HAL Id: hal-00699295
https://hal.archives-ouvertes.fr/hal-00699295
Submitted on 20 May 2012HAL is a multi-disciplinary open access archive for the deposit and dissemination of sci-entific research documents, whether they are pub-lished or not. The documents may come from teaching and research institutions in France or abroad, or from public or private research centers.
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des établissements d’enseignement et de recherche français ou étrangers, des laboratoires publics ou privés.
A Joint Named Entity Recognition and Entity Linking
System
Rosa Stern, Benoît Sagot, Frédéric Béchet
To cite this version:
Rosa Stern, Benoît Sagot, Frédéric Béchet. A Joint Named Entity Recognition and Entity Linking System. EACL 2012 Workshop on Innovative hybrid approaches to the processing of textual data, Apr 2012, Avignon, France. �hal-00699295�
A Joint Named Entity Recognition and Entity Linking System
Rosa Stern,1,2Benoˆıt Sagot1 and Fr´ed´eric B´echet3 1
Alpage, INRIA & Univ. Paris Diderot, Sorbonne Paris Cit´e / F-75013 Paris, France
2
AFP-Medialab / F-75002 Paris, France
3
Univ. Aix Marseille, LIF-CNRS / Marseille, France
Abstract
We present a joint system for named entity recognition (NER) and entity linking (EL), allowing for named entities mentions ex-tracted from textual data to be matched to uniquely identifiable entities. Our approach relies on combined NER modules which transfer the disambiguation step to the EL
component, where referential knowledge about entities can be used to select a correct entity reading. Hybridation is a main fea-ture of our system, as we have performed experiments combining two types of NER, based respectively on symbolic and statis-tical techniques. Furthermore, the statisti-cal EL module relies on entity knowledge acquired over a large news corpus using a simple rule-base disambiguation tool. An implementation of our system is described, along with experiments and evaluation re-sults on French news wires. Linking ac-curacy reaches up to 87%, and the NER f-measure up to 83%.
1 Introduction
1.1 Textual and Referential Aspects of Entities
In this work we present a system designed for the extraction of entities from textual data. Named entities (NEs), which include person, location, company or organization names1 must therefore be detected using named entity recognition (NER)
techniques. In addition to this detection based on their surface forms, NEs can be identified by mapping them to the actual entity they denote, in order for these extractions to constitute use-ful and complete information. However, because
1
The set of possible named entities varies from restric-tive, as in our case, to wide definitions; it can also include dates, event names, historical periods, etc.
of name variation, which can be surfacic or en-cyclopedic, an entity can be denoted by several mentions (e.g., Bruce Springsteen, Springsteen, the Boss); conversely, due to name ambiguity, a single mention can denote several distinct entities (Orange is the name of 22 locations in the world; in French, M. Obama can denote both the US president Barack Obama (M. is an abbreviation of Monsieur’Mr’) or his spouse Michelle Obama; in this case ambiguity is caused by variation). Even in the case of unambiguous mentions, a clear link should be established between the surface men-tion and a uniquely identifiable entity, which is achieved by entity linking (EL) techniques.
1.2 Entity Approach and Related Work In order to obtain referenced entities from raw textual input, we introduce a system based on the joint application of named entity recognition (NER) and entity linking (EL), where theNER
out-put is given to the linking component as a set of possible mentions, preserving a number of am-biguous readings. The linking process must there-after evaluate which readings are the most proba-ble, based on the most likely entity matches in-ferred from a similarity measure with the context.
NER has been widely addressed by symbolic, statistical as well as hybrid approaches. Its ma-jor part in information extraction (IE) and other
NLPapplications has been stated and encouraged by several editions of evaluation campaigns such as MUC (Marsh and Perzanowski, 1998), the CoNLL-2003NER shared task (Tjong Kim Sang and De Meulder, 2003) or ACE (Doddington et al., 2004), whereNERsystems show near-human performances for the English language. Our sys-tem aims at benefitting from both symbolic and statisticalNERtechniques, which have proven ef-ficient but not necessarily over the same type
of data and with different precision/recall trade-off. NER considers the surface form of entities; some type disambiguation and name normaliza-tion can follow the detecnormaliza-tion to improve the re-sult precision but do not provide referential infor-mation, which can be useful in IE applications.
