Challenging deep image descriptors for retrieval in heterogeneous iconographic collections
Texte intégral
Figure

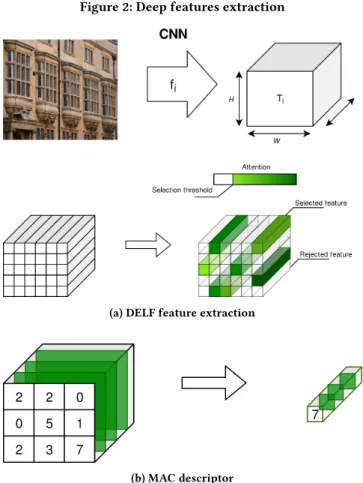
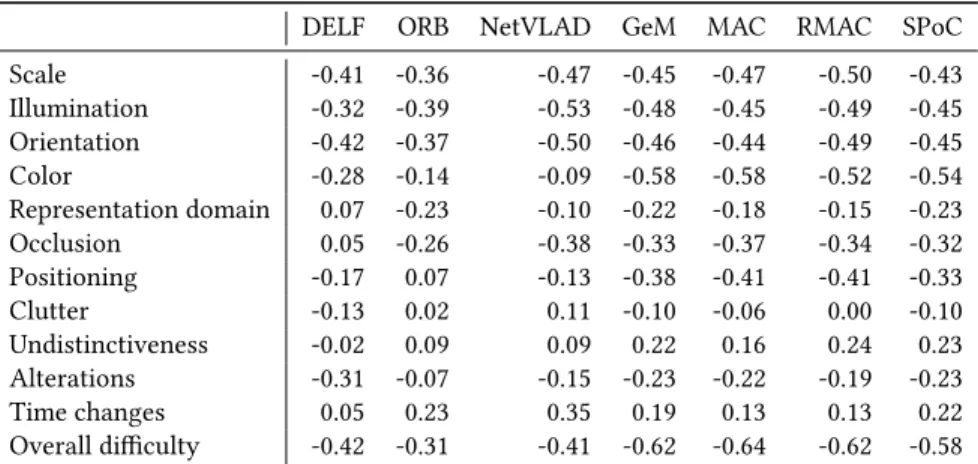

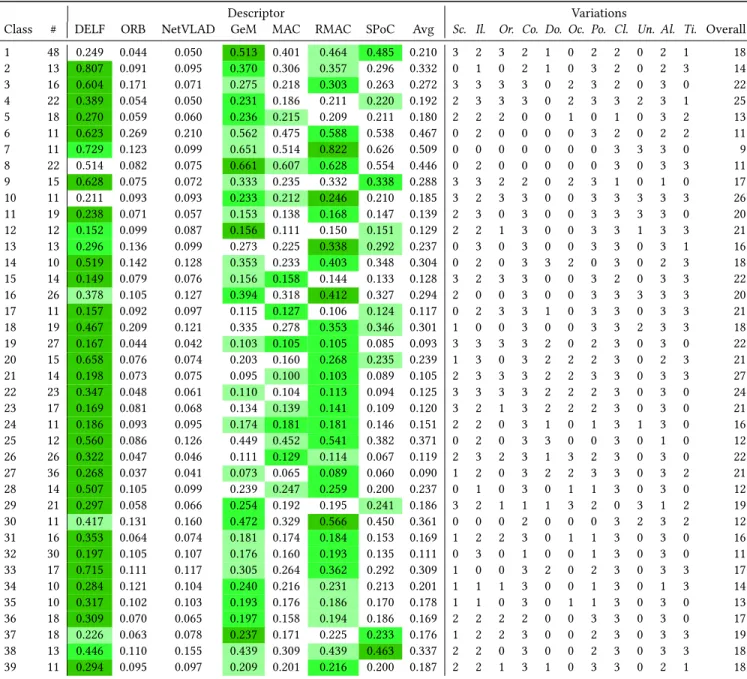
Documents relatifs
6 Comparison of our method RGB(D) versus hallucination network RGB(H), networks trained with only images RGB and oracle descriptor RGBD using both images and depth maps at test time:
– Our two central assumptions (Gaussian mixture model calculated separately on different contexts and only in background images) can slightly improve the foreground/background ratio
Image decomposition and restoration using total variation minimization and the H −1 norm. Convex Analysis, volume 224 of Grundlehren der mathematischen
These observations were the starting point of the decomposition algorithm by Aujol and Chambolle in [17] which split an image into three components: geometry, texture, and noise..
This article relies on two recent developments of well known methods which are a color Fourier transform us- ing geometric algebra [1] and Generalized Fourier descrip- tors defined
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
We focus here on a specific clique-based model, namely the Gripon Berrou neural model (GBNN) [2], which uses the clique structure in the network adjacency matrix to efficiently
Figure 1 provides an illustration of a target cue story sharing a structural correspondence with a superficially dissimilar analog source candidate
