Adaptive behaviour and feedback processing integrate experience and instruction in reinforcement learning
Texte intégral
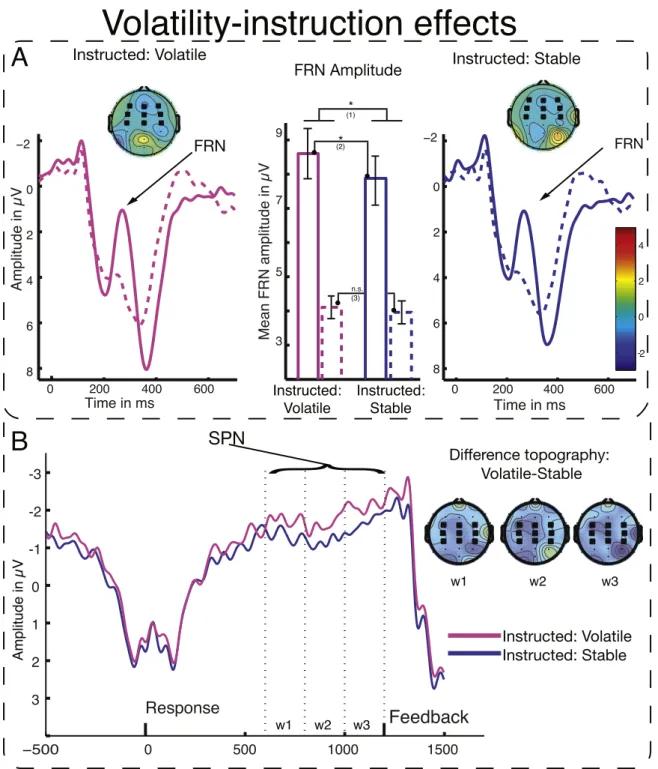
Figure



Documents relatifs
We modelled a document treatment chain which extracts events from web pages and other open source documents as a Markov Decision Process, and solved it using reinforcement
We expect our AI to learn to construct chains that eventually perform as well as this expert chain, learning not only the correct order of the services and the best parameters, but
In this context, we show that the optimal choice of direct investment is explained by an investment condition; the firm uses and exploit his ownership
negative RPE amplitude between instruction conditions in trials preceding rule 781.. Low-level unexpectedness is therefore unlikely to
Kassara, Feedback spreading control laws for semilinear distributed parameter systems, Systems Control Lett., 40 (2000), pp.. Lions, Optimal Control of Systems Governed by
ImpUcations for control. Some aspects of the motor organlzatlon of the oculomotor system. Parallels and interactions in ocular and manual performance. Quarterly Journal
In particular, existence of a local, codimen- sion two Chenciner bifurcation of the steady state, with the sign restriction γ 1 < 0 in the normal form (19), implies a
A synthetic map (Fig. 1b) based on the geophysical results obtained by magnetometry and electromagnetic induction (EMI) demonstrates a cross positioning problem. It appears that
