Notes de cours
Introduction au logiciel
Etienne RIVOT, Jérôme GUITTON, Tristan ROUYER
Laboratoire d’Ecologie HalieutiqueAgrocampus Rennes
Introduction
Un logiciel de statistique
R est un logiciel qui offre un langage et un environnement pour l’analyse statistique des données et la représentation graphique.
Site Web : http://www.r-project.org/
Il permet notamment :
- de manipuler des données (stocker, manipuler des tables de données de grande dimension, extraire des données de tables, résumer les données … ) ;
- d’effectuer du calcul matriciel et autres opérations mathématiques complexes ; - de réaliser des analyses statistiques des plus simples aux plus complexes ; - de réaliser des graphiques du plus simple au plus élaboré ;
- de programmer de façon simple et efficace ;
- de se lier avec d’autres logiciels ou langages (par exemple, possibilité de lien avec C, C++ et Fortran pour compiler des tâches lourdes).
R utilise un langage (en fait un dialecte, c’est à dire un langage intégré et interprété plus facile à comprendre que les langage de base type C++ et qui ne nécessite pas de compilation avant l’exécution du programme) dérivé du langage S (AT&T Bell Laboratories). S est distribué sous le nom du logiciel Splus. Il existe des différences entre le langage R et Splus, mais la plupart des programme écris en Splus peuvent être transcrits en R moyennant quelques petits ajustements.
R est très utilisé dans la communauté des « biométriciens » en France et à l’étranger, et en particulier dans la communauté halieutique.
Un logiciel libre
R appartient à la famille des logiciels « GNU Public Licence » (http://www.gnu.org/). Un logiciel sous licence GNU est un « logiciel libre » qui permet à tout à chacun :
- de disposer du logiciel gratuitement (généralement téléchargeable gratuitement) ; - d’utiliser le programme pour tout usage, y compris commercial ;
- d’étudier le fonctionnement du programme, de l'améliorer, le modifier, publier ces améliorations (l'accès libre au code source est donc requis) ;
- de redistribuer des copies, gratuitement ou non, sous quelque forme que ce soit ;
Cela favorise le développement « collaboratif » du logiciel par une communauté importante d’utilisateurs.
Le développement et la distribution de R sont assurés par plusieurs statisticiens regroupés dans le « R Development Core Team », qui rend public ses développements dans le « Comprehensive R Archive Network (CRAN) » (http://www.cran.r-project.org) .
Un langage de script : une source de flexibilité
L’utilisation du logiciel R nécessite d’écrire un programme (un script) qui est une suite de commandes. Les commandes sont des instructions interprétées qui font intervenir des opérateurs et des fonctions. Exemple
> setwd("C:/repertoire0") (sélectionne le répertoire de travail "repertoire0") > sqrt(x) (calcule et renvoie la racine carrée du nombre x)
Ce fonctionnement à base de script peut apparaître a priori comme moins convivial et moins intéressant qu’un fonctionnement à base de « fenêtres » et de « menus » à sélectionner comme dans d’autres logiciels. Mais il offre d’énorme avantages. Il permet d’écrire un programme contenant une suite logique de traitement des données et de représentation graphique et de le stocker. Cela permet d’automatiser les tâches et de les répéter sur d’autres jeux de données.
Un système modulaire : les librairies
Les fonctions élémentaires de R sont regroupées dans la librairie base chargée au démarrage de la console.
Le fonctionnement collaboratif GNU permet à R d’être un logiciel statistique très réactif au développement de nouvelles méthodes et de nouvelles applications. Cela se matérialise sous la forme d’une bibliothèque de fonction considérable et en constant développement, disponible au téléchargement. Ces fonctions sont regroupées dans des librairies (ou packages), qui forment des modules qu’il est possible d’adjoindre au logiciel de base.
Exemple
> library(geoR) (télécharge la librairie de géostatistiques « geoR ») > library(ade4) (télécharge la librairie d’analyse multivariée « ade4 »)
> library(FLCore) (télécharge la librairie FLR pour l’évaluation des stocks halieutiques)
Installer R
Il y a plusieurs moyens de se procurer le logiciel R. 1) Télécharger à partir du site officiel
http://www.r-project.org/
Il suffit alors de suivre les instructions. Un programme d’installation « setup » se charge d’installer R sur l’ordinateur. Il est recommandé de s’aider des instructions du manuel d’installation (fichier .pdf) que l’on trouve aussi sur le site officiel.
2) Copier le répertoire R d’une machine où il est installé
Il est possible d’installer R simplement en copiant le répertoire contenant le programme du logiciel R (RGUI.exe, généralement stocké dans R/bin/RGUI.EXE) à partir d’un autre ordinateur.
Installer / Charger des librairies
Pour installer une librairie (ou package) supplémentaire 1) Le plus simple
Menu « package » / « Installer une librairie » de la fenêtre de commande Rgui
Permet de la télécharger un nouveau package à partir du site CRAN et de l’installer sur votre machine (il faut paramétrer le site miroir - choisir de préférence le site de France/Lyon).
2) Sinon
- Directement sur le site CRAN
Télécharger le module d’intérêt à l’adresse suivante :
http://cran.cict.fr/src/contrib/PACKAGES.html
Des manuels (fichier .pdf) d’utilisation de chaque package sont disponibles. - A partir d’un fichier .zip déjà sur votre ordinateur
Il faut exécuter la commande > install.packages()
(voir l’aide en ligne sur cette fonction)
Pour charger une librairie (déjà installée sur votre machine)
Pour que les fonctions d’un package soient disponibles dans le logiciel, il est nécessaire que ce package soit « chargé ». Cela ne se fait pas automatiquement au démarrage de R, même si le package est installé.
Pour charger une librairie, il faut exécuter la commande (en début de script) > library(nom_lib)
Pour accéder à la liste des librairies déjà installée sur le système, taper la commande > library()
Sites d’intérêt reliés à R
Site de R-projecthttp://www.r-project.org/
De nombreux manuels sont disponibles, ainsi que d’autres informations Un site fournissant une myriade d’exemples de code …
http://zoonek2.free.fr/UNIX/48_R/all.html
Le site de l’Univ. Lyon 1, avec cours, TD …
Environnement de travail
Assigner une variable
a <- 2A <- 3
b <- ( (2*2) -4 + 2 )/2 Attention
Il vaut mieux éviter le signe "=" - taper ?"<-" pour plus de détails sur les assignements R fait la différence entre minuscule et majuscules
Le meilleur réflexe : demander de l’aide !
Aide en ligne sur une fonction ou une commande?sqrt # Retourne l'aide sur la fonction "racine carrée"
help(sqrt) # Equivalent
?"for" # Retourne l'aide sur la commande "for"
Rechercher des informations sur un thème
help.search("linear model") # Retourne une liste de ref. évoquant "linear model"
Obtenir le code de la fonction (sauf pour les fonctions primitives)
length # Indique que "length" est une fonction primitive
Gérer son environnement de travail
Sélectionner / voir un répertoire de travail# Sélectionne un "Répertoire de travail" (Working directory) setwd("D:/A_moi/Routines/R/InitiationR")
getwd() # Voir le répertoire courant
Attention
Toutes les actions de lecture et de sauvegarde de fichier seront faite par défaut dans ce répertoire tant que aucune modification n'est spécifiée.
Notez que les chemins d'accès aux fichiers utilisent des "/" et pas des "\" comme dans Windows
Charger une librairie de R
Remarque
Il est aussi possible de charger une librairie à partir du menu principal « packages » de R. Une librairie non encore installée ne pourra pas être charger. Pour installer une librairie, exécuter « Installer un libraire » dans le menue « package » de R.
