(^
: '*^'—w.'i^y
HD28
.M414
Context
Interchange:
Representing
and Reasoning
about
Data
Semantics
in
Heterogeneous
Systems
Cheng
Hian
Goh, Stephane
Bressan,
Stuart
E.Madnick,
Michael
D.
SiegelSloan
WP#
3928
CISL
WP#
96-06
December
1996
The
Sloan
School
of
Management
Massachusetts
Instituteof
Technology
Cambridge,
MA
02142
Context
Interchange:
Representing
and
Reasoning about
Data
Semantics
in
Heterogeneous
Systems*
Cheng
Hian
Goh^
Stephane
Bressan
Stuart
E.Madnick
Michael D.
SiegelSloan School
ofManagement
Massachusetts
Institute ofTechnology
Email:
{chgoh,sbressan,smadnick,msiegel}@mit.edu
December
5,1996
Abstract
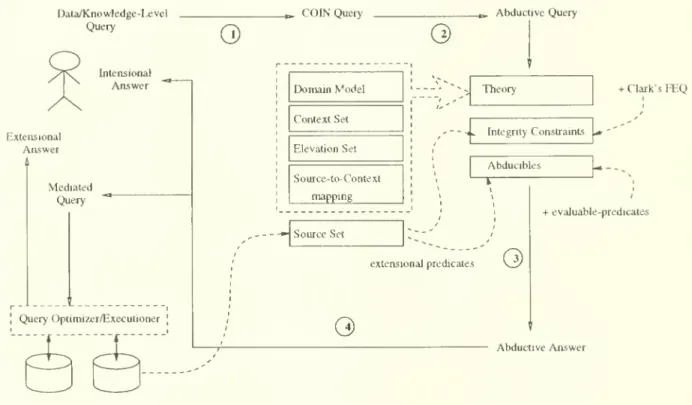
The
context iNterchange (coin) strategy [44; 48] presents a novel perspectiveformedi-ateddataaccessinwhich semanticconflicts
among
heterogeneoussystems arenotidentifiedapriori,but aredetectedand reconciled bya ContextMediator through comparisonof
con-texts associated with any two systemsengaged in dataexchajige. In this paper,
we
presentaformalcharacterization and reconstruction ofthis strategyinaCOINframework, basedon
adeductive object-orienteddatamodel andlanguagecalled COIN.
The
COIN framework pro-vides alogicalformalism forrepresenting data semantics indistinct contexts.We
show
thatthispresentsa well-founded basisfor reasoningaboutsemantic disparitiesin heterogeneous
systems. In addition, it combines the best features of loose- and tight-coupling approaches
in defining an integration strategy that is scalable, extensible and accessible. These latter
features are
made
possible by allowingcomplexity ofthe system to be harnessed in smallchunks, byenabling sources and receivers to remaiin loosely-coupled tooneanother,and by
sustaining an infrastructurefor dataintegration.
Keywords:
Context, heterogeneous databfises, logic and databases, mediators, semanticinteroperability.
'Thisworkissupportedinpartby
ARPA
andUSAF/Rorae
Laboratoryundercontra£tF30602-93-C-0160, theInternationaJ Financial ServicesResearchCenter (IFSRC),cindthePROductivity From Information Technology
(PROFIT) project at MIT.
1
Introduction
The
last fewyearshave
witnessedan unprecedented growth
inthenumber
ofinformationsources(traditional database systems,
data
feeds, web-sites,and
applications providing structured orsemi-structured
data
on
requests)and
receivers(human
users, data warehouses,and
applica-tions that
make
data
requests). This is spurredon
by
anumber
of factors: for example, easeof access to the Internet,
which
isemerging
as the de facto global information infrastructure,and
the rise ofnew
organizational forms (e.g., adhocraciesand
networked organizations [36]),which
mandated
new
ways
ofsharingand
managing
information.The
advances in networkingand
telecommunications technologies have led to increased physical connectivity (the abilityto
exchange
bitsand
bytes), but not necessarily logical connectivity (the ability toexchange
information meaningfully).
This problem
is traditionally referred to as theneed
for semanticinteroperability [47]
among
autonomous
and
heterogeneous systems.1.1
Context
Interchange:
Background
The
goal of thispaper
is to describe a novel approach, called Context Interchange (coin),for achieving semantic interoperability
among
heterogeneous sourcesand
receivers.The
COIN
strategy described in this
paper
drew
its inspirationfrom
earlierwork
reported in [48; 44].Specifically,
we
share the basic tenets that• the detection
and
reconciliation of semantic conflicts axesystem
serviceswhich
arepro-vided
by
a Context Mediator,and
shouldbe
transparent to a user;and
• the provision of such a mediation service requires only that the user furnish a logical
(declarative) specification of
how
data are interpreted in sourcesand
receivers,and
how
conflicts,
when
detected, should be resolved,but
notwhat
conflicts exists a prioribetween
any two
systems.These
insights axe novelbecause
they depaxtfrom
classical integration strategieswhich
ei-ther require users to
engage
in the detectionand
reconciliation of conflicts (in the case ofloosely-coupled systems; e.g.,
MRDSM
[33],VIP-MDBMS
[29]), or insist that conflicts shouldbe
identifiedand
reconciled, a priori,by
some
system
administrator, inone
ormore
sharedschemas
(as in tightly-coupled systems; e.g.,Multibase
[30],Mermaid
[49]).Unfortunately, as interesting as these ideas
may
be, they couldremain
asvague musings
in the absence of a formal conceptual foundation.
