope because it only needs to serve one specific user group. Increasingly, data marts are being developed because they better suited for analysis by the managers within a department. (Inmon 1996)
Chapter 3. OLAP
3.1. Introduction
Prior to the introduction of the Relational Model, database management systems (DBMS) rarely provided tools for end users to access data. Separate query-only tools were provided by some DBMS vendors but not others. (Singh 1998) One of the original goals of the Relational Model was to create more structure in database design so that DBMS products would be appealing to a wider audience of end users. Today, relational databases are accessed by a wide-variety of non-data processing specialists through the use of many end user tools. These include general purpose query tools, spreadsheets, graphics packages and off-the-shelf packages supporting various departmental functions inside an organization. For end users, this has led to a dramatic improvement in the query/ report processing in terms of speed, cost and ease of use. With spreadsheet-like applica-tions, the ability to generate queries and reports no longer required knowledge of COBOL. The easy to learn and easy to use spreadsheet gave business analysts the ability to perform the query and reporting tasks for themselves.
As end users became more empowered to meet their own data needs, they had more flexibility to experiment with various analyses and aggregations. However, even though the spread of relational DBMS tools allowed the analysts to conduct better analy-ses with much more efficiency, there are still significant limitations to their capabilities. (Singh 1998) Most end user products that have been developed are front-end tools to rela-tional DBMS with straightforward and simplistic funcrela-tionality. These spreadsheets and
query generators are extremely limited in the ways in which data can be aggregated, sum-marized, consolidated, viewed and analyzed. The ability to consolidate, view and analyze data according to multiple dimensions is something that was missing from these applica-tions. Multi-dimensional data analysis allows data to be viewed in a manner that makes sense to the business analyst, and is a central functionality of On-Line Analytical Process-ing (OLAP).
OLAP was introduced in 1993 by E.F. Codd as a tool to provide users with the ability to perform dynamic data analysis. (Koutsoukis 1997) Data analysis which exam-ines data without the need for much manipulation is referred to as static data analysis. Static data analysis usually views data from the perspective of how it was stored in the database. There are many types of tools that facilitate this type of two dimensional analy-sis, such as the traditional spreadsheet. Dynamic analysis involves manipulating historical data, such as data in a warehouse, extensively. This includes creating and manipulating data models which access the data many times across multiple dimensions. The key con-cept in OLAP is that it is designed for allowing many users to access the same data in a way that they each can perform whatever analysis they need to. The idea is to attempt to support all kinds of data analysis and discovery, in a way that is efficient, useful, and pos-sible. In the framework of a modem data warehouse, OLAP can provide the interface for executive users to conduct analyses on the data warehouse.
3.2. Multidimensional Data Model
In database terms, a dimension is a data category such as a product or location. Each category can have many characteristics, known as "dimension values," such as
prod-uct A, B, or C. In relational terminology, a dimension would correspond to the "attribute" while the dimensional values correspond to the attribute's "domain." (Koutsoukis 1997)
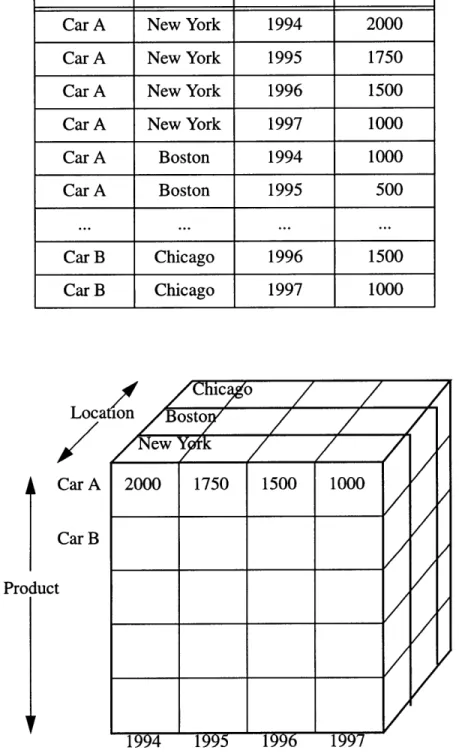
Table 3.1: Data in a Relational Table
Product Location Time Units
