FTL REPORT R87-2
AUTOMATED SPEECH RECOGNITION
IN
AIR TRAFFIC CONTROL
Thanassis
Trikas
FLIGHT TRANSPORTATION LABORATORY REPORT R87-2
AUTOMATED SPEECH RECOGNITION
IN AIR TRAFFIC
CONTROL
Thanassis
Trikas
AUTOMATED SPEECH RECOGNITION
IN AIR TRAFFIC CONTROL
by
THANASSIS TRIKAS
Abstract
Over the past few years, the technology and performance of Automated Speech Recog-nition (ASR) systems has been improving steadily. This has resulted in their successful use in a number of industrial applications. Motivated by this success, a look was taken at the application of ASR to Air Traffic Control, a task whose primary means of communication is verbal.
In particular, ASR, and audio playback was incorporated into an Air Tiraffic Control Simulation task in order to replace blip-drivers, people responsible for manually keying in verbal commands and simulating pilot responses. This was done through the use of a VOTAN VPC2000 ASR continuous speech recognition system which also possessed a digital recording capability.
Parsing systems were designed that utilized the syntax of ATC commands, as defined in the controller's handbook, in order to detect and correct recognition errors. As well, techniques whereby the user could correct any recognition errors himself were included.
Finally, some desirable features of ASR systems to be used in this environment were formulated based on the experience gained in the ATC simulation task and parser design. These predominantly include continuous speech recognition, a simple training procedure, and an open architecture to allow for the customization of the speech recognition to the particular task at hand required by the parser.
Acknowledgements
I would like to express my sincere gratitude and appreciation to the following people: Prof.
R. W. Simpson, my thesis advisor, for his suggestions and guidance; Dr. John Pararas, for all of his help and encouragement with every stage of this work; My fellow graduate students, Dave Weissbein, Mark Kolb, Ron LaJoie and Jim Butler for their help and friendship, both in and out of the classroom; and finally, my parents and brothers for their encouragement.
As well, I would also like to thank the NASA/FAA TRI-University Program for funding this research.
Contents
Abstract Acknowledgements iii 1 Introduction 1 1.1 Motivation . . . .. 1 1.2 Application Areas . . . . 31.2.1 ATC Command Recognition: Operational Environment . . . . 7
1.2.2 ATC Command Recognition: Simulation Environment . . . . 10
1.3 O utline ... . . . . 12
2 Automatic Speech Recognition 13 2.1 Introduction . . . . 13
2.2 How ASR Systems Work . . . . 15
2.3 Recognition Errors . . . . 21
2.3.1 Categorization . . . . 21
2.3.2 Factors Affecting Recognition . . . . 21
3 ASR Systems Selected for Experimentation 24 3.1 LISNER 1000 . . . . 24
3.1.1 Description . . . . 24
3.1.2 Evaluation and Testing . . . . 27
3.1.3 Recommendations . . . . 33
3.2 VOTAN VPC2000 System . . . . 36
3.2.1 Description . . . . 36
3.2.2 Evaluation and Testing . . . . 38
4 ATC Simulation Environment: Command Recognition System Design 44 4.1 ATC Simulation and Display . . . . 45
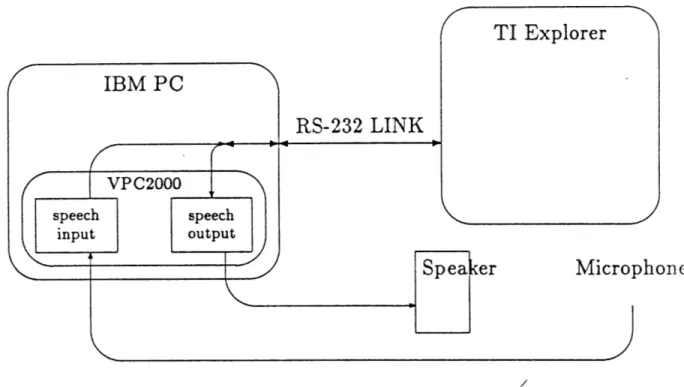
4.2 Speech Input Interface . . . . 48
4.2.1 ASR System . . . .. . . . 48
4.2.2 User Feedback and Prompting . . . . 50
4.2.3 Speech Input Parser . . . . 53
4.2.4 Discussion . . . . 77 - i i .i
-4.3 Pseudo-Pilot Responses . . . .. . . . . . . . 80
4.4 Discussion . . . - - . - - - - . .. . . . . . 85
5 Air Traffic Control Connand Recognition: Operational Applications 93 5.1 General Difficulties . . . - . . . . .. . . . . . . 93
5.1.1 Recognition of Aircraft Names . . . . 94
5.1.2 Issuance of Non-Standard Commands . . . . 95
5.2 Application Specific Difficulties . . . . 96
5.2.1 Digitized Command Transmission - Voice Channel Offloading . . . . . 96
5.2.2 Command Prestoring . . . 100
6 Conclusions and Recommendations 103 6.1 Sum m ary . . . 103
6.2 Recommendations . . . 104
6.3 Future Work . . . 110
-List of Figures
2.1 Block Diagram of Generic ASR system. . . . . 16
3.1 LIS'NER 1000 Functional Block Diagram. . . . . 25
3.2 Commands used in preliminary ASR system evaluation. . . . . 31
3.3 VAX Display for Command entry feedback. . . . . 32
3.4 Example of word boundary mis-alignment due to misrecognition errors. . . . 42
4.1 Configuration of ATC Simulation Hardware. . . . . 46
4.2 Icon used for display of fixes in the simulation display . . . .-. . . . . 47
4.3 Icon used for display of airports in the simulation display . ./. . . . . 47
4.4 Icon used for display of aircraft in the simulation display . . . . 48
4.5 Sample of the ATC Simulation Display on the TI Explorer. . . . . 49
4.6 Display format including feedback for spoken commands. . . . . 52
4.7 Example of the Finite State Machine logic for the specification of a heading . 55 4.8 Superblock structure of the FSM implemented. . . . . 57
4.9 Internal structure of the Aircraft Name Superblock . . . . 59
4.10 Internal structure of the Heading Command Superblock . . . . 60
4.11 Internal structure of the Altitude Command Superblock . . . . 61
4.12 Internal structure of the Airspeed Command Superblock . . . . 62
4.13 Airspeed Command Superblock maintaining original ATC syntax . . . . 63
4.14 Table of ATC Commands used in Pattern Matcher database . . . . 74
4.15 Flowchart of sequencing of VPC2000 functions . . . . 83
List of Tables
1.1 Table of ICAO Phonetics . . . . 6 3.1 Table of typical words used for ASR evaluation . . . . 28
4.1 Table of discrete messages recorded for Pseudo-pilot response formulation . . 81
-Chapter 1
Introduction
1.1
Motivation
Since airline deregulation, the amount of commercial air traffic has been steadily increas-ing. This increase has had two major repercussions.
