HAL Id: hal-00664499
https://hal.inria.fr/hal-00664499
Submitted on 30 Jan 2012
HAL is a multi-disciplinary open access
archive for the deposit and dissemination of
sci-entific research documents, whether they are
pub-lished or not. The documents may come from
teaching and research institutions in France or
abroad, or from public or private research centers.
L’archive ouverte pluridisciplinaire HAL, est
destinée au dépôt et à la diffusion de documents
scientifiques de niveau recherche, publiés ou non,
émanant des établissements d’enseignement et de
recherche français ou étrangers, des laboratoires
publics ou privés.
Comparison of Spectral Properties of Read, Prepared
and Casual Speech in French
Jean-Luc Rouas, Mayumi Beppu, Martine Adda-Decker
To cite this version:
Jean-Luc Rouas, Mayumi Beppu, Martine Adda-Decker. Comparison of Spectral Properties of Read,
Prepared and Casual Speech in French. LREC, May 2010, Valetta, Malta. �hal-00664499�
Comparison of spectral properties of read, prepared and casual
speech in French
Jean-Luc Rouas
1, Mayumi Beppu
2, Martine Adda-Decker
11LIMSI-CNRS UPR 3251, France
2 Dept. Computer Science, Tokyo Institute of Technology, Japan
rouas@limsi.fr, beppu@ks.cs.titech.ac.jp, madda@limsi.fr Abstract
In this paper, we investigate the acoustic properties of phonemes in three speaking styles: read speech, prepared speech and spontaneous speech. Our aim is to better understand why speech recognition systems still fails to achieve good performances on spontaneous speech. This work follows the work of Nakamura et al. (Nakamura et al., 2008) on Japanese speaking styles, with the difference that we here focus on French. Using Nakamura’s method, we use classical speech recognition features, MFCC, and try to represent the effects of the speaking styles on the spectral space. Two measurements are defined in order to represent the spectral space reduction and the spectral variance extension. Experiments are then carried on to investigate if indeed we find some differences between the three speaking styles using these measurements. We finally compare our results to those obtained by Nakamura on Japanese to see if the same phenomenon appears.
1.
Introduction
This work follows the work of Nakamura et al. (Naka-mura et al., 2008) on Japanese speaking styles, with the difference that we here focus on French. We first conduct the same experiments as Nakamura and then propose further analysis. Motivations for this work are expressed in section 2.. The section 3. describes the analysis method. In section 4., we recall the experiments and the results obtained by Nakamura on Japanese. The next section, section 5., details the French corpora we are using. The experiments achieved on this French data are detailed in section 6.. In the last section, we compare the results between Japanese and French data whenever they may be com-pared, and we propose further analyses.
2.
Motivations
After having focused mainly on read speech, the auto-matic speech transcription systems also achieve nowa-days very good performances on broadcast news data (usually around 10-15% of Word Error Rate (Fousek et al., 2008)). These systems benefit of years of re-search focused only on the automatic transcription of read speech and broadcast news data, which can be attested by looking at the numerous NIST evaluations carried on during the last decades.
However, when coping with spontaneous speech, even the best actual systems achieve quite poor perfor-mances, with an accuracy that may be as low as 40%. These results emphasise the fact that sponta-neous speech and read speech are indeed very different both acoustically and linguistically (Furui, 2003). One of the remaining challenges for automatic speech transcription is to give the systems the ability to deal with every kind of input data, including spontaneous speech. To fulfil this goal, it is crucial to analyse what are the most noticeable differences between speaking
styles using features traditionally used by automatic speech transcription systems.
On the acoustic point of view, it is known that the spectral distribution of continuously spoken vowels or syllables is much smaller than that of isolated spo-ken vowels or syllables. This phenomenon is some-times called spectral reduction. Similar reduction have been observed in the parametric space for spontaneous speech compared to read speech, using formant fre-quency data measured from one speaker (van Son and Pols, 1999). A study on Japanese confirmed this ob-servation using large corpora (Nakamura et al., 2008). Considering French, we know that read speech and spontaneous speech are structurally different. Com-plex syllables tend to be simplified, and deletion of the word-final consonants and vowels of unstressed sylla-bles frequently occurs in French spontaneous speech (Adda-Decker et al., 2005).
This phenomenon may be responsible for some of the automatic transcription errors on spontaneous speech. That is why we propose to study it in this paper. Another phenomenon that may characterise sponta-neous speech is the spectral variance extension. This phenomenon has been studied in (Nakamura et al., 2008) on Japanese data.