Car A New York 1994 2000
Car A New York 1995 1750
Car A New York 1996 1500
Car A New York 1997 1000
Car A Boston 1994 1000 Car A Boston 1995 500 CarB Chicago 1996 .. 1500.. Car B Chicago 1996 1500 Car B Chicago 1997 1000 Loca Car A Car B Product
lon
/Bostoy//
/
New k/
2000 1750 1500 1000 1994 1995 1996 1997 TimeFigure 3.1. Multidimensional cubes representing data in Table 1. (Kenan 1995)
'-' '
t I
///
_r . ..- a ,
The relational framework can be visualized in tables while a multidimensional data model can be visualized as a cube. In Figure 3.1., the cube demonstrates how information is stored as cells in an array of time, location and product. This cube is 3-dimensional, but the concept of adding another dimensions is the same as adding another array, such as price, to the cube. This array can be associated with all or some of the dimensions, that is,
the price may or may not change over time and from place to place
Multidimensional databases (MDDBs) support matrix arithmetic, so that a calcula-tion can present an array by performing a single matrix operacalcula-tion on the cells of another array. (Kenan 1995) MDDBs also are capable of much faster query performance because an array contains information that has already been categorized. For example, it's easy to aggregate an array of cars sold in Boston, whereas, in the relational table, a query would need to scroll through all the records and check whether it contains the Boston field. As the data becomes more complex, there is dramatically increasing savings from utilizing the multidimensional model. If a calculation had to be performed on Car A in a 10x10x10 cube, the MDDB only requires looking through a slice of a 10x10 array rather than check-ing through all 1000 records. Furthermore, as the number of dimensions increase, the multidimensional model can result in exponential savings.
3.3. Twelve Rules
Codd defined 12 rules for OLAP, which have since been added to by others. These original 12 rules provide a conceptual framework for OLAP's key characteristics and are at the core of most existing commercial OLAP tools. These rules are listed below and described in further detail in the following sections: (Codd 1993)
1. Multi-Dimensional Conceptual View 2. Transparency
3.Accessibility
4.Consistent Reporting Performance 5.Client-Server Architecture
6.Generic Dimensionality
7.Dynamic Sparse Matrix Handling 8.Multi-User Support
9.Unrestricted Cross-dimensional Operations 10.Intuitive Data Manipulation
11.Flexible Reporting
12.Unlimited Dimensions and Aggregation Levels
3.3.1. Multi-Dimensional Conceptual View
A key feature in OLAP is providing multidimensional data views, that is allowing data to be viewed across multiple dimensions. Multidimensional data tables help reflect a perspective on data that is more useful to the business user. This is because multidimen-sional views fit data to reflect the business perspective, not forcing the business user to perform analyses from the data perspective. As an example, a manager needs to see prod-uct sales by month, location, and market.
One way to visualize the concept of multidimensional viewing of data is to con-sider a spreadsheet. A single spreadsheet is two dimensional, with one dimension the col-umns and the other being the rows. A stack of spreadsheets would be three dimensional and two stacks would be four dimensional. Below are some common terms related to the manipulation and viewing of data: (Koutsoukis 1997)
Drill-Down: The exploration of data to lower levels of more detail along a dimen-sion.
Roll-Up: The aggregation of data to higher levels of summary along a dimension. Slice: Any two-dimensional slice of the data.
Dice: The rotation of the cube to reveal another different slice of data along a dif-ferent set of dimensions.
Pivot: A change of the dimension orientation, such as from rows to columns.