EL achieves the association of NER results with uniquely identified entities, by relying on an en-tity repository, available to the extraction system and defined beforehand in order to serve as a tar-get for mention linking. Knowledge about en-tities is gathered in a dedicated knowledge base (KB) to evaluate each entity’s similarity to a given context. After the task of EL was initiated with
Wikipedia-based works on entity disambiguation, in particular by Cucerzan (2007) and Bunescu and Pasca (2006), numerous systems have been devel-oped, encouraged by the TAC 2009KBpopulation task (McNamee and Dang, 2009). Most often in
EL, Wikipedia serves both as an entity repository
(the set of articles referring to entities) and as aKB
about entities (derived from Wikipedia infoboxes and articles which contain text, metadata such as categories and hyperlinks). Zhang et al. (2010) show how Wikipedia, by providing a large anno-tated corpus of linked ambiguous entity mentions, pertains efficiently to the EL task. Evaluated EL
systems at TAC report a top accuracy rate of 0.80 on English data (McNamee et al., 2010).
Entities that are unknown to the reference database, called out-of-base entities, are also con-sidered byEL, when a given mention refers to an
entity absent from the available Wikipedia arti-cles. This is addressed by various methods, such as setting a threshold of minimal similarity for an entity selection (Bunescu and Pasca, 2006), or training a separate binary classifier to judge whether the returned top candidate is the actual denotation (Zheng et al., 2010). Our approach of this issue is closely related to the method of Dredze et al. in (2010), where the out-of-base en-tity is considered as another entry to rank.
Our task differs from EL configurations out-lined previously, in that its target is entity extrac-tion from raw news wires from the news agency Agence France Presse (AFP), and not only link-ing relylink-ing on gold NER annotations: the input of the linking system is the result of an auto-maticNERstep, which will produce errors of var-ious kinds. In particular, spans erroneously de-tected asNEs will have to be discarded by ourEL
system. This case, which we call not-an-entity, contitute an additional type of special situations, together with out-of-base entities but specific to our setting. This issue, as well as others of our task specificities, will be discussed in this paper. In particular, we use resources partially based on Wikipedia but not limited to it, and we experiment on the building of a domain specific entityKB
in-stead of Wikipedia.
Section 2 presents the resources used through-out our system, namely an entity repository and an entityKBacquired over a large corpus of news wires, used in the final linking step. Section 3 states the principles on which the NER compo-nents of our system relies, and introduces the two existingNERmodules used in our joint architec-ture. TheELcomponent and the methodology ap-plied are presented in section 4. Section 5 illus-trates this methodology with a number of experi-ments and evaluation results.
2 Entity Resources
Our system relies on two large-scale resources which are very different in nature:
• the entity database Aleda, automatically extracted from the French Wikipedia and
Geonames;
• a knowledge base extracted from a large cor-pus of AFP news wires, with distributional and contextual information about automati-cally detected entites.
2.1 Aleda
The Aleda entity repository2is the result of an ex-traction process from freely available resources (Sagot and Stern, 2012). We used the French Aleda databased, extracted the French Wikipedia 3 andGeonames4. In its current development, it provides a generic and wide coverage entity re-source accessible via a database. Each entity in Aleda is associated with a range of attributes, ei-ther referential (e.g., the type of the entity among Person, Location, Organization and Company, the population for a location or the gender of a person, etc.) or formal, like the entity’sURIfrom
2Aleda is part of the Alexina project and freely available
athttps://gforge.inria.fr/projects/alexina/.
3
www.fr.wikipedia.org
4
Wikipedia orGeonames; this enables to uniquely identify each entry as a Web resource.
Moreover, a range of possible variants (men-tions when used in textual content) are associ-ated to entities entries. Aleda’s variants include each entity’s canonical name, Geonameslocation
labels, Wikipedia redirection and disambiguation pages aliases, as well as dynamically computed variants for person names, based in particular on their first/middle/last name structure. The French Aleda used in this work comprises 870,000 entity references, associated with 1,885,000 variants.