In the following section, we present the approaches used to compute means to assess these phenomena.
3.
Acoustic analysis method
3.1. Features
Utterances are digitalised using 16kHz sampling, and segmented by silences of 400 ms duration or longer. The speech waveform are converted to 12 dimensional MFCC vectors using a 25 ms length window shifted every 10 ms. The MFCC vectors are augmented with their first and second derivatives, together with the first and second differential log-energy, resulting in 38-dimensional vectors.
3.2. Spectral reduction ratio
In order to characterise the spectral reduction phe-nomenon, we must use a reference corpus. This corpus, hereafter denoted R, is in our case a read speech cor-pus.
The spectral space extent is estimated by calculating the difference between the mean of the MFCC features for a given phoneme p and the averaged value over all the phonemes of the same corpus.
The ratio is then computed by dividing the spectral space extent for the corpus X with the one measured for the reference corpus R.
The distances used in this paper are euclidean dis-tances.
In formal terms, the spectral reduction ratio can be expressed by the following formula:
redp(X) =
kµp(X) − Av(µp(X))k
kµp(R) − Av(µp(R))k
(1) with µp being the mean vector of phoneme p uttered
with the speaking style X, µp(R) is the mean vector
for phoneme p for read speech, and Av indicates the average value.
3.3. Spectral variance extension ratio
Using a similar method, we now define the variance extension ratio, still using the reference corpus R. The spectral variance is estimated as being the sum of the variances obtained for each MFCC coefficient for all the realisations of a phoneme p.
The spectral variance extension ratio is thus defined as being the ratio between the spectral variance of the phoneme p on the corpus X and the spectral variance of the same phoneme on the corpus R.
The formalised method used to compute this ratio is:
extp(X) = PK k=1σ 2 pk(X) PK k=1σpk2 (R) (2)
with K being the dimension of the MFCC vector, and σ2
pk(X) the kth dimensional element of the variance
vector of MFCC for phoneme p uttered with speaking style X.
4.
Acoustic characteristics of Japanese
speaking styles (Nakamura et al.,
2008)
In (Nakamura et al., 2008), various speaking styles are analysed using large-scale Japanese speech corpora. This work focused mainly on the analysis of the differ-ences between acoustic characteristics for spontaneous and read speech.
The data used in these experiments come from the Cor-pus of Spontaneous Japanese (CSJ) (Maekawa, 2003) and the Japanese Newspaper Article Sentence (JNAS) (Itou et al., 1999). The CSJ corpus is composed of 660 hours of speech and was recorded from 1999 to 2004. The JNAS corpus consists in 60 hours of speech. It was recorded from 1995 to 1997.
These corpus covers several conditions, including monologue, dialogue and read speech. For the purpose of the following experiments, only some situations, con-sidered most representative of a speaking style, are utilised. These are, ranking from the most formal to the most informal: Read speech, Academic presenta-tions, Extemporeaneous presentations (informal pre-sentations), Dialogue.
The experiments carried on using this framework show that reduction of MFCC space is observed for almost all the phonemes in the three speaking styles in com-parison with read speech. This phenomenon is most noticeable for the dialogue utterances.
Results obtained using the spectral variance extension ratio indeed show that an extension of the variance is observed for almost all the phonemes in the three speaking styles.
5.
French corpora
Three speech corpora with read, prepared and casual spontaneous speaking styles were used. The reference read speech corpus is the French BREF (Lamel et al., 1991) corpus composed of read newspaper speech. BREF includes over 100 h of speech from 120 speak-ers. The text materials were selected from the French newspaper Le Monde, so as to provide a large vocab-ulary (over 20,000 words) and a wide range of phonetic environments.
Prepared speech comes from the development and test sets of the ESTER 2003-2004 and ESTER2 2007-2008 evaluation campaigns (Galliano et al., 2006) to-talling about 50 hours of speech. The journalistic speech were selected from various French and franco-phone (Maghreb and Africa) radios: France Inter, Ra-dio France International, RaRa-dio Television du Maroc, France Info.
Casual spontaneous speech comes from the NCCFr cor-pus (Torreira et al., in press), composed of conversa-tions between friends. NCCFr, totalling 36 hours of speech, comprises 23 pairs of speakers (24 males, 22 females) producing conversation of about 90 minutes each. recorded in 2007 in Paris
Each corpus is hereafter called BREF, ESTER, NC-CFr respectively. All this corpus comprise manual or-thographic transcriptions, which have been phonetised and automatically aligned.
6.