3.3.2. Transparency
Transparency helps ensure that users do not need to care from what data sources the information is coming from. (Codd 1993) This means that it should not matter what types of servers are used and whether the data are coming from homogeneous or heteroge-neous databases. OLAP should be provided with an open systems architecture, so that the analytical tool can be added to anywhere that the end user wants. Transparency also ensure that it does not matter what client or front-end tools are used by the end users. This rule allows business analysts to not need to learn different analysis tools and simplifies the
data analyses process for them.
3.3.3. Accessibility
Accessibility helps ensure that end users can perform analysis using one concep-tual schema. (Codd 1993) This means that the OLAP tool must map its own logical schema to heterogeneous data sources, access the data and perform any conversions needed to present a single consistent view for the user. The data sources may include leg-acy systems, relational and non-relational databases. The OLAP tool should allow the users to not be concerned with where the data are coming from and what types of formats those sources are. Furthermore, the OLAP tool should be able to access these sources on its own to carry out the necessary analyses.
3.3.4. Consistent Reporting Performance
Users need to have a tool that performs consistently when interacting with the data. OLAP tools need to ensure that as the data model, data size, or number of dimensions increase, there should not be significant performance degradation. This will allow the end users to focus on performing the analysis rather than worrying about what model to use to overcome the performance problems.
3.3.5. Client-Server Architecture
OLAP products must function in a client-server environment because most corpo-rate data is stored in mainframe systems while end users often use personal computers. Operating in a client-server environment will increase the flexibility and ease of use for the business end users who can access the information from their own computers. How-ever, functioning in this environment also means that the servers that OLAP tools work with must be able to work with various clients using minimal effort in integration. Also, the servers must be intelligent enough to ensure transparency when working with multiple data sources and end user tools.
3.3.6. Generic Dimensionality
Generic dimensionality means that every data dimension should be the same in its structure and operational capabilities. (Codd 1993) This also means that the basic data structure, formulae and reporting formats should not be biased toward any one particular data dimension and that all the dimensions should be able to handle any type of data. Since the various dimensions have the same operational capabilities, end users will have the ability to perform consistent functions and analyze the same type of data.
3.3.7. Dynamic Sparse Matrix Handling
The OLAP system must adapt its physical schema to the specific analytical model that optimizes sparse matrix handling. (Codd 1993) Data sparseness occurs when there are many missing cells in relation to the number of possible cells. This leads to the data being distributed unevenly across the data set and possibly different physical schema. The size of the resulting schema depends on how the sparseness is distributed and how the data is accessed. Given any sparse matrix, there exists one and only one optimum physical schema which provides the maximum memory efficiency and matrix operability. The OLAP tool's basic physical data unit must be configurable to any of the available dimen-sions and the access methods must be dynamically changeable in order to optimally han-dle sparse data.
3.3.8. Multi-User Support
Since OLAP is intended to be a strategic tool for business users, it must support the ability of a group of users to concurrently access the data. OLAP tools must allow multi-ple users to retrieve and update either the same analytical model or create different models from the same data. Furthermore, this means that the concurrent users should be provided with data security and integrity.
3.3.9. Unrestricted Cross-Dimensional Operations
The OLAP system must be able to recognize dimensional hierarchies and automat-ically perform associated calculations within and across dimensions. (Codd 1993) The tool must infer calculations between dimensions without requiring the end user to
explic-itly define the inherent relationships. Furthermore, calculations that are not inherent and require the users to specify the formula should not restrict calculations across dimension.
3.3.10. Intuitive Data Manipulation
Data manipulation should be accomplished by direct action upon the cells of the analytical model in order to ensure ease of use for the business analyst. Pivoting (consoli-dation path reorientaion), drilling down across columns or rows, zooming out to see a more general picture, and other manipulations inherent in data analysis should be accom-plished with an intuitive interface. There should be no need to use menus and the user's view of the dimensions should contain all the necessary information to accomplish these
actions.