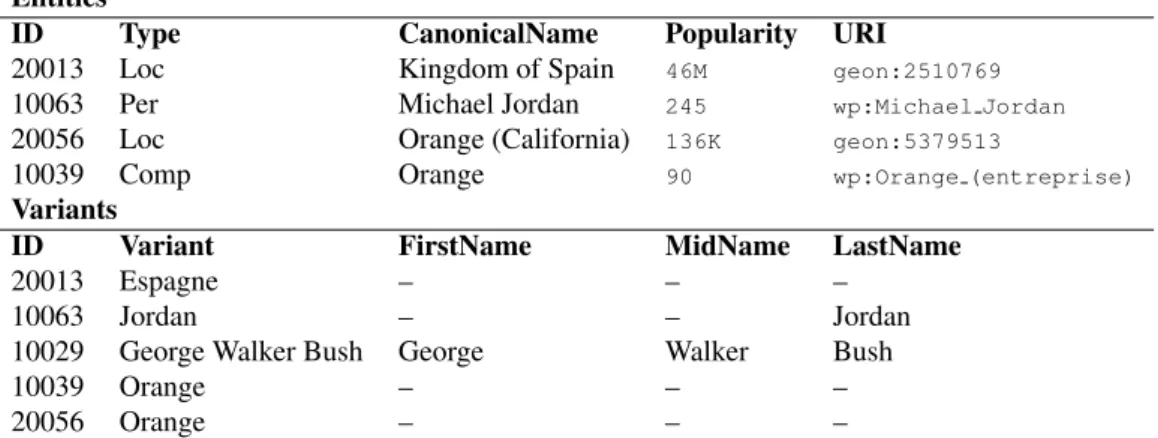
The main informative attributes assigned to each entity in Aleda are listed and illustrated by examples of entries in Tab. 1. The popularity at-tribute is given by an approximation based on the length of the entity’s article or the entity’s popu-lation, from Wikipedia and Geonamesentries re-spectively. Table 1 also details the structure of Aleda’s variants entries, each of them associated with one or several entities in the base.
Unlike most EL systems, Wikipedia is not the entity base we use in the present work; rather, we rely on the autonomous Aleda database. The collect of knowledge about entities and their us-age in context will also differ in that our target data are news wires, for which the adaptability of Wikipedia can be questioned.
2.2 Knowledge Acquisition over AFP news The linking process relies on knowledge about en-tities, which can be acquired from their usage in context and stored in a dedicated KB. AFP news wires, like Wikipedia articles, have their own structure and formal metadata: while Wikipedia articles each have a title referring to an entity, ob-ject or notion, a set of categories, hyperlinks, etc.,
AFP news wires have a headline and are tagged with a subject (such as Politics or Culture) and several keywords (such as cinema, inflation or G8), as well as information about the date, time and location of production. Moreover, the distri-bution of entities over news wires can be expected to be significantly different from Wikipedia, in particular w.r.t. uniformity, since a small set of entities forms the majority of occurrences. Our particular context can thus justify the need for a domain specificKB.
As opposed to Wikipedia where entities are identifiable by hyperlinks, AFP corpora provide no such indications. Wikipedia is in fact a corpus
where entity mentions are clearly and uniquely linked, whereas this is what we aim at achiev-ing overAFP’s raw textual data. The acquisition of domain specific knowledge about entities from
AFPcorpora must circumvent this lack of
indica-tions. In this perspective we use an implemen-tation of a naive linker described in (Stern and Sagot, 2010). For the main part, this system is based on heuristics favoring popular entities in cases of ambiguities. An evaluation of this sys-tem showed good accuracy of entity linking (0.90) over the subset of correctly detected entity men-tions:5 on the evaluation data, the resulting NER
reached a precision of 0.86 and a recall of 0.80. Therefore we rely on the good accuracy of this system to identify entities in our corpus, bearing in mind that it will however include cases of false detections, while knowledge will not be available on missed entities. It can be observed that by do-ing so, we aim at performdo-ing a form of co-traindo-ing of a new system, based on supervised machine learning. In particular, we aim at providing a more portable and systematic method for EL than the
heuristics-based naive linker which is highly de-pendent on a particular NER system, SXPipe/NP, described later on in section 3.2.