First, as the amount of air traffic increases, the Air Traffic Control (ATC) system is rapidly approaching its saturation capacity. Thus, an ever increasing number of aircraft are being delayed, either on the ground at their originating airport, or in the air at their destination, until they can be accommodated by the ATC system. These delays, apart from being annoying from a traveler's point of view, are also the cause of increased fuel consumption and operating costs of aircraft waiting for take-off clearance or waiting for landing clearance. Since current air traffic growth trends are expected to continue, a great deal of study is being made into techniques for increasing the capacity of the ATC system as well as utilizing the existing capacity more efficiently. These techniques, although they often only involve procedural changes, almost always introduce a heavy reliance on computers and automation. Thus the Air Traffic Controller will more and more be forced to interface with computers in the execution of his everyday tasks in an increasingly automated system[1).
Second, the amount of air traffic for which controllers are responsible is also increasing. This, in conjunction with the loss of skilled personnel arising from the PATCO strike of
19811, means that air traffic controllers are working harder now than ever before. It is an
'Many people feel that only now is the ATC system beginning to return to the level of expertise and staffing that was prevalent before the PATCO strike.
issue of great concern since this increase in workload could possibly translate directly into a decrease in safety. In order to help alleviate this increase in workload, some airports increase the number of active controllers on duty during busy periods and give them each smaller sectors to control. Still, there are practical limits to this subdivision of sectors or the number of controllers on duty and for this reason, a greater and greater emphasis is being placed on automation in the ATC environment in order to reduce workload.
While the number and scope of automation strategies is fairly broad, all of these have one common factor; the dissemination of information from a human operator, typically the controller, to a computer. It is here where the increase in automation places the greatest strain. Speech recognition is a means of alleviating this by providing a simpler controller-computer interface as well as performance improvements not possible with more conventional interfaces.
Current input modalities such as the keyboard, special function keys, or a mouse (with pull down menus), although sufficient for a great number of tasks, can become somewhat awkward or clumsy in an ATC environment. This because the primary means of information transfer in ATC is verbal. Thus, it is conceivable that in some situations, information would have to be repeated twice, once through speech for humans, and another time through
key-boards for computers. For example, in today's semiautomated system, changes in flight plans
or cruising altitudes have to be transmitted by the controller through the voice channel to the pilots as well as entered through the keyboard into the computer in order to maintain the veracity and integrity of the flight plan database. This type of redundancy will become even more acute as more automation is introduced into the ATC system, with the obvious adverse effects on controller workload. The problem is more pronounced if the information must be entered in real-time in order to, for example, reflect the current state of an aircraft or number of aircraft in the ATC system.
Even if we ignore these real-time strategies and the requirement of redundant information transfer, speech still has a large number of benefits over more conventional input modalities
[2,3]. It is easier, simpler, less demanding and more natural than other more conventional
use2. It also allows the controller to use his eyes or hands simultaneously for other tasks, thus potentially allowing for multi-modal communication strategies (i.e., simultaneous use of more than one input modality such as keyboard and speech, or trackball and speech). The consequences of these factors are that the task may be performed faster or more accurately or that an extra operator may no longer be required.
These however are not the only possible benefits. Some studies indicate that under certain circumstances, memory retention in tasks performed using speech is often better than that using other input modalities. As well, speech is the highest capacity output channel of humans[4,5,6), yielding roughly a threefold (or more) improvement in data entry rates over a keyboard in problem solving tasks that require thinking and typing[2]. Thus, there are significant benefits to utilizing this channel in terms of operator workload reductions.
The goal of the work reported here is not to design an ASR system but instead to use an off the shelf system, applying it in the context of an ATC environment, in order to explore the potential benefits and problems in applying ASR to this environment. A secondary goal is to determine desirable features and requirements for an ASR system designed specifically for ATC. It is often lamented that one of the problems facing designers of ASR systems is that they do not have any specific criteria for their design (other than the obvious ones of low recognition error rates and delays)[2]. Granted, the required or desirable features may be dependent upon the exact ATC application, but it appears that there are some generalities that can still be made which could lead to an ASR system well suited for ATC applications as a whole.
1.2
Application Areas
Technically termed Automated Speech Recognition3 or ASR, the recognition of human speech by computers is a technology that is widely acclaimed as being "here". Although a
2
In practice however, some restrictions to the natural flexibility of speech must still be applied as shall be shown later.
3The term speech recognition should not be confused with the term voice recognition. The latter deals with the
recognition of a particular speaker based on his or her vocal patterns while the former deals with the actual recognition of what the speaker is saying.
lot of work is being and still remains to be done, ASR has already moved out of the realm of pure research and is being used successfully in industry, where significant operational benefits have been accrued [7,8,9]. Thus, although each particular application should be analyzed in its own right in order to determine its specific benefits and pitfalls, it appears that the significant amount of real-world practical experience and success with using this type of technology indicate that it is feasible. It is these successes and the rapidly advancing
state-of-the-art technology that have motivated interest in ASR systems and how they can
be used in an ATC environment4.
In general, tasks for which ASR should be considered for use are those which either cannot be accomplished using conventional methods such as the keyboard or trackball, or which in some way are being inadequately performed currently.
Initial applications of this type of technology in ATC would be in existing data-entry tasks. These tasks entail replacing or complementing more conventional input modalities, principally keyboards, with ASR in areas where the sole function is the straightforward entry of data into the computer[3,14).
