On-Line Learning of Lexical Items and Grammatical Constructions via Speech, Gaze and Action-Based Human-Robot Interaction
Texte intégral
Figure

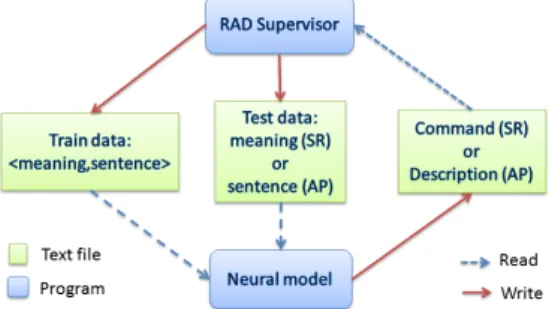
Documents relatifs
Other approaches try to use qualitative reasoning systems instead of the low level detailed representation to capture the functional behavior of design
When an agent interacts with a frequency similar to the learned one, weights (that are already learnt on modifi- able links) are associated with the visual activities induced by
To effectively learn to imitate posture (see Figure 1) and recognize the identity of individuals, we employed a neural network architecture based on a sensory-motor association
5 Within the semantic unfragmented whole constituted by the notion of X and its reference to the type <be X>, which is viewed as being continuous, the speaker may
حب اءدب ةيلمعلا لولحلا عابتاب هتسايس رييغت رملأا ىضتقاف رطخأ رض و لمع لاكشأ ءوسأ هذه نكل .اهيلع يئاهنلا ءاضقلا فدهب لافطلأا » ةيتامغاربلا « 537
Based on the aforementioned evidence for the role of gaze direction in social interactions, we consider a human-avatar mirror game where the avatar provides the human follower with
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
Its cross reactivity with other analyzed species has allow us to identify new cellular localizations for other members of the XMAP215 family members of proteins