The knowledge acquisition was conducted over a large corpus of news wires (200,000 news items of the years 2009, 2010 and part of 2011). For each occurrence of an entity identified as such by the naive linker, the following features are col-lected, updated and stored in the KB at the en-tity level: (i) enen-tity total occurrences and occur-rences with a particular mention; (ii) entity oc-currence with a news item topics and keywords, most salient words, date and location; (iii) entity co-occurrence with other entity mentions in the news item. These features are collected for both entities identified by the naive linker as Aleda’s entities and mentions recognized by NER
pat-tern based rules; the latter account for out-of-base entities, approximated by a cluster of all mentions whose normalization returns the same string. For instance, if the mentions John Smith and J. Smith were detected in a document but not linked to an entity in Aleda, it would be assumed that they co-refer to an entity whose normalized
5This subset is defined by a strict span and type correct
detection, and among the sole entities for which a match in Aleda or outside of it was identified; the evaluation data is presented in section 5.1.
Entities
ID Type CanonicalName Popularity URI
20013 Loc Kingdom of Spain 46M geon:2510769
10063 Per Michael Jordan 245 wp:Michael Jordan
20056 Loc Orange (California) 136K geon:5379513
10039 Comp Orange 90 wp:Orange (entreprise)
Variants
ID Variant FirstName MidName LastName
20013 Espagne – – –
10063 Jordan – – Jordan
10029 George Walker Bush George Walker Bush
10039 Orange – – –
20056 Orange – – –
Table 1: Structure of Entities Entries and Variants in Aleda
name would be John Smith; this anonymous en-tity would therefore be stored and identified via this normalized name in theKB, along with its oc-currence information.
3 NER Component
3.1 Principles
One challenging subtask ofNERis the correct
de-tection of entity mentions spans among several ambiguous readings of a segment. The other usual subtask ofNERconsists in the labeling or
classi-fication of each identified mention with a type; in our system, this functionality is used as an indica-tion rather than a final attribute of the denoted en-tity. The type assigned to each mention will in the end be the one associated with the matching en-tity. The segment Paris Hilton can for instance be split in two consecutive entity mentions, Paris and Hilton, or be read as a single one. Whether one reading or the other is more likely can be inferred from knowledge about entities possibly denoted by each of these three mentions: depending on the considered document’s topic, it can be more prob-able for this segment to be read as the mention Paris Hilton, denoting the celebrity, rather than the sequence of two mentions denoting the cap-ital of France and the hotel company. Based on this consideration, our system relies on the ability of theNERmodule to preserve multiple readings in its output, in order to postpone to the linker the appropriate decisions for ambiguous cases. Two
NERsystems fitted with this ability are used in our architecture.
Figure 1: Ambiguous NER output for the segment
Paris HiltoninSXPipe/NP
3.2 SymbolicNER: SXPipe/NP
NPis part of theSXPipe surface processing chain (Sagot and Boullier, 2008). It is based on a se-ries of recognition rules and on a large coverage lexicon of possible entity variants, derived from the Aleda entity repository presented in section 2.1. As anSXPipe component,NPformalizes the
text input in the form of directed acyclic graphs (DAGs), in which each possible entity mention is represented as a distinct transition, as illus-trated in Figure 1. Possible mentions are labeled with types among Person, Location, Organization and Company, based on the information available about the entity variant in Aleda and on the type of the rule applied for the recognition.
Figure 1 also shows how an alternative transi-tion is added to each mentransi-tion reading of a seg-ment, in order to account for a possible non-entity reading (i.e., for a false match returned by the
NERmodule). When evaluating the adequacy of each reading, the following EL module will in fact consider a special not-an-entity candidate as a possible match for each mention, and select it as the most probable if competing entity readings prove insufficiently adequate w.r.t. the considered context.
3.3 StatisticalNER: LIANE
The statistical NER system LIANE (Bechet and Charton, 2010) is based on (i) a generative HMM-based process used to predict part-of-speech and semantic labels among Person, Location,
Organi-zation and Productfor each input word6, and (ii) a discriminative CRF-based process to determine the entity mentions’ spans and overall type. The HMM and CRF models are learnt over theESTER
corpus, consisting in several hundreds of hours of transcribed radio broadcast (Galliano et al., 2009), annotated with the BIO format (table 2). The
out-investiture NFS O aujourd’hui ADV B-TIME `
a PREPADE O
Bamako LOC B-LOC
Mali LOC B-LOC
Table 2: BIO annotation for LIANE training
put of LIANE consists in an n-best lists of possi-ble entity mentions, along with a confidence score assigned to each result. Therefore it also provides several readings of some text segments, with al-ternatives of entity mention readings.
