An assessment of the video analytics
technology gap for transportation facilities
The MIT Faculty has made this article openly available.
Please share
how this access benefits you. Your story matters.
Citation
Thornton, J., J. Baran-Gale, and A. Yahr. “An Assessment of the
Video Analytics Technology Gap for Transportation Facilities.”
Technologies for Homeland Security, 2009. HST ’09. IEEE
Conference On. 2009. 135-142. Copyright © 2009, IEEE
As Published
http://dx.doi.org/10.1109/THS.2009.5168025
Publisher
Institute of Electrical and Electronics Engineers
Version
Final published version
Citable link
http://hdl.handle.net/1721.1/62008
Terms of Use
Article is made available in accordance with the publisher's
policy and may be subject to US copyright law. Please refer to the
publisher's site for terms of use.
An Assessment of the Video Analytics Technology Gap for Transportation
Facilities
Jason Thornton, Jeanette Baran-Gale, Aaron Yahr
MIT Lincoln Laboratory, 244 Wood St., Lexington, Ma. 02420
Abstract
We conduct an assessment of existing video analytic technology as applied to critical infrastructure protec-tion, particularly in the transportation sector. Based on discussions with security personnel at multiple facilities, we assemble a list of desired video analytics functionality, which we group into five categories: low-level activity detection, high-low-level behavior detection, discrimination, tracking, and content retrieval. We then evaluate the capabilities and deficiencies of current technology to meet these needs, in part by applying representative video analytic tools to a testbed of video data from multiple sources. As part of the evaluation, we examine performance across pixel resolution of de-grees of scene clutter. Finally, we identify directions for promising technology development in order to address
critical gaps.1
1. Introduction
In support of security operations, critical infras-tructure facilities often deploy comprehensive installa-tions of surveillance video cameras. These surveillance systems serve two functions: they provide a visual record of events for the investigation of past incidents, and they allow security personnel to perform real-time monitoring of their facilities more effectively. The visual cues provided by such systems may be used to detect suspicious or otherwise noteworthy behavior, including some criminal and terrorist acts. Due to the decreasing costs of digital video cameras, digital video recorders, and network capabilities, many facilities have been increasing their investments in this tech-nology (and therefore, their surveillance coverage)[1]. However, it is difficult for humans to monitor mul-tiple video feeds simultaneously, or to inspect large
1. This work was sponsored by the Department of the Air Force under Air Force Contract # FA8721-05-C-0002. Opinions, interpre-tations, conclusions and recommendations are those of the authors and are not necessarily endorsed by the United States Government.
volumes of archived data. This is the motivation for video analytic (or intelligent video) technology, which encompasses a set of techniques for the automatic interpretation of video data. Such tools can serve as aids for security personnel, directing their attention to the most relevant video.
Many commercially available tools offer a standard set of video interpretation capabilities and are meant to work out of the box, with little or no tuning required by the end user[2]. Some critical infrastructure facilities have already deployed such tools within limited capac-ities, especially for perimeter monitoring and archived content retrieval[3]. However, the performance of these systems is often problematic, due to the difficulties inherent in video analysis. Two of the most common modes of failure are false negatives and false positives. In the first case, the system does not detect an activity-of-interest because it is too complex or subtle for the analytic algorithms to reliably distinguish it from normal background activity. In the second case, the system claims to detect an activity that is not exhibited in the processed video, issuing a false alarm; when frequent enough, these alarms become a distraction to security personnel rather than an aid. In addition, some critical infrastructure facilities have specialized analytic needs which are not well-addressed by the commercial market.
In this work, we conduct an assessment of existing video analytic technology as applied to critical infras-tructure protection, based partially on experiments us-ing a video data testbed. As part of this assessment, we are surveying the video interpretation needs of different types of critical infrastructure facilities, as well as their past or present experiences with video analytic technol-ogy. We are then applying representative commercial and open-source tools to sample video datasets, in order to evaluate the ability of current technology to meet high-priority critical infrastructure needs. Finally, we are identifying critical gaps which might benefit from near-term research and development within the next several years.
We note that our initial focus is on algorithms and information processing, and not on camera hardware or network configuration issues. There have been sev-eral recent open evaluations of video interpretation algorithms, including the Performance Evaluation of Tracking and Surveillance (PETS) workshops[4] and the NIST TREC Video Retrieval Evaluation series [5]. To the extent that these evaluations address the capabilities we wish to assess, we take into account their findings and, in the case of PETS, incorporate some of their data into our experiments.