There have, for example, already been studies into the use of speech input to replace keyboards in the flight-strip entry and updating functions [15]. It was found that under certain traffic conditions at even moderate traffic densities, it was possible for the controller responsible for maintaining this information to become overloaded. Thus, it would seem possible that data entry rates could be improved by using speech recognition. Although these studies demonstrated no significant difference in data entry rates over keyboards, ASR technology has advanced significantly since 1977 when the study took place and as such it is likely that improvements are now possible. Of primary significance is the fact that the recognition system used was a discrete speech system which is inherently slower and than a continuous speech recognition system. Therefore, it seems plausible that a continuous speech recognition system would provide improvements in data entry rates. Regardless of this, it was found that the error rate for entering flight data using ASR was lower than
'Although some mention will be given to ASR in the aircraft cockpit, this work deals primarily with applica-tions of ASR to the controllers task. The reader wishing further information on ASR in the cockpit is urged to consult, amongst others, the related articles [10,11,12,13).
that using a keyboard, indicating that there are indeed possible payoffs. In addition, even if no significant performance improvements can be realized, there is still the issue of which modality is preferred by controllers.
What will be covered in this work is a broad range of applications that involve the recognition, by computer, of verbal controller commands currently directed towards aircraft pilots. This for two reasons. First, this information, as shall be shown later, can be very useful when made available to automation systems and second, ATC commands, by design, contain features that are similar to those that yield optimum ASR performance. These features are as follows.
First, since there is only one user of the ASR system at each ATC sector, a speaker de-pendent recognition system (to be explained in Chapter 2) can be used. This is advantageous because speaker dependent systems are inherently more accurate than speaker independent systems which must recognize speech from a number of different speakers. Different con-trollers for any given sector can still be readily accommodated with this system simply by storing their speech data on a floppy or cassette and calling it up when they report onto the sector.
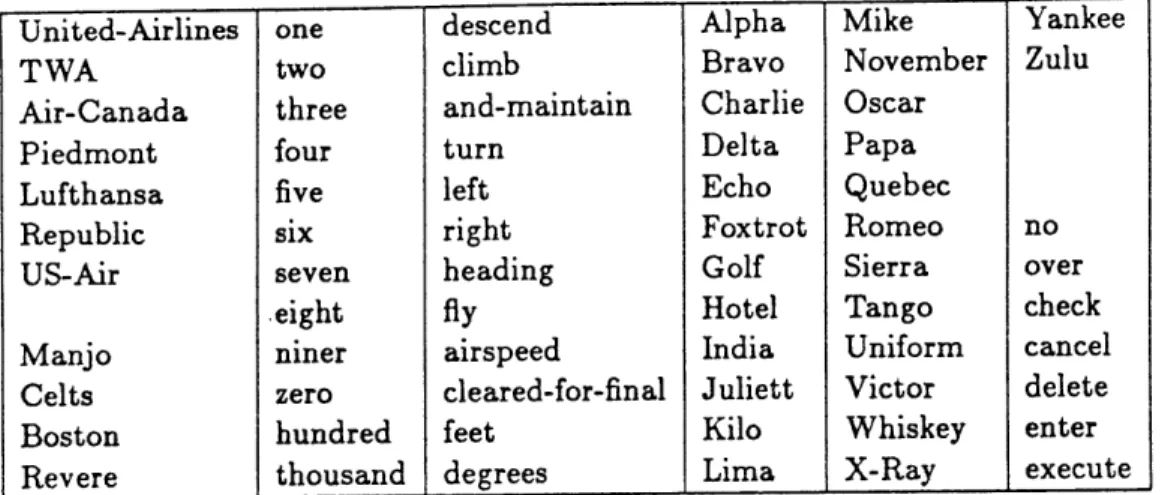
Second, the procedures used for communication between pilots and controllers are de-signed to reduce recognition errors made by communication over a possibly noisy radio chan-nel. Thus, similar sounding words that are easily confused by humans (and thus even more likely to be confused by an ASR system) have been eliminated. This is exemplified by the use of the word "niner" instead of "nine" in order to reduce the likelihood of confusion with the word "five". As well, short words such as the letters of the alphabet, which are also very difficult to recognize correctly, have been replaced by the "zulu" or phonetic alphabet[16] (see Table 1.1).
Finally and most importantly, the overall structure of ATC commands, in terms of their distinctness from one another and the rigid syntax that is used[16], coupled with the fact that the task is to recognize entire commands as opposed to individual words implies that there is a lot of additional information that can be brought to bear to aid in the recognition process.
Table 1.1: Table of ICAO Phonetics
Thus, for example, the ATC command syntax can be used to constrain the input to only those words that are syntactically valid and thereby reduce errors. T~is however is not of help in detecting errors between two syntactically valid words, such as two different numbers. Although it might seem over-restrictive to rigidly enforce this command syntax, this is not so. In fact, during training, controllers are forced to adhere fairly well to it, and most continue to do so throughout their careers.
There is however additional information contained in the rest of a command that provides further capability for error detection and correction. For example, consider the vectoring command "TWA turn left heading zero one zero". If the recognized command is "TWA turn left heading zero five zero" and the aircraft's heading is 040, then the "turn left" would signal, to the pilot for example, that a mistake has been made somewhere and that clarification should be requested. This same information that is used by the pilot is also potentially usable by an ASR system.
Another example of this occurs if the word "descend" is not recognized in a "descend and maintain five thousand" command. Here, it is still clear, based on the rest of the input, what the desired action is and this can potentially be used to infer what the un-recognized word was. A Alpha N November B Bravo 0 Oscar C Charlie P Papa D Delta
Q
Quebec E Echo R Romeo F Foxtrot S Sierra G Golf T Tango H Hotel U Uniform I India V Victor J Juliett W Whiskey K Kilo X X-ray L Lima Y Yankee M Mike Z ZuluIn fact, the human listener uses this same type of information to aid in the recognition process. This was demonstrated by Pollack and Pickett [17] who showed that roughly 20 to
30 percent of the words from tape-recorded conversations cannot be understood by a given
listener when they are played back individually in random order, even though every word was perfectly understood in the original conversation.
The actual ways in which the information made available through the recognition of Air Traffic Controller commands can be used are numerous and will be discussed in the following sections. They are loosely grouped into two classes called "Operational Applications" and "Simulation Applications". These involve applications in the current or projected operational environment and in the simulation environment respectively.