As shown in (Bechet and Charton, 2010), the learning model of LIANE makes it particularly robust to difficult conditions such as non capital-ization and allows for a good recall rate on various types of data. This is in opposition with manually handcrafted systems such as SXPipe/NP, which
can reach high precision rates over the develop-ment data but prove less robust otherwise. These considerations, as well as the benefits of a coop-erations between these two types of systems are explored in (B´echet et al., 2011).
By coupling LIANE andSXPipe/NPto perform
the NER step of our architecture, we expect to benefit from each system’s best predictions and improving the precision and recall rates. This is achieved by not enforcing disambiguation of spans and types at theNER level but by transfer-ring this possible source of errors to the linking step, which will rely on entity knowledge rather than mere surface forms to determine the best readings, along with the association of mentions with entity references.
4 Linking Component
4.1 Methodology for Best Reading Selection As previously outlined, the purpose of our joint architecture is to infer best entity readings from
6For the purpose of type consistency across both
NER
modules, theNP type Company is merged with
Organiza-tion, and the LIANE mentions typed as Product are ignored since they are not yet supported by the overall architecture.
Figure 2: Possible readings of the segment Paris
Hiltonand ordered candidates
contextual similarity between entities and docu-ments rather than at the surface level duringNER. The linking component will therefore process am-biguousNERoutputs in the following way,
illus-trated by Fig. 2.
1. For each mention returned by theNER
mod-ule, we aim at finding the best fitting entity w.r.t. the context of the mention occurrence, i.e., at the document level. This results in a list of candidate entities associated with each mention. This candidates set always in-cludes the not-an-entity candidate in order to account for possible false matches returned by theNERmodules.
2. The list of candidates is ordered using a pointwise ranking model, based on the max-imum entropy classifier megam.7 The best scored candidate is returned as a match for the mention; it can be either an entity present in Aleda, i.e., a known entity, or an anony-mousentity, seen during the KB acquisition but not resolved to a known reference and identified by a normalized name, or the spe-cial not-an-entity candidate, which discards the given mention as an entity denotation. 3. Each reading is assigned a score depending
on the best candidates’ scores in the reading. The key steps of this process are the selection of candidates for each mention, which must reach a sufficient recall in order to ensure the reference resolution, and the building of the feature vec-tor for each mention/entity pair, which will be evaluated by the candidate ranker to return the most adequate entity as a match for the mention. Throughout this process, the issues usually raised byELmust be considered, in particular the ability for the model to learn cases of out-of-base enti-ties, which our system addresses by forming a set of candidates not only from the entity reference base (i.e., Aleda), but also from the dedicatedKB
where anonymous entities are also collected. Fur-thermore, unlike the general configuration ofEL
tasks, such as the TACKB population task
(sec-7
tion 1.2), our input data does not consist in men-tions to be linked but in multiple possibilities of mention readings, which adds to our particular case the need to identify false matches among the queries made to the linker module.
4.2 Candidates Selection
For each mention detected in theNERoutput, the mention string or variant is sent as a query to the Aleda database. Entity entries associated with the given variant are returned as candidates. The set of retrieved entities, possibly empty, consti-tutes the candidate set for the mention. Because the knowledge acquisition included the extraction of unreferenced entities identified by normalized names (section 2.2), we can send the normaliza-tion of the mennormaliza-tion as an addinormaliza-tional query to our
KB. If a corresponding anonymous entity is re-turned, we can create an anonymous candidate and add it to the candidate set. Anonymous candi-dates account for the possibility of an out-of-base entity denoted by the given mention, with respec-tively some and no information about the potential entity they might stand for. Finally, the set is aug-mented with the special not-an-entity candidate. 4.3 Features for Candidates Ranking
For each pair formed by the considered mention and each entity from the candidate set, we com-pute a feature vector which will be used by our model for assessing the probability that it repre-sents a correct mention/entity linking. The vec-tor contains attributes pertaining to the mention, the candidate and the document themselves, and to the relations existing between them.