One
attempt
at identifying a conceptualbe
fraughtwith
ambiguity. For example, it reliedon
implicitagreement
on
what
the modifiersfor different attributes are, as well as
what
conversion functions axe applicable for differentkinds of conflicts,
and
is silenton
how
different conversion definitionscan
be
associated withdistinct contexts. Defining the semantics of
data through
annotations attached to individualdata elements tend also to
be cumbersome, and
there isno
systematicway
ofpromoting
thesharing
and
reusing of the semantic representations.At
thesame
time, the representationalformalism
remains
somewhat
detachedfrom
the underlying conflict detection algorithm (thesubsumption
algorithm [48]).Among
other problems, this algorithm requires conflict detection tobe done
on
a pairwise basis (i.e.,by comparing
the context definitions fortwo
systems at atime),
and
isnon-committal
on
how
aquery
planfor multiplesources canbe
constructed basedon
the sets of pair-wise conflicts. Furthermore, the algorithm limits meta-attributes to only asingle-level (i.e., property lists
cannot
be
nested),and
are not able to takeadvantage
ofknown
constraints for
pruning
offconflictswhich
are guaranteed never to occur.1.2
Summary
of
Contributions
We
havetwo
(intertwined) objectives in thispaper. First,we aim
toprovidea
formalfoundationfor the
Context
Interchange strategy that will not only rectify theproblems
described earlier,but
alsoprovide foran
integrationofthe underlyingrepresentationaland
reasoning formalisms.Second, the deconstruction
and
subsequentreconstruction^ oftheContext
Interchangeapproach
described in [48; 44] provides us with the opportunity to address the concern for integration
strategies that are scalable, extensible
and
accessible.Our
formal characterization of theContext
Interchange strategy takes theform
ofaCOIN
framework,
based
on
theCOIN
data model,which
is acustomized
subset of the deductiveobject-oriented
model
calledGulog^
[15].coin
is a "logical"data
model
in the sense that ituses logicas a
formalism
for representingknowledge and
for expressingoperations.The
logicalfeatures of
coin
provide us with a well-founded basis formaking
inferencesabout
semanticdisparities that exist
among
data
indifferent contexts. In particular, acoin
framework
canbe
translated toa
normal program
[34] (equivalently, aDatalog^^^program)
forwhich
thesemanticsis well-defined,
and where sound computational
procedures forquery answering
exist. Sincethere is
no
real distinctionbetween
factual statements (i.e.,data
in sources)and
knowledge
(i.e., statements
encoding data
semantics) in this logicalframework,
both
querieson data
sources [data-level queries) as well as queries
on
data semantics [knowledge-level queries) canIn this dixonstmction, we tease apcirt different elementsofthe Context Interchange strategy with thegocil
ofunderstanding their contributions individually and collectively. The reMnstntction examines how the same
features(and more) can be accomplisheddifferently within theformalism wehave invented.
be
processed inan
identicalmanner.
As
an
alternative to the classic deductive framework,we
investigate the adoption ofan
abductiveframework
[27] for query processing. Interestingly,although
abduction and
deductionare "mirror-images" ofeach other [14], the abductive answers,computed
using a simple extension to classic SLD-resolution leads to intensional answers asopposed
to extensionalanswers
thatwould be
obtained via deduction. Intensionalanswers areuseful in our
framework
fora
number
ofconceptualand
practical reasons. Inparticular, ifthequery
is issuedby a
"naive" userunder
theassumption
that there areno
conflicts whatsoever,theintensional
answer
obtainedcan be
interpreted asthe corresponding mediated queryinwhich
database accesses are interleaved with data transformations required for mediating potential
conflicts. Finally,
by
checking the consistency oftheabducted
answers againstknown
integrityconstraints,
we show
that theabducted answer can be
greatly simplified,demonstrating
aclearconnection to
what
is traditionallyknown
as semantic query optimization [7].As
much
as it is a logical data model,COIN
is alsoan
"object-oriented"data model
be-cause it adopts
an
"object-centric" view ofthe worldand
supportsmany
ofthe features (e.g.,object-identity, type- hierarchy, inheritance,
and
overriding)commonly
associated withobject-orientation.
The
standard use of abstraction, inheritance, as well as structuraland
behavioralinheritance [28] present
many
opportunitiesfor sharingand
reuse of semantic encodings.Con-versionfunctions (for transforming therepresentation of
data between
contexts)can
be modeled
as
methods
attached to types in a natural fashion. Unlike "general purpose" object-orientedformalisms,
we
make
some
adjustments
tothestructure ofourmodel by
distinguishingbetween
different kinds of objects
which have
particular significance forourproblem domain.
In partic-ular,we
introducethe notion of context-objects, described in [37], as reified representations forcollectionsofstatements
about
particular contexts.This
allows contextknowledge
tobe
definedwith a
common
reference pointand
is instrumental in providing a structuringmechanism
formaking
inferences across multiple theorieswhich
may
be mutually
inconsistent.The
reconstruction of theContext
Interchange strategy allows us to gobeyond
theclas-sical concern of "non-intrusion",
and
provides a formulation that is scalable, extensibleand
accessible [21].
By
scalability,we
require that the complexity of creatingand
administering(maintaining) the interoperationservices should not increase exponentially
with
thenumber
ofparticipatingsources
and
receivers. Extensibility refersto the ability to incorporate changes ina
gracefulmanner;
in particular, local changes should nothave
adverse effectson
other partsof the larger system. Finally, accessibility refers to
how
thesystem
is perceivedby
a user interms
ofits ease-of-useand
flexibility insupporting different kinds of queries.strategy^. Provisions for msiking sources
more
accessible to users isaccomplished
by
shiftingthe
burden
for conflict detectionand
mediation to the system; supporting multipleparadigms
for
data
accessby
supporting queries formulated directlyon
sources as well as queriesmedi-ated
by
views;by
making
knowledge
ofdisparate semantics accessible to usersby
supportingknowledge-level queries
and
answering
with intensional answers;and
by
providing feedback inthe
form
ofmediated
queries. Scalabilityand
extensibility are addressedby
maintaining thedistinction
between
the representation of data semantics as isknown
in individual contexts,and
the detection of potential conflicts thatmay
arisewhen
data areexchanged between two
systems;
by
thestructuralarrangement
that allowdata
semanticstobe
specified withreferenceto
complex
object types in thedomain
model
asopposed
to annotations tightly-coupled in theindividual
database
schemas;by
allowing multiple systemswith
distinctschemas
tobind
tothesame
contexts;by
the judicious use of object-oriented features, in particular, inheritanceand
overriding in the type
system
present in thedomain
model;and by
sustainingan
infrastruc-turefor
data
integration thatcombines
these features.As
aspecial effort in providing suchan
infrastructure,
we
introduce a meta-logical extension oftheCOIN
framework which
allows setsofcontext
axioms
tobe
"objectified"and
placed ina hierarchy, such thatnew
and
more
com-plex contexts
can
be
derived tlirough ahierarchical composition operator [5]. Thismechanism,
coupled
with
type inheritance, constitutesa
powerfulapproach
for incorporating changes (e.g.,the additionof a
new
system, or changes to thedomain
model)
in agracefulmanner.
Finally,
we
remark
that thefeasibilityand
featuresofthisapproach have
been demonstrated
in a prototype
implementation
which
providesmediated
access to traditional database systems(e.g., Oracle databases) as well as semi-structured
data
(e.g.. Web-sites)^.1.3
Organization
of
this
Paper
The
rest ofthispaper
isorganized as follows. Followingthis introduction,we
present amotiva-tional
example which
is used to highlight selected features oftheContext
Interchange strategy.We
demonstrate
in Section 3 the novelty of ourapproach by comparing
it with a variety ofother classical
and
contemporary
approaches. Section 4 describes the structureand
languageofthe
COIN
data model,which forms
the basis for the formal characterization of theContext
Interchange strategy in a
COIN
framework.