1.2.1 ATC Command Recognition: Operational Environment
By far the simplest application of Air Traffic Control Command Recognition, or ATCCR,
would be to use it in order to provide a memory aid to controllers. Here, ATCCR could be used to recognize controller commands issued to pilots directly (without the need to type them in) and display them on a scrolling history of issued commands. This could possibly be used by the controller in order to determine which commands have already been issued since, during high workload situations, it is possible to forget these. Because the ASR system would not be a direct part of ATC operations in this application, recognition errors would not have any significant effects on the controller's performance of his duties. Thus, this type of system could be used in order to generate data on the recognition accuracy and error rates in a real-world ATC environment, as a precursor to the implementation of ATCCR for other tasks. As well, it would create a database of controller commands issued in a format readily readable by a computer and would thus allow for computer analysis of different aspects of controller operating procedure.
Once some practical experience has been gained with ATCCR, a far more ambitious application can be undertaken. This would be to use speech recognition to allow the computer system to listen in to the commands issued by the controller and responses issued by pilots. This information, in conjunction with the other information available to the computer (such
as radar tracks, minimum safe altitudes, restricted zones, etc.) could be used to provide a backup controller to catch any potentially dangerous situations that might be missed by the controller. The system would in effect provide for conformance monitoring and conflict alert. This application however is extremely difficult since it requires not only very good speech recognizer performance, but also the integration of a large number of different technologies including such fields as AI and Natural Language Understanding. This task is also greatly complicated by the difficulties involved in the recognition of pilot transmissions arising not only from the noise and low bandwidth of the radio channel, but also from the great variability possible in pilot speech.
As mentioned previously, one of the primary motivating factors for the use of ASR relates to the increase in automation in the ATC environment. This increase in automation is not only occurring on the ground, but in the air as well. As more and more new aircraft progress to "digital" cockpits, it is becoming increasingly obvious that there would be significant benefits to linking these two systems together digitally, in a format that would allow direct communication between ground controller, ground computer, airborne computer and pilot, as opposed to verbally from controller to pilot as is the case now. This could be accomplished using by using ATCCR to first recognize the controller's commands and then transmit a representation of these to the specified aircraft5. Once received by the aircraft, they could then be reproduced, for presentation to the pilot, either aurally, using, for example a speech synthesizer, or visually using a standard display.
With this configuration, one can easily envision a future system where the flight director in an aircraft would receive commands directly from the controller and his computer and then, pending acknowledgment and verification from the pilot, execute them[10].
The benefits that can be accrued with this digital link between air and ground are nu-merous. Most importantly, message intelligibility could be enhanced significantly. Currently, commands transmitted over a noisy and often over-used radio channel are somewhat difficult to make out and often result in errors made by pilots. Messages transmitted in a digital
'Although the exact method by which this transmission would take place remains to be seen, it could be accomplished using the digital communication capability made possible by Mode S.
format however are less likely to be corrupted by noise. Even if they are, checks can easily be made as to their integrity. Furthermore, since these commands are now in a format where they can be readily manipulated by computer, they can be made available for recall by the pilot in order to avoid the need for the controller to repeat or re-issue commands should the pilot forget them.
The increased use of this digital link would also greatly off-load the voice channel. This, would improve the intelligibility of any verbal communications made using it, as well as increase the effective bandwidth of the controller-pilot communication channel as a whole.
Although more conventional technology in the form of vocoders6 could also be used for
command digitization, again, without requiring the controller to key in his command, ASR possesses significant advantages over these. First, current vocoders operate at a minimum of about 1200 baud. ASR systems however can reduce this to something on the order of 200 baud if straight recognized text is transmitted, and even lower if this text is further compressed. Thus, much less of a strain on the bandwidth of the digital link is incurred using an ASR system.
Second, since vocoders simply sample the speech waveform, the only way of recreating and presenting the digitized information transmitted is to reproduce the original audio signal. This however results in a format that is unusable by a computer and as such, the issued command could not be displayed visually to the pilot, or used in any future automation functions unless it was also keyed into the computer.
In a command digitization and transmission application scenario such as the one de-scribed earlier, another problem, arising from the mix of "digital" and conventional aircraft, is created. In particular, it would be necessary for controllers to keep track of which aircraft must be "spoken" to and which can have keyed commands/information sent to them. If ASR is used, possibly in conjunction with keyboards and/or other input modalities, then it would be possible, if he so desires, for the controller to issue commands verbally to all of the aircraft. It would then be up to the computer to determine the capabilities of the aircraft being referred to. If it possesses "digital" capability, then then the verbal message
6
would be sent digitally. If not, the message could be sent verbally over the radio link, either through reproduction by a speech synthesizer of some sort (advantages in terms of a distinct voice over a possibly cluttered radio channel, disadvantages in terms of intelligibility) or by replaying a recording of the message made as it was previously said by the controller.
A further application of ATCCR, although one for which ATCCR is not essential, is to
allow for the prestoring and automatic (or semi-automatic) issuance of clearances to aircraft. In practice, the controller can often anticipate what clearances should be issued to aircraft often minutes in advance. Thus, with an ATCCR system, he could pre-store these clearances for issue later by the computer and divert some of his attention to other tasks. These clearances could be transmitted, as described earlier for the digital cockpit scenario, either digitally or verbally depending on aircraft capabilities.
The actual issuance of these clearances could be accomplished either by simply recalling the clearance from the computer when it is desired, or by having the computer automat-ically monitor the specified aircraft to determine when it should be issued. Granted, the controller might want to validate or acknowledge every command sent to the aircraft by the computer, but this could be done by simply prompting the user whenever it is time to trans-mit a command and asking if the command should still be issued. In this way, the ultimate responsibility still lies with the ATC controller.
1.2.2 ATC Command Recognition: Simulation Environment
Before any of the (aforementioned) real-world applications of Air Traffic Controller com-mand recognition can be studied and evaluated, a facility to demonstrate them in an envi-ronment typical of Air Traffic Control should be available. For this reason, one of the initial goals of this work was the incorporation of ASR into an existing real-time ATC simulation.
In investigating the configuration of this simulation, it was readily apparent that it, in itself, was an ideal application of ATC command recognition. In particular, current real time
ATC simulations use what are called pseudo-pilots or blip drivers. These are people whose
task it is to translate verbal commands from the subject controller involved in the simulation into typed commands that are keyed into a computer. The use of these people adds to the
cost and complexity of the experiments using the simulation. ASR would allow these people to be replaced by a direct data path from the subject controller to the simulation computer. Granted, this is not likely to have the flexibility that is available with a human blip driver, but the advantages in terms of cost and manpower requirements could possibly outweigh this.