Entity attributes Entity attributes present in Aleda and theKBare used as features: Aleda pro-vides the entity type, a popularity indication and the number of variants associated with the entity. We retrieve from theKBthe entity frequency over the corpus used for knowledge acquisition. Mention attributes At the mention level, the feature set considers the absence or presence of the mention as a variant in Aleda (for any en-tity), its occurrence frequency in the document, and whether similar variants, possibly indicating name variation of the same entity, are present in the document (similar variants can have a string equal to the mention’s string, longer or shorter than the mention’s string, included in the men-tion’s string or including it). In the case of a
mention returned by LIANE, the associated con-fidence score is also included in the feature set. Entity/mention relation The comparison be-tween the surface form of the entity’s canonical name and the mention gives a similarity rate fea-ture. Also considered as features are the relative occurrence frequency of the entity w.r.t. the whole candidate set, the existence of the mention as a variant for the entity in Aleda, the presence of the candidate’s type (retrieved from Aleda) in the possible mention types provided by theNER. The KBindicates frequency of its occurrences with the considered mention, which adds another feature. Document/entity similarity Document metadata (in particular topics and keywords) are inherited by the mention and can thus characterize the en-tity/mention pair. Equivalent information was col-lected for entities and stored in theKB, which al-lows to compute a cosine similarity between the document and the candidate. Moreover, the most salient words of the document are compared to the ones most frequently associated with the entity in theKB. Several atomic and combined features are
derived from these similarity measures.
Other features pertain to the NER output con-figuration, as well as possible false matches:
NER combined information One of the two available NER modules is selected as the base provider for entity mentions. For each mention which is also returned by the second NER
mod-ule, a feature is instanciated accordingly.
Non-entity features In order to predict cases of not-an-entity readings of a mention, we use a generic lexicon of French forms (Sagot, 2010) where we check for the existence of the mention’s variant, both with and without capitalization. If the mention’s variant is the first word of the sen-tence, this information is added as a feature.
These features represent attributes of the en-tity/mention pair which can either have a boolean value (such as variant presence or absence in Aleda) or range throughout numerical values (e.g., entity frequencies vary from 0 to 201,599). In the latter case, values are discretized. All fea-tures in our model are therefore boolean.
4.4 Best Candidate Selection
Given the feature vector instanciated for an (can-didate entity, mention) pair, our model assigns it a score. All candidates in the subset are then ranked accordingly and the first candidate is returned as
the match for the current mention/entity linking. Anonymous and not-an-entity candidates, as de-fined earlier and accounting respectively for po-tential out-of-base entity linking and NER false matches, are included in this ranking process. 4.5 Ranking of Readings
The last step of our task consists in the ranking of multiple readings and has yet to be achieved in order to obtain an output where entity mentions are linked to adequate entities. In the case of a reading consisting in a single transition, i.e., a sin-gle mention, the score is equal to the best candi-date’s score. In case of multiple transitions and mentions, the score is the minimum among the best candidates’ scores, which makes a low entity match probability in a mention sequence penaliz-ing for the whole readpenaliz-ing. Cases of false matches returned by theNERmodule can therefore be dis-carded as such in this step, if an overall non-entity reading of the whole path receives a higher score than the other entity predictions.
5 Experiments and Evaluation
5.1 Training and Evaluation Data
We use a gold corpus of 96 AFP news items in-tended for bothNERandELpurposes: the manual
annotation includes mention boundaries as well as an entity identifier for each mention, correspond-ing to an Aleda entry when present or the normal-ized name of the entity otherwise. This allows for the model learning to take into account cases of out-of-baseentities. This corpus contains 1,476 mentions, 437 distinct Aleda’s entries and 173 en-tities absent from Aleda. All news items in this corpus are dated May and June 2009.
In order for the model to learn from cases of not-an-entity, the training examples were aug-mented with false matches from theNERstep, as-sociated with this special candidate and the pos-itive class prediction, while other possible candi-dates were associated with the negative class. Us-ing a 10-fold cross-validation, we used this corpus for both training and evaluation of our joint NER
andELsystem.
It should be observed that the learning step con-cerns the ranking of candidates for a given men-tion and context, while the final purpose of our system is the ranking of multiple readings of sen-tences, which takes place after the application of
our ranking model for mention candidates. Thus our system is evaluated according to its ability to choose the right reading, considering bothNER re-call and precision andEL accuracy, and not only the latter.