2. Desired Capabilities
Before conducting our assessment, we collected information about video analytic needs from security representatives at airports, subway stations, train/bus stations, national monuments, secure office buildings, and military bases. This information includes desired functionality (irrespective of technical limitations), rel-ative priorities for these needs, and some input about operational restrictions. Based on these discussions, we assembled a list of desired capabilities, which we group into the following five categories:
• Low-level activity detection: This category
in-cludes detection capabilities for specific actions with relatively well-defined descriptions. These activities occur over short time spans ranging from seconds to minutes, and judgment of their occurrence is generally consistent across hu-man observers. Examples include fence-climbing, window-breaking, and item abandonment.
• High-level activity detection: High-level
activi-ties are more ambiguously defined than low-level activities, indicated more by patterns of behavior than by specific physical actions. In fact, it is not always clear to human observers what comprises an instance of these activity types. Examples in-clude pre-operational site casing and surveillance and individuals exhibiting abnormally high stress levels.
• Object discrimination: This category includes
any sort of discrimination between scene compo-nents, including humans, vehicles, animals, and inanimate objects. Since many surveillance tasks revolve around human activity, one of the most useful forms of discrimination is between human motion and non-human motion.
• Coordinated tracking: This category includes
prolonged tracking of persons or vehicles, possi-bly across multiple camera views within the same
facility. Some desired capabilities require tracking a person or vehicle backwards in time in order to bring up all video depictions. Other capabilities require tracing an object’s path on a common geo-spatial reference frame shared by all cameras (such as a facility floor plan).
• Video content retrieval: Video retrieval
capabil-ities allow security personnel to search through archived footage efficiently. For example, secu-rity may wish to execute semantic queries for particular types of content, such as all vehi-cles appearing in a specified region within the last several days. Such tools must accommodate searching over large video datasets without heavy computational loads (i.e., without reprocessing all archived video).
For the most part, these need categories require dif-ferent video interpretation techniques, although there are some common sub-components between the cat-egories. For instance, the detection of tailgating may rely upon the ability to track individuals over relatively short time periods. We note that we exclude two more specialized categories of video analytic capabilities from our assessment: video-based biometrics and li-cense plate recognition. Though we do not discuss them here, both of these are active areas of research and development[6], [7], [8].
3. Assessment Methodology
To aid with our assessment of existing video analytic technology, we are acquiring testbed data from several sources, described below:
• The first source is publicly available datasets from PETS 2004, 2006, and 2007, which contain several types of staged activities (e.g., abandoned items, loitering, fighting, falling) among back-grounds of crowds in public areas. This video was captured at 30 frames per second and stored using the MPEG4 compression format.
• The second source is an internal dataset collected by clusters of high-resolution cameras at Lin-coln Laboratory overlooking a parking lot and several building exteriors. We have video data collected on two different days (one overcast day with snow coverage, and one mild day with no snow coverage). This dataset also includes sev-eral staged activities (such as fence-climbing and casing), along with normal background activity depicting person/vehicle motion and interactions.
This video was captured at 4 frames per second and stored using the MPEG4 compression format.
• The final source is external data collected at one or more representative critical infrastructure facilities. Collection of this data is ongoing, and the experimental results plots presented in this paper do not incorporate this data source. Combined, the datasets we use contain a variety of indoor and outdoor environments, with variable camera positions and a range of scene clutter and occlusion effects.
In order to guide our assessment, we applied exam-ples of commercial off-the-shelf and open-source video analytic software to our testbed data. Most of the open-source tools were taken from OpenCV[9], a library of computer vision utilities. We note that we cannot conduct empirical tests for every capability need on our list, since we are limited both by the content of the testbed data and the functionality available in our tools. We use a few tools as case studies which, when combined with the context provided by video interpretation experts and feedback from security personnel, provide some useful indications about the state of the technology. During experimentation, we vary properties of the video data such as frame rate and pixel resolution, in order to gauge the effect on video analytic performance.