Section 5 introduces the abduction fram,eworkand
illustrates
how
abductive inference is used as the basis for obtaining intensional answers,and
in particular, mediated
answers
corresponding to naive queries (i.e., those formulated whileFor thesakeof brevity, further references
made
totheContextInterchange strategyfrom thispointonrefersto this recon.struction unlessotherwise specified.
This prototypeisaccessiblefrom any
WWW-client
(e.g., NetscapeBrowser) andcan be demonstrated uponassuming
that sources arehomogeneous).
Section 6 describes a meta-logical extension to theCOIN framework which
allows changes tobe
incorporated in agracefulmanner.
Section 7de-scribes the prototype
system which
provides integrated access toa
variety of heterogeneoussources while
adopting
theframework which
we
have
described.We
concludein Section 8 witha
number
ofsuggestions for further work.2
Motivational
Example
Consider the scenario
shown
in Figure 1, deliberately kept simple for didactical reasons.Data
on
"revenue"and
"expenses" (respectively) forsome
collection ofcompanies
are available intwo autonomously-administered
data sources, eachcomprised
of a single relation^.Suppose
a user is interested in
knowing
which companies have been
"profitable"and
their respectiverevenue: this
query can be
formulated directlyon
the (export)schemas
of thetwo
sources asfollows^:
Ql:
SELECT
rl.cname,
rl.revenue
FROM
rl,r2
WHERE
r1.cname
=r2.cname
AND
rl.revenue
>
r2.expenses;
In the absence of
any
mediation, this query will return theempty
answer
ifit is executed overthe extensional
data
setshown
in Figure 1.The
above
query, however, does not take intoaccount thefact thatdata
sources cireadmin-istered independently
and have
different contexts: i.e., theymay embody
differentassumptions
on
how
information contained therein shouldbe
interpreted.To
simplify the ensuingdiscus-sion,
we assume
that thedata
reported in thetwo
sources differ only in the currenciesand
scale-factors of"company
financials" (i.e., financial figures pertaining to the companies,which
include
revenue
and expenses).
Specifically, inSource 1, all"company
financials" arereportedusingthe currency
shown
and
ascale-factor of1; the only exception iswhen
they are reportedin
Japanese
Yen
(JPY); inwhich
case the scale-factor is 1000. Source 2,on
the other hand,reports all
"company
financials" inUSD
using ascale-factor of 1. In the light oftheseremarks,'Throughoutthispaper,we
make
theassumptionthat therelationcil datamodelisadoptedtobethe canonicaldatamodel [47]: i.e.,weassumethatthedatabaseschemas exported bythe sourcesare relationalandthatqueries
areformulated using
SQL
(orsomeextension thereof). Thissimplifiesthe discussionby allowingusto focusonsemantic conflicts in disparate systems without being detracted by conflicts over data model constructs. The
choice ofthe relational data model is oneofconvenience rather than necessity, and is not tobe construedas a
constraint oftheintegration strategy being proposed.
®We
assume, without loss of generality, that relation ncimes are unique across all data sources. This can always be accomplished viasome renamingscheme: say, by prefixing relationname
with thename
ofthe dataContext
c.Alt "companyftnancials"("revenue"inclusive)are reported
inthecurrencyshownforeachcompany
Alt "companyftnancials" are reported usingascale-factorof1
except foritems reportedinJPY, wherethe
scale-factoris1000 rl cname revenue IBM NTT 1 000 000 1 000 000 currency USD JPY SourceI
Context
c,2
All"companyftnancials"are reportedinUSD, usingascale-factorof1
Query
select rl.cname, rl.revenue
from rl, r2
where rl.cname = r2.cname
and rl.revenue > r2.expenses
User
r2 cname
necessarily
being
precise at all times; formal definitionsofthe underlying representationaland
inference formalisms are
postponed
to Sections 4, 5,and
6 ofthis paper.2.1
Functional Features
of
Context
Interchange:
A
User
Perspective
Unlikeclassical
and
contemporary
approaches, theContext
Interchangeapproach
providesuserswith a
wide
array ofoptionson
how
and what
queriescan
be
askedand
the kinds of answerswhich can be
returned.These
featureswork
intandem
to allow greaterflexibilityand
effective-ness in gaining access to information present in multiple, heterogeneous systems.
Query
Mediation:
Automatic
Detection
and
Reconciliation of Conflicts
In a
Context
Interchange system, thesame
query (Ql) canbe submitted
to a specializedmediator [54], called a Context Mediator,
which
rewrites thequery
so that dataexchange
among
siteshaving
disparate contexts axe interleaved with appropriatedata
transformationsand
access to ancillarydata
sources(when
needed).We
refer to this transformation as querymediation
and
the resultingquery
as the corresponding mediated query.For example, the
mediated
queryMQl
corresponding toQl
is given by:MQl:
SELECT
rl.cname,
rl.revenue
FROM
rl,r2
WHERE
rl.currency
=
'USD'AND
rl.cname
=
r2.cnaineAND
rl.revenue
>
r2.expenses;
UNION
SELECT
rl.cname,
rl.revenue
*1000
* r3.rate
FROM
rl, r2,r3
WHERE
rl.currency
=
'JPY'AND
rl.cname
=
r2.cname
AND
rS.fromCur
=
rl.currency
AND
rS.toCur
=
'USD'AND
rl.revenue
*1000
*rS.rate
>
r2.expenses
UNION
SELECT
rl.cname,
rl.revenue
*rS.rate
FROM
rl, r2,r3
WHERE
rl.currency
<>
'USD'AND
rl.currency
<>
'JPY'AND
r3.fromCur
=
rl.currency AND
rS.toCur
=
'USD'AND
rl.cname
=
r2.cname
AND
rl.revenue
* r3.rate
>
r2.expenses;
This
mediated query
considers all potential conflictsbetween
relations rland r2
when
com-paring values of "revenue"
and
"expenses" as reported in thetwo
different contexts. Moreover,the
answers
returnedmay
be
further transformed so that theyconform
to the context of thereceiver.
Thus
in ourexample,
the revenue ofNTT
willbe
reported as 9600 000
asopposed
to 1000
000.More
specifically, the three-part queryshown
above can be understood
as follows.The
firstsubquery
takes care of tuples forwhich
revenue is reported inUSD
using scale-factor1; in this case, there is
no
conflict.The
secondsubquery
handles tuples forwhich
revenue isreported in JPY, implying a scale-factor of 1000. Finally, the last
subquery
considers the casewhere
the currency is neitherJPY
nor USD, inwhich
case only currency conversion is needed.Conversion
among
different currencies is aidedby
the ancillary data sourcer3
which
providescurrency conversion rates.