3.3.11. Flexible Reporting
A primary requirement for business users is the ability to present information in reports. Analysis and presentation of data is simpler when rows, columns and cells of data can be easily viewed and compared in any possible format. This means that the rows and columns must be able to contain and display all the dimensions in an analytical model. Furthermore, each dimension contained in a row or column must be able to contain and display any subset of the members. A flexible reporting OLAP tool will allow end users to present the data or synthesized information according to any orientation they desire.
3.3.12. Unlimited Dimensions and Aggregation Levels
The OLAP system should not impose any artificial restrictions on the number of dimensions or aggregation levels. (Codd 1993) This is so that from a business point of view, the end users will not be limited by how they want to look at the data. However, in
practice, the number of dimensions required by business models is typically around a dozen each having multiple hierarchies. This means that OLAP systems should in general support approximately fifteen to twenty concurrent data dimensions within a common analytical model. Each of these generic dimensions must allow essentially an unlimited number of user-analyst defined aggregation levels within any given consolidation path.
3.4. Interface for Data Warehouse
OLAP and data warehousing are very much complementary. In order for the end-user to be able to conduct analysis with the data warehouse, there needs to be an interface. While the data warehouse stores and manages the analytical data, OLAP can be the strate-gic tool to conduct the actual analysis. It is used as a common methodology for providing the interface between the user and the data warehouse. OLAP builds on previous technol-ogies of analysis by introducing spreadsheet-like multidimensional data views and graphi-cal presentation capabilities. Utilizing the data warehousing concept, decision makers in an organization can use the OLAP interface to perform various types of analysis directly on the data. This interface allows for multidimensional data analysis and easy presenta-tion of graphs and results on the data warehouse.
The flexibility of OLAP as described in Codd's twelve rules allows it to be easily used by business managers across a wide spectrum of data sources and data types. The ability of OLAP to provide multidimensional data views gives users the ability to see and understand the information more intuitively. This leads to quicker formulation of different and more in-depth types of analyses that can be made on the data warehouse. Without data warehousing, OLAP would not necessarily be possible because the unorganized data
would not be able to support the required OLAP functionality. Furthermore, applying multidimensional OLAP tools to data warehousing allows much faster query and report generation performance, especially as the warehouse gets into terabytes of data.
3.5.
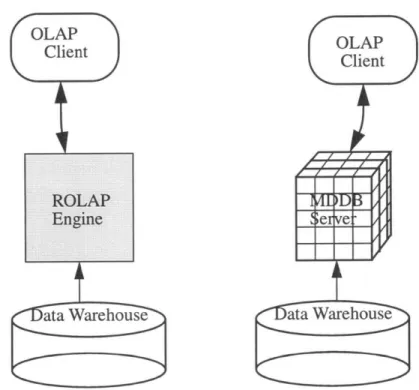
MOLAP vs. ROLAP
There are two different approaches to how the front-end OLAP tools can interface with the data warehouse. (MicroStrategy 1995, Arbor 1995) One method is to use a MDDB OLAP (MOLAP) server while the other approach is to use Relational OLAP (ROLAP) technology. In the case of using a multidimensional database, the MDDB can be used as the data warehouse but is typically built on top of the data warehouse. This means that the MOLAP server is an intermediate step between the data warehouse and the end user. Since the information will be viewed in multiple dimensions, pre-storing infor-mation in a MDDB is a logical step. Storing data in an MDDB leads to faster query per-formance because of the inherent dimensions, but there are disadvantages as well. One problem is that it is difficult to change the data model of a MDDB once it has been estab-lished, so the design process must make sure that all the desired views are represented in the MDDB. Furthermore, MDDBs generally aggregate data before it has been added to the database so the process of loading data into the database may be extremely slow.