Quelques commandes utiles
ls # liste les variables de l'environnement de travail
remove(a) # supprime la variable a
rm(list = ls(a,b)) # supprime les variables a et b rm(list = ls()) # supprime toutes les variables
Types / Modes élémentaires
Le Type (ou mode) est la nature des variables concernées, qui peuvent être :
numeric (réel ou entier) v <- 2 ; is(v)
character
t <- "que du blabla ce truc" ; is(t)
logique
tr <- TRUE ; is(tr) # Vrai fs <- FALSE ; is(fs) # Faux
vm <- NA ; is(vm) # Valeur manquante
complex
c <- 2+3i ; is(c) ♦
♦♦
♦ Exercice
# Que se passe t’il ?
v <- 2 ; t <- "que du blabla ce truc" ; u <- v+t
# Cette dernière commande retourne un message d'erreur car l"opérateur "+" n'est pas défini pour le type "texte"
Objets
R manipule des OBJETS (le type de l'objet x est obtenu par la commande « is(x) »). La notion d'OBJET est fondamentale, et est finalement intuitive : à un type d'OBJET sont associés des fonctions ou des opérations qu'il est possible d'effectuer avec.
vector
Ce sont les "objets de base" de R. Les variables de dimension 1 sont considérées comme des vecteurs.
v <- 2 ; is(v) t <- "texte" ; is(t) v <- c(1,2,3) ; is(v)
matrix
m <- as.matrix(v) ; is(m) # convertit le vecteur v en matrice
data. frame
Une table de données, composée de colonnes DE MEME TAILLE. Mais les "types" des colonnes peuvent être différents : par exemple on peut mélanger des "nombres" avec des "facteurs".
list
Une liste est un objet constitué de sous objet qui peuvent être de nature différente. Une liste peut combiner des vecteurs, des matrices, des tables ... . Les sous-objets qui composent la liste sont numérotés ou bien et/ou nommés.
l <- list(a=1, v = c(1,1)) ; is(l)
factor
Les facteurs sont des objets très particuliers propres aux analyses statistiques (dans une analyse de variance par exemple). Il est important de déclarer une variable comme « facteur » pour ne pas que R la considère comme numérique mais comme une variable qualitative.
l <- c(1,2,3)
f <- as.factor(f) ; is(f) # crée le facteur f à trois niveaux 1, 2, 3
function
Fonctions (préprogrammée ou programmée par l'utilisateur). is(sqrt)
♦ ♦♦
♦ Exercice
# Que ce passe t’il ? v <- c(2,1,3)
length(v) nrow(v)
# Cette dernière commande nrow(v) ("nombre de ligne") retourne du vide car elle s'applique à un objet de type "matrice" et pas "vecteur".
Manipulations et arithmétique sur les vecteurs et matrices
Opérations arithmétiques ELEMENT par ELEMENT
Toutes les fonctions arithmétiques classiques sur des nombres réels s'appliquent sur les vecteur et les matrices ==> retournent l'opération effectuée TERME à TERME.
v <- c(1,2,3) ; w <- c(2,0,2) v-1 v+w v*w v/w v^2 sqrt(v) exp(v) log(w) ♦ ♦♦ ♦ Exercice
# Fabriquer le vecteur v = (10,100,1000) et le vecteur w formé par la racine carrée de chaque composante.
Vecteurs
Créer un vecteur# Concaténer une séquence de scalaires v <- c(3,2,1)
# Créer une séquence
v <- 1:10 # Créer une séquence de 1 à 10 (pas de 1 par défaut)
v <- 10:1 # Ordre décroissant
v <- seq(from=1, to=10, by=2) # Séq. de 1 à 10 avec un pas de 2 (ordre croissant) v <- rep(c(1,2), times=10) # Répéter 10 fois un motif (par exemple le motif (1,2))
Concaténer deux vecteurs w <- c(v,v)
Commandes et opérations arithmétiques SPECIFIQUES aux vecteurs v <- c(4,2,7)
length(v) # Dimension (longueur) min(v) ; max(v) ; range(v) # Min et max
sum(v) ; cumsum(v) # Somme, somme cumulée
prod(v) ; cumprod(v) # Produit et produit cumulé mean(v) ; var(v) ; sd(v) # Moyenne, variance, écart type median(v) ; quantile(v) # Médianes et Quantiles
v.2 <- sort(v) # Ordonner un vecteur par ordre croissant
which(v==4) # Indices (position) d'un élément
which(v>2) ♦
♦♦
♦ Exercice
# Créer le vecteur v = (1,5,9,4,2,8,7) et trouver la position (l’indice) du maximum de v
Matrices
Créer une matrice
Une matrice est un tableau à n lignes et p colonnes. Une matrice peut contenir des nombres ou du texte, mais tous les éléments doivent être du même type (on ne peut pas mélanger du texte et des nombre dans une matrice).
Une matrice se crée avec la commande "matrix" et les arguments "nrow" (nb de lignes) et "ncol" (nb de colonnes).
x <- 1 # Matrice remplie automatiquement avec x
m <- matrix(x, nrow = 2, ncol = 3)
m <- matrix(c(1,2,3), nrow=1,ncol=3) # Créer une matrice 1 ligne et 3 colonnes m <- matrix(c(1,2,3), 1, 3) # Syntaxe + condensée
m <- matrix(c(1,2,3), nrow=3,ncol=1) # Créer une matrice 3 lignes et 1 colonne
# Lire un vecteur et en remplir les LIGNES au fur et à mesure (utiliser byrow = FALSE pour remplir par colonne
m <- matrix(c(1,2,3,4,5,6), nrow = 2, ncol = 3, byrow = TRUE) ♦
♦♦
♦ Exercice
Créer la matrice suivante à partir du vecteur (1,2,3,4,5,6)
[,1] [,2]
[1,] 1 2
[2,] 3 4
[3,] 5 6
Dimensions d’une matrice
m <- matrix(c(1,2,3,4,5,6), nrow = 2, ncol = 3, byrow = TRUE) dim(m)
nrow(m) ncol(m)
Manipulation / Extraction des éléments
m <- matrix(c(6,5,4,3,2,1), nrow = 2, ncol = 3, byrow = TRUE)
m[2,3] # Element (i,j) : m[i,j]
m[1,] # Ligne i : m[i,]
m[,2] # colonne j : m[,j]
m[1:2,2:3] # Sous-matrice : m[i:j,i':j'] m[-1,] # Enlever la ligne i : m[-i,] m[,-1] # Enlever la colonne j : m[,-j]
diag(m) # Diagonale de m (attention, adapté à une matrice carrée) n <- m*(m>2) # Eléments de la matrice m > 2, 0 sinon
Position des éléments d'une matrice
Les positions sont indiquées par un numéro (vers le bas en partant du coin gauche)
which.max(m) # trouve le maximum
which.min(m) # le minimum
which(m<4) # tous les éléments < 4
Transposer m1 <- t(m) ♦ ♦♦ ♦ Exercice Créer la matrice [,1] [,2] [,3] [,4] [1,] 0 0 0 0 [2,] 0 0 0 0 [3,] 9 10 11 12 [4,] 13 14 15 16 à partir de la matrice [,1] [,2] [,3] [,4] [1,] 1 2 3 4 [2,] 5 6 7 8 [3,] 9 10 11 12 [4,] 13 14 15 16
Concaténer deux matrices (de même dimension)
m1 <- matrix(c(1,2,3,4), nrow = 2, ncol = 2, byrow = TRUE) m2 <- matrix(c(5,6,7,8), nrow = 2, ncol = 2, byrow = TRUE)
# Par colonne (l'une à côté de l'autre) cbind(m1,m2)
# Par ligne (l'une sous l'autre) rbind(m1,m2) ♦ Exercice Fabriquer la matrice [,1 ] [,2] [,3 ] [,4 ] [,5 ] [,6] [,7] [,8] [1 ,] 1 2 1 2 1 2 1 2 [2 ,] 1 2 1 2 1 2 1 2 [3 ,] 1 2 1 2 1 2 1 2 à partir de la matrice [,1 ] [,2 ] [1 ,] 1 2 [2 ,] 1 2 [3 ,] 1 2
Arithmétique sur les matrices
Toutes les opérations vectorielles (somme, moyenne …) peuvent s’appliquer sur les lignes ou les colonnes d’une matrice, grâce à la fonction apply()
Par ligne : apply(m,1,operation) Par colonne : apply(m,2,operation)
m1 <- matrix(c(1,2,3,4), nrow = 2, ncol = 2, byrow = TRUE) apply(m1,1,mean) # Moyenne des lignes de m1 apply(m1,2,mean) # Moyenne des colonnes de m1
apply(m1,1,sum) # Somme sur les lignes de m1
Algèbre matricielle Produit matriciel
Attention aux dimensions ( r = m1.m2, dim(m1)=(n,p), dim(m2)=(p,q), dim(r) = n.q ) m1 <- matrix(c(1,2,3,1,2,3), nrow = 2, ncol = 3, byrow = TRUE)
m2 <- matrix(c(1,2,3,1,2,3), nrow = 3, ncol = 2, byrow = TRUE) # Produit matriciel de m1*m2
r <- m1%*%m2
Inverser (matrice carrée inversible)
m1 <- matrix(c(1,2,2,1), nrow = 2, ncol = 2, byrow = TRUE)
m2 <- solve(m1) # Inversion
Listes
Une liste est un objet constitué de sous objets qui peuvent être de nature différente. On crée des listes avec la fonction "list".