This
second query,when
executed, returns the "correct"answer
consisting only ofthe tuple
<
'NTT', 9600
000>.
Support
forViews
In the preceding
example,
thequery
Ql
is formulated directlyon
the exportschema
for thevarious sources.
While
this provides a great deal of flexibility, it also requires users toknow
what
data
arepresentwhere
and be
sufficientlyfamiliarwith the attributes indifferentschemas
(so as to construct a query).
A
simpleand
yet effective solution to theseproblems
is to allowviews to
be
definedon
the sourceschemas
and have
users fornmlate queriesbased on
the viewinstead. For example,
we
might
definea viewon
relationsrl
and
r2, givenby
CREATE VIEW
vl(cname,
profit)
ASSELECT
rl.cname,
rl.revenue
- r2.expenses
FROM
rl, r2WHERE
rl.cname
= r2.cname;
In
which
case,query
Ql
can be
equivalently formulatedon
theview
vl asVQl:
SELECT
cname,
profit
FROM
vlWHERE
profit
>
0;While
achieving essentially thesame
functionalities as tightly-coupled systems, notice thatview
definitions inour case areno
longer concerned with semantic heterogeneityand
mcike noattempts at identifying or resolving conflicts. In fact,
any query
on
aview
(say,VQl
on
vl)can
be
trivially rewritten to aquery
on
the sourceschema
(e.g., Ql).This
means
that querymediation can
be undertaken by
theContext
Mediator
as before.Knowledge-Level
versus
Data-Level Queries
Instead of inquiring
about
stored data, it issometimes
useful tobe
able toquery
thesemanticsof data
which
are implicit in different systems. Consider, for instance, thequery based
on
asuperset of SQL*^:
Sciore et aJ. [43] havedescribed a similar (but not identical) extension of
SQL
in which context is treatedQ2:
SELECT
rl.cname,
rl.revenue.
scaleFactor
IN cl,rl.
revenue.
scaleFactor
IN c2FROM
rlWHERE
rl.revenue.
scaleFactor
IN cl <> rl.revenue.
scaleFactor
IN c2;Intuitively, this
query
asks forcompanies
forwhich
scale-factors for reporting "revenue" in rl(in context cl) differ
from
thatwhich
the userassumes
(in context c2).We
refer to queriessuch as
Q2
as knowledge-level queries, asopposed
to data-level querieswhich
are enquireson
factual data present in
data
sources. Knowledge-level queries have received little attention inthe database literature
and
certainly have notbeen
addressedby
the data integrationcommu-nity. This, in our opinion, is a significant
gap
since heterogeneity in disparate data sourcesarises primarily
from
incompatibleassumptions
about
how
data
are interpreted.Our
abilityto integrate access to
both data
and
semanticscan
be
exploitedby
users to gain insights intodifferences
among
particular systems("Do
sourcesA
and
B
report a pieceofdata
differently?If so, how?"), or
by
aquery
optimizerwhich
may
want
toidentify siteswith minimal
conflictinginterpretations (to
minimize
costs associated withdata
transformations).Interestingly, knowledge-levelqueries
can be answered
usingthe exactsame
inferencemech-anism
formediating
data-level queries. Hence, submittingquery
Q2
to theContext Mediator
will yield the result:
MQ2:
SELECT
rl.cname,
1000, 1FROM
rlWHERE
rl.currency
= 'JPY';which
indicates that theanswer
consists ofcompanies
forwhich
the currency attribute hasvalue 'JPY', in
which
case the scale-factors in context cland
c2 are1000 and
1 respectively.Ifdesired, the
mediated query
MQ2
canbe
evaluatedon
the extensionaldata
set to returnan
answer
grounded
in actualdata
elements. Hence, ifMQ2
is evaluatedon
thedata
setshown
inFigure 1,
we
would
obtain the singletonanswer
<'NTT',
1000, 1>.Extensional versus
Intensional
Answers
Yet
another feature ofContext
Interchange is thatanswers
to queriescan
be both
intensionaland
extensional. Extensional answers correspond to fact-setswhich one
normally expects ofa database retrieval. Intensional answers,
on
the other hand, provide only a characterizationof the extensional
answers
without actually retrievingdata from
thedata
sources. In thepreceding
example,
MQ2
can in factbe understood
asan
intensionalanswer
for Q2, while thetupleobtained
by
the evaluation ofMQ2
constitutes the extensionalanswer
forQ2.
In the
COIN
framework,
intensional answers aregrounded
in extensional predicates (i.e.,names
ofrelations), evaluablepredicates (e.g., arithmetic operators or "relational" operators),and
external functionswhich can be
directly evaluatedthrough
system
calls.The
intensionalanswer
is thusno
differentfrom
a querywhich can
normallybe
evaluatedon
a conventionalquery
subsystem
ofaDBMS.
Query
answering
in aContext
Interchangesystem
is thus atwo-step process:
an
intensionalanswer
is first returned in response to a user query; thiscan
thenbe
executedon
a conventionalquery subsystem
to obtain the extensional answer.The
intermediary intensionalanswer
serves anumber
of purposes [24]. Conceptually, itconstitutes the
mediated query
correspondingtothe userquery
and can be
used toconfirm theuser's
understanding
ofwhat
thequery
actually entails.More
oftenthan
not, the intensionalanswer
can be
more
informativeand
easier tocomprehend compared
to the extensionalanswer
it derives. (For
example,
the intensionalanswer
MQ2
actually conveysmore
information thanmerely returning the single tuple satisfying the query.)