Even though the OLAP view of data is inherently multidimensional, data from relational warehouses can be transformed into multiple dimensions. This is through a ROLAP engine that performs the necessary calculations and transformation on the data. The ROLAP engine sits between the end user and the data warehouse. (MicroStrategy 1995) The appeal of this approach is that there is no need to create an intermediate
multi-dimensional data model to store the data so that there is no need to predefine what types of views may exist. The data warehouse can be created using relational databases and can be accessed directly by the ROLAP front-end tools. The problem with this approach is that the process of accessing data and calculating data from the relational databases and trans-forming them into multidimensional views may take an extremely long time. However, in reality, both the MOLAP and ROLAP solutions work but are typically used for different applications and by different end users who have different analysis and speed require-ments.
OLAP OLAP
ROLAP 0
Engine ee
ata Warehouse ata Warehouse
Figure 3.2. Using a ROLAP engine vs. creating an intermediate MDDB server. (MicroStrategy 1995, Arbor 1995)
Chapter 4. Data Mining
4.1. Introduction
Organizations generate and collect huge volumes of data in the daily process of operating their businesses. Today, it is not uncommon for these corporate databases to bloat into the range of terabytes. (Codd 1993) Yet, despite the wealth of information stored in these databases, by some estimates, only seven percent of all data that is col-lected is used. (IBM) This leaves an incredible amount of data, which undoubtedly con-tain valuable organizational information, largely untouched. In the increasingly competitive business environment of the information age, strategic advantages can be obtained by deriving information from the unused data.
Historically, data analysis has been conducted using regression and other statistical techniques. These techniques require the analyst to create a model and direct the knowl-edge gathering process. Data mining is the process of automatically extracting hidden information and knowledge from databases. It applies techniques from artificial intelli-gence to large quantities of data to discover hidden trends, patterns and relationships. Data mining tools do not rely on the user to determine information or knowledge from the data. Rather, they automate the process of finding predictive information. (PROFIT Web Page 1998) This is an emerging technology that has recently been increasingly applied to business analysis and has increasingly been targeted for end users. Some of the applica-tions and tasks of commercial data mining tools include association, classification, and clustering. These applications have been used in a wide variety of industries ranging from
retail to telecommunications for purposes of inventory planning, targeted marketing, and customer retention.
Data mining techniques are much more powerful than the traditional data analysis methods of regression and linear modeling. Data mining applies algorithms such as neural networks, which mimic the human brain for parallel computation. By utilizing neural net-works and other concepts from artificial intelligence, data mining can achieve results that even domain experts can not. These techniques allow analysis to be conducted on much larger quantities of data as compared to traditional methods. Furthermore, data mining automates the discovery of knowledge from the data and results in predictions that can outperform domain experts. Applying new technologies, such as data mining can lead to significant value-added benefits in data analysis that can not be achieved with traditional methods.
4.2. Data Mining Tasks
Data mining tasks are the various types of analyses that can be conducted on a set of data. The analyses can be seen as a methodology used to solve a specific type of prob-lem or make a specific type of prediction. (Data Mining Web Page) Each task is a type of pattern that a data mining technique looks for in the database. Different data mining tech-niques or algorithms can be used for achieving the goals of these tasks. The tasks described are the ones most commonly used when data mining tools are applied to data-bases.
4.2.1. Association
Association is a task that finds correlations such that the presence of one set of items implies that other items are also likely to be present. (Data Mining Web Page) This is essentially a method of discovering which items go together and is also referred to as affinity grouping or market basket analysis. Data mining a database of transactions using the association task derives a set of items, or a market basket, that are bought together.
The typical example of an association report is that "80% of customers who bought item A also bought item B." (IBM) The specific percentage of occurrences (80 in this case) is referred to as the confidence factor of the association. There can also be mul-tiple associations such as "75% of customers who bought items C and D also bought items E and F." For any two sets of items, two association rules can be generated. Thus in the first example, the other rule that can be generated is "70% of customers who bought item B also bought item A." The two associations do not have to lead to the same probabilities. Applications of association tasks include inventory planning, promotional sales planning, direct marketing mailings, and shelf planning. The industries which apply asso-ciation tasks tend to be ones which deal with marketing to customers, such as the retail and grocery industries.