4. Low-Level Activity Detection
There is a wide range of specific activities relevant to critical infrastructure security operations. Activi-ties of interest include abandoned items, loitering, perimeter-crossing, fence-climbing, window-breaking, baggage theft, tailgating through restricted access points, falling/collapsing, and physical altercations. Commercial video analytics tools address the detection of some of these directly, incorporating them into the syntax made available to the end-user when defining alarm-generation rules. The first three capabilities, in particular, are commonly included in commercial packages. We discuss empirical performance results for one of these sample capabilities below.
4.1. Abandoned items
Item abandonment typically refers to situations in which pedestrians leave behind hand-carried items (e.g., bags, packages, or suitcases) in public spaces. The video analytic objective is to form an association between pedestrians and the items in their possession, and then raise an alarm when a pedestrian moves away
from the item for a sustained period of time (defined by some spatial and temporal criteria encoded in the analytic rule)[10].
For our quantitative evaluation, we used 43 video sequences depicting abandoned item events, along with background data depicting no abandoned item events. This data was recorded in five different environments and contains some video of the same events captured at different camera angles or post-processed to achieve different frame resolutions. We applied a representative COTS video analytics toolkit to process this data, using built-in functionality to attempt detection of abandoned item events. As in all of our empirical trials, we left any configurable algorithm parameters at their default values. Any system alarm corresponding to an actual left item event was considered a successful detection, while any alarm that did not was considered a false positive. In some cases, the system issued multiple alarms in rapid succession, apparently in response to the same activity; we combined these instances into a single alarm when computing performance statistics.
Across all processed video, the probability of de-tection of real abandoned item events was 67%. To some degree, the performance is a function of data characteristics such as scene crowdedness and pixel resolution, which varies in our dataset. To address these factors, we ascribe to each video clip a category for clutter (i.e., the average number of movers in the scene) and pixels-on-item (i.e., the average number of pixels depicting the abandoned item). Figure 1 shows the detector performance across two environment types, crowded indoor and sparse indoor, for a fixed range of pixels-on-item. The sparse scenes have approxi-mately 0-10 movers in a typical frame, while the crowded scenes have approximately 10-30. In this case, the scenes with less clutter allow for a reduction in false positives and a significant increase in detections. In contrast, Figure 2 plots the performance statistics across pixels-on-item for sparse indoor settings. Note that probability of detection decreases with resolution, although the 25-100 pixel range still gives sufficient cues for 50% detection in the sparse environment.
We observed the following common causes of diffi-culty for this task:
• False positive cause: Shifting heads or limbs
that suddenly come into view are mistaken for abandoned items. In these cases, the skin-colored group of pixels stands out from clothing or scene background as a newly introduced blob.
• False positive cause: Stationary humans, or
slow-moving humans who are distant from the camera, are labeled as abandoned objects.
as-A b a n d o n e d ite m a lg o rith m p e rfo rm a n c e w ith c lu tte r v a ria tio n (1 0 0 - 4 0 0 p ix e ls o n ite m )
S pars e Indoor C row ded Indoor
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% S ce n e T yp e P ro b ab ilit y o f d e tect io n 0 2 4 6 8 10 12 14 16 18 20 Fa ls e a la rm s pe r hour
D etec tion rate F als e alarm rate
Figure 1. Abandoned item detection performance by moving clutter category.
A b a n d o n e d ite m a lg o rith m p e rfo rm a n c e w ith re s o lu tio n v a ria tio n (sp a rs e in d o o r e n v iro n m e n ts ) 75% 63% 50% 13 8 8 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% 100 - 400 50 - 200 25 - 100 R a n g e o f P ix e ls o n Ite m P ro b ab ilit y o f d e te ct io n 0 2 4 6 8 10 12 14 16 18 20 F a lse alar m s p e r h o u r Detection rate False alarm rate
Figure 2. Abandoned item detection performance by pixels-on-item range.
sociation between person and object, they are disassociated when the person becomes partially occluded, leading to an incorrect abandoned item alarm.
• False negative cause: Motion in front of an
aban-doned item causes frequent occlusions, preventing the system from recognizing a static object. Based on these observations, we believe the follow-ing would be useful objectives for future algorithm development:
• Incorporation of stronger, more articulated human body models: A model that correctly fits pixels to a detailed human form, including the limbs and head, would be less likely to confuse stationary humans or human segments with inanimate ob-jects.
• Three-dimensional scene reconstructions: Partial occlusion is a frequent obstacle for abandoned item detection. Computing a three-dimensional
representation of the scene using multiple over-lapping camera views (if available) can help re-cover some object positions otherwise lost in two-dimensional image plane projections.