Experiments
The first experiment aims at measuring the durations of the automatically aligned phonemes for the three corpora. This is done in order to visualise the distri-bution of phoneme durations for each speaking style and to select the phonemes according to their dura-tion.
The result of this experiment is drawn in figure 1. As seen on this figure, the distributions are quite sim-ilar for BREF and ESTER, with a slight shift to the left for ESTER. This shift may be due to the effect of speaking rate, which should be faster for prepared journalistic speech than for read speech.
0,00 0,02 0,04 0,06 0,08 0,10 0,12 0,14 0,16 0,18 0,20 0,22 0,24 0,26 0,28 0,30 0,00 0,05 0,10 0,15 0,20 0,25 BREF (read) ESTER (prepared) NCCFr (spontaneous) Duration (s)
Figure 1: Duration distribution for each corpus. X-axis : duration in seconds, Y-X-axis : estimation of the probability
The shape of the distribution for the NCCFr corpus is however very different. We can observe a peak for phonemes of 30 ms duration, which is the shorter du-ration allowed by the automatic alignment. This may be an effect of conversational spontaneous speech, for which some phonemes might be subject to deletion (see (Adda-Decker et al., 2008) for more details on this phe-nomenon).
Although the shapes clearly differs, the median value for each distribution is almost the same (between 60 and 70 ms). Thus, we will first consider only “normal” length segments, which have a duration between 40 and 120 ms.
6.1. Phoneme reduction ratio & variance extension
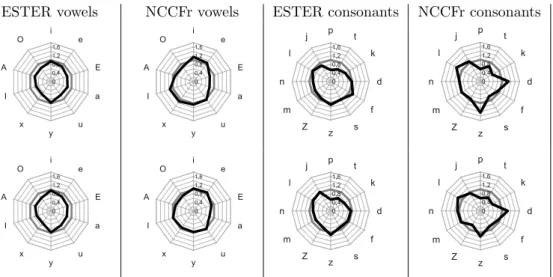
The phoneme reduction ratio and variance extension ratio are computed on our data using the same formula respectively described in sections 3.2., equation 1 and 3.3., equation 2. The reference corpus R, used for all the following experiments, is the BREF corpus. As we can observe on the first two columns of figure 2, the spectral space reduction is observed mainly for the ESTER corpus. For this corpus, almost all the phonemes have a reduced spectral space, except /i/ and /y/.
However, for NCCFr, the spectral reduction phe-nomenon is not as obvious. In fact, the spectral space seems almost identical to that of read speech, with a few exceptions.
The results on the spectral variance extension, shown on the last two columns of figure 2, are in accordance with our expectations. The spectral variance is in-dubitably increased for ESTER, and even more for ERNESTUS.
6.2. Influence of segment duration
As the results from the previous section are a bit sur-prising, we have therefore investigated if the observed reduction phenomenon may be emphasised or not for short or long segments, short segments being segments
ESTER red NCCFr red