4.2.2. Classification
Classification involves evaluating the features of a set of data and assigning it to one of a predefined set of groups. (Data Mining Web Page) This is the most commonly used data mining task. Classification can be applied by using historical data to generate a model or profile of a group based on the attributes of the data. This profile is then used
classify new data sets and can be used to predict the future behavior of new objects by determining which profile they match.
A typical example of applying classification is fraud detection in the credit card industry. In order to use the classification task, a predefined set of data is used to train the system. This set of data needs to contain both valid and fraudulent transactions, deter-mined on a record-by-record basis. Since these transactions have been predefined or pre-classified, the system determines the parameters to use to recognize the discriminatory features. Once these parameters are determined, the system utilizes them in the model for future classification tasks.
A variation of the classification task is estimation or scoring. (IBM) Where classi-fication gives a binary response of yes or no, estimation provides a gradient such as low, medium, or high. That is, estimation can be used to determine the several levels or dimen-sions of profiles so that a value can be attached to a profile. In the credit card example, estimation would provide a number which could be interpreted as a credit-worthiness score based upon a training set that was prescored. In essence, estimation provides several profiles along a set of data, representing the degree that a profile fits a group.
The profiles that are generated in classification can be used for target marketing, credit approval, and fraud detection. The data mining techniques that are typically used for classification are neural networks and decision trees.
4.2.3. Sequential Patterns
Sequence-based tasks can introduce a new dimension along time to the data min-ing process. (Data Minmin-ing Web Page) Traditional association or market basket analysis evaluates a collection of items as a point-in-time transaction. However, with historical
time-series data, it is possible to determine in what order specific events occurred. Much like association tasks, sequential patterns establishes the order which can be used to corre-late certain items in the data set. The amount of time between certain correcorre-lated events can also be determined by sequential pattern tasks.
An example of a sequential pattern rule is the identification of a typical set of pre-cursor purchases that might predict potential subsequent purchases of a specific item. The rules established might include a statement such as "90% of customers who purchase computers purchase printers within a year." This type of analysis is used heavily in sales promotion and for financial firms for the events that affect the price of financial instru-ments.
4.2.4. Clustering
Clustering is a task that segments a heterogeneous group or population into a num-ber of more homogeneous subgroups. This is different from classification because cluster-ing does not depend on predefined profiles for the subgroups. Clustercluster-ing is performed automatically by the data mining tools that identify the distinguishing characteristics of a dataset and is considered to be an undirected data mining task. (Data Mining Web Page) The tools partition the database into clusters based upon the attributes in the data and results in groups of records that represent or possess certain characteristics. The patterns found are innate to the database and might represent some unexpected yet extremely valu-able corporate information.
One example application of clustering is for segmenting a group of people who have answered a questionnaire. (IBM) This approach can divide consumers according to their answer patterns and create subgroups which have the most similarity within them and
the most difference between them. Clustering or segmentation is used in database market-ing applications that determine the best demographic groups to targets for a certain mar-keting campaign.
Clustering is often used as a first step in the data mining process before some other tasks are applied to a set of data. (Data Mining Web Page) It can be used to identify a group of related records that can then be the starting point of further analysis. As an example, after segmenting a population using clustering tasks, association analysis can be applied to the subgroups to determine correlated purchases of a particular demographic group.
4.3. Techniques and Algorithms
A variety of techniques and algorithms from artificial intelligence are applied for data mining. By applying these AI techniques, which are more powerful than traditional data analysis methods, much larger databases can be evaluated and more insightful knowl-edge can be drawn from the data.
4.3.1. Neural Networks
Neural networks, also known as Artificial Neural Networks or ANNs, refer to a class of non-linear models that attempt to emulate the function of biological neural net-works in brains. ANNs mimic human brains by using computer programs to detect pat-terns, make predictions, and learn. (Berson and Smith 1997) Neural networks show a good ability to "learn" patterns from a dataset and can identify patterns used for data min-ing such as association, classification, and the extraction of underlymin-ing dynamics of a data-base.
