[PDF] Cours structuré sur le Langage C++ en pdf | Cours informatique
Texte intégral
Figure





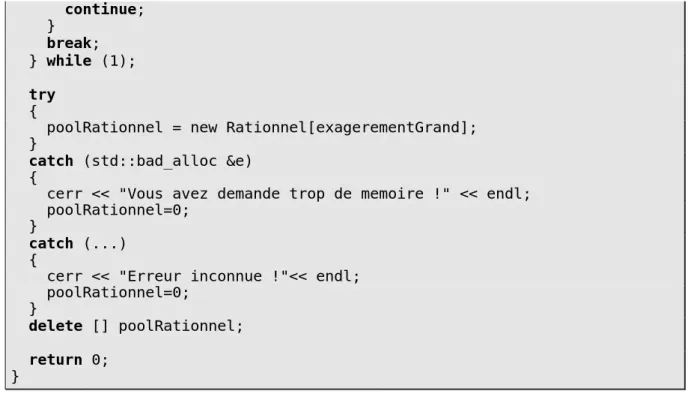
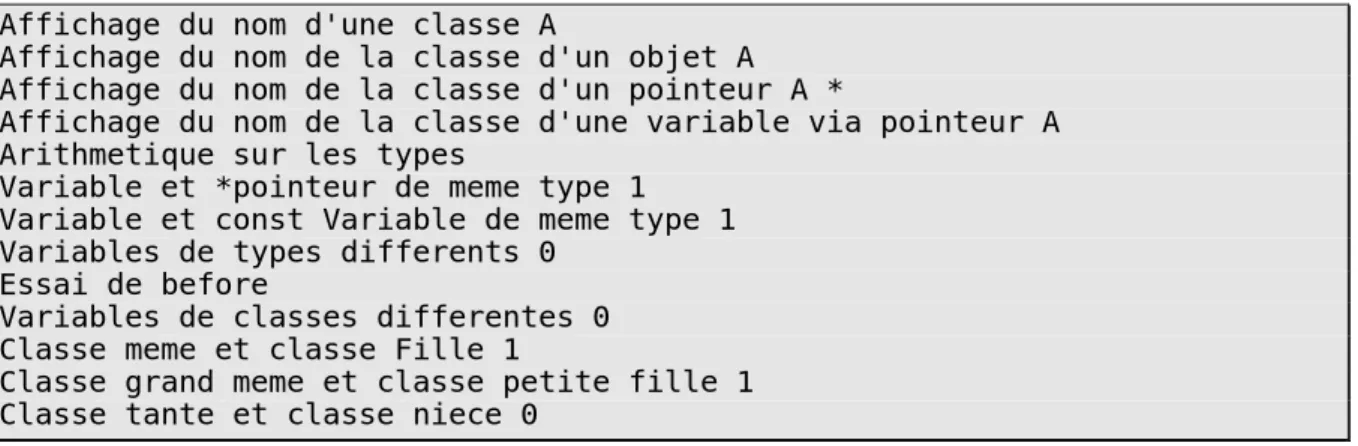

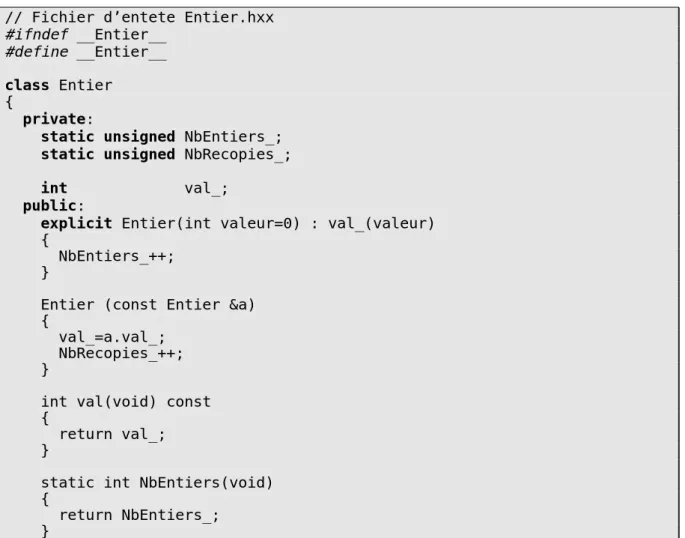
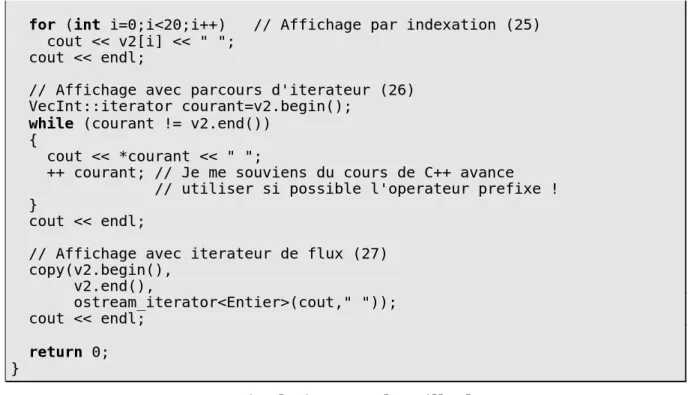
Documents relatifs
Runtime Monitor notifies of observable states Executed Model Property Manager updates model state Execution Semantics Runtime Monitor Temporal Monitor 1.2 deployed
Indeed the non-verbal signals sequences contained in these segments will be distributed for different types of attitude variations, and therefore will not be very frequent before
Data from the two cases were analysed for the relational structures between the two (national and international) levels of processes for governing global health. We found
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
Diagnóstico de áreas potenciais para recuperação de área degradada, em região de extração de areia, com uso de sedimento de canal de adução de água e lodo de Estação
Par ailleurs, les enfants ont tous utilisé PLAY-ON à partir du clavier, c'est à dire des flèches directionnelles (la gauche et la droite pour la discrimination et les quatre pour
De plus, la mise en scène de certaines activités de jeu demande que l’enfant prenne la perspective d’un personnage, qu’il puisse conférer des propriétés d'animé à des
Réunis dans une même base de données comprenant les enregistrements, leurs transcriptions orthographiques et les métadonnées décrivant les documents, le contexte