4.2. Discussion
Current video analytic technology demonstrates some success detecting low-level activities, as long as there is a sufficient number of pixels-on-target and low clutter in the form of movers. The performance of these capabilities tends to be a function of both the complex-ity of interactions which define the activities and the duration of the activities. Simple-interaction activities such as perimeter-crossing or falling/collapsing require a less detailed (and therefore easier) video interpre-tation than activities such as tailgating, item aban-donment, or window-breaking, which require pars-ing interactions between multiple persons or objects. In addition, actions that occur over relatively short time spans facilitate detection more than actions that occur over extended time spans, which have more opportunity for algorithm breakdown. For instance, we would expect five-minute loitering rules to miss detections more often than 30-second loitering rules. Overall, it seems plausible that incremental algorithm improvements could eventually lead to a robust set of low-level activity characterization abilities in all but the most challenging settings.
5. High-Level Activity Detection
In contrast to low-level activities, high-level activ-ities are defined by patterns of behavior that exhibit more subtle visual cues. It is difficult for video in-terpretation algorithms to parse these behaviors for several reasons: the individual cues tend to be difficult to detect, they do not occur in well-defined sequences, and they may be exhibited over extended periods of time (from minutes to hours) and across multiple camera views. For critical infrastructure protection, high-level activities of interest include the following:
• Site casing and surveillance: Individuals who
survey the layout of a site or closely monitor the details of operation might be doing so in preparation for terrorist or criminal acts. Poten-tial cues include systematic movement throughout the facility, in addition to unusual focus on or photographing of critical site components, such as support structures or air intake vents.
• Abnormally high stress or malicious intent:
Some security personnel are trained to look for
individuals exhibiting signs of high stress or malicious intent, in order to determine when they should initiate an investigative interview[11]. However, visible indicators of these states of mind, such as aggressive body language or par-ticular facial expressions, are usually fairly subtle and require well-fit models of human motion to achieve automatic interpretation. We note that there are efforts to combine video cues with other remote physiological measurements in order to detect mal-intent (for example, the DHS Future Attribute Screening Technology program).
• Possession of concealed weapons or explosives:
While concealed weapons or explosives are typ-ically not directly observable through video, the individuals concealing them tend to exhibit ob-servable patterns of body language. These include unusual walking gaits, constant clothing adjust-ments, and repetitive over-the-clothes patting of the weapon/explosive to make sure it is in position and secure.
To our knowledge, conventional video analytic tools (both commercial and open-source) do not attempt to detect these high-level activities. This may be be-cause of the ambiguous task definitions or bebe-cause of the difficulty of detection these activities. Successful algorithm development for these applications would probably have to incorporate highly articulated models of human body and face motion, and would also have to track and catalog an individual’s actions long enough to establish a suspicious pattern of behavior.
6. Object Discrimination
In the broadest sense this technique encompasses any effort to distinguish between various object types within a video scene. Its sophistication and robustness is a strong driver of performance for certain detection capabilities, especially in the case of prevalent back-ground clutter within a scene. We focus on the ability to distinguish between human motion and vehicle mo-tion, and to separate instances of either from negligible background motion, since this form of discrimination is a particularly useful component for many scene interpretation tasks.
To test performance on the discrimination task, we again employed a COTS video analytic system, in-structing it to alarm whenever a moving object (human or vehicle) crossed over a specified line segment within each video scene. Since the video analytic system reports whether an alarm was triggered by a person or vehicle, we were able to tabulate a confusion matrix
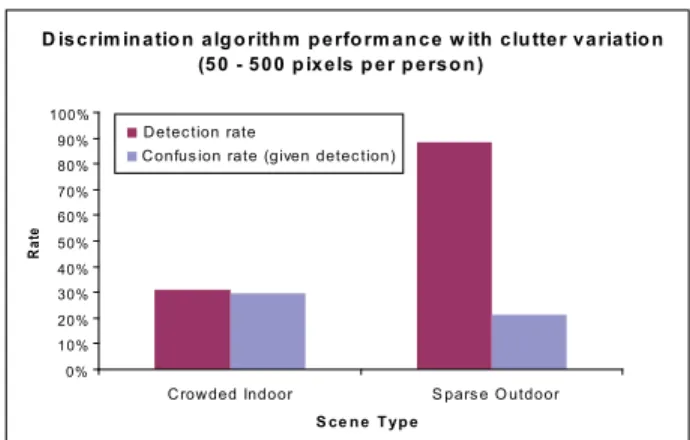
D is c rim in a tio n a lg o rith m p e rfo rm a n c e w ith c lu tte r v a ria tio n (5 0 - 5 0 0 p ix e ls p e r p e rs o n ) 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
C row ded Indoor S pars e O utdoor
S ce n e T yp e
Ra
te
D etec tion rate
C onfus ion rate (given detec tion)
Figure 3. Person/vehicle discrimination perfor-mance by moving clutter category.