The other function often performed by blip-drivers is the simulation of pilot responses to the controller in order to add to the fidelity of the simulation for certain ATC research. This function can also be replaced by the computer by using computer generated verbal responses. This technology is much more mature and does not pose the same types of technological problems posed by ASR. Computer generated responses can be produced in basically two ways. The first is through a rule-based text-to-speech synthesizer. This takes written text and through a series of often empirically derived algorithms or rules, specifies the output of an electronic sound synthesis circuit in order to generate an imitation of human speech. The major drawbacks of this system are perception or intelligibility problems that arise due to the flat monotone and "robot" like quality of the speech output. Most systems available however, provide at least some ability for the user to specify stress and intonation patterns, in order to make the output more intelligible (see related articles [18,19,20,21,22,23]). Such a system's advantages lie in its flexibility, in that there is no requirement to know beforehand exactly what the words or phrases that the system will be required to say are.
The second method for simulating pilot responses utilizes pre-recorded messages and plays them back in a specified order as required by the user. An example of this kind of system is the response when requesting a telephone number from Information. This technique results in messages that are more intelligible than text-to-speech because they are in fact, simply tape or digital recordings of human speech. It is however, far less flexible in that all possible messages must be recorded beforehand. As well, it requires a lot of memory to store these pre-recorded messages in the computer although there are a number of techniques to reduce this [24,25). Furthermore there is the difficulty of introducing intonation and emphasis into the speech output since this requires that all possible occurrences of these can be predicted beforehand and suitable messages recorded.
Recognition errors can be handled much more easily in the simulation environment. If one occurs, the computer can simply respond with a verbal "Say again." message thus adding even more to the realism of the simulation. Note that recognition error rates must be kept fairly low since a system that responds with "Say Again." too often is not very practical.
1.3
Outline
As has been shown, there is quite a variety of possible applications arising from the use of ASR to recognize Air Traffic Controller verbal commands. Some of these, although still potentially useful, might turn out to be impractical especially in light of current technology.
Thus, this work will explore these applications in more detail.
Before commencing on a description of the work performed and the results obtained, it is important to first define some terms and concepts dealing with ASR systems. These are covered in Chapter 2. The reader wishing more detailed information is urged to consult the references.
In Chapter 3, the ASR systems that were purchased and used are described with particular reference to the features that were found to be desirable.
The work performed was concerned predominantly with the development of both speech input and output capabilities for an ATC terminal area simulation. In Chapter 4, the imple-mentation of this task is detailed. In particular, the design of a system for ATC command recognition (ATCCR) will be presented. Integral to this are such things as the methods used to incorporate ATC syntax requirements and constraints as well as the handling of recognition errors, both their detection and correction.
In Chapter 5, some of the operational applications of ATCCR alluded to earlier are revisited and analyzed in greater detail as to their feasibility and possible shortcomings, based on the experience gained from the Simulation application.
Finally, Chapter 6 outlines the conclusions of this work, along with suitable recommenda-tions for further work both with the existing hardware as well as with new technology ASR systems that are currently appearing on the market.
Chapter 2
Automatic Speech Recognition
2.1
Introduction
The basic purpose of a speech recognition system is to recognize verbal input from some pre-defined vocabulary and to translate it into a string of alphanumeric characters. Before beginning a description of how these systems work however, it is first important to present some general categorizations of the systems that are available. In general, ASR systems can be categorized based on three different features and capabilities. These are:
1. Speaker Dependence/Independence
2. Discrete/Connected/Continuous Speech Recognition
3. Vocabulary Size
The first of these deals with whether or not the system is designed to be used by only one speaker at a time. If it is speaker dependent, then it must be trained to a particular user's vocal patterns, typically by having him repeat to the system all of the words that are desired for it to recognize. With speaker independent systems, there is no need for this extensive training procedure because some basic information about how the words in the vocabulary are spoken is usually incorporated directly into the system. In general however, the speaker dependence distinction is one that is closely related to accuracy. A speaker dependent system can be made somewhat speaker independent simply by having multiple users train the system to their voices. Thus, it would possess data from a spectrum of speakers
and should in theory be able to recognize speech from any speakers with roughly similar vocal patterns. If it possessed sufficient accuracy, then it could be termed speaker dependent. Its accuracy however, would tend not to be as good as a system that was explicitly designed for speaker independence.
The second categorization deals with the type of speech input that is allowable. For discrete speech recognition systems, it is assumed that the words or utterances contained in the vocabulary will be spoken with a brief period of silence in between. This period of silence is typically on the order of 150 to 200 msec long and is used to delineate utterances, thereby allowing a simpler and more accurate recognition algorithm to be implemented.
These utterances are in general not restricted to being single words. In fact, they can be entire phrases. Individual words contained in these phrases however cannot be recognized unless they have been trained as such.
Connected word recognition systems, however, impose fewer restrictions on the user in that these periods of silence need not occur after every word. Thus, the user can run words together during his speech. Every so often however, a pause must still be included (the actual recognition of the speech does not commence until this is detected). This is not much of a problem since normal speech tends to be liberally sprinkled with these pauses.
Continuous speech recognition systems provide the most flexibility in how the user speaks. With them, there is no requirement for the user to pause anywhere during speech input. Unlike connected systems, recognition is performed as the words are spoken. Thus, it is possible for words at the beginning of a stream of continuous speech to be recognized before the user is finished talking or has paused.
The third categorization deals with how many words can be recognized by the ASR system. This varies a great deal from system to system. In general, the limiting factor in vocabulary size is the inherent accuracy of the recognition system. The higher the accuracy, the larger the vocabulary possible. This is why speaker independent systems which, as a rule, possess lower recognition accuracies than comparable speaker dependent systems, have smaller vocabularies.
This can be very cumbersome and time consuming for large vocabularies and thus limits the practical size of the vocabulary to roughly 100 words or so. Other systems however, use training procedures that do not require each word to be explicitly trained. With these systems, the vocabulary size is often in the hundreds or thousands of words.
In defining vocabulary size, there is another factor to consider. This involves the capability of some systems to activate only certain sections of the entire vocabulary. Hence, a better indicator of performance is the size of the active or instantaneous vocabulary. Clearly the larger the active vocabulary, the greater the likelihood of recognition errors and the larger the recognition delays since more comparisons must be performed.