Exemple v1 <- c(1,2,3) v2 <- c(4,3,2) vt <- c("a","b","c","d")
m <- matrix(c(1,2,3,4,5,6), nrow = 2, ncol = 3, byrow = TRUE)
l1 <- list(v1,v2) # Crée la liste avec les objets v1 et v2 l2 <- list(vt,m) # Crée la liste avec les objets vt et m
# Nommer les éléments d'une liste (Rq : La commande l1 <- list(v1,v2) seule crée une liste dans laquelle les éléments v1 et v2 ne sont pas nommés)
names(l1) # Les éléments ne sont pas nommés
names(l1) <- c("v1","v2")
names(l1) # Les éléments sont nommés
# Appeler un élément dans une liste l1$v1
# Créer des variables portant le nom des composantes de la liste attach(l1)
# Résumer une liste summary(l1) Remarques
De très nombreuses fonctions (et notamment les fonctions statistiques) renvoient les résultats dans des listes. Il est alors possible d’extraire les éléments de la liste en les appelant par leur nom.
La commande « $ », utilisée pour appeler un élément nommer dans une liste par nom.de.la.liste$nom.de.l’élément est fondamentale. Elle est aussi valable pour appeler une variable (colonne) dans une table de données (data.frame).
Exemple de liste issue du résultat de la fonction « lm() » (linear model) Exemple
x <- c(1,2,3,4,5,6) ; y <- c(1.1, 1.9, 3.4, 3.9, 5.4,6.2) ; reg1 <- lm(y~x)
names(reg1) # reg1 est une liste qui contient des résultats clé de la régression linéaire summary(reg1) # summary(reg1) est aussi une liste qui contient d’autres résultats
Table de données : data.frame
Les « data frame » (Tables de données) sont des tables hétérogènes composés d'une collection de colonnes homogènes, c'est à dire de même taille (mais de type éventuellement différent - par exemple on peut mélanger des "nombres" avec des "facteurs" dans une table.
C’est un objet fondamental dans la pratique : une « data frame » est une table de données à analyser, généralement composée de colonnes qui contiennent les variables décrivant les individus en ligne.
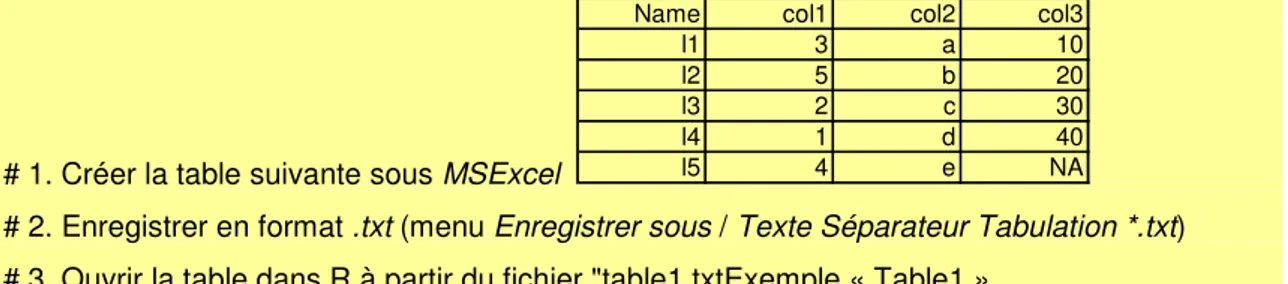
Créer une table à partir de variables connues de R
ExempleName <- c("l1","l2","l3","l4","l5") col1 <- c(3,5,2,1,4)
col2 <- c("a","b","c","d","e") col3 <- c(10,20,30,40, NA) # 1ere méthode : Création directe t <- data.frame(Name,col1,col2,col3)
# 2eme méthode : Concaténation par colonne t <- cbind.data.frame(Name,col1,col2,col3) is(t)
Attention
L’utilisation de la fonction cbind() au lieu de cbind.data.frame() entraîne la formation d’une matrice au lieu d’une table de données, et conduira à des problèmes.
Lire une table à partir d’un fichier déjà stocké
Fonctions read.table() ou read.csv()Lecture d’un fichier en format .txt (ascii, séparateurs "tabulations")
Pour créer un fichier en format .txt avec séparateurs "tabulations" le plus simple est de créer le fichier sous MSExcel et de l’enregistrer en format .csv (sous MSExcel, menu Enregistrer sous / Texte Séparateur Tabulation *.txt).
Exemple « Table1 »
# 1. Créer la table suivante sous MSExcel
Name col1 col2 col3
l1 3 a 10
l2 5 b 20
l3 2 c 30
l4 1 d 40
l5 4 e NA
# 2. Enregistrer en format .txt (menu Enregistrer sous / Texte Séparateur Tabulation *.txt) # 3. Ouvrir la table dans R à partir du fichier "table1.txtExemple « Table1 »
t <- read.table(file = "table1.txt", header = TRUE, sep = "")
# header = TRUE : lit la première ligne comme une ligne de titre (nom des colonnes) # = FALSE : lit la première ligne comme de la donnée
# sep = la façon dont les données sont séparées dans le fichier source # Nombreuses autres options
Attention
Attention au répertoire de travail sélectionné. Pour être sûr de lire dans le bon répertoire de travail, on peut utiliser la fonction setwd() avant la fonction read.table() ou bien spécifier le chemin d’accès complet du fichier à lire directement dans la fonction read.table() (read.table(file = " U:/A_moi/Routines/R/InitiationR/table1.txt", …)).