The two main structural components of a neural network are the nodes and the links. (Berson and Smith 1997) The nodes correspond to a neuron in the brain and the links correspond to the connections between the neurons. In the neural network, each node is a specific factor or input into the model and each link has a weight attached to it, which determines the impact of the node. Thus the values of the nodes are multiplied with the values of the weights in the connecting links to determine the input of the next stage. This is repeated until the final prediction value.
Input 0.5 Weight = 0.5 A
1.0 Output
Input eight = 1.0
B 0.75
Figure 4.1. A one input layer neural network, with two input nodes, two links, and one output node. (Berson and Smith, 1997)
A neural network must first enter a training phase in which the network is "trained" with historical or past data using backpropagation, or an alternative approach. Next, the performance of the network is verified by checking against a validation or test set. The performance of a particular type of network might depend on the complexity of the underlying function, the signal to noise ratio, the desired prediction performance, and the number of input and output variables and their correlations. In practice, a number of network types and architectures are tried out to determine the optimal configuration. Examples of major network classes include: Feed-forward or Multi-Layer Perceptron (MLP), Time Delay Neural Network (TDNN) and Recurrent Neural Networks. Major learning algorithms include: Hebbian Learning, backpropagation momentum learning,
time delay network learning, and topographic learning.
4.3.2. Decision Tree
A decision tree is a predictive model that can be viewed as a tree. In the tree-shaped structures representing sets of decisions, each branch of the tree is a classification question and the leaves of the tree are parts of the data set that match the classification. (Berson and Smith 1997) Specific decision tree methods include Classification and Regression Trees (CART) and Chi Square Automatic Interaction Detection (CHAID).
The algorithms works by picking predictors and their splitting values on the basis of the gain in information that the split provides. Gain is determined by the amount of information that is needed to correctly make a prediction both before and after the split has been made. It is defined as the difference between the probability of correct prediction of the original segment and the accumulated probabilities of correct prediction of the result-ing split segments. (Berson and Smith 1997)
4.3.3. Nearest Neighbor
Nearest neighbor is a prediction technique that uses records from historical data-bases that are similar to an unknown record. It identifies similar predictor values from those records and utilizes the record that is the "nearest" to the unknown record. (Berson and Smith 1997) The "nearness" factor depends on the problem that is trying to be solved. For example, when trying to predict family income, some factors could include college attended, age, or occupation. But the first step in identifying similar records is to narrow down the problem to the neighborhood that the person lives in before selecting the "near-est" neighbor as the predictor.
A variation of the nearest neighbor algorithm that is used quite often for data min-ing is the k-nearest neighbors method. This is an improvement to the classic nearest neighbor method as it uses k records to provide better prediction accuracy and eliminates problems caused by outliers. (Berson and Smith 1997)
4.3.4. Genetic Algorithms
Genetic algorithms are computer programs that, just like biological organisms, undergo mutation, reproduction, and selection of the fittest. Over time, these programs improve their performance in solving a particular problem. (Berson and Smith 1997) Some of the ways that computer programs can undergo a mutation or reproduction are that the programs exchange values or create new programs. In data mining applications, the specific problem can be defined and a genetic computer algorithm will attempt to find the best solution through the process of natural selection.
Genetic algorithms can be seen as a type of optimization technique that are based on the concepts of evolution. For data mining, they have generally not shown faster or better solutions than the other algorithms, but have been used as a validation technique. (Berson and Smith 1997)
4.4. Interaction with a Data Warehouse
Data mining can leverage existing technologies of data warehouses and data marts because the data in those databases are already stored in a manner that is efficient for anal-ysis. (Gartner Group 1995) The process of creating a warehouse for data mining is useful because the data is collected into a central location and stored into a common format.