Automated GUI performance testing
39
0
0
Texte intégral
Figure




+7

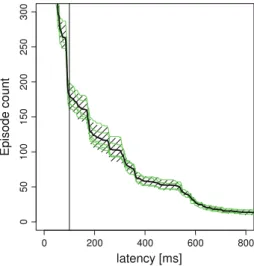

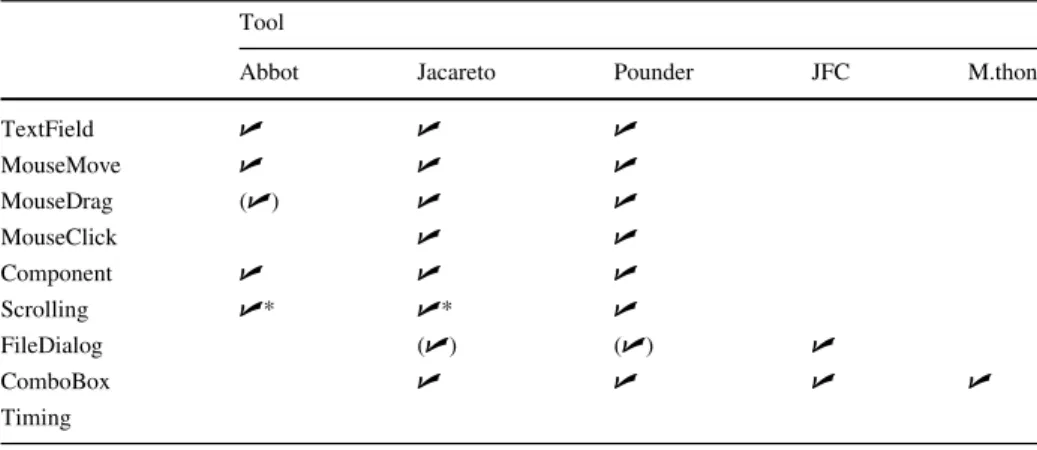

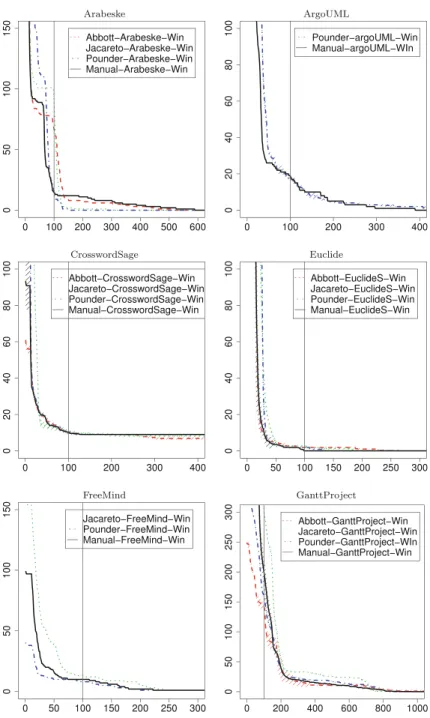
Documents relatifs