Option « header = ». Si le fichier ne contient pas de ligne de titre, utiliser « header = TRUE » conduit à considérer la première ligne de données comme des titres = des noms pour les variables. Si le fichier contient une ligne de titre (nom des variables), l’instruction « header = FALSE » conduit à considérer la première ligne de titre comme des données.
Lecture d’un fichier en format .csv (séparateur "points virgules")
Pour créer un fichier en format .csv avec séparateur = "points virgules", le plus simple est de créer le fichier sous MSExcel et de l’enregistrer en format .csv (sous MSExcel, menu Enregistrer sous / CSV Séparateurs points-virgules *.csv).
Exemple « table 1 »
# 1. Créer la table suivante sous MSExcel
Name col1 col2 col3
l1 3 a 10
l2 5 b 20
l3 2 c 30
l4 1 d 40
l5 4 e NA
# 2. Enregistrer en format .csv (menu Enregistrer sous / CSV Séparateurs "points-virgules" *.csv)
# 3. Ouvrir la table dans R à partir du fichier "table1.txt"
t <- read.table(file = "table1.csv", header = TRUE, sep = ";") Remarque
La fonction read.csv() permet de lire directement des fichiers avec séparateurs "virgules".
Nommer les colonnes d’une table / les lignes d’une table
Directement à la lecture à la lecture dans un fichier (.txt ou .csv)Exemple
# A partir de la table suivante enregistrée en .txt sous le nom table1_0.txt
l1 3 a 10 l2 5 b 20 l3 2 c 30 l4 1 d 40 l5 4 e NA
t <- read.table(file = "table1_0.txt", header = FALSE, sep = "", col.names = c("Name","col1", "col2", "col3"), row.names = c("A","B", "C", "D",”E”) )
Ou bien pour une table déjà formée sans nom de colonne t <- read.table(file = "table1_0.txt", header = FALSE, sep = "") names(t) = c("Name","col1", "col2", "col3")
Sauvegarde d’une table dans un fichier .txt
Fonction write.table()Exemple
# Attention au répertoire de travail en cours write.table(x=t, file = "table1_save.txt",
append = FALSE,
row.names = FALSE, col.names = TRUE, quote = FALSE)
# append = FALSE : détruit tout le contenu du fichier table2 (si existant) avant de sauvegarder (TRES CONSEILLE)
# append = TRUE : combine le fichier avec le contenu du fichier table2 existant (TRES DANGEREUX)
# Nombreuses options
Remarque : Le chemin d’accès complet du fichier dans le quel on veut stocker la table peut être spécifié directement : (write.table(x=t,file=" U:/A_moi/Routines/R/InitiationR/table1.txt", …)).
Contenu et composantes d'une table
summary(t) # Résumé d'une Table (par colonne)
names(t) # Nom des colonnes
dimnames(t) # Noms des lignes : première composante de la liste
# Noms des colonnes : deuxième composante de la liste
t$col1 # Colonne de t dont le nom est col1
t[,"col1"]
# Création d'objets (vecteurs) portant le nom des colonnes de t
attach(t) # Retourne les objets (colonnes) "Name", "col1", "col2", "col3" col1 # Après "attach(t)", l'objet "col1" existe
Remarque : La fonction attach() est pratique car même si la table est chargée, les variables portant le nom des colonnes sont inconnues pour R. Mais à utiliser prudemment. Peut notamment conduire à des confusions de variables, notamment des variables portant le même nom.
Extraire / Filtrer des données à partir d’une Table
# Sélection de colonnes# Créer une table t2 contenant les colonnes 1 et 2 de t. Les colonnes sont appelées par leur nom dans l’instruction select = c(). Elle doivent donc être nommées au préalable.
t2 <- subset(t, select = c(col1,col2))
# Sélection sur les lignes
# Créer une table t2 contenant les lignes pour qui col3 >=3
t2 <- subset(t, subset = c(col1>=3)) # Lignes pour qui col1>=3 # Cumuler deux conditions avec les fonctions logiques (exemple « ET ») t2 <- subset(t, subset = ((col1>=3) & (col2=="b")))
# Exemple « OU »
t2 <- subset(t, subset = ((col1>=3) | (col2=="b")))
Concaténer deux Tables pour en créer une autre (par colonne ou par lignes)
# Superposer des lignes (si même nombre de colonnes)rbind.data.frame(t,t2)
rbind(t,t2) # Idem rbind.data.frame()
# Juxtaposer des colonnes (si même nombre de lignes) cbind.data.frame(t,t$col1)
cbind(t,t$col1) # Idem cbind.data.frame()
Appliquer une fonction aux composantes ou aux lignes d'une Table
Fonction apply() ou lapply()apply(t,1,sum) # Message d’erreur car t a des colonnes non numériques Fonction tapply()
La fonction tapply() permet de faire des opérations simples (moyennes, variance ..) sur une variable d’une table, en croisant différents facteurs. Voir un exemple ci-dessous.
♦
♦
♦
♦
Exercice
Sur la table « saumons » - Exemple de manipulation # 1. Ouvrir le fichier excel "saumons.xls"
# 2. Enregistrer .xls --> .txt
# 3. Ouvrir la table dans R à partir du fichier "saumons.txt" et visualiser la table, afficher le nom des variables colonnes
# 4. Construire une nouvelle table « saumons_r » à partir de « saumons » en ne conservant que les observations pour lesquelles la variable "reliability" = 1.
# 5. A partir de saumons_r, créer une nouvelle colonne appelée log.dens composée de log(density), et rattacher cette nouvelle colonne à la table saumons_r
# 6. Calculer la moyenne du log de la density par année et par age (tous habitats confondus)
Solution
# 1. Ouvrir le fichier excel "saumons.xls" # 2. Enregistrer .xls --> .txt
# 3. Ouvrir la table dans R à partir du fichier "saumons.txt" et visualiser la table, afficher le nom des variables colonnes
setwd("D:/A_moi/Routines/R/InitiationR")
saumons <- read.table(file = "saumons.txt", header = TRUE, sep = "") saumons[1 :10,]
names(saumons) summary(saumons)
# 4. Construire une nouvelle table « saumons_r » à partir de « saumons » en ne conservant que les observations pour lesquelles la variable "reliability" = 1.
saumons_r <- subset(saumons, subset=(reliability==1)) saumons_r[1 :10,]
summary(saumons_r)
# 5. A partir de saumons_r, créer une nouvelle colonne appelée log.dens composée de log(density), et rattacher cette nouvelle colonne à la table saumons_r
log.dens <- log(saumons_r$density)
saumons_r <- cbind.data.frame(saumons_r, log.dens) names(saumons_r)
saumons_r[1 :10,]
# 6. Calculer la moyenne du log de la density par année et par age (tous habitats confondus) tapply(saumons_r$log.dens,
Graphiques
Généralités
R permet de réaliser des graphiques très variés et de très grande qualité. Les graphiques sont réalisés à partir de commandes (= des fonctions déjà implémentées), qui disposent de très nombreuses options.
Les graphiques réalisés peuvent être imprimés, ou exportés sous différents formats (.eps, .jpeg, .tiff …)
D’une manière générale, les commandes graphiques prennent en argument les données et un ensemble d’options qui permettent de contrôler la mise en forme du graphique. Certaines fonctions graphiques particulières prennent comme argument des objets d'un type particulier produit par une autre fonction.