2.2
How ASR Systems Work
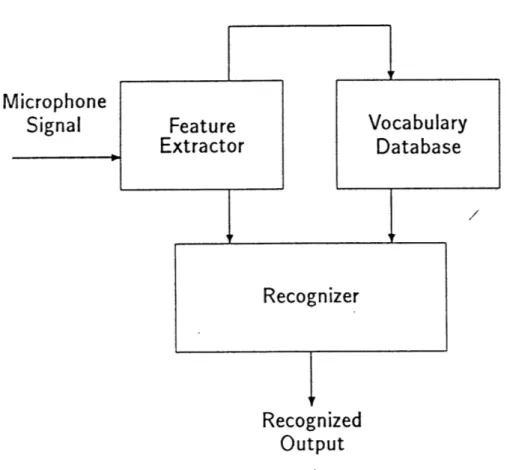
Although the actual details of how ASR systems work varies a great deal from system to system, their basic internal structure is very similar. It consists of a Feature Extractor, a Recognizer and a Vocabulary Database as indicated in Figure 2.1.
The feature extractor is basically responsible for analyzing the incoming speech input signal and extracting data from it in a format that can be used by the recognition algorithm. The recognition algorithm then takes this data and compares it to data in the vocabulary database in order to determine which, if any, word was said.
The vocabulary database contains all of the words that can be recognized by the ASR system. It is created by having the user train or enroll onto the system or through purely theoretical means. In the simplest training procedure, the user simply repeats, a given number of times, all of the words contained in the vocabulary so as to provide the ASR system with information as to how these words "look" when spoken. This information is then used to create a set of reference patterns or templates each one describing a particular word. Other training procedures however, are much simpler and only require the user to read a few paragraphs of text aloud from which the ASR system extracts information about how the user articulates his words and in this way, generates the required templates.
Microphone
Signal
Recognized
Output
Figure 2.1: Block Diagram of Generic ASR system.
Vocabulary
Database
primary responsibility of the Feature Extractor. The simplest form of feature extraction is to sample the incoming speech signal. Since the bandwidth of human speech is roughly 4kHz, this implies a sampling rate of at least 8kHz minimum. At this rate, 8 kbytes of data (assuming 8 bit quantization of the data) are produced for every second of speech. This creates serious problems both in terms of memory requirements as well as recognition delays (it takes a long time to process this much data). For this reason, alternative techniques are used in order to reduce the data rates required.
One of the simplest and most successful of these takes advantage of the fact that the frequency spectrum of the speech signal, although it varies in time, does not vary quickly. Thus, if the signal is passed through a bank of bandpass filters in order to determine its spectrum, these can be sampled at rates much slower than 8 kHz (typically at rates near 100
Hz).
Another successful technique to reduce data rates is to use Linear Predictive Coding or LPC [26]. Here, an estimate is made of the present value of the input signal based on a linear combination of the last n values, in conjunction with an all pole model of the vocal tract. The output of this system is then related to the coefficients that minimize the estimation or prediction error and again produces data at a rate of roughly 100 Hz.
In some systems, this data is further processed to produce a more compact representation. For example, in vector quantization, each data sample (it is usually a vector of data) is compared to a set of standard reference frames and replaced by a symbol associated with the frame that best matches it. Thus, the output of the feature extractor can be transformed into a sequence of symbols.
In a slightly more complex system, the incoming speech signal undergoes more extensive processing in order to recognize the actual phonemes that it contains. Phonemes are the different sounds that are made during speech (eg; "oo", "ah", and so on) and form a set of basic building blocks for speech. Both the number and the actual phonemes themselves differ somewhat from language to language but they are relatively constant for a given language. There are roughly forty different phonemes contained in the English language [243. Thus, the speech signal can be characterized by roughly forty different symbols. Thus, the data
rates generated by the feature extractor are very low, on the order of 50-100 Hz. Feature extractors of this sort are potentially more accurate in that they try to extract the same features from the speech signal that the user consciously tries to reproduce when he says a word.
In any case, no matter what the data outputted by the feature extractor actually repre-sents, there is a lot of similarity in how it is subsequently processed.
In a discrete speech recognition system for example, the data output by the feature extractor is saved in a buffer until the end of a word, as indicated by a short period of silence, is detected. This yields a matrix of data, assuming that the feature extractor outputs data in the form of frames or vectors of data, whose one axis corresponds to time. This matrix or pattern is then compared to patterns contained in the Vocabulary database that were generated in a similar manner while the user was training the system. Here, a problem is readily evident. Because different words and even different vocalizations of the same word are different lengths, a common reference for comparison must be found. A simple way to accomplish this is to time-normalize the patterns, so that they are of uniform length, by merging adjacent frames together or by interpolating between them as required. If this is done uniformly along the length, or time axis, of the matrix or pattern, then it is termed
linear time-normalization.
Now that the two patterns are the same length, they can be compared to determine whether or not they match. The actual method of doing this again varies from system to system. The simplest involves measuring the norm of the difference between the two matrices in order to compute the distance between them. The most common norm used is the Euclidean or 2-norm which is simply the square root of the sum of the squares of each entry in the difference matrix. There are in addition, other more complicated and computationaly intensive methods for distance measure but these are described elsewhere [26,24,27]. If the distance between these two patterns is lower than a prespecified threshold, then a match is declared. This threshold test prevents random noises such as doors slamming
and phones ringing from creating false recognitions.
dra-matically as the size of the vocabulary increases (they are typically confined to vocabulary sizes on the order of 20 to 40 words). This is primarily because the time normalization procedure obscures a lot of the features of the spoken word. Furthermore, if one examines an utterance closely, it can be seen that when its length changes, it does not do so uniformly (linearly) along the length of the word. Consider the word "five". If the duration of this word is increased as it is. spoken, it can be seen that most of the stretching occurs in the "i" sound and not the
f"
and "v". In order to more readily account for this phenomenon, anon-linear time normalization technique is used. With this technique, time normalization is
accomplished by aligning features found in the reference and input patterns in such a way as to obtain the best match. Since the number of possible non-linear time alignments can be quite numerous, dynamic programming techniques are used to eliminate some of these and thereby reduce the computational complexity of this algorithm. For this reason, this technique is often termed Dynamic Time Warping (DTW).