From
an
operational standpoint, thecomputation
ofextensional answers are likely tobe
many
orders ofmagnitude
more
expensivecompared
to the evaluation of the corresponding intensional answer. It thereforemakes
good
sense not to continue with
query
evaluation ifthe intensionalanswer
satisfies the user.From
apractical standpoint, this two-stage process allows us to separate
query mediation from
queryoptimization
and
execution.As
we
will illustrate later in this paper,query
mediation is drivenby logical inferences
which do
notbond
well with the (predominantly cost-based) optimizationtechniques that
have
been
developed [40; 45].The
advantage
ofkeeping thetwo
tasks apart isthus not merely a conceptual convenience, but allows us to take
advantage
ofmature
techniquesfor
query
optimization indetermining
how
best aquery canbe
evaluated.Query
Pruning
Finally, observethat consistency checking is
performed
asan
integral activity ofthe mediationprocess, allowing intensional answers to
be
pruned
(insome
cases, significantly) to aurive atanswers
which
are bettercomprehensible
and
more
efficient. Forexample,
ifQl
had been
modified to include the additional condition "rl.
currency
= 'JPY'", the intensionalanswer
returned
(MQl)
would have
only the secondSELECT
statement (but not the firstand
thethird) since the other
two
would have been
inconsistent with thenewly
imposed
condition.This
pruning
of the intensional answer,accomplished
by
taking into consideration integrityconstraints (present as part of a query, or those defined
on
sources)and knowledge
ofdata
semanticsindistinctsystems, constitutesa
form
ofsemantic
query optimization [7]. Consistencychecking
however
canbe an
expensive operationand
the gainsfrom
amore
efficient executionmust
be
balanced against the cost ofperforming
the consistency check duringquery
mediation.In our case, however, the benefits are
ampUfied
since spuriousconflicts thatremain
undetectedcould result in
an
additional conjunctive query involving multiple sources.2.2
Functional Features
of
Context
Interchange:
A
System
Perspective
It is natural to
assume
the internal complexity ofany system
will increase incommensuration
with the external functionalities it offers.
The
Context
Interchangesystem
isno
exception.We
make
no
claim that ourapproach
is "simple"; however,we
submit
that this complexityis
decomposable and
well-founded. Decomposability has obvious benefitsfrom
asystem
engi-neering perspective, allowing complexity to
be
harnessed into small chunks, thusmaking
ourintegration
approach
more
endurable, evenwhen
thenumber
of sourcesand
receivers areex-ponentially large
and
when
changes arerampant.
The
complexity is said tobe
well-foundedbecause
it is possible to characterize the behavior ofthesystem
inan
abstractmathematical
framework.
This
allows us tounderstand
the potential (or limits) ofthe strategy apartfrom
the idiosyncrasies of the implementation,
and
is useful for providing insights intowhere
and
how
improvements
canbe made.
We
describebelow
some
of theways
inwhich
complexityis decoupled in a
Context
Interchange system, as well as tangible benefitswhich
resultfrom
formalization ofthe integration strategy.
Representation
of
'Meaning'
asopposed
toConflicts
As
mentioned
earlier, a key insight oftheContext
Interchangestrategy is thatwe
can
representthe
meaning
ofdata
in the underlyingsourcesand
receivers without identifyingand
reconcilingall potential conflicts
which
existbetween any
two
systems. Thus, query mediation canbe
per-formed dynamically
(aswhen
a query is submitted) or itcan
be
used toproduce
a query plan(the
mediated
query) that constitutes alocally-defined view. In the latter case, thisviewissim-ilar to the shared
schemas
in tightly-coupled systemswith
one
important exception:whenever
changes
do
occur (say,when
the semantics ofdataencoded
insome
context is changed^), theContext Mediator can
be
triggered to reconstruct the localview
automatically. Unlike the casein tightly-coupled systems, thisreconstructionrequires
no
manual
interventionfrom
thesystem
administrators. In
both
oftheabove
scenarios, changes in local systems are well-containedand
do
notmandate
human
intervention in other parts of the larger system.This
represents asignificant gain over tightly-coupled systems
where maintenance
of sharedschemas
constitutea
major system
bottleneck.*Foran accountof
why
thisseemingly strangephenomenonmay
bemorecommon
thaniswidelybelieved to be, see [52].Contexts
versus
Schemas
Unlikethesemantic-value model, the
COIN data
model
adopts a verydifferentconceptualizationof contexts: instead of
a
property-list associatedwith
individualdata elements,we
view contextas consisting of a collection of
axioms which
describes a particular "situation" a source orreceiver is in.
Domain
Model
semanticNumber scaleFaclor...7(8)-=:::,-..
semantics tnDg moneyAmt companyFinancials semantic-relation r2' currency 1^1 currencyTVpe Legendobject for
which
the object-id is aSkolem
function [8] definedon
some
key values. For eachrelation r present in a source, there is
an
isomorphic relation r' definedon
the correspondingsemantic-objects.
Among
other features, this structure allows us toencode assumptions
oftheunderlying context independentlyof structure
imposed on
data in underlyingsources (i.e., theschemes). For example, the constraint: all
"company
financials" are reported inUS
Dollarswithin context C2 can
be
described using the clause^X'-.companyFinancials, currency{c2,
X'):currencyType
h
curre/Jcy(c2,X')[va/ue(c2) ->'USD'].
The
method
currency issaid tobe
a modifier because it modifieshow
the value ofasemantic-object is reported.
A
detailed presentation of the details of thisframework
willbe
presentedlater in Section 4.
The
dichotony between schemas and
contexts present anumber
ofopportunities forsys-tematic sharing
and
reuse ofsemantic encodings. For example, different sourcesand
receiversin the
same
contextmay
now
bind to thesame
set ofcontext axioms;and
distinct attributeswhich
correlatewith
one
another (e.g.,revenue,
expenses)
may
be
mapped
to instances ofthe
same
semantic-type (e.g., companyFinancials).These
circumvent the need to define anew
property-list for all attributes in each schema. Unlike the semantic value model, there is no
ambiguity
on
what
modifierscan be
introduced as "meta-attributes" since all properties ofsemantic- types are explicitly defined in the
domain
model.As
pointed out in the previoussection, views
can be (more
simply) definedon
the extensional relation independently of thecontext descriptions.
This
constitutes yet another benefit of teasing apart the structure ofasource,
and
semanticswhich
are implicit in its context.Inheritance
and
Overriding
inSemantic-
Types
Not
surprisingly,the various features frequently associated with "object-orientation" are usefulin our representation
scheme
as well. Semantic-types fall naturally into a generalizationhier-archy,
which
allow us to takeadvantage
ofstructuraland
behavioral inheritance in achievingeconomy
of expression. Structural inheritance allows a semantic-type to inherit thedeclara-tions defined for its supertypes. For example, the semantic-type
companyFinancials
inheritsfrom
moneyAmt
the declarations concerning the existence of the"methods"
currencyand
scaleFactor. Behavioral inheritance allows the definitions ofthese
methods
tobe
inherited aswell. Hence, if
we
had
defined earlier that instances ofmoneyAmt
has a scale-factor of 1,all instances of
companyFinancials would
inherit thesame
scale-factor since every instance ofcompanyFinancials
isan
instance ofmoneyAmt.