Exemple > plot(x,y)
Pour accéder aux paramètres (données et options) acceptés dans une fonction graphique, on peut utiliser l’aide.
Exemple > ?plot > help(plot)
Ouvrir un dispositif graphique
Une commande graphique produit l'ouverture d'une fenêtre contenant le graphique demandé. C'est ce qu'on appelle un dispositif graphique. Ce dispositif devient automatiquement le dispositif courant (ou actif), et tout appel de commande graphique entraînera l'affichage d'un graphique sur celui-ci.
Exemple
x <- c(1,2,3,4,5) ; y1 <- c(0.9, 2.2, 2.9, 4.3, 5.4) ; y2 <- 10*y1 plot(x,y1)
plot(x,y2)
Pour pouvoir réaliser et visualiser deux graphiques différents, on peut ouvrir une nouvelle fenêtre graphique avant chaque commande graphique.
Exemple
x <- c(1,2,3,4,5) ; y1 <- c(0.9, 2.2, 2.9, 4.3, 5.4) ; y2 <- 10*y1 windows() # Ouvre un premier dispositif graphique plot(x,y1)
windows() # Ouvre un second dispositif graphique qui devient le dispositif actif plot(x,y2)
Remarque
Nuage de points (x,y) et dérivés
Nuage de points Fonction plot() x <- c(1,2,3,4,5) ; y <- c(0.9, 2.2, 2.9, 4.3, 5.4) windows() plot(x,y) Principales options plot(x,y,type = "p", # tracé des points seulement
pch = 21, # forme du point
col = "red", # couleur des points
bg = "blue", # couleur du fond des points
xlab = "axe des x", # nom axe des X
ylab = "axe des y", # nom axe des Y
main = "mon premier graphique", # titre
xlim = c(0,6), # limites axes des X
ylim = c(0,7)) # limites axes des y
Superposer deux nuages de points
Fonction points() (après avoir appelé la fonction plot)
x <- c(1,2,3,4,5) ; y1 <- c(0.9, 2.2, 2.9, 4.3, 5.4) ; y2 <- 2*y1 windows()
plot(x, y1, pch = 21, col = "red", bg = "red", ylim=c(0,12)) points(x, y2, pch = 22, col = "blue", bg = "blue")
Relier les points par des lignes
x <- c(1,2,3,4,5) ; y1 <- c(0.9, 2.2, 2.9, 4.3, 5.4) ; y2 <- 2*y1 windows()
plot(x, y1,
type = "l", # relier les points par une ligne
lty = 1, # ligne pleine
col = "red", # de couleur rouge
lwd = 1, # d’épaisseur 1
ylim=c(0,12))
points(x, y2,
type = "b", # relier les points par une ligne + tracer les points
lwd = 3) # d’épaisseur 3
Utile
Types de points pch
Type de lignes lty
Spécifiée comme un entier (0=blanc, 1=normal, 2=tirets, 3=pointillés, 4=alterné, 5=tirets longs, 6=tirets longs-tirets courts) ou comme une chaine ("blank", "solid", "dashed", "dotted", "dotdash", "longdash", "twodash".
♦ ♦♦
♦ Exercice
A partir de la table « saumons », tracer les graphiques suivants
5 10 15 20 25 30 35 5 0 1 0 0 1 5 0 2 0 0 Relation density-Lf density L f 5 10 15 0 5 1 0 1 5
densité moyenne en fonction de l'âge
année d e n si té m o ye n n e Solution setwd("D:/A_moi/Routines/R/InitiationR")
saumons <- read.table(file = "saumons.txt", header = TRUE, sep = "") saumons0 <- subset(saumons, subset = (age ==0))
saumons1 <- subset(saumons, subset = (age ==1))
# Premier graphique windows()
plot(saumons0$density,saumons0$Lf, pch = 16, col = "red",
xlab = "density", ylab=”Lf”,main="Relation density-Lf", ylim=c(50,200)) points(saumons1$density,saumons1$Lf, pch = 15, col = "blue") # Deuxième graphique windows() mean.dens <- tapply(saumons$dens,
INDEX = list(saumons$year, saumons$age), FUN = mean) mean.dens
plot(1:16, mean.dens[,1],ylim = c(0,15),
pch = 16, type = "b", lty = 1, col = "red", lwd = 2, xlab = "année", ylab = "densité moyenne",
main = "densité moyenne en fonction de l’âge") points(1:16, mean.dens[,2],
pch = 15, type = "b", lty = 2, col = "blue", lwd = 2)
Histogrammes
Fonction hist()Exemple
# Génère un échantillon de taille n=1000 tiré dans une loi N(m=0,sd=5) ech.norm <- rnorm(n=1000, mean = 0, sd=5)
# Tracer l’histogramme de cet échantillon hist(x=ech.norm,
plot = TRUE, # si FALSE, renvoie la hauteur des barres sans graphique breaks = 20, # nombre d’intervalles ou vecteur des centres des intervalles freq = FALSE, # fréquence (TRUE) ou probabilité (FALSE)
border = "red", # couleur des contours des barres col = "blue", # couleur de l’intérieur des barres xlim = c(-25,25)) # limite de tracé de l’axe des x
# Ajoute une courbe lissée sur l’histogramme lines(density(ech.norm, bw=3), col="green", lwd=3) ♦
♦♦
♦ Exercice
A partir de la table « saumons », tracer l’histogramme de la taille des juvéniles de saumons. Conclusions ?. Tracer le graphique ci-dessous.
Histogram of saumons0$Lf saumons0$Lf D e n s it y 50 100 150 200 0 .0 0 0 .0 2 0 .0 4 0 .0 6 0 .0 8 Solution setwd("D:/A_moi/Routines/R/InitiationR")
saumons <- read.table(file = "saumons.txt", header = TRUE, sep = "") saumons0 <- subset(saumons, subset = (age ==0))
saumons1 <- subset(saumons, subset = (age ==1))
windows()
hist(saumons$Lf, freq = FALSE, xlim = c(50,200), breaks = 20, border = "black")
windows()
hist(saumons0$Lf,
freq = FALSE, xlim = c(50,200), breaks = 20, border = "red",
xlab = "Lf (mm)", main = "Histogramme des tailles en function de l’âge") lines(density(saumons0$Lf, bw=4), col="red", lwd=2)
hist(saumons1$Lf, add= TRUE,
breaks=20, freq = FALSE, border = "blue") lines(density(saumons1$Lf, bw=4), col="blue", lwd=2)
Box-plot
Fonction boxplot()Exemple
# Génère un échantillon de taille n=100 tiré dans une loi N(m=0,sd=5), et un autre de même taille tiré dans une loi N(m=5,sd=10)
ech1 <- rnorm(n=100, mean = 0, sd=5) ech2 <- rnorm(n=100, mean = 5, sd=10) ech <- cbind.data.frame(ech = c(ech1,ech2),
loi = c(rep(1,times=100),rep(2,times=100)))
# Tracer l’histogramme de l’échantillon ech.norm1 boxplot(x=ech1,
range = 1.5, # largeur des boites en range * écart inter-quartile horizontal = FALSE, # Box plot horizontal (TRUE) ou vertical (FALSE) border = "red", col = "pink", # couleur des contours des barres et de l’intérieur notch = TRUE, # génère un biseau pour indiquer l’IC de la médiane ylab ="valeur de ech1")
# Tracer l’histogramme de l’échantillon ech.norm en fonction de la loi boxplot(formula = ech$ech~ech$loi,
horizontal = FALSE, border = "red", col = "pink") ♦
♦♦
♦ Exercice
A partir de la table « saumons », tracer les box-plot des densités moyennes de juvéniles de saumons d’âge 0+ 1) en fonction de l’année ; 2) en fonction de l’habitat.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 5 1 0 1 5 2 0 2 5 3 0 3 5 année
flats rapids runs
5 1 0 1 5 2 0 2 5 3 0 3 5 habitat Solution setwd("D:/A_moi/Routines/R/InitiationR")
saumons <- read.table(file = "saumons.txt", header = TRUE, sep = "") saumons0 <- subset(saumons, subset = (age ==0))
# En fonction de l’année windows()
boxplot(formula = saumons0$density ~ saumons0$year, horizontal = FALSE, border = "red", col = "pink", xlab ="année" )
windows()
boxplot(formula = saumons0$density ~ saumons0$hab, horizontal = FALSE, border = "red", col = "pink", xlab = "habitat")
Gérer la mise en forme des fenêtres graphiques
Commande générique par()La commande par() permet de mettre en forme de façon permanente (où jusqu'à ce qu'on en change) un dispositif graphique. Elle s’associe avec de très nombreuses commandes qui permettent notamment de gérer la police, la taille du texte, de faire apparaître plusieurs graphiques dans la même fenêtre.
