Reducing trace size in multimedia applications endurance tests
Texte intégral
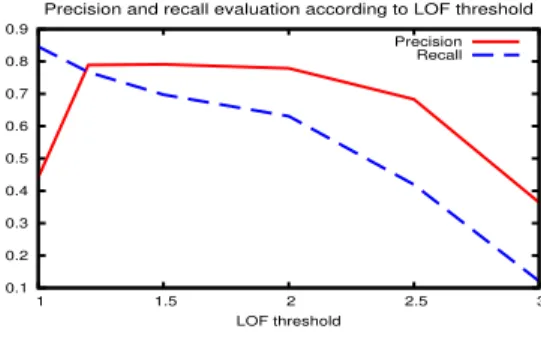
Figure
Documents relatifs
A combination of these techniques has been integrated into the DAMA (Demand Assign- ment Multiple Access) protocol, used in the DVB-RCS standard [4], in order to both ensure a
As an example of novel and e↵ective recommendation techniques, in the following we show a system for recommen- dations of multimedia items, that originally combines intrin- sic
In this paper we show how different ontology design patterns along with state-of-the-art ontology engineering methodologies help during the construction of ontologies, by describing
The development of an intuitive user interface constitutes a central requirement of the system. While preserving the simplicity of use, the application allows: a) access to the
Currently, the team of legal experts is extracting keywords (legal themes) that could provide de basis to classify the different proceedings at hand and is extracting legal concepts
In general, our model checking methodology for the analysis of cryptographic protocols consists of five steps which are (1) protocol and attacker representation, (2)
In this context, the paper first proposes a suitable hardware architecture to implement a feasible WMS node based on off-the-shelf technology, then it shows how the energy
La difficulté, lorsque de telles applications traitent et échangent des documents, est l’automatisation des adaptations nécessaires, ce qui se traduit par la recherche et