BREF ESTER 1 0,95 1 0,76 1 0,77 1 0,7 1 0,67 1 0,72 1 0,97 1 0,79 1 0,77 1 0,72 1 0,78 1 0,8 1 0,86 i O A I x @ y u o c a E e 0 0,4 0,8 1,2 1,6 BREF 1 1,07 1 0,85 1 0,88 1 1,04 1 1,01 1 1,07 1 1,01 1 1,01 1 0,97 1 0,89 1 0,78 1 0,85 1 1,09 NCCFr i O A I x @ y u o c a E e 0 0,4 0,8 1,2 1,6 BREF ESTER p 1 0,53 w 1 0,89 h 1 1,03 j 1 0,86 r 1 0,61 1 0,69 N 1 0,46 n 1 0,74 m 1 0,73 Z 1 1,23 z 1 0,88 v 1 1,11 S 1 0,72 s 1 1,13 f 1 1,06 g 1 1,09 d 1 0,94 b 1 0,83 k 1 0,51 t 1 0,52 p w h j r N n m Z z v S s f g d b k t l l p w h j r l N n m Z z v S s f g d b k t 0 0,4 0,8 1,2 1,6 BREF p 1 0,28 w 1 0,83 h 1 1,09 j 1 0,83 r 1 0,74 1 0,96 N 1 0,93 n 1 0,81 m 1 0,78 Z 1 0,9 z 1 0,98 v 1 1,27 S 1 0,52 s 1 0,79 f 1 0,39 g 1 0,93 d 1 1,06 b 1 0,72 k 1 0,3 t 1 0,35 p w h j r N n m Z z v S s f g d b k t NCCFr l l p w h j r l N n m Z z v S s f g d b k t 0 0,4 0,8 1,2 1,6
ESTER ext NCCFr ext
BREF ESTER 1 1,24 1 1,24 1 1,25 1 1,27 1 1,26 1 1,24 1 1,22 1 1,16 1 1,17 1 1,18 1 1,25 1 1,22 1 1,24 1,24 1,3 1,24 1,41 1,25 1,29 1,27 1,37 1,26 1,25 1,24 1,18 1,22 1,35 1,16 1,26 1,17 1,24 1,18 1,21 1,25 1,31 1,22 1,35 1,24 1,25 i O A I x @ y u o c a E e 0 0,4 0,8 1,2 1,6 BREF 1 1,3 1 1,41 1 1,29 1 1,37 1 1,25 1 1,18 1 1,35 1 1,26 1 1,24 1 1,21 1 1,31 1 1,35 1 1,25 1,24 1,24 1,25 1,27 1,26 1,24 1,22 1,16 1,17 1,18 1,25 1,22 1,24 NCCFr i O A I x @ y u o c a E e 0 0,4 0,8 1,2 1,6 BREF ESTER p 1 1,14 w 1 1,02 h 1 1,07 j 1 1,1 r 1 1,07 1 1,15 N 1 1,2 n 1 1,1 m 1 1,04 Z 1 0,98 z 1 0,99 v 1 1,07 S 1 1,17 s 1 1,17 f 1 1,5 g 1 0,95 d 1 1,06 b 1 1,13 k 1 1,18 t 1 1,04 p 1,14 1,34 w 1,02 1,21 h 1,07 1,45 j 1,1 1,15 r 1,07 1,15 1,15 1,21 N 1,2 1,2 n 1,1 1,36 m 1,04 1,16 Z 0,98 1,04 z 0,99 1,04 v 1,07 1,28 S 1,17 1,06 s 1,17 1,31 f 1,5 1,67 g 0,95 1,06 d 1,06 1,21 b 1,13 1,23 k 1,18 1,32 t 1,04 1,21 f g d b k t l l p w h j r l N n m Z z v S s f g d b k t 0 0,4 0,8 1,2 1,6 BREF p 1 1,34 w 1 1,21 h 1 1,45 j 1 1,15 r 1 1,15 1 1,21 N 1 1,2 n 1 1,36 m 1 1,16 Z 1 1,04 z 1 1,04 v 1 1,28 S 1 1,06 s 1 1,31 f 1 1,67 g 1 1,06 d 1 1,21 b 1 1,23 k 1 1,32 t 1 1,21 p 1,14 w 1,02 h 1,07 j 1,1 r 1,07 1,15 N 1,2 n 1,1 m 1,04 Z 0,98 z 0,99 v 1,07 S 1,17 s 1,17 f 1,5 g 0,95 d 1,06 b 1,13 k 1,18 t 1,04 f g d b k t NCCFr l l p w h j r l N n m Z z v S s f g d b k t 0 0,4 0,8 1,2 1,6
Figure 2: spectral reduction ratio (red) and variance extension (ext) for the ESTER and NCCFr corpora compared with BREF
under 40 ms duration, long segments being over 120 ms.
Figure 3 shows the spectral reduction ratio for the ES-TER and NCCFr corpora compared to BREF for both duration conditions. We observe that for short seg-ments, especially for the NCCFr corpus, the spectral space is quite reduced. Even given the short duration of those segments, this phenomenon should not be ne-glected as short segments are indeed frequent in our conversational speech corpus. We can note however that the spectral space reduction is not very impor-tant for longer segments.
The variance extension ratio has also been computed for both duration conditions (see figure 4). The figures show that the variance of phonemes are extended for both conditions. The extension appears to be stronger for short segments of conversational speech as opposed to long segments. This phenomenon is observed for both speaking styles.