Diviser une fenêtre graphique de façon régulière Commande par(mfrow = c()) ou par(mfcol = c())
Ces commandes permettent de diviser la fenêtre graphique en cases régulières, disposée en un nombre de ligne x un nombre de colonnes que l’on spécifie.
Avec la commande par(mfrow = c()), les graphiques sont réalisées en remplissant d’abord la première ligne de cases dans la fenêtre graphique, puis la deuxième … . La commande par(mfrow = c()) permet de rempli d’abord les colonnes.
Exemple
setwd("D:/A_moi/Routines/R/InitiationR")
saumons <- read.table(file = "saumons.txt", header = TRUE, sep = "") saumons0 <- subset(saumons, subset = (age ==0))
windows()
par(mfrow = c(2,2)) # divise en deux lignes et deux colonnes boxplot(formula = saumons0$density ~ saumons0$year,
horizontal = FALSE, border = "red", col = "pink", xlab ="année" ) plot(1,1)
plot(1,1)
boxplot(formula = saumons0$density ~ saumons0$hab,
horizontal = FALSE, border = "red", col = "pink", xlab = "habitat")
Diviser une fenêtre graphique de façon irrégulière Commande layout()
Cette commande est plus plastique que la précédente et permet des arrangements graphiques non réguliers. Elle permet de diviser le dispositif graphique en plusieurs régions de taille différentes dans lesquelles seront tracés successivement, ou non, les graphiques.
La commande layout() prend comme argument une matrice nxp qui sert à définir la position et la taille des zones de graphiques dans une grille à n lignes x p colonnes.
Par exemple
définit une matrice “m” de taille 3*3, mais contenant 3 zones de graphiques. La zone 1 est constituée par toutes les cases de la matrice qui contiennent le chiffre 1. Idem pour les zones 2 et 3. Une zone contenant le chiffre 0 ne pourra pas contenir de graphique.
La commande layout.show() affiche les limites des figures tracées. Exemple
m <- matrix(c(1,1,2,1,1,2,3,3,3),3,3,byrow = TRUE) windows() ; layout(m) ; layout.show(n=3)
Les graphiques seront affichés dans l’ordre dans le quel sont définies les zones Exemple
setwd("D:/A_moi/Routines/R/InitiationR")
saumons <- read.table(file = "saumons.txt", header = TRUE, sep = "") saumons0 <- subset(saumons, subset = (age ==0))
windows()
m <- matrix(c(1,1,2,1,1,2,3,3,3),3,3,byrow = TRUE) layout(m)
boxplot(formula = saumons0$density ~ saumons0$year,
horizontal = FALSE, border = "red", col = "pink", xlab ="année" ) plot(1,1)
boxplot(formula = saumons0$density ~ saumons0$hab,
horizontal = FALSE, border = "red", col = "pink", xlab = "habitat")
Ajouter du texte dans un graphique
Ajouter un titre Commande title() Exemple x <- c(1,2,3,4,5) ; y1 <- c(0.9, 2.2, 2.9, 4.3, 5.4) windows() plot(x, y1)title(main = "y en fonction de x",
line = 0) # line = Indique le numéro de ligne où placer le titre
# Si négatif, le titre sera dans le cadre de la figure
title(main = "deux lignes plus plus bas", line = -2) # Nombreuses autres options
Ajouter du texte n’importe où Commande text()
Exemple
x <- c(1,2,3,4,5) ; y1 <- c(0.9, 2.2, 2.9, 4.3, 5.4) ; windows() ; plot(x, y1)
title(main = "y en fonction de x", line = 1)
xt <- c(2,3,4) ; # abscisses et ordonnées où seront positionnés yt <- c(5,4,3) ; # les chaînes de texte de « labels »
text(labels=c("rajouter","du","texte"), # le texte à rajouter x = xt, y = yt,
col="red", # couleur
cex = 2) # taille (par rapport à 1)
# Nombreuses autres options Remarque
Voir aussi la commande mtext() qui permet d’ajouter du texte dans la marge des figures
Ajouter une légende
Commande legend()x <- c(1,2,3,4,5) ; y1 <- c(0.9, 2.2, 2.9, 4.3, 5.4) ; y2 <- 2*y1 windows()
plot(x, y1, pch = 21, col = "red", bg = "red", ylim=c(0,12)) points(x, y2, pch = 22, col = "blue", bg = "blue")
text.legend <- c("ech1","ech2") # la légende à écrire legend(text.legend ,
x="topleft", # position dans le graphique
pch=c(21,22), # forme des points
col = c("red","blue"), pt.bg=c("red","blue"), # couleurs des points et du fond
title="Légende") # titre de la légende
# Nombreuses autres options
Contrôler les axes (ajouter, personnaliser …)
Commande axis()Fonctions statistiques linéaires simples
Régression linéaire
La régression linéaire est introduite à partir d’un exemple simple : les résultats du championnat de France de football de l’année 2005 (table « Foot2005 »)
Charger les données rm(list=ls(all=TRUE))
setwd("D:/A_moi/Routines/R/InitiationR")
foot2005 <- read.table(file = "foot2005.txt", header = TRUE, sep = "") foot2005
Tracer « classement » = f(« nb. Victoires ») windows()
plot(foot2005$vict, foot2005$clas,
pch=21, col = "red", xlab = "Nb de victoires", ylab = "Classements", main = "Championnat de Foot 2005")
Régression linéaire Classement = f(nb. victoires) reg1 <- lm(formula = foot2005$clas ~ foot2005$vict)
names(reg1) # Tout ce qui est contenu dans l’objet reg1
summary(reg1) # Résumé de la régression linéaire
names(summary(reg1)) # Ce que l’on trouve dans “summary()”
coef(reg1) # Coefficients de la régression
resid(reg1) # Résidus de la régression
fitted(reg1) # Valeurs des classements prédits
# (alignés sur la droite de régression)
summary(reg1)$r.squared # Coefficient R² de la régression
Intervalles de confiance autour de l’estimation des paramètres confint(reg1, level = 0.95) # Niveau 95% confint(reg1, level = 0.50) # Niveau 50%
Test « t » de nullité des coefficients "intercept" et "coef dir"
summary(reg1)
INTERPRETATION
C’est un test de Student de nullité de chaque coefficients du modèle.