DTW not only yields greatly improved results for discrete speech, but it can readily be extended to both connected and continuous speech recognition. The process of extending this procedure to connected speech is fairly straightforward and consists of finding a similar non-linear alignment, but this time relating the entire spoken input phrase to a super-pattern consisting of the "best" sequence of reference patterns. This "best" sequence of words is then the recognized phrase.
This procedure is modified in continuous speech recognition systems so that non-linear time alignments between reference and input templates are calculated as the speech comes in. In this way, when the score of the comparisons using this alignment dips below a certain threshold, a match is declared and the normalization procedure is begun anew from the point where this current matched pattern ended'. Thus, the principal difference between this and connected speech recognition lies in where recognition events occur.
With these systems however, some problems arise due to the differences between words when spoken in discrete as opposed to continuous or connected speech. First of all, words tend to be shorter when spoken as part of a continuous stream than when spoken individually.
The resulting differences in length are sometimes too excessive for the recognition algorithm to handle and thus errors result. Furthermore, the actual articulation of adjacent words is sometimes changed significantly due to the slurring together of words. This phenomenon, termed co-articulation often results in sounds that were not part of either individual word. A good example of this occurs when the words "did you" are spoken quickly. The result sounds more like "dija" than anything else and unless allowances are made for this, it is certain to cause recognition errors.
In order to attempt to take this into account, some systems use what is termed embedded or
in phrase training. With this, vocabulary words are trained as part of a stream of continuous
speech in order to include co-articulation effects on word boundaries. This however is not very general since these effects are to a great deal dependent on exactly what the surrounding words are and it is unrealistic to train for all possible word combinations.
It is in order to account for some of these variations in how words/are said that other procedures are being used as well'. These include such techniques as statistically based DTW
[29) as well as a process known as Hidden Markov Modeling (HMM) [30,31].
In a standard Markov Model, the various vocalizations of a word are used in order to con-struct a finite state machine type con-structure where each state is associated with a particular data frame or feature and each branch with the probability of receiving that feature. With HMM however, this one-to-one correspondence between states and features is eliminated. In-stead, each state is probabilistically associated with a number of features. Since assumptions are no longer made about exactly which features are required in the input, and the actual feature (or state) sequence is hidden, the number of states that are required to represent an utterance can be reduced without a large degradation in performance. This also allows for some errors to be made during the feature extraction process. The training procedure for a system using HMM however is quite time consuming since quite a few repetitions of each word must be used in order to evaluate the probabilities associated with each of the branches of the finite state machine.
2
Only the gross variabilities have been presented so far. There are other, somewhat smaller, but potentially equally significant sources of variability and these will be discussed in Section 2.3.2.
Thus, it can be seen that there are quite a few different techniques for recognizing speech. This section has presented a brief introduction into some of these in order to provide the reader with some necessary background. If more detailed information is desired, then addi-tional references should be consulted.
2.3. Recognition Errors
2.3.1
Categorization
Any speech recognition system, even human, is certain to make at least some recognition errors. The difference between systems lies however in the rate at which these errors occur and in the inherent capabilities for recovering from them and correcting for them. In general, recognition errors fall into three major categories.
1. Mis-recognition errors are those in which one word is mistaken for another. This also
implies that the comparison successfully passed any recognition threshold tests. 2. Non-recognition errors are those in which spoken words, that are members of the
current active vocabulary, are not recognized at all. This is usually because the utter-ance, when spoken, is sufficiently different from that as trained so that the recognition threshold is not passed. Some reasons why these differences arise will be discussed later.
3. Spurious-recognition errors are those in which the ASR system indicates that a word
was spoken when in fact none was. These typically arise when extraneous noises are mistaken for speech.
In general, the occurrence of these types of errors is very dependent on both the particular recognition system that is being used as well as its operating parameters such as recognition thresholds.
2.3.2
Factors Affecting Recognition
More important than the types of recognition errors are the questions of how and why they occur and what affects their frequency. It is by understanding these issues that error
rates can be reduced. In general, since ASR systems are simply pattern matchers, it is obvious that anything creating differences between these patterns as they are trained and as they are produced during speech will increase the error rates.
These factors can range from stress, high workload, and nervousness on the part of the user when speaking to the system to such things as day to day variations in his speech possibly arising from such things as fatigue and colds. Some systems try to counter some of these day to day variations by putting the speakers through a short enrollment session each time they begin to use the system. In this, the user simply reads a short phrase prior to using the system in order to allow the recognition system to adapt to how he is speaking that particular day or session.
Other factors affecting recognition accuracy include environmental or background noise. This can affect recognition accuracy in three basic ways. First, it can lead to spurious recognitions through the ASR systems' mistaking of these sounds for valid speech input. Second, users might be forced to change their articulation in order to compensate for and be heard over background noises, and third, the noise might actually corrupt the speech signal itself and mask a lot of information. While some systems simply use a noise canceling microphone to counteract these, this is sometimes not sufficient and techniques to more directly account for background noise must be incorporated into the recognition algorithm itself.
The type of microphone used can have even further effects on recognition accuracy [37,38}. In particular, microphones with a poor frequency response or highly non-linear or time vary-ing response will greatly affect the quality and constancy of the signal made available to the ASR system. The end result might be that not enough "clean" signal is available to the ASR system for it to accurately discern between the utterances spoken.
To a great extent, it is the training procedure itself that produces a lot of the differences between templates and the words as they are usually spoken. This is because users often train the vocabulary words in a way that is significantly different from the way that they actually say them. This is termed the training effect and is caused by nervousness or hesitance on the part of the user. Furthermore, they are often simply reading words off a list and this
results in different pronunciations of words. Granted, one would desire a system that is not sensitive to variations this small in the way that words are spoken however, most systems, especially speaker dependent continuous speech ones are, unfortunately.
As mentioned earlier, speaker dependency is closely tied to recognition accuracy. In general, speaker independent systems are much less sensitive too the types of variations mentioned earlier, but are consequently also much less accurate than speaker dependent systems since they must accommodate a much broader range in how words are said. These variations come not only from pitch and inflection changes from user to user, but also from dialect and accent. In order to keep error rates reasonable, these systems tend to confine themselves to small vocabularies. Conversely, speaker dependent systems are trained by the eventual user and hence know with much greater accuracy, how each of the words said by the user would appear. This is analogous to a human's ability to recognize more easily the speech of someone with whom they are familiar.