Inheritance
need
notbe
monotonic.Non-monotonic
inheritancemeans
that the declarationor definition of a
method
can
be
overridden in a subtype.Thus,
inherited definitions canbe
viewed
cis defaultswhich can
alwaysbe changed
to reflect the specificities at hand.Value Conversion
Among
Different
Contexts
Yet another benefit of
adopting
an
object-orientedmodel
in ourframework
is that it allowsconversion functions
on
values tobe
explicitlydefined intheform
ofmethods
definedon
varioussemantic types. For
example,
the conversion function for convertingan
instance ofmoneyAmt
from one
scale-factor(F
in contextC)
to another (Fi in context Ci) canbe
defined as follows:X'
-.moneyAmt h
X'[cvt(ci)@scaleFactor, C,
U^V]
<r- X'[scaleFactor(ci)^-[value{ci)^Fi]],X'[sca}eFactor{C)^.[vahieici)^F]],
V
=
U*
F/F^.
This
conversion function, unless explicitly overridden, willbe
invokedwhenever
there is arequest for scale-factor conversion
on
an
objectwhich
isan
instance ofmoneyAmt
and
when
theconversion isto
be performed with
reference to context C\. Overridingcan
take place alongthe generalization hierarchy: as before,
we
may
introduce a different conversion function for asubtype
ofmoneyAmt.
Notice that thisconversion function isdefined with reference to contextCi only: in order for scale-factor conversion to take place in a different context, the conversion
function (which could
be
identical totheone
in ci, or not) will havetobe
definedexplicitly.This
phenomenon
allows diff"erent conversion functions tobe
associated with different contextsand
is a powerful
mechanism
for different users to introduce theirown
interpretations of disparatedata inalocalized fashion.
The
apparentredundancy
(in having multiple instancesof thesame
definition in diff'erent contexts) is addressed
through
theadoption ofa context hierarchywhich
is described next.
Hierairchical
composition
of
Contexts
By
"objectifying" sets ofaxioms
associated with contexts,we
can introduce a hierarchicalrelationship
among
contexts. If c is a subcontext of c', then all theaxioms
defined in (/ aresaid to apply in c unless they are "overridden".
An
immediate
application of this conceptis to
make
all "functional" contexts subcontexts of a default context Cq,which
contains thedefault declarations
and
method
definitions.Under
this scheme,new
contexts introduced needonly to identify
how
it is differentfrom
the default contextand
introduce the declarationsand
method
definitionswhich need
tobe changed
(overridden). This isformulated as ameta-logicalextension ofthe
COIN framework and
willbe
described in further details in Section 6.Another advantage
ofhaving this hierarchy ofcontext is theability to introduce changes tothe
domain model
inan
incrementalfashionwithout having adverse effectson
existing systems.For example,
suppose
we
need toadd
anew
sourceforwhich
currency units takeon
a differentrepresentation (e.g.,
'Japanese Yen'
versus 'JPY'). This distinction has notbeen
previouslycapturedinour
domain
model,which
has hithertoassumed
currency units have ahomogeneous
representation.
To accommodate
thenew
data
source, it is necesscU-y toadd
anew
modifierforcurrencyType, say format, in the
domain
model:cuTrencyType[forinat(ctx) => semanticString].
Rather than
making
changes to all existing contexts,we
can assign a default value to thismodifier in cq,
and
at thesame
time, introduce a conversion function formapping
between
currency representations of different formats (e.g.,
'Japanese
Yen'and
'JPY'):X:
currencyType,
format{co,X):semanticStringh
format(co,A')[vaJue(co)—)
'abbreviated'].
X
-.currencyTypeh X[cvt(co)@C,
U^V]
<r- ... (body)...
The
last step in this process is toadd
to thenew
context (cf) the following context axiom:X
-.currencyType, format{c',X)
.semanticStringh
format(c',X)[vaJue(c')-> 'full'].which
distinguishes it as having a different format.3
Context
Interchange
vis-a-vis
Traditional
and
Contemporary
Integration
Approaches
In the preceding section,
we
have
made
detailedcomments
on
themany
features that theContext
Interchangeapproach
has over traditional loose-and
tight-coupling approaches. Insummary,
although
tightly-coupledsystems
may
provide better support fordata
access toheterogeneous
systems (compared
to loosely-coupled systems), theydo
not scale-up effectivelygiven the complexity involved in constructing a shared
schema
for a largenumber
ofsystemsand
are generallyunresponsiveto changes forthesame
reason. Loosely-coupled systems,on
theother hand, require little central administration
but
are equally non-viable since they requirenon-tenable
when
thenumber
of systems involved is largeand
when
changes are frequent^°.The
Context
Interchangeapproach
provides a novelmiddle ground between
the two: it allowsqueries to sources to
be mediated
in a transparentmanner,
provides systematic support forelucidatingthe semantics of
data
indisparate sourcesand
receivers,and
at thesame
time, doesnot
succumb
to the complexities inherent inmaintenance
of shared schemas.At a
cursory level, theContext
Interchangeapproach
may
appear
similar tomany
contem-porary integration approaches.
Examples
of thesecommonalities
include:• framing the
problem
inMcCarthy's
theory of contexts [37] (as inCarnot
[11],and
more
recently, [18]);
• encapsulation [3] ofsemantic
knowledge
ina hierarchyof rich data typeswhich
are refinedviasub-typing (as inseveralobject-oriented multidatabase systems, the archetypeof
which
is
Pegasus
[2]);• adoption of a deductive or object-oriented
formalism
[28; 15] (as in theECRC
Multi-database
System
[26]and
DISCO
[50]);• provision ofvalue-added services
through
the useofmediators [54] (as inTSIMMIS
[20]);We
posit that despite these superficial similarities, ourapproach
represents aradical departurefrom
thesecontemporary
integration strategies.To
beginwith, anumber
ofcontemporary
integrationapproaches
are in factattempts aimed
at rejuvenating the loose- or tight-coupling approach.
These
are often characterizedby
theadoptionof
an
object-orientedformalism which
providessupport
formore
effectivedata
trans-formation (e.g.,
0*SQL
[32]) or to mitigate the effects ofcomplexity inschema
creationand
change
management
through
the use of abstractionand
encapsulationmechanisms.
To some
extent,
contemporary approaches
such asPegasus
[2], theECRC
Multidatabase
Project [26],and
DISCO
[50] canbe
seen asexamples
of the latter strategy.These
differfrom
theCon-text Interchange strategy since they continue to rely
on
human
intervention in reconcilingconflicts a priori
and
in themaintenance
ofshared schemas. Yet another difference is thatal-though
adeductiveobject-oriented formalism isalso used in theContext
Interchange approach,"semantic-objects" in
our
caseexistonly conceptuallyand
are neveractually materialized.One
implication ofthis is that
mediated
queriesobtainedfrom
theContext Mediator can be
furtherWe
have drawn asharp distinction between the two here toprovide a contrast of their relative features. Inpractice,oneismostlikely toencounter a hybridofthe twostrategies. It shouldhowever be noted thatthetwo
strategies are incongruent in their outlook and are not able to easily take advantage ofeach other's resources.
For instance, datasemantics encapsulated in a shared .schema cannot beea-sily extracted by au.ser to assist in
formulating aquery which seeksto reference the sourceschemas directly.
optimized usingtraditional
query
optimizers orbe
executedby
thequery
subsystem
ofclassical(relational)
query
subsystems
without changes.In the
Carnot system
[11], semantic interoperability is accomplishedby
writing articulationaxioms which
translate "statements"which
are true in individual sources to statementswhich
are meaningful in the
Cyc
knowledge
base [31].A
similarapproach
isadopted
in [18],where
it is suggested that domain-specific ontologies [22],
which
may
provide additional leverageby
allowing the ontologies to
be
sharedand
reused, canbe
used in place of Cyc.While
we
likethe explicit treatment of contexts in these efforts
and
share their concern for sustaining aninfrastructure for
data
integration, our realization of these differ significantly. First, liftingaxioms
[23] inour case operateat afiner level of granularity: ratherthan
writingcixiomswhich
map
"statements" present in a data source to acommon
knowledge
base, they are used fordescribing "properties" of individual "data objects". Second, instead of
having
an
"ontology"which
captures aF. structural relationshipsamong
data
objects(much
like a "global schema"),we
have
adomain model
which
is amuch
less elaborate collection ofcomplex
semantic-types.These
differences account largely for the scalabilityand
extensibility ofour approach.Finally,
we
remark
that theTSIMMIS
[41; 42]approach stems
from
the premise thatin-formation integration could not,
and
should not,be
fullyautomated.
With
this in mind,TSIMMIS
opted
in favor ofprovidingboth
aframework
and
a collection of tools to assisthu-mans
in their information processingand
integration activities. This motivated the inventionofa "light-weight" object
model
which
is intended tobe
self-describing. Forpractical purposes,thistranslates to the strategy of
making
sure that attribute labelsare as descriptive as possibleand
opting for free-text descriptions ("man-pages")which
provide elaborationson
theseman-tics ofinformationencapsulated ineach object.
We
concur that thisapproach
may
be
effectivewhen
thedata
sourcesare ill-structuredand
when
consensuson
a shared vocabulary cannotbe
achieved.
However,
there are alsomany
other situations (e.g.,where
data sources arerelativelywell-structured
and
where
some
consensus canbe
reached)where
human
intervention is notappropriate or necessary: this distinction is primarily responsible for the different approaches
taken in
TSIMMIS
and
our strategy.4
The
COIN
Data
Model:
Structure,
Language,
and
Frame-work
In [37],
McCarthy
pointed out that statementsabout
the world are never always true or false:the truth or falsity of a statement
can
onlybe understood with
reference to a given context.c: ist{c,a)
which
suggests that the statementa
is true ("«<") inthe context c^\ thisstatement itselfbeingasserted in
an
outer context c. Lifting axioms^^ are used to describe the relationshipbetween
statements in different contexts.
These
statements are oftheform
c: ist{c,a) <=> ist{c',a')
which
suggests that "cr in c states thesame
thingas a' in c"'.McCarthy's
notion of "contexts"and
"liftingaxioms"
provide a usefulframework
formod-eling statements in heterogeneous databases
which
are seemingly in conflictwith
one
another.From
this perspective, factual statements present in adata
source areno
longer "universal"facts
about
the world,but
are true relative to the context associatedwith
the source but notnecessarily soin
a
different context.Thus,
ifwe
assignthelabelsc\and
C2 tocontextsassociatedwith sources 1
and
2 in Figure 1,we
may
now
write:c: ist(ci,
rl('NTT',
1000
000, 'JPY'))-c: «s<(c2, r2('NTT', 5000
000)).The
context cabove
refers to the ubiquitous context inwhich
our discourse isconducted
(i.e.,the integration context)
and
may
be omitted
in the ensuing discussionwhenever
there isno
ambiguity.
In the
Context
Interchange approach, the semantics of data are captured explicitly in acollection of statements asserted in the context associated with each source, while allowing
conflict detection
and
reconciliation tobe
deferred to thetime
when
aquery
is submitted.Building
on
the ideas developed in [48; 44],we
would
like tobe
able to represent the semanticsof
data
at the levelof individual data elements (asopposed
to the predicateor sentential level),which
allows us to identifyand
deal with conflicts at a finer levelof granularity. Unfortunately,individual
data
elementsmay
be
present inarelationwithouta unique
denotation. Forinstance,the value 1
000 000
inrelationrl (asshown
inFigure 1)simultaneouslydescribes therevenueofIBM and NTT
whilebeing
reportedin different currenciesand
scale-factors. Thus, the statements"in thewords of
Guha
[23], contexts represents "thereification ofthe context dependencies ofthe sentencesassociated with thecontext." They are said tobe "rich-objects" in that "they cannot bedefined orcompletely described" [38]. Consider, forinstance, the context associated with the statement; "Therearefovir billion people hving on Earth". To fully qualify thesentence, we might add that it assumes that the time is 1991, However, thiscertainlyis not the onlyrelevantassumption inthe underlyingcontext, sincethereare implicitassumptions
about
who
is considered a "live person" (are fetuses in thewomb
alive?), or what it means to be "on earth"(doesit include people
who
arein orbit around the earth?)aJso called articulation axioms in Cyc/Carnot [11].
ist{ci,
currency(R,Y)
f-t1{N,R,Y)).
ist{ci, scaIeFactor{R,1000) <-
currency(R,Y),
F
='JPY').
ist{cu scaleFactor{R,\) <- currency
{R,Y),
Y
t^'JPY')-intendingto represent thecurrencies
and
scale-factorsofrevenueamounts
will result inmultipleinconsistent values.
To
circumvent this problem,we
introduce semantic-objects,which
canbe
referencedunambiguously through
their object-ids. Semantic-objects arecomplex
termsconstructed
from
the correspondingdata
values (also calledprimitive-objects)and
are used asabasis for inferring
about
conflicts, but are never materialized inan
object-store.This
willbe
described in furtherdetails in the next section.
The
data
model
underlyingourintegrationapproach, calledCOIN
(forcontext
INterchange),consists of
both
a structuralcomponent
describinghow
data objects are organized,and
alan-guage
which
provides the basis for niciking formal assertionsand
inferencesabout
a universeof discourse. In the
remainder
of this section,we
providea
description ofboth
ofthesecom-ponents, followed
by
a formal characterization oftheContext
Interchange strategy intheform
ofa
COIN framework.
The
latter willbe
illustratedwith
reference to the motivationalexample
introduced in Section 2.
4.1
The
Structural
Elements
of
COIN
The
COIN data
model
is a deductive object-orienteddata
model
designed to provide explicitsupport for
Context
Interchange. Consistentwith
object-orientation [3], information units aremodeled
as objects,having unique and immutable
object-ids (oids),and
corresponding to typesin
a
generalization hierarchy with provision fornon-monotonic
inheritance.We
distinguishbetween
two
kinds ofdata
objects in coin: primitive objects,which
are instances of primitivetypes,
and
semantic-objectswhich
areinstances of semantic-types. ObjectsinCOIN
have
both an
oid
and
a value: these are identical in the case of primitive-objects,but
different forsemantic-objects.
This
isan
important
distinctionwhich
willbecome
apparent shortly.Primitive-types correspond to
data
types (e.g., strings, integers,and
reals)which
are nativeto sources
and
receivers. Semantic-types,on
the other hand, arecomplex
types introduced tosupport the underlying integration strategy. Specifically, semantic-objects
may
haveproper-ties
which
are either attributes or modifiers. Attributes represent structural properties ofthesemantic-object
under
investigation: for instance,an
object of the semantic-typecompanyFi-nancials must,
by
definition, describessome
company;
we
capture this structuraldependency
by
definingthe attributecompany
for the semantic-type companyFinancials. Modifiers,on
theother hand, Eire used as the basis for capturing "orthogonal" sources of variations concerning
themodifierscurrency
and
scaleFactor definedformoney
Ami
suggeststwo
sources of variationsin
how
the value correspondingtoan
instance ofmoneyAmt
may
be
interpreted."Orthogonal-ity" here refers to the fact that the value
which
canbe
assigned toone
modifier isindependent
ofother modifiers, as is the case
with
scaleFactorand
ciu-rency. This is not a limitationon
theexpressiveness ofthe
model
sincetwo
sources of variationswhich
are correlatedcan
alwaysbe
modeled
as a single modifier.As
we
shall see later, this simplification allows greater flexibilityin dealing
with
conversions of values across diff"erent contexts.Unlike primitive-objects, the value of a semantic-object
may
be
different in differentcon-texts. For
example,
ifthe (Skolem)term
sko is the oid for the object representing the revenueof NTT, it is perfectly legitimate for
both
(1) ist{ci, value{skQ,1000000));
and
(2) ist{c2, value(sko,9
600
000)),to
be
true since contexts c\and
C2embody
differentassumptions
on
what
currenciesand
scale-factors are usedto report the value ofa revenue amount^''. Forour
problem domain,
it is oftenthe case that the value ofa semantic-object is
known
insome
context, but not others. This isthe case in the
example
above,where
(1) isknown, but
not (2).The
derivation of (2) is aidedby
a special liftingaxiom
defined below.Definition
1 Let tbe an
oid-termcorresponding to a semantic-object ofthe semantic-type r,and suppose
the value of t is given in context Cg. Forany
context representedby
C,we
haveist{C, value{t,X) <- fcvt{t,Cs,X')
^
X)
<^ ist{cs, value{t,X')).We
refer to /cvt, as the conversion function for t in context C,and
say thatX
is the value oftin context C,
and
that it is derivedfrom
context Cs-Q
As
we
shallseelater, theconversion functionreferencedabove
ispolymorphically defined, beingdependent
on
the type of the object towhich
it is applied,and
may
be
different in distinctcontexts.
Since modifiers of a semantic-type are orthogonal
by
definition, the conversion functionreferenced in the preceding definition
can
in factbe
composed
from
other simpler conversionmethods
definedwith
reference toeachmodifier.To
distinguishbetween
thetwo,we
referto thefirstas a composite conversionfunction,
and
the latter as atomic conversionfunctions.Suppose
A
predicate-calculu.slanguageisusedin thediscussionheresinceitprovidesbetter intuitionformostreaders.The COIN language, for which properties are modeled a-s "methods" (allowing us towrite sA:o[vaJue->l000000]
asopposedto value{skoA000000)), will beformaJly defined in Section 4.2.
modifiersofa semantic-type r are
mi,
. . .,mj^,
and
/cvt is acomposite
conversion function forT. It follows that ift is an object oftype r, then
{f^,'2it^c,,X')
=
X,)
A---A
{£lit^Cs,Xk-,)
=
X)
fcvt{t,Cs,X')
=
X
if3X\,
... ,Xk-]
such thatwhere f^H
corresponds to theatomic
conversion function with respect to modifier rrij. Noticethat the order in
which
the conversions are eventually effected need not correspond to theordering of the
atomic
conversionsimposed
here, since the actual conversions are carried outin a lazy fashion
and depends
on
the propagationof variable bindings.Finally,
we
note that value-basedcomparisons
inthe relationalmodel
requiressome
adjust-ments
here.We
say thattwo
semantic-objects are distinct iftheir oids are different. However,distinct semantic-objects
may
be
semantically-equivalent as defined below.Definition
2 Let©
be a
relationaloperatorfrom
theset {=,<,>,<,>,
7^, . .}. Ifiand
t' areoid-terms correspondingto semantic-objects, then
(t®t')
O
(value{t,X)A
vahie{t',X')A
X
®
X')In particular,
we
say that tand
t' are semantically-equivalent in context c ifist{c,t=t').We
sometimes abuse
the notationslightlyby
allowingprimitive-objects to participateinsemantic-comparisons. Recall that
we
do
not distinguishbetween
the oidand
the value of a primitiveobject; thus, ist{C, va/ue(l
000
000, 1000000))
is true irregardlessofwhat
C
may
be.Suppose
we know
that ist{Ci, value{skQ,1000
000)),where
sko refers to the revenue ofNTT
as before.The
expressionsko
<
5000
000
will therefore evaluate to "true" in context c\ but not context C2, since ist{c2, value{sko,
9
600
000)).This
latter factcan
be
derivedfrom
the value of sko in ci (which is reporteda priori in
rj
and
the conversion function associatedwith
the typecompanyFinancials
(seeSection 5.3).
4.2
The
Language
of
COIN
We
describe inthissection the syntaxand
informal semanticsofthe languageof COIN,which
isinspired largely
by Gulog
[15]^''.Rather than
making
inferences using a context logic (see, for^"GulogdiffersfromF-logic[28] inthatmethodrulescireboundtotheunderlyingtypes,whichleadstodifferent
approciches for dealing with non-monotomc inheritance. Specifically, in the case of F-logic, it is not rales but
ground expressions that axe handed down the generalization hierarchy. Since we are interested in reasoning at