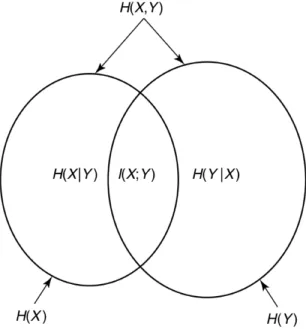
Information flow in plastic neural network
37
0
0
Texte intégral
Figure
![Figure 5: Change of synaptic weights as a function of the relative timing of pre- and postsynaptic spikes (source: [6])](https://thumb-eu.123doks.com/thumbv2/123doknet/15040018.691392/9.918.289.631.109.381/figure-change-synaptic-weights-function-relative-timing-postsynaptic.webp)

+7
![Figure 7: Firing patterns reproduced by Izhikevich model (source: [1])](https://thumb-eu.123doks.com/thumbv2/123doknet/15040018.691392/11.918.149.789.111.582/figure-firing-patterns-reproduced-izhikevich-model-source.webp)

Documents relatifs