Decomposing square matrices
Texte intégral
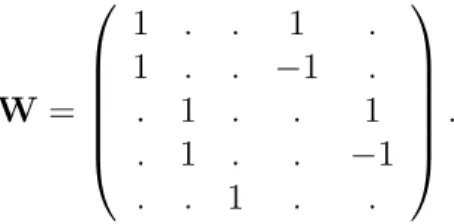
Figure


Documents relatifs
de Seguins Pazzis, The classification of large spaces of matrices with bounded rank, in press at Israel Journal of Mathematics,
Remember that in the reduce function for each key you get a stream of data which is stored in an Iterator in Java.. It is not possible to reset a stream of data (and an iterator) nor
A comparison between the two latter who generally permit to derive different optimal chain parenthesizations (OP’s), raised the interest of computing the matrix chain product in
By such transformations, every matrix can be first brought to its reduced row echelon form by row operations, and then columns with pivots can be moved to the beginning and used
In a Newton method for training deep neural networks, at each conjugate gradient step a Gauss-Newton matrix-vector product is conducted.. Here we discuss our implementation by using
In Section 3 we introduce the Bergman-Schatten classes and prove the similar inequalities to those proved by Nakamura, Ohya and Watanabe for Bergman function spaces.. INEQUALITIES
The first such example was the sharp weighted estimate of the dyadic square function by Hukovic–Treil–Volberg [7] followed by the martingale multiplier by Wittwer [27], the
Structures of Eleclrospraycd Pb(Uradl-Hr Complexes by Infrared Multiple J>huton Oissodalion SIIC<'troscoIIY ... Results and Discussion ... Infrared Characterization of
