Improving bag-of-poses with semi-temporal pose descriptors for skeleton-based action recognition
Texte intégral
Figure




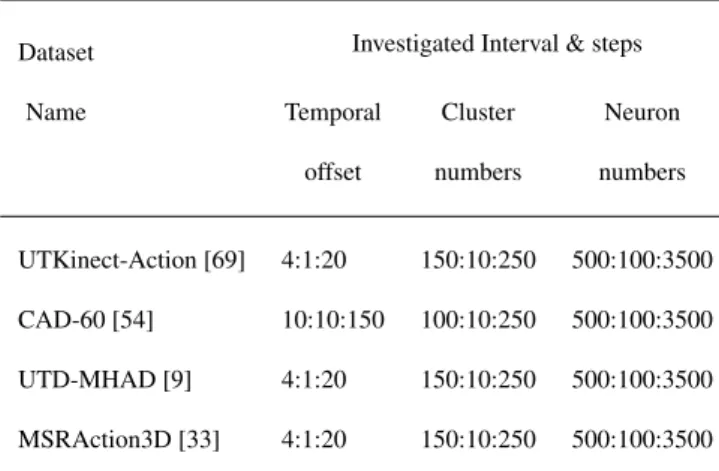
![Table 3: Comparison with the state-of-the-art results on UTKinect-Actiondataset Feature Engineering Method Accuracy (%) Hand-crafted HOJ3D [69] (LOSeqO) 90.92Lie Group [59]97.8 Spatiotemporal SHs [73] 93.0 Our method 98.98 Learned representations RDF-based](https://thumb-eu.123doks.com/thumbv2/123doknet/13643204.427617/19.892.62.405.219.839/comparison-utkinect-actiondataset-feature-engineering-accuracy-spatiotemporal-representations.webp)

Documents relatifs
Wang, “Hierarchical recurrent neural network for skeleton based action recognition,” in IEEE conference on computer vision and pattern recognition (CVPR), 2015, pp. Schmid,
Appearance and flow informa- tion is extracted at characteristic positions obtained from human pose and aggregated over frames of a video.. Our P-CNN description is shown to
Subsequently, an LSTM based network is proposed in order to estimate the temporal dependency between noisy skeleton pose estimates.. To that end, we proposed two main components: (1)
Second, a two-stage method for 3D skeleton-based action detection is proposed which uses hand-crafted features in the action localization stage and deep features in the
In this paper, we proposed a new view-invariant action recognition system using only RGB information. This is achieved by estimating the 3D skeleton information of the subject
DataBase Set of features used Results UCLIC All features 78% UCLIC Only geometric features 66% UCLIC Only motion features 52% UCLIC Only Fourier features 61% SIGGRAPH All features
Northwestern-UCLA dataset: The dataset contains 10 types of action sequences taken from three differ- ent point of views. Ten different subjects performed each action up to 10
