Generating Unsupervised Models for Online Long-Term Daily Living Activity Recognition
Texte intégral
Figure
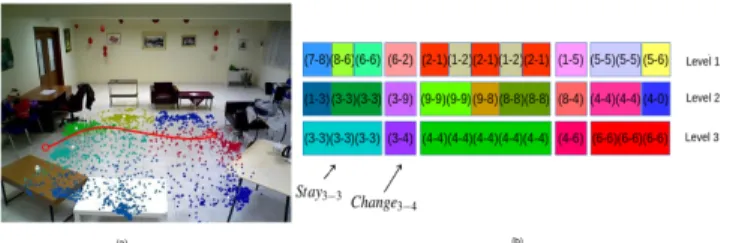
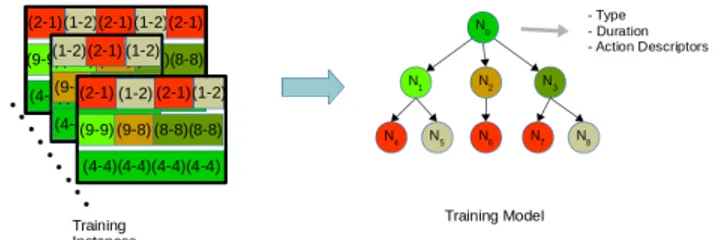

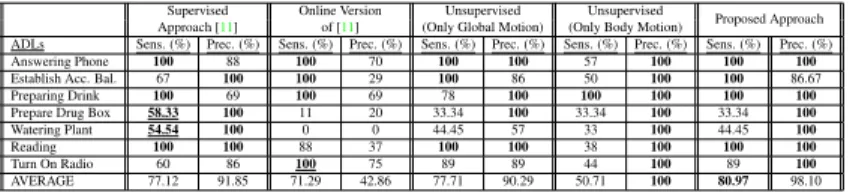
Documents relatifs
response to 70 consecutive flashes.. Evoked cortical potentials from visual association area to a 100-msec flash of low intensity at various times following
Aux heures les plus fraîches de la journée, les conditions bioclimatiques sont légèrement éprouvantes entre novembre et mars (à cause de l'air sec qui rend plus supportable la
290. BERRADA Rachid Gynécologie Obstétrique 291. BOUCHIKHI IDRISSI Med Larbi Anatomie 293. DAALI Mustapha* Chirurgie Générale 298. EL HAJOUI Ghziel Samira
Dans ce développement, on propose de combiner la correction de (Jin et al 2015), liées au taux de défaillance non détecté par le proof test , avec les équations de la norme CEI 61508
For Sen (1987), when players face situations such as the PD, they may adopt reciprocal behaviour because they understand that success in such situations is the result of
Four genomic modules (labeled at top of panel) with different genetic origins are identified; genomic modules are indicated in dark gray. B) Phylogenetic tree constructed by
- 88 - فررررر يةرررررتاذ رررررعا ررررر ذ رررررتاذ ررررراص ةرررررش ررررردي فرررررة ة اذ ا رررررماذ ررررررر ذ رررررررتاذ هررررررر يةرررررررتاذ
Keywords : Green product, Environmental management system, quality of life, economic enterprises, sustainable development. : ةمممدقملا دراوسسملل
![[PDF] Initiation à la programmation en Basic | Cours informatique](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw==)