5.2 Task Specificities
As outlined in section 1.2, the input for the stan-dard EL task consists in sets of entity mentions from a number of documents, sent as queries to a linking system. Our current task differs in that we aim at both the extraction and the linking of enti-ties in our target corpus, which consists in unan-notated news wires. Therefore, the results of our system are comparable to previous work when considering a setting where theNERoutput is in fact the gold annotation of our evaluation data, i.e., when all mention queries should be linked to an entity. Without modifying the parameters of our system (i.e., no deactivation of false matches predictions), we obtain an accuracy of 0.76, in comparison with a TAC top accuracy of 0.80 and a median accuracy of 0.70 on English data.8
It is important to observe that our data con-sists only in journalistic content, as opposed to the TAC dataset which included various types of cor-pora. This difference can lead to unequally diffi-culty levels w.r.t. theEL task, sinceNERandEL
in journalistic texts, and in particular news wires, tend to be easier than on other types of corpora. This comes among other things from the fact that a small number of popular entities constitute the majority of NE mention occurrences.
In most systems, EL is performed over noisy NERoutput and participates to the final decisions about NEs extractions. Therefore the ability of our system to correctly detect entity mentions in news content is estimated by computing its pre-cision, recall and f-measure.9 The EL accuracy, i.e., the rate of correctly linked mentions, is
mea-8
As explained previously, these figures, as well as the ones presented later on, cannot be compared with the 0.90 score obtained by the naive linker which we used for the en-tityKBacquisition. This score is obtained only on mentions identified by theSXPipe/NPsystem with the correct span and type, whereas our system does not consider the mention type as a contraint for the linking process, and on correct identifi-cation of a match in or outside of Aleda.
9
Only mention boundaries are considered forNER evalu-ation, while other settings require correct type identification for validating a fully correct detection. In our case,NERis not a final step, and entity typing is derived from the entity linking result.
Setting NER EL JointNER+EL
Precision Recall f-measure Accuracy Recall Precision f-measure
SXPipe/NP 0.849 0.768 0.806 0.871 0.669 0.740 0.702 LIANE 0.786 0.891 0.835 0.820 0.730 0.645 0.685 SXPipe/NP-NL 0.775 0.726 0.750 0.875 0.635 0.678 0.656 LIANE-NL 0.782 0.886 0.831 0.818 0.725 0.640 0.680 SXPipe/NP& 2 0.812 0.747 0.778 0.869 0.649 0.705 0.676 LIANE &SXPipe/NP 0.803 0.776 0.789 0.859 0.667 0.689 0.678 Table 3: JointNERandELresults. EachELaccuracy covers a different set of correctly detected mentions
sured over the subset of mentions whose reading was adequately selected by the final ranking. The evaluation of our system has been conducted over the corpus described previously with settings pre-sented in the next section.
5.3 Settings and results
We used each of the two available NER modules as a provider for entity mentions, either on its own or together with the second system, used as an indicator. For each of these settings, we tried a modified setting in which the prediction of the naive linker (NL) used to build the en-tity KB (section 2.2) was added as a feature to each mention/candidate pair (settingsSXPipe/NP -NL and LIANE-NL). These experiments’ results are reported in Table 3 and are given in terms of:
• NERprecision, recall and f-measure;
• EL accuracy over correctly recognized enti-ties; therefore, the different figures in col-umnELAccuracy are not directly
compara-ble to one another, as they are not obtained over the same set of mentions;
• joint NER+EL precision, recall and f-measure; the precision/recall is computed as the product of theNERprecision/recall by the ELaccuracy.
As expected, SXPipe/NPperforms better as far as NER precision is concerned, and LIANE per-forms better as far as NER recall is concerned.
However, the way we implemented hybridation at theNERlevel does not seem to bring improve-ments. Using the output of the naive linker as a feature leads to similar or slightly lowerNER pre-cision and recall. Finally, it is difficult to draw clear-cut comparative conclusions at this stage concerning the jointNER+ELtask.
6 Conclusion and Future Work
We have described and evaluated various settings for a jointNERandELsystem which relies on the
NERsystemsSXPipe/NPand LIANE for theNER
step. TheELstep relies on a hybrid model, i.e., a statistical model trained on a manually annotated corpus. It uses features extracted from a large cor-pus automatically annotated and where entity dis-ambiguations and matches were computed using a basic heuristic tool. The results given in the pre-vious section show that the joint model allows for goodNERresults over French data. The impact of the hybridation of the twoNERmodules over the EL task should be further evaluated. In particu-lar, we should investigate the situations where an mention was incorrectly detected (e.g., the span is not fully correct) although theELmodule linked it with the correct entity. Moreover, a detailed eval-uation of out-of-base linkings vs. linking in Aleda remains to be performed.
In the future, we aim at exploring various addi-tional features in theELsystem, in particular more combinations of the current features. The adapta-tion of our learning model to NERcombinations should also be improved. Finally, a larger set of training data should be considered. This shall be-come possible with the recent manual annotation of a half-million word French journalistic corpus.
References
F. Bechet and E Charton. 2010. Unsupervised knowl-edge acquisition for extracting named entities from speech. In 2010 IEEE International Conference on
Acoustics, Speech and Signal Processing.
R. Bunescu and M. Pasca. 2006. Using encyclope-dic knowledge for named entity disambiguation. In
Proceedings of EACL, volume 6, pages 9–16. F. B´echet, B. Sagot, and R. Stern. 2011.
Coop´eration de m´ethodes statistiques et sym-boliques pour l’adaptation non-supervis´ee d’un
syst`eme d’´etiquetage en entit´es nomm´ees. In Actes
de la Conf´erence TALN 2011, Montpellier, France. S. Cucerzan. 2007. Large-scale named entity
disam-biguation based on wikipedia data. In Proceedings
of EMNLP-CoNLL, volume 2007, pages 708–716. G. Doddington, A. Mitchell, M. Przybocki,
L. Ramshaw, S. Strassel, and R. Weischedel. 2004. The automatic content extraction (ace) program-tasks, data, and evaluation. In
Proceed-ings of LREC - Volume 4, pages 837–840.
M. Dredze, P. McNamee, D. Rao, A. Gerber, and T. Finin. 2010. Entity disambiguation for knowl-edge base population. In Proceedings of the 23rd
International Conference on Computational Lin-guistics, pages 277–285.
S. Galliano, G. Gravier, and L. Chaubard. 2009. The Ester 2 Evaluation Campaign for the Rich Tran-scription of French Radio Broadcasts. In
Inter-speech 2009.
E. Marsh and D. Perzanowski. 1998. Muc-7 eval-uation of ie technology: Overview of results. In
Proceedings of the Seventh Message Understanding Conference (MUC-7) - Volume 20.
P. McNamee and H.T. Dang. 2009. Overview of the tac 2009 knowledge base population track. In Text
Analysis Conference (TAC).
P. McNamee, H.T. Dang, H. Simpson, P. Schone, and S.M. Strassel. 2010. An evaluation of technologies for knowledge base population. Proc. LREC2010. B. Sagot and P. Boullier. 2008. SXPipe 2 :
ar-chitecture pour le traitement pr´esyntaxique de cor-pus bruts. Traitement Automatique des Langues (T.A.L.), 49(2):155–188.
B. Sagot and R. Stern. 2012. Aleda, a free large-scale entity database for French. In Proceedings of
LREC. To appear.
B. Sagot. 2010. The Lefff , a freely available and large-coverage morphological and syntactic lexicon for French. In Proceedings of the 7th Language
Resources and Evaluation Conference (LREC’10), Vallette, Malta.
R. Stern and B. Sagot. 2010. D´etection et r´esolution d’entit´es nomm´ees dans des d´epˆeches d’agence. In Actes de la Conf´erence TALN 2010, Montr´eal, Canada.
E. F. Tjong Kim Sang and F. De Meulder. 2003. In-troduction to the conll-2003 shared task: Language-independent named entity recognition. In
Proceed-ings of CoNLL, pages 142–147, Edmonton, Canada. W. Zhang, J. Su, C.L. Tan, and W.T. Wang. 2010. En-tity linking leveraging: automatically generated an-notation. In Proceedings of the 23rd International
Conference on Computational Linguistics, pages 1290–1298.
Z. Zheng, F. Li, M. Huang, and X. Zhu. 2010. Learn-ing to link entities with knowledge base. In Human
Language Technologies: The 2010 Annual Confer-ence of the North American Chapter of the Associa-tion for ComputaAssocia-tional Linguistics, pages 483–491.