Test de H0 ("le coefficient est nul") contre H1 ("le coefficient n’est pas nul"). On rejette k’hypothèse H0 si p-value = Pr(Student > |t value|) < seuil. Généralement, on prend la valeur 0.05 (5%) pour le seuil.
Test « F » de la "significativité de l'effet de "x" sur la réponse "y"
anova(reg1)
INTERPRETATION
C’est un test de Fisher de « modèle emboîté ». A partir du modèle le plus simple (sans effet du nombre de victoires sur le classement), on rajoute l’effet « nombre de victoires » et on teste si la quantité de variance expliquée par cette variable est significative.
Test de H0 ("la variable explicative x n'a pas d'effet sur la réponse y") contre H1 ("x a un effet linéaire sur y"). On rejette H0 si p-value = Pr(Fisher > F value) < seuil. Généralement, on prend la valeur 0.05 (5%) pour le seuil.
Remarque
Dans le cas d’une régression linéaire simple, le test « t » de nullité du coefficient de la variable X dans la régression est équivalent au test « F » de significativité de l’effet de la variable X dans la régression. Mais cette équivalence n’est pas une règle générale. Notamment, elle n’est pas vraie dans le cas d’une analyse de variance.
Graphiques usuels de la régression linéaire
Tracé de la droite de régression sur le nuage de points dans une fenêtre 2x2 windows() ; par(mfrow = c(2,2))
plot(foot2005$vict, foot2005$clas, pch = 21, col = "red",
xlab = "Nb. de victoires", ylab = "Classement", main = "Classement vs Nb de victoires")
abline(reg1, lty=1, lwd=2) # rajoute la droite de régression du modèle reg1
Ajout de l'équation de la régression et du R² sur le graphique # Equation de la régression
text(x=11,y=18, pos=4, as.expression(substitute(y==a*x+b, list(a=round(coef(reg1)[2],2), b=round(coef(reg1)[1],2)))))
# Equation du R²
text( x=11,y=15, pos=4, as.expression( substitute( R²==r, list(r=round(summary(reg1)$r.squared,2)) ) ) )
Analyse graphique des résidus Histogramme (distribution des résidus)
hist(resid(reg1), xlim = c(-10,10), breaks=10, main = "Hist. des residus - reg1") Résidus en fonction du classement prédit (homogénéité des résidus)
plot(fitted(reg1),resid(reg1),
col = "black", xlab = "Fitted class", ylab = "Residuals", main = "Residus vs valeurs ajustées")
QQplot des résidus (test graphique de la normalité des résidus)
qqnorm(resid(reg1), main = "QQplot des résidus (test de normalité)") qqline(resid(reg1))
♦ ♦♦
♦ Exercice
Exemple « saumons » - Régression linéaire de la taille en fonction de la densité A partir de la table de données « saumons »
1. Tracer taille (Lf) = f(densité)
2. Faire la régression linéaire de la taille en fonction de la densité Donner les coefficients estimés de la régression Donner le R² de la régression
3. Tracer la droite de régression sur le graphique 4. Tester la nullité des coefficients de la régression
5. Tester la significativité de l’effet de la densité sur la taille
6. Tester (graphiquement) l’homogénéité et la normalité des résidus 7. Conclusion ? Comment améliorer le modèle ?
Solution rm(list = ls())
setwd("D:/A_moi/Routines/R/InitiationR")
saumons <- read.table(file = "saumons.txt", header = TRUE, sep = "")
windows() ; par(mfrow = c(2,2)) plot(saumons$density, saumons$Lf)
coef(reg1)
summary(reg1)$r.squared summary(reg1)
anova(reg1)
# Analyse des résidus
hist(resid(reg1)) # L’histogramme des résidus est bimodal ! plot(fitted(reg1),resid(reg1))
qqnorm(resid(reg1), main = "QQplot des résidus (test de normalité)")
qqline(resid(reg1)) # La normalité des résidus n’est pas du tout
# respectée
# Conclusion : un modèle inadapté
# 2 stratégies alternatives peuvent être proposées : 1) scinder le jeu de données en deux partie, les saumons d’âge 0 et les saumons d’âge 1, et réaliser deux régressions linéaires simples indépendantes sur les deux jeux de données ; 2) réaliser une régression multiple en introduisant l’âge comme seconde variable explicative. C’est cette deuxième stratégie qui est proposée dans la suite.
# Essai 2 : Régression multiple avec l’âge
windows() ; par(mfrow = c(2,2)) plot(saumons$density, saumons$Lf)
reg2 <- lm(saumons$Lf ~ saumons$density + saumons$age) coef(reg2)
summary(reg2)$r.squared anova(reg2)
summary(reg2)
# Analyse des résidus hist(resid(reg2))
plot(fitted(reg2), resid(reg2))
qqnorm(resid(reg2), main = "QQplot des résidus (test de normalité)") qqline(resid(reg2))
# Graphique de la double régression windows()
plot(saumons$density, saumons$Lf, main = “Ajustement regression multiple“) Lf.fitted <- fitted(reg2)
saumons <- cbind.data.frame(saumons,Lf.fitted) saumons0 <- subset(saumons, subset = (age==0)) saumons1 <- subset(saumons, subset = (age==1))
points(saumons0$density,saumons0$Lf.fitted, type = “l”, col = “red”, lwd = 2) points(saumons1$density,saumons1$Lf.fitted, type = “l”, col = “blue”, lwd = 2)
Analyse de variance
L’analyse de variance est introduite à partir d’un exemple simple : l’étude de la variabilité de la densité d’anguilles en fonction des facteurs « années » et « secteurs » (table « anguilles »).
Charger les données rm(list = ls())
setwd("D:/A_moi/Routines/R/InitiationR")
anguilles <- read.table(file = "anguilles.txt", header = TRUE, sep = "")
Explorer les données
Déclarer les variables comme facteurs (c'est essentiel sinon R peut les considérer comme des variables quantitatives si elles sont codées par des chiffres dans le tableau de données, comme c’est le cas des années (year)).
anguilles$sect <- as.factor(anguilles$sect) anguilles$year <- as.factor(anguilles$year)
Bilan du nombre d’observations par facteur ou croisement de facteurs.
levels(anguilles$sect) # fait le bilan des niveaux du facteur « habitat » levels(anguilles$year)
table(anguilles$sect) # bilan du nb. d’observation dans chaque niveau table(anguilles$year)
table(anguilles$year, anguilles$sect) # nombre d’obs. par croisement de facteurs Appliquer une opération à une table par facteur
# Exemple : moyenne de la densité par croisement des facteurs “year” et “sect” tapply(anguilles$dens, INDEX = list(anguilles$year, anguilles$sect), FUN = mean) tapply(anguilles$dens, INDEX = list(anguilles$year), FUN = mean)
Graphiques exploratoires - densité par facteur
Box-plot (résumé visuel de la variabilité des données) de la densité en fonction des facteurs années et secteurs
windows() ; par(mfrow = c(1,2))
boxplot(anguilles$dens ~ anguilles$sect, horizontal = FALSE, xlab = "sect", ylab = "dens", main = "Density / Habitat", col = "pink")
boxplot(anguilles$dens ~ anguilles$year, horizontal = FALSE, xlab = "year", ylab = "dens", main = "Density / Year", col = "red")
Graphiques d'interactions (deux facteurs sur le même graphique) windows() ; par(mfrow = c(2,1))
interaction.plot(x.factor = anguilles$year,
trace.factor = anguilles$sect, response = anguilles$dens, fun = mean) interaction.plot(x.factor = anguilles$sect,
trace.factor = anguilles$year, response = anguilles$dens, fun = mean)
Analyse de variance à deux facteurs AVEC INTERACTIONS (modèle peu adapté dans ce cas) # Remarque : la fonction lm est équivalente à la fonction aov()
# aov1 <- lm(formula = anguilles$dens ~ anguilles$sect + anguilles$year
+ anguilles$sect*anguilles$year)
aov1 <- lm(formula = anguilles$dens ~ anguilles$sect + anguilles$year)
coef(aov1) # Estimation des paramètres (effets)
fitted(aov1) # Valeurs prédites
resid(aov1) # Résidus
Test « t » de nullité des coefficients
summary(aov1)
INTERPRETATION
Pour chaque coefficient α, on teste H0 ("α=0") contre H1 ("α non nul"). On rejette H0 si p-value = Pr(Student > |t value|) < seuil (=0.05).
