Keyword-based speaker localization: Localizing a target speaker in a multi-speaker environment
Texte intégral
Figure
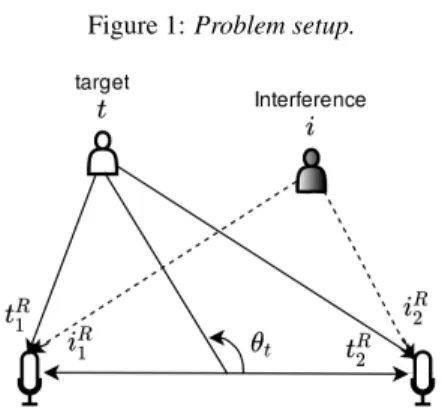
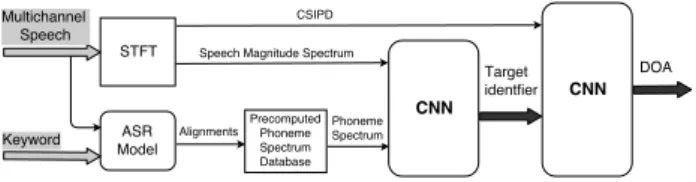
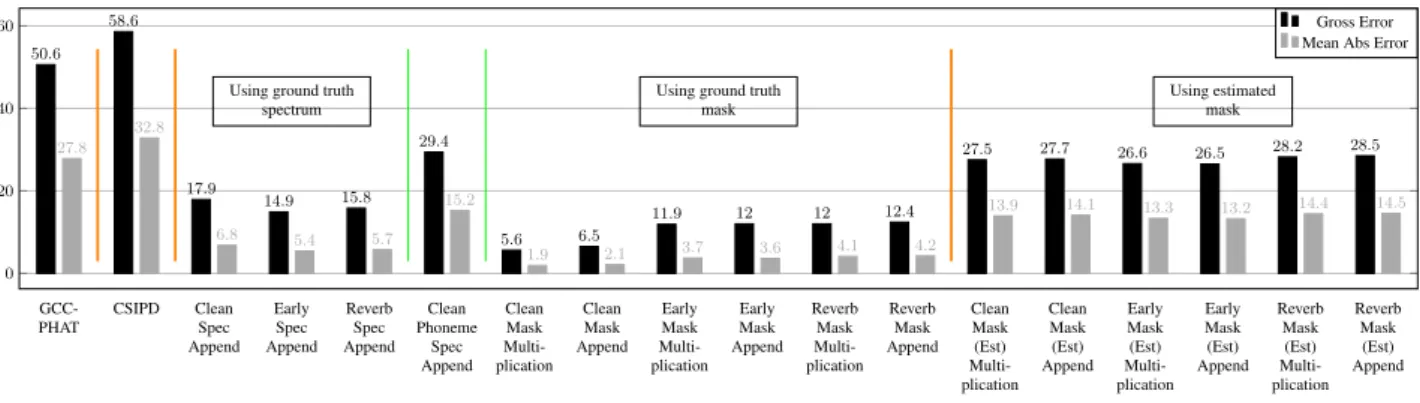
Documents relatifs
In the North, we will partner with the University College of the North to build a new trades training centre to help students take advantage of the good jobs created by Manitoba
Upon receipt of the final recommendations of the Manitoba Round Table, my government will introduce a Sustainable Development act to institutionalize the principles
Last year, following consultations with Manitobans, my government presented our Framework for Economic Growth, a comprehensive strategy aimed directly at long-term job and
My government will continue to place a high priority on investment in infrastructure, and will introduce policies and programs to ensure that Manitoba's infrastructure is capable
My ministers also recognize the economic realities that are facing rural communities and remain firmly committed to working with Manitobans to create and capture opportunities
This year our universities, colleges, and technical institutions will receive total provincial capital support of $52 million to fund the construction of 19 new and
The 1980-81 capital program, involving construction of long-term, lasting assets such as roads, hospitals, educational institutions, and public buildings, will total $1.083 billion, an
At the centre of a new, modern direction for this government is a balanced approach to the choices facing us today: the need to maintain vital public services, the need to cut taxes