ESTER vowels NCCFr vowels ESTER consonants NCCFr consonants BREF ESTER 1 0,86 1 0,58 1 0,72 1 0,59 1 0,47 1 0,59 1 0,83 1 0,69 1 0,75 1 0,64 1 0,69 1 0,64 1 0,75 i O A I x @ y u o c a E e 0 0,4 0,8 1,2 1,6 BREF 1 0,68 1 0,63 1 0,61 1 1,01 1 0,76 1 0,81 1 0,71 1 0,45 1 0,76 1 0,81 1 0,7 1 0,63 1 0,89 NCCFr i O A I x @ y u o c a E e 0 0,4 0,8 1,2 1,6 BREF ESTER p 1 0,53 w 1 0,89 h 1 1,03 j 1 0,86 r 1 0,61 1 0,69 N 1 0,46 n 1 0,74 m 1 0,73 Z 1 1,23 z 1 0,88 v 1 1,11 S 1 0,72 s 1 1,13 f 1 1,06 g 1 1,09 d 1 0,94 b 1 0,83 k 1 0,51 t 1 0,52 p w h j r N n m Z z v S s f g d b k t l l p w h j r l N n m Z z v S s f g d b k t 0 0,4 0,8 1,2 1,6 BREF p 1 0,28 w 1 0,83 h 1 1,09 j 1 0,83 r 1 0,74 1 0,96 N 1 0,93 n 1 0,81 m 1 0,78 Z 1 0,9 z 1 0,98 v 1 1,27 S 1 0,52 s 1 0,79 f 1 0,39 g 1 0,93 d 1 1,06 b 1 0,72 k 1 0,3 t 1 0,35 p w h j r N n m Z z v S s f g d b k t NCCFr l l p w h j r l N n m Z z v S s f g d b k t 0 0,4 0,8 1,2 1,6 BREF ESTER 1 0,92 1 0,75 1 0,75 1 0,8 1 0,67 1 0,75 1 0,92 1 0,78 1 0,74 1 0,77 1 0,88 1 0,84 1 0,85 i O A I x @ y u o c a E e 0 0,4 0,8 1,2 1,6 BREF 1 1,12 1 0,94 1 0,93 1 1,18 1 0,88 1 0,99 1 1,05 1 1 1 0,92 1 0,85 1 0,8 1 0,82 1 1,05 NCCFr i O A I x @ y u o c a E e 0 0,4 0,8 1,2 1,6 BREF ESTER p 1 0,48 w 1 0,74 h 1 1,04 j 1 0,9 r 1 0,91 1 0,97 N 1 0,89 n 1 0,75 m 1 0,78 Z 1 0,87 z 1 1,02 v 1 1,28 S 1 0,98 s 1 0,93 f 1 1 g 1 1,1 d 1 0,95 b 1 0,85 k 1 0,65 t 1 0,55 p w h j r N n m Z z v S s f g d b k t l l p w h j r l N n m Z z v S s f g d b k t 0 0,4 0,8 1,2 1,6 BREF p 1 0,54 w 1 0,84 h 1 1,31 j 1 1,15 r 1 1,13 1 1,26 N 1 1,11 n 1 1,05 m 1 1,11 Z 1 0,89 z 1 1,23 v 1 1,43 S 1 0,89 s 1 0,81 f 1 0,93 g 1 1,18 d 1 1,2 b 1 1,13 k 1 0,68 t 1 0,73 p w h j r N n m Z z v S s f g d b k t NCCFr l l p w h j r l N n m Z z v S s f g d b k t 0 0,4 0,8 1,2 1,6
Figure 3: spectral reduction ratio for the ESTER and NCCFr corpora compared with BREF for different phoneme durations. first line : short phonemes, second line : long phonemes (>120ms)
ESTER vowels NCCFr vowels ESTER consonants NCCFr consonants
BREF ESTER 1 1,24 1 1,31 1 1,03 1 0,97 1 1,33 1 1,39 1 1,18 1 1,24 1 1,15 1 1,19 1 1,11 1 1,19 1 1,19 1,24 1,45 1,31 1,46 1,03 1,14 0,97 1,14 1,33 1,33 1,39 1,36 1,18 1,37 1,24 1,59 1,15 1,31 1,19 1,26 1,11 1,18 1,19 1,49 1,19 1,4 i O A I x @ y u o c a E e 0 0,4 0,8 1,2 1,6 BREF 1 1,45 1 1,46 1 1,14 1 1,14 1 1,33 1 1,36 1 1,37 1 1,59 1 1,31 1 1,26 1 1,18 1 1,49 1 1,4 1,24 1,31 1,03 0,97 1,33 1,39 1,18 1,24 1,15 1,19 1,11 1,19 1,19 NCCFr i O A I x @ y u o c a E e 0 0,4 0,8 1,2 1,6 BREF ESTER p 1 1,14 w 1 1,02 h 1 1,07 j 1 1,1 r 1 1,07 1 1,15 N 1 1,2 n 1 1,1 m 1 1,04 Z 1 0,98 z 1 0,99 v 1 1,07 S 1 1,17 s 1 1,17 f 1 1,5 g 1 0,95 d 1 1,06 b 1 1,13 k 1 1,18 t 1 1,04 p 1,14 1,34 w 1,02 1,21 h 1,07 1,45 j 1,1 1,15 r 1,07 1,15 1,15 1,21 N 1,2 1,2 n 1,1 1,36 m 1,04 1,16 Z 0,98 1,04 z 0,99 1,04 v 1,07 1,28 S 1,17 1,06 s 1,17 1,31 f 1,5 1,67 g 0,95 1,06 d 1,06 1,21 b 1,13 1,23 k 1,18 1,32 t 1,04 1,21 f g d b k t l l p w h j r l N n m Z z v S s f g d b k t 0 0,4 0,8 1,2 1,6 BREF p 1 1,34 w 1 1,21 h 1 1,45 j 1 1,15 r 1 1,15 1 1,21 N 1 1,2 n 1 1,36 m 1 1,16 Z 1 1,04 z 1 1,04 v 1 1,28 S 1 1,06 s 1 1,31 f 1 1,67 g 1 1,06 d 1 1,21 b 1 1,23 k 1 1,32 t 1 1,21 p 1,14 w 1,02 h 1,07 j 1,1 r 1,07 1,15 N 1,2 n 1,1 m 1,04 Z 0,98 z 0,99 v 1,07 S 1,17 s 1,17 f 1,5 g 0,95 d 1,06 b 1,13 k 1,18 t 1,04 f g d b k t NCCFr l l p w h j r l N n m Z z v S s f g d b k t 0 0,4 0,8 1,2 1,6 BREF ESTER 1 1,24 1 1,23 1 1,26 1 1,25 1 1,23 1 1,3 1 1,15 1 1,26 1 1,31 1 1,37 1 1,29 1 1,36 1 1,25 1,24 1,23 1,23 1,38 1,26 1,24 1,25 1,21 1,23 1,23 1,3 1,25 1,15 1,18 1,26 1,28 1,31 1,4 1,37 1,54 1,29 1,34 1,36 1,47 1,25 1,16 i O A I x @ y u o c a E e 0 0,4 0,8 1,2 1,6 BREF 1 1,23 1 1,38 1 1,24 1 1,21 1 1,23 1 1,25 1 1,18 1 1,28 1 1,4 1 1,54 1 1,34 1 1,47 1 1,16 1,24 1,23 1,26 1,25 1,23 1,3 1,15 1,26 1,31 1,37 1,29 1,36 1,25 NCCFr i O A I x @ y u o c a E e 0 0,4 0,8 1,2 1,6 BREF ESTER p 1 2,13 w 1 1,26 h 1 1,21 j 1 1,23 r 1 0,96 1 1,09 N 1 1,12 n 1 1,28 m 1 1,14 Z 1 1,04 z 1 1,08 v 1 1,04 S 1 1,26 s 1 1,61 f 1 1,57 g 1 1,15 d 1 1,18 b 1 1,29 k 1 1,35 t 1 1,88 p 2,13 2 w 1,26 1,18 h 1,21 1,44 j 1,23 1,04 r 0,96 0,96 1,09 1,01 N 1,12 1,24 n 1,28 1,2 m 1,14 1,02 Z 1,04 0,95 z 1,08 0,97 v 1,04 1,02 S 1,26 0,98 s 1,61 0,97 f 1,57 0,93 g 1,15 1,06 d 1,18 1,14 b 1,29 1,28 k 1,35 1,21 t 1,88 1,5 g d b k t l l p w h j r l N n m Z z v S s f g d b k t 0 0,4 0,8 1,2 1,6 BREF p 1 2 w 1 1,18 h 1 1,44 j 1 1,04 r 1 0,96 1 1,01 N 1 1,24 n 1 1,2 m 1 1,02 Z 1 0,95 z 1 0,97 v 1 1,02 S 1 0,98 s 1 0,97 f 1 0,93 g 1 1,06 d 1 1,14 b 1 1,28 k 1 1,21 t 1 1,5 p 2,13 w 1,26 h 1,21 j 1,23 r 0,96 1,09 N 1,12 n 1,28 m 1,14 Z 1,04 z 1,08 v 1,04 S 1,26 s 1,61 f 1,57 g 1,15 d 1,18 b 1,29 k 1,35 t 1,88 g d b k t NCCFr l l p w h j r l N n m Z z v S s f g d b k t 0 0,4 0,8 1,2 1,6
Figure 4: spectral variance extension ratio for the ESTER and NCCFr corpora compared with BREF for different phoneme durations.first line : short phonemes, second line : long phonemes (>120ms)
6.3. Influence of lexical content
In this section, we will focus of acoustic differences that might be observed while considering the role of the words. We have distinguished function and content words, based on the word frequency in each corpus. First, words are ranged in decreasing frequencies. Function words are then isolated using the following paradigm: they are the 100 most frequent words, as long as their cumulated count is less than 50% of all the words in the corpus. Some content words occur-ing in this list are manually removed: as we deal here with french news corpora (BREF and ESTER), some of the most frequent words are for example “France”, “Monsieur”, “pr´esident”.
Moreover, function words do not cover all the french phonemes equally. We have thus removed from the analysis the phonemes that occur less than 1000 times. Those omitted phonemes are : /c o @/ and /b g S v N r h w/.
The results of the analysis are shown in figure 5 for the spectral space reduction, and in figure 6 for the
variance extension.
Figure 5 shows that the spectral space is always more conserved for the content words than for the function words.
The variance extension ratio is larger for the vowels contained in function words than for content words.
7.
Discussion
Nakamura, in (Nakamura et al., 2008) seems to pro-vide results showing quite clearly the effects of spec-tral space reduction and specspec-tral variance extension in Japanese. On his data, the spectral space is more re-duced when the speaking style gets more spontaneous. Similarly, the spectral variance is increased for spon-taneous data.
In our experiments on French data, we have been able to observe the same phenomenon for the spectral vari-ance. The tests carried on “normal” duration phonemes do not however show the same behaviour for the spec-tral reduction. The specspec-tral space is more reduced for
ESTER vowels NCCFr vowels ESTER consonants NCCFr consonants BREF ESTER 1 0,94 1,14 1 0,78 0,85 1 0,79 0,89 1 0,71 1,14 1 0,71 1,12 1 0,96 1,06 1 0,76 1,02 1 0,81 0,78 1 0,79 0,79 1 0,87 1,07 0,96 1,05 0,75 0,87 0,76 0,87 0,69 0,99 0,67 0,93 0,73 1,08 0,98 0,96 0,8 1,01 0,75 0,99 0,71 0,9 0,77 0,78 0,8 0,88 0,84 1,07 i O A I x y u a E e 0 0,4 0,8 1,2 1,6 BREF 1 1,14 1 0,85 1 0,89 1 1,14 1 1,12 1 1,06 1 1,02 1 0,78 1 0,79 1 1,07 0,96 1,05 0,75 0,87 0,76 0,87 0,69 0,99 0,67 0,93 0,73 1,08 0,98 0,96 0,8 1,01 0,75 0,99 0,71 0,9 0,77 0,78 0,8 0,88 0,84 1,07 NCCFr i O A I x y u a E e 0 0,4 0,8 1,2 1,6 BREF ESTER 1 0,54 0,57 1 0,86 1,06 1 0,97 1,28 1 0,83 0,97 1 0,85 1 1 0,9 0,92 1 1,09 1,43 1 0,96 0,8 1 1,19 0,91 1 0,98 1,29 1 0,78 0,63 1 0,65 0,81 0,53 0,59 0,73 0,86 1,1 1,35 1,02 0,94 0,88 1,12 0,95 1,2 0,85 1,04 0,82 1,06 0,81 1,04 0,83 0,75 1,11 1,18 1,12 1,6 0,96 0,85 0,88 0,82 0,93 0,9 1,13 1,48 0,94 1,25 0,9 1,18 0,73 0,63 0,68 0,71 p j l n m Z z s f d k t 0 0,4 0,8 1,2 1,6 BREF 1 0,57 1 1,06 1 1,28 1 0,97 1 1 1 0,92 1 1,43 1 0,8 1 0,91 1 1,29 1 0,63 1 0,81 0,53 0,59 0,73 0,86 1,1 1,35 1,02 0,94 0,88 1,12 0,95 1,2 0,85 1,04 0,82 1,06 0,81 1,04 0,83 0,75 1,11 1,18 1,12 1,6 0,96 0,85 0,88 0,82 0,93 0,9 1,13 1,48 0,94 1,25 0,9 1,18 0,73 0,63 0,68 0,71 NCCFr p j l n m Z z s f d k t 0 0,4 0,8 1,2 1,6 BREF ESTER 1 0,96 1,05 1 0,75 0,87 1 0,76 0,87 1 0,69 0,99 1 0,67 0,93 1 0,98 0,96 1 0,8 1,01 1 0,77 0,78 1 0,8 0,88 1 0,84 1,07 0,96 1,05 0,75 0,87 0,76 0,87 0,69 0,99 0,67 0,93 0,73 1,08 0,98 0,96 0,8 1,01 0,75 0,99 0,71 0,9 0,77 0,78 0,8 0,88 0,84 1,07 i O A I x y u a E e 0 0,4 0,8 1,2 1,6 BREF 1 1,05 1 0,87 1 0,87 1 0,99 1 0,93 1 0,96 1 1,01 1 0,78 1 0,88 1 1,07 0,96 1,05 0,75 0,87 0,76 0,87 0,69 0,99 0,67 0,93 0,73 1,08 0,98 0,96 0,8 1,01 0,75 0,99 0,71 0,9 0,77 0,78 0,8 0,88 0,84 1,07 NCCFr i O A I x y u a E e 0 0,4 0,8 1,2 1,6 BREF ESTER 1 0,53 0,59 1 1,02 0,94 1 0,95 1,2 1 0,82 1,06 1 0,81 1,04 1 0,83 0,75 1 1,11 1,18 1 0,88 0,82 1 0,93 0,9 1 0,94 1,25 1 0,73 0,63 1 0,68 0,71 0,53 0,59 0,73 0,86 1,1 1,35 1,02 0,94 0,88 1,12 0,95 1,2 0,85 1,04 0,82 1,06 0,81 1,04 0,83 0,75 1,11 1,18 1,12 1,6 0,96 0,85 0,88 0,82 0,93 0,9 1,13 1,48 0,94 1,25 0,9 1,18 0,73 0,63 0,68 0,71 p j l n m Z z s f d k t 0 0,4 0,8 1,2 1,6 BREF 1 0,59 1 0,94 1 1,2 1 1,06 1 1,04 1 0,75 1 1,18 1 0,82 1 0,9 1 1,25 1 0,63 1 0,71 0,53 0,59 0,73 0,86 1,1 1,35 1,02 0,94 0,88 1,12 0,95 1,2 0,85 1,04 0,82 1,06 0,81 1,04 0,83 0,75 1,11 1,18 1,12 1,6 0,96 0,85 0,88 0,82 0,93 0,9 1,13 1,48 0,94 1,25 0,9 1,18 0,73 0,63 0,68 0,71 NCCFr p j l n m Z z s f d k t 0 0,4 0,8 1,2 1,6
Figure 5: spectral reduction ratio for the ESTER and NCCFr corpora compared with BREF for different word classes. first line : function words, second line : content words
ESTER vowels NCCFr vowels ESTER consonants NCCFr consonants
BREF ESTER 1 1,22 1,2 1 1,33 1,65 1 1,25 1,26 1 1,25 1,29 1 1,3 1,19 1 1,25 1,33 1 1,17 1,19 1 1,28 1,34 1 1,28 1,41 1 1,32 1,31
ERROR: dimensionn1 must be positive GSL
1: 1,3 0,99
ERROR: dimensionn1 must be positive GSL
1: 1,18 1,35 1,39
init_source.c:29: matrix integer error handlerinvoked.
parse error
init_source.c:29: matrix integer error handlerinvoked.
parse error i O A I x y u a E e 0 0,4 0,8 1,2 1,6 BREF 1 1,2 1 1,65 1 1,26 1 1,29 1 1,19 1 1,33 1 1,19 1 1,34 1 1,41 1 1,31
dimensionn1 must be positive GSL
1: 1,3
dimensionn1 must be positive GSL
1: 1,18 1,35 NCCfr
init_source.c:29:matrix integer handler invoked.
error
init_source.c:29:matrix integer handler invoked. error i O A I x y u a E e 0 0,4 0,8 1,2 1,6 BREF ESTER 1 1,83 1,55 1 1,2 1,2 1 1,14 1,06 1 1,22 1,3 1 1,11 1,13 1 1,2 1,12 1 1,16 1,09 1 1,54 1,09 1 1,4 1 1 1,21 1,23 1 1,11 1,09 1 1,31 1,19 1,13 1,47
ERROR: dimensionn1 must be positive GSL
1: 1,02 1,2 0,98 0,99
ERROR: dimensionn1 must be positive GSL
ERROR: dimensionn1 must be positive GSL
ERROR: dimensionn1 must be positive GSL
1: 1:
0,9 1,18 1,43 1,56
ERROR: dimensionn1 must be positive GSL
ERROR: dimensionn1 must be positive GSL
1: 2:
ERROR: dimensionn1 must be positive GSL
init_source.c:29: matrix integer error handler invoked.
parse error
init_source.c:29: matrix integer error handler invