Inverse Kinematics On-line Learning: a Kernel-Based Policy-Gradient approach
Texte intégral
Figure
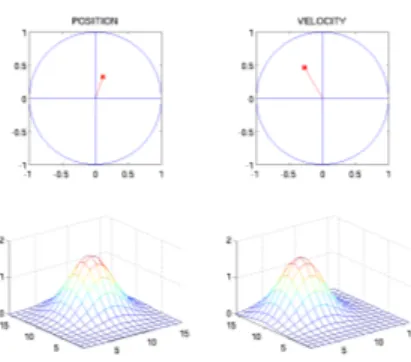
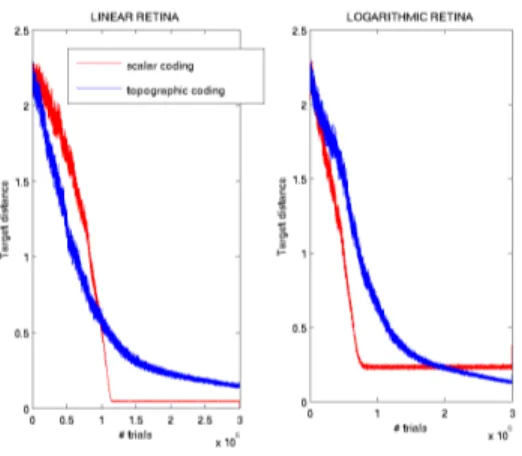
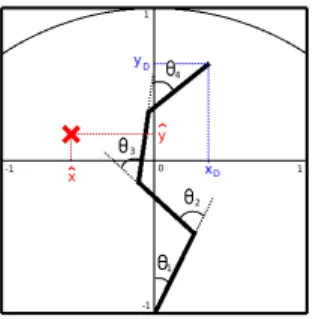
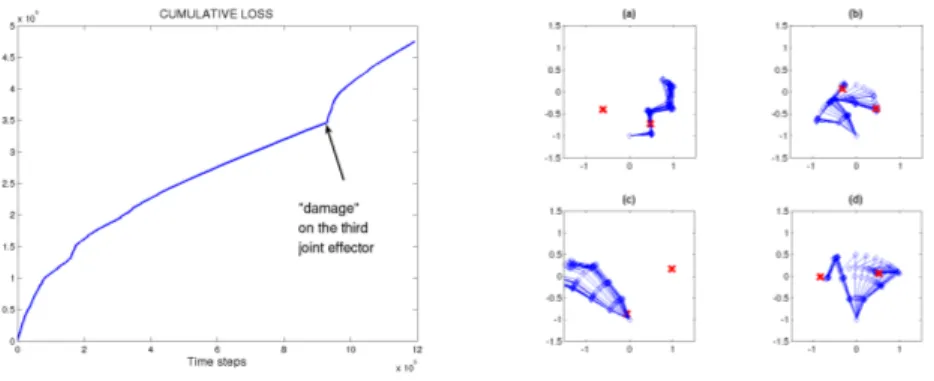
Documents relatifs
Keywords: optimal control, reinforcement learning, policy search, sensitivity analysis, para- metric optimization, gradient estimate, likelihood ratio method, pathwise derivation..
Our main result shows that, under the two above mentioned assumptions (that is, ρ is close to a constant in C 2 and the initial datum is smooth and increasing) the discrete and
In Figure 7.9, one can see that the spread between the average returns of decile 1 and decile 10 is higher for the ML model (9.8%) compared with the linear combination of the top
Indeed, since the pioneering works [12] on the linear Fokker-Planck equation and [15, 16] on the porous medium equation, several equations have been interpreted as gradient flows
Each one is localized by a Point of Reference (PR). To simplify, one measure is analyzed as one pavement marking localized by a PR. The monitoring is not completed by a
A wide range of approaches have been proposed to attenuate or remove line artifacts, including lowpass and notch filters (Luck, 2005), frequency domain filters (Mitra and Pesaran,
Spectral line removal in the LIGO Data Analysis System (LDAS). of the 7th Grav. Wave Data Anal. Coherent line removal: Filtering out harmonically related line interference
Since the edges of the cube and detected edges in the images are equally affected by the same constant errors due to both chemical shifts and magnetic susceptibility, we assume that
