HDclassif: an R Package for Model-Based Clustering and Discriminant Analysis of High-Dimensional Data
Texte intégral
Figure



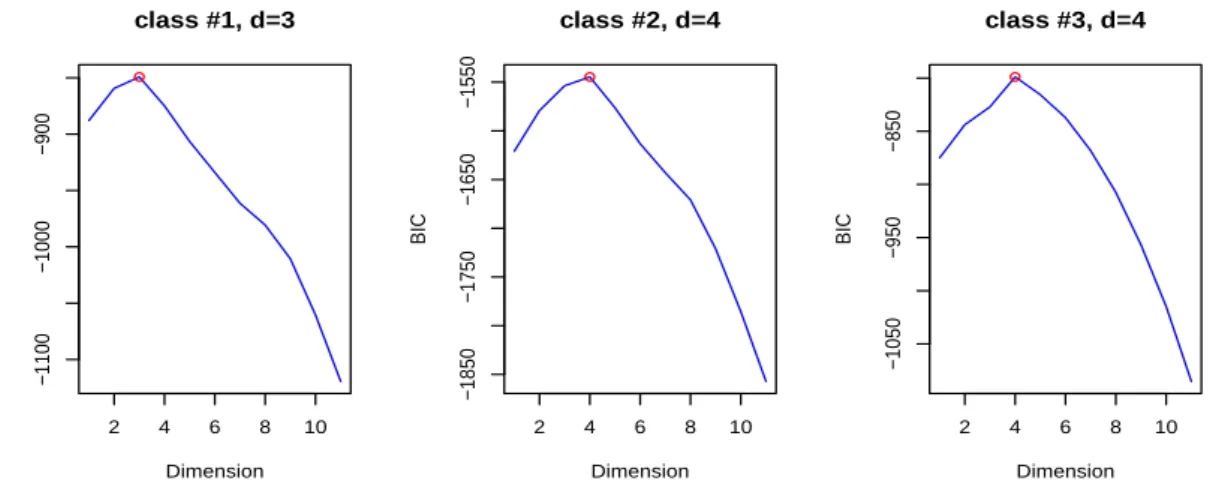
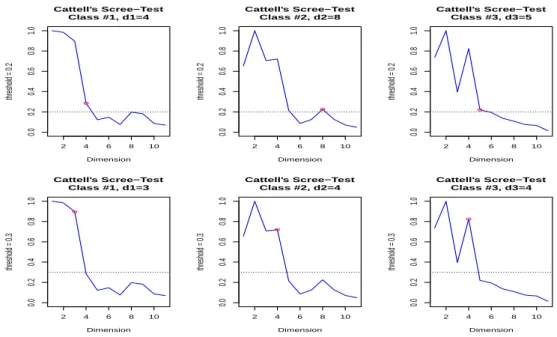


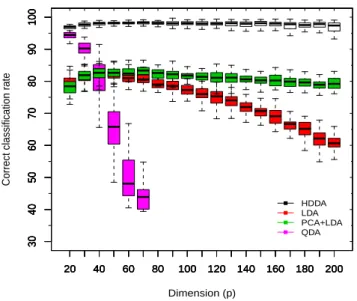
![Figure 8: Effect of the dimension on correct classification rates on simulated data with the functions hddc (model [a k b k Q k d k ]) and Mclust (models VVV, VVI and EEI)](https://thumb-eu.123doks.com/thumbv2/123doknet/13408930.406957/23.892.131.769.223.831/figure-effect-dimension-correct-classification-simulated-functions-mclust.webp)

Documents relatifs
After having recalled the bases of model-based clustering, this article will review dimension reduction approaches, regularization-based techniques, parsimonious modeling,
The R package blockcluster allows to estimate the parameters of the co-clustering models [Govaert and Nadif (2003)] for binary, contingency and continuous data.. This package is
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
The standard model for lustering observations desribed through ategorial variables is the so-alled latent lass model (see.. for instane
HDclassif: An R Package for Model-Based Clustering and Discriminant Analysis of High-Dimensional Data.. Laurent Bergé, Charles Bouveyron,
Three versions of the MCEM algorithm were proposed for comparison with the SEM algo- rithm, depending on the number M (or nsamp) of Gibbs iterations used to approximate the E
The ZIP employ two different process : a binary distribution that generate structural
In order to investigate the effect of the sample size on clustering results in high- dimensional spaces, we try to cluster the data for different dataset sizes as this phenomenon