Chapter 3
ASR
Systems Selected for
Experimentation
In selecting an ASR system for this research, a two step approach was taken. First, an inexpensive, low performance, system was purchased. This was done in order to give a better insight into ASR technology so that the requirements and desirable features of a higher performance system to be used in subsequent research and development could be more accurately defined.
The goal of this work, as stated previously, was to obtain some practical information about the incorporation of ASR in ATC. It was not to test and document the performance of a number of ASR systems currently on the market. As such, the evaluation details and results are presented in an exploratory, qualitative, rather than a quantitative manner. It was felt that this would give the reader a better idea of the problems typically encountered using this type of technology, without creating a false sense of confidence in performance figures which are, after all, highly subject to a number of factors and difficult to duplicate from test to test.
3.1
LISNER 1000
3.1.1 Description
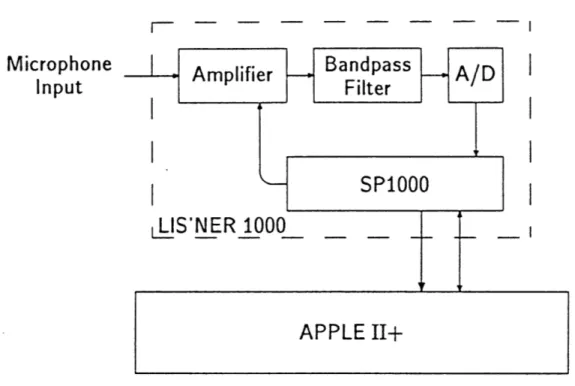
The ASR system purchased for initial evaluation was the LIS'NER 1000 system produced
Microphone
Amplifier
Bandpass
A/D
Input
Filter
SP1000
LIS'NER 1000
APPLE
II+
Figure 3.1: LIS'NER 1000 Functional Block Diagram.
software, for the APPLE II family of home computers and cost $250 at the time of purchase in May 1985.
The LIS'NER 1000 ASR system is a speaker dependent, discrete word recognition sys-tem[27,32,33]. Total vocabulary is 64 words or utterances.
A block diagram of the system hardware is shown in Figure 3.1. Its basic operation is as
follows. First, the signal from a headset mounted electret microphone is filtered to prevent aliasing and remove low frequency biases. It is then digitized by an A-to-D and sampled by the SP1000 chip at a rate of 6.5 khz. The SP1000 uses this incoming signal to generate LPC data. This LPC data is organized in frames, each frame consisting of 8 LPC and one energy parameter, and is made available to the APPLE at a rate of 50 hz. It is this data that is used by the system in the recognition process.
During normal operation, a value for the background noise is constantly being monitored
by looking at the energy level of the incoming signal. A significant increase in the energy of
the SP1000 is then saved in a buffer until the end of the word is detected. This is specified
by a period of silence (roughly 200 msec) determined, again, by looking at the energy of the
incoming signal. The resulting data is compressed or time normalized into a block of data 12 frames long to allow for a more uniform means of comparison as well as to minimize the amount of data that must be stored. This compression is accomplished by merging together any adjacent frames that are very similar. Thus, any "interesting" features of the waveform are preserved.
What is then done differs depending upon whether the user is in recognition or training mode. In training mode, this data is averaged with data from previous vocalizations of the same utterance to form a template. Currently, the software requires that each utterance be repeated twice during training. When all of the utterances in the vocabulary have been
repeated twice, the training phase is finished.
In recognition mode however, the resulting data is compared to the vocabulary templates to find the best match. This comparison is performed using dynamic time warping and a Euclidean norm as a distance measure. The template that possesses the shortest distance is the one that is selected as the best match. This distance however, must be greater than a minimum threshold (termed the acceptance threshold). This threshold provides a trade-off between unrecognized words and false recognitions. If it is too low, then valid utterances will not be successfully recognized. If it too high, then utterances not in the vocabulary or spurious noises will be misrecognized as valid words.
Since the time to recognize a word depends directly on the number of words or templates in the vocabulary, a small trick is used to reduce the search time. This involves examining the distance measure as it is computed for each template. If the distance is less than a certain prespecified threshold (termed the lower threshold), then that template is treated as the best match and no further computations are performed. As well, if the distance is greater than a third threshold value (termed the upper threshold), all further comparisons to the utterance are stopped. This hopefully allows the system to quickly disregard spurious noises such as doors slamming, phones ringing, and so on since these will likely result in distances that are greater than the upper threshold in almost all cases. Those cases of spurious noise that
do pass this test however, will still not likely cause recognition errors due to the acceptance
threshold test.
A useful feature incorporated into this system is the ability to divide the entire trained
vocabulary into what are termed groups, by assigning every trained utterance to a particular group. Using these, an active vocabulary, that is to say, the vocabulary of words or utterances which is searched through during the recognition algorithm, can be reduced to a subset of the total trained vocabulary. Once a word is recognized, a search byte for the group containing the recognized word is used to specify which groups comprise the new active vocabulary. Since reduction of the size of the active vocabulary reduces the number of comparisons that must be made by the recognition algorithm it has the potential for decreasing recognition delays as well as reducing the probability of mis-recognition errors. This grouping structure however, is not entirely arbitrary as each trained word can occur only in one group and a search byte can only be specified on a group by group instead of on a word by word, basis.
3.1.2 Evaluation and Testing
There were basically two modes of testing that were performed on the Lis'ner 1000. The first involved the straightforward training of a particular vocabulary and subsequent testing of the recognition accuracy and other parameters on a word by word basis while the second involved the recognition of entire sequences of words, in sentences typical of ATC commands.
Word Entry
The primary goal of testing on a word by word basis was to study basic parameters of interest such as recognition speeds, delays, and accuracy. This was accomplished by having the user talk to the LIS'NER 1000 and having the APPLE display on its screen a representation of the recognized utterance.
The testing was performed with a value of zero for the lower threshold. This meant that the distance between any template and an utterance had to be less than zero, clearly an impossibility, for the template to be declared a match and all further comparisons stopped. Thus it forced the recognition algorithm to search through the entire active vocabulary. As