associating person or vehicle line-crossing events with person or vehicle alarms. We extract two performance metrics from the confusion matrix: detection rate (i.e., the percentage of human or vehicle events that trig-gered any alarm), and confusion rate (i.e., the percent-age of detection cases for which the system confused humans and vehicles).
Figure 3 plots discrimination performance metrics for two environments with different moving clutter lev-els. As in low-level activity detection, we see a strong disparity in detection capability between crowded and sparse environments. The false negative rate increases with a rise in number of occlusions occurring within the scene. The confusion rate, however, seems to remain relatively constant despite changes in scene crowdedness. This suggests that crossing tracks of movers, though fundamental to detection, may be a lesser driver of discrimination performance.
Similarly, Figure 4 shows that a reduction in number of pixels-per-person (down to the 125-500 range) does not significantly alter the discrimination capability in the crowded indoor environment. Both detection rate and confusion rate show only slight reductions within crowded scenes as the number of pixels-per-person decreases, although we would expect performance to drop-off significantly at some point if we examined even smaller pixel-per-person ranges.
We observed the following common causes of diffi-culty for this task:
• Confusion cause: The primary metric for
discrim-ination between vehicles and humans was the aspect ratio of the mover. Thus the successful differentiation between the two groups was driven in part by whether or not the look angle of the camera distorted the aspect ratio of the movers within the scene.
Discrimination performance with resolution variation (Crowded indoor environments)
29% 24% 35% 31% 31% 36% 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% 500 - 2000 250 - 1000 125 - 500 R a n g e o f P ix e ls p e r p e rso n Ra te
C onfus ion rate (given detec tion) D etec tion rate
Figure 4. Person/vehicle discrimination perfor-mance by pixels-on-target range.
• Confusion cause: When segmentation is
imper-fect, groups of moving humans and persons toting luggage sometimes mirror the aspect ratio or contour shape of vehicles, leading to algorithm confusion.
• False negative cause: Poor contrast with
back-ground or high frequency of occlusions seemed to cause difficultly extracting movers from the background.
• False positive cause: Mechanical motion (such
as automatic doors sliding shut) was occasionally declared human motion by the algorithm. Based on these observations, we believe the following would be useful objectives for future algorithm devel-opment:
• Automatic correction for perspective distortion may improve performance, since this seems to affect some of the primary discrimination cues (aspect ratios, contours, etc).
• Incorporation of spatial-temporal texture cues: The assumption underlying this technique is that vehicles maintain more structural rigidity while in motion, while humans exhibit more variation due to moving limbs and changing pose. Furthermore, movement texture (as characterized by the spatial-temporal frequency domain) can more effectively distinguish human/vehicle motion from back-ground motion with unique frequency-domain signatures, such as crashing waves or trees blow-ing on the wind.
7. Tracking
Based upon desired capabilities for critical infras-tructure, we divide the tracking problem into three subproblems of escalating difficulty: tracking within a
7% 5% 43% 46% MCMC Results 58% 5% 6% 2% 29% Camshift Results Uninitiated Track
Track Loss due to Target Occlusion Track Loss due to Confuser
Track Loss due to Environmental Change Track Completed
Figure 5. Tracking results for each technique
single camera view, tracking and retrieval across multi-ple camera views, and full-site path reconstruction on a geo-spatial reference map. Existing video analytic systems mostly address the first subproblem, since relatively short-term tracking within a single camera view drives the interpretation of some specific activities like loitering and item abandonment.