Test F de significativité des effets des différents facteurs
anova(aov1)
INTERPRETATION
Pour chaque facteur Ψ (ici il y a deux facteurs, le facteur « sect » et le facteur « year », on teste H0 ("Ψ n'a pas d'effet sur la réponse") contre H1 ("Ψ a un effet sur la réponse"). On rejette H1 si p-value = Pr(Fisher > F value) < seuil (=0.05).
Analyse graphique des résidus windows() ; par(mfrow = c(2,2))
plot(fitted(aov1), resid(aov1), col = "black",
xlab = "Fitted density", ylab = "Residuals", main = "Residuals vs Fitted")
hist(resid(aov1), xlim = c(-15,15), breaks = 30)
qqnorm(resid(aov1), main = "Residuals QQplot") qqline(resid(aov1))
♦ ♦♦
♦ Exercice
Exemple « saumons »
Variation de la LOGdensité en fonction des différents facteurs ? 1. Explorer les données
Proposer une première interprétation sur la base de l’exploration graphiques des données. Quel modèle pourrait-on construire ?
2. Proposer une analyse de variance de LOGdensity en fonction des différents facteurs.
♦ ♦♦
♦ Solution rm(list = ls())
setwd("D:/A_moi/Routines/R/InitiationR")
saumons <- read.table(file = "saumons.txt", header = TRUE, sep = "")
# 1. Explorer les données # Déclarer les facteurs
saumons$hab <- as.factor(saumons$hab) # déclare “Habitat” comme facteur saumons$sect <- as.factor(saumons$sect)
saumons$year <- as.factor(saumons$year)
# Tabuler les facteurs
levels(saumons$hab) # fait le bilan des niveaux du facteur « habitat » levels(saumons$sect)
levels(saumons$year)
table(saumons$hab) # bilan du nb. d’observation dans chaque niveau table(saumons$sect)
table(saumons$year)
# Moyenne de la log.densité par croisement année x habitat x secteurs
tapply(log(saumons$density), list(saumons$year, saumons$hab, saumons$sect), mean)
# Box plot exploratoires - densité par facteur windows() ; par(mfrow = c(2,2))
boxplot(log(saumons$density) ~ saumons$age, horizontal = FALSE, xlab = "age", ylab = "dens", main = "Density / Age", col = "blue")
boxplot(log(saumons$density) ~ saumons$hab, horizontal = FALSE, xlab = "hab", ylab = "dens", main = "Density / Habitat", col = "pink")
boxplot(log(saumons$density) ~ saumons$year, horizontal = FALSE, xlab = "year", ylab = "dens", main = "Density / Year", col = "red")
boxplot(log(saumons$density) ~ saumons$sect, horizontal = FALSE, xlab = "sect", ylab = "dens", main = "Density / Sect", col = "green")
# Graphiques d'interactions (deux facteurs sur le même graphique) windows() ; par(mfrow = c(3,1))
interaction.plot(x.factor = saumons$year,
trace.factor = saumons$age, response = log(saumons$density), fun = mean) interaction.plot(x.factor = saumons$hab,
trace.factor = saumons$year, response = log(saumons$density), fun = mean) interaction.plot(x.factor = saumons$year,
trace.factor = saumons$hab, response = log(saumons$density), fun = mean)
# 2. ANOVA - modèle : densité = effets age + habitat + année + secteur aov1 <- lm(formula = log(saumons$density)
~ saumons$age + saumons$hab + saumons$year + saumons$sect)
coef(aov1) # Estimation des paramètres (effets)
summary(aov1) # Résumé avec test “t” de nullité des coefficients anova(aov1) # Test “F” de significativité des effets
fitted(aov1) # Valeurs prédites
resid(aov1) # Résidus
# 3. Remise en cause : effet secteur ?
# Le test F précédent montre que l’effet secteur n’est pas significatif. On propose une nouvelle analyse de variance sans effet secteur Ł ANOVA sans effet secteur
aov2 <- lm(formula = log(saumons$density)
~ saumons$age + saumons$hab + saumons$year) summary(aov2)
anova(aov2)
windows()
par(mfrow = c(2,2))
plot(fitted(aov2), resid(aov1), col = "black",
xlab = "Fitted log density", ylab = "Residuals", main = "Residuals vs Fitted") hist(resid(aov2), xlim = c(-2,2), breaks = 30)
qqnorm(resid(aov2), main = "Residuals QQplot") qqline(resid(aov2))
Estimations par les moindres carrés (régression non linéaire)
Exemple des données de croissance « taille-âge »Créer la fonction de croissance de Von Bertalanffy Von.Berta <- function(t,p)
# p = (K, Linf, t0) dans la courbe de Von Bertalanfy # L = Linf*(1-exp(-K*(t-t0)))
{
if ( length(p)==3) { res <- p[2]*(1-exp(-p[1]*(t-p[3]))) } else { res <- "NA" ; print("dim of parameter p is incorrect") } res
} REMARQUE
Si la fonction est enregistrée dans un script Von.Berta.R, il est possible de "charger" la fonction sans avoir besoin de la créer de nouveau à l’aide des instructions
source("U:/A_moi/Routines/R/library_perso/Von.Berta.R") Von.Berta
Charger les données
# setwd("U:/A_moi/Routines/R/InitiationR") setwd("K:/InitiationR")
Growth <- read.table(file = "growth_data.txt", header = TRUE, sep = "") # Créer des vecteurs qui portent le nom des colonnes
attach(Growth)
Régression non linéaire (méthode des "moindres carrés") nls1 <- nls(formula = length ~ Linf*(1-exp(-K*(age-t0))),
start = list(K = 0.1, Linf = 40, t0 = -4), algorithm = "default") Résultats et test "t" approchés de nullités des coefficients
coef(nls1) summary(nls1) Calcul "artisanal" du R²
R2.nls1 <- 1- ( sum(resid(nls1)^2) ) / ( sum((length-mean(length))^2) )
Calcul de la longueur prédite par la fonction avec paramètres estimés et Graphe param <- as.vector(coef(nls1)) # Récupération des paramètres age.t <- seq(1:max(age)) # Un vecteur d’âge pour le graphique
length.t <- Von.Berta(age.t,param) # La taille donnée par la fonction de VB
# Graphique windows()
par(mfrow = c(1,1))
plot(age,length, xlab = "Age", ylab = "Length", type = "p", col = "black", bg = “black”, main = "Non linear least-square (nls)")
Simuler des données (avec et sans aléatoire)
Simuler des données de croissance sans bruit / avec bruit (voir programme VonBerta_Simul.R)
- Simuler un modèle dynamique (modèle SR simple) (Voir programme Ricker_Simul.R)