Adaptation to Novel Accents: Feature-Based Learning of Context-Sensitive Phonological Regularities
19
0
0
Texte intégral
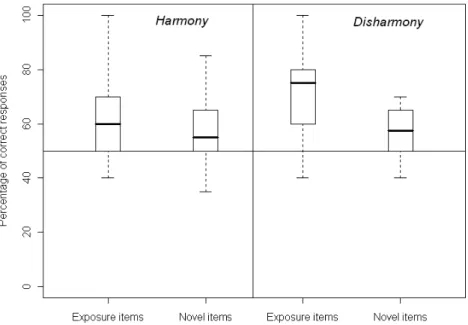
Figure


Documents relatifs