7.1. Single camera tracking
We conducted some tests for single-camera track-ing, applying two algorithm implementations from the open-source community to sample testbed videos. The first tracking tool is an OpenCV implementation of the Continuously Adaptive Meanshift (Camshift) algorithm [12]. The second tracking tool is an OpenCV implementation of a Markov Chain Monte Carlo (MCMC) technique[13]. For testing, we selected 145 targets (both persons and vehicles) from four video scenes and applied both tracking algorithms described above. We specified the initial position of each tar-get within a particular frame as input to the track-ing algorithms. If the tracker successfully started the tracking process without immediately transitioning to background confusers, we counted it as an initiated track. If it tracked the target through to the end of the test sequence, we counted it as a successfully completed track. Track lengths in our test videos varied from a few seconds to a few minutes. Figure 5 displays the breakdown of tracking results for the Camshift and MCMC trackers, including several categories of observed causes for track loss.
In addition, Figure 6 plots performance metrics for the more effective tracker (MCMC) on the four
M C M C tra c k in g a lg o rith m p e rfo rm a n c e 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
Indoor crowded Indoor sparse Outdoor sparse
(winter conditions) S ce n e T yp e S u ccess R at e
Initiated Trac k s C om pleted Trac k s
Outdoor sparse (clear conditions)
Figure 6. Tracking performance of MCMC algo-rithm across different environments.
test video environments. Other than in the snow-covered environment, performance remains somewhat consistent. However, track completion rates experience some degradation due to scene crowdedness in the indoor setting. The results in outdoor winter conditions are significantly worse because of markedly lower contrast (due to reduced levels of sunlight). Commonly observed tracking failure modes included:
• Unsuccessful track acquisition: Targets with
low-intensity color profiles, often caused by dark clothing, proved problematic for the Camshift technique. It could not achieve target acquisition when it lacked the color to build a stable color histogram.
• Target occlusion: The trackers sometimes lost
targets undergoing heavy occlusion by other com-ponents in the scene. In these failure cases, the tracker could not recover, terminating the track prematurely.
• Track switch to a confuser: The trackers would
sometimes switch over and track confusers, or other parts of the scene with sufficiently similar appearance to the target. Confusers included other moving people and vehicles as well as stationary background components.
• Environmental changes: Changes in outdoor
light-ing due to clouds or weather, as well as indoor illumination changes, caused some track losses for the Camshift technique.
In general, tracking algorithms search for a consensus between motion models and appearance models. The tracking algorithms we tested experienced a significant number of track losses to confusers, even when the target maintained consistent motion. As a result, we may expect an improvement in performance if we use trackers with more of an emphasis on strong motion
models rather than adaptive appearance models that fit to other scene components too easily.
7.2. Multi-camera tracking and path
recon-struction
The problem of multi-camera tracking introduces a considerable number of additional difficulties beyond those in the single-camera tracking problem. For one thing, there may be significant variation of human or vehicle appearance from one camera view to another. This is due to potential differences in resolution, view-ing angle, and imagview-ing properties between cameras. In addition, if the cameras do not overlap, the tracker must disregard or use only weak motion models to associate tracks between views. Finally, tracking a person or vehicle across an entire critical infrastructure site requires maintaining tracks over larger spatial areas and periods of time, increasing the volume potential confusers.
Path reconstruction requires not only success-ful multi-camera tracking but also geo-registration and path interpolation. Geo-registration requires each camera to map the coordinate system of its two-dimensional image plane into a common coordinate system in the three-dimensional world, so that the target path can be traced on a shared reference map. This mapping typically requires prior knowledge about the location of the ground plane relative to the camera and becomes unstable at far-field viewing angles. In addition, when camera coverage is not complete, parts of the target path will be missing; therefore, complete path reconstruction requires that the video analytic system fill in the gaps with some sort of path esti-mation algorithm. Although commercial systems are beginning to address these trickier tracking problems, the capabilities of this technology remain less than robust in operational settings.
8. Video Content Retrieval
The objective for this class of capabilities is the intelligent retrieval of video samples from archived video based on user queries. Because it is computa-tionally impractical to re-process large sets of archived video every time a user query is issued, these systems must instead process video as it is captured and store useful meta-data, or content tags, on which to perform searches. Consequently, content retrieval systems must address three fundamental problems: how to interpret video content as it arrives, how to form meta-data for storage of this content, and how to process (preferably semantic) user queries about content.
Solutions to the first problem are limited by the capabilities of real-time video analytic processing. Techniques for meta-data formation must deal with a trade-off between the size of the extracted data and its expressiveness; systems which store too many low-level details require more storage space and slower search times, while systems that store more compact descriptors discard potentially valuable information. Finally, the format for queries is important because they must be user-friendly and capable of expressing the desired search criteria.
Some systems also store meta-data related to the appearance of standard object classes (e.g., persons, vehicles, boats, or faces) in support of queries re-questing all instances of one of these classes within a spatial or temporal window. While video indexing based on object classes is not perfect, this capability has improved significantly within the last decade due to active research, as evidenced by the TRECVID and Video Analysis and Content Extraction (VACE)[14] evaluations. In summary, existing systems can handle basic query structures using a limited set of pre-defined object classes and modifiers.
9. Summary
Existing video analytic technology offers some use-ful tools for critical infrastructure security, although it does not yet achieve all of the capabilities desired by security personnel. Video analytics software can reliably recognize certain types of low-level activities when the scene characteristics facilitate successful op-eration. However, specific activity detection becomes less than reliable when the scene contains a high vol-ume of moving clutter or when the activity-of-interest is defined by more complicated interactions between persons, limbs, vehicles, or objects (e.g., a person breaking a car window). Current systems can also achieve some degree of discrimination and tracking ca-pabilities, although these are error-prone. For security purposes, particularly useful developments in video an-alytics technology would include the following: basic interpretation of behavioral cues, robust discrimination between humans and non-humans (especially in far-field views), and facility-wide multi-camera tracking and path reconstruction.
References
[1] J. Vlahos, “Surveillance society: New high-tech cam-eras are watching you,” Popular Mechanics, January 2008.
[2] N. Gagvani, “Challenges in video analytics,” in Ad-vances in Pattern Recognition: Embedded Computer Vision, 2008, ch. 12, pp. 237–256.
[3] A. Smith, “Ti, others see potential for smart video security systems.”
[4] M. Ferryman, Ed., Proceedings of IEEE International Workshop on Performance Evaluation of Tracking and Surveillance (PETS), 2007. [Online]. Available: http://pets2007.net/
[5] A. Smeaton, P. Over, and W. Kraaij, “High-level feature detection from video in trecvid: A 5-year retrospective of achievements,” in Multimedia Content Analysis, The-ory and Applications, 2009, pp. 151–174.
[6] C. Anagnostopoulos, I. Anagnostopoulos, I. Psoroulas, and V. Loumos, “License plate recognition from still images and video sequences: Asurvey,” IEEE Trans-actions on Intelligent Transportation Systems, vol. 9, no. 3, pp. 377–391, 2008.
[7] D. Tao, X. Li, X. Wu, and S. Maybank, “General tensor discriminant analysis and gabor features for gait recognition,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 29, no. 10, pp. 1700– 1715, 2007.
[8] P. Phillips, “Overview of the multiple biometric grand challenge,” in MBGC Workshop, 2009. [Online]. Available: http://face.nist.gov/mbgc/
[9] G. Bradski and A. Kaehler, Learning OpenCV: Com-puter Vision with the OpenCV Library. OReilly Press, 2008.
[10] D. Thirde, L. Li, and J. Ferryman, “An overview of the pets 2006 dataset,” in Proceedings of IEEE International Workshop on Performance Evaluation of Tracking and Surveillance (PETS 2006), 2006, pp. 47– 50.
[11] S. Donnelly, “A chastened airport watches for suspects,” Time Magazine, August 2003.
[12] D. Comaniciu, V. Ramesh, and P. Meer, “Real-time tracking of non-rigid objects using mean shift,” in Pro-ceedings of the IEEE Conferenceon Computer Vision and Pattern Recognition (CVPR), 2008.
[13] S. Zhou, R. Chellappa, and B. Moghaddam, “Visual tracking and recognition using appearance-adaptive models in particle filters,” IEEE Transactions on Image Processing, vol. 11, pp. 1434–1456, 2004.
[14] V. Manohar, M. Boonstra, V. Korzhova, P. Soundarara-jan, D. Goldgof, R. Kasturi, S. Prasad, H. Raju, R. Bowers, and J. Garofolo, “Pets vs. vace evaluation programs: A comparative study,” in Proceedings of IEEE International Workshop on Performance Evalu-ation of Tracking and Surveillance (PETS), 2006.