Legal requirements on explainability in machine learning
Texte intégral
Figure
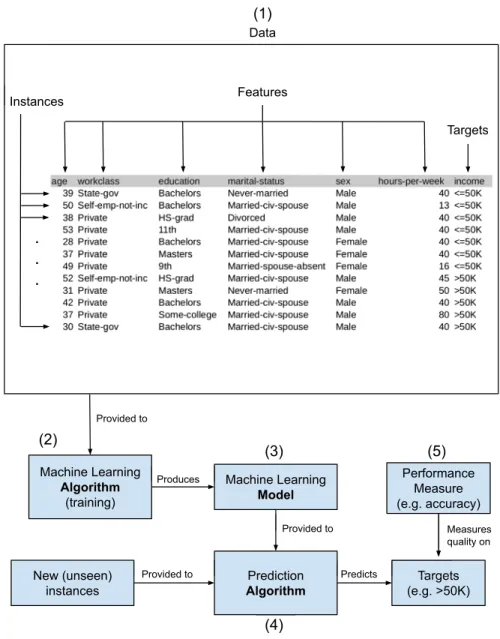
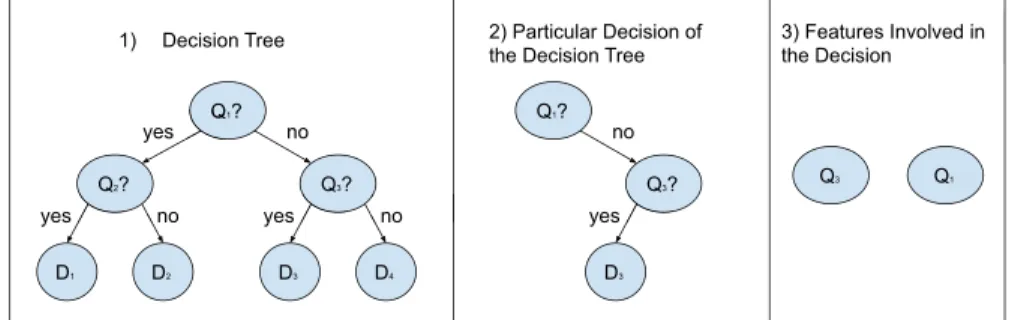
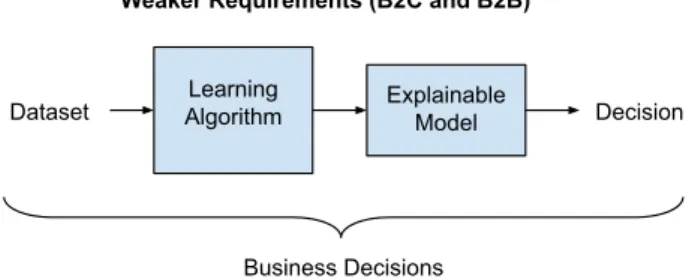


Documents relatifs
The algorithmic procedure for calculating crack growth in a solder joint with a given grain structure is visualized in figure
The expression of monomer availability can be obtained by multiply the monomer density and ratio of partition functions between surface (Z Ÿ ) and bulk (Z Ô ) [21]. This ratio
Participants then rated nine risk factors for tail-biting from 1 (no risk) to 10 (high risk). After training scores were better correlated with risk rankings already described
Therefore, the proposed core model of events in the legal domain has fulfilled the main requirements and covered different complex aspects of events such as
The results of the open-ended question Q1 show that the groups usually make decisions on stakeholder analysis, determining the sources of requirements, as well as functional
surrogate mother must pass the child to the genetic parents and the parents are obliged to take the child (recommended condition); the amount of compensation to the surrogate mother
Both approaches are ways to approach the construction of modern AI systems that could be employed in legal domains in a transparent way. Such work is only yet starting and
Therefore, Section 3.1 defines the role, description and requirements of the end- users and stakeholders for their participation in the KAP phase; Section 3.2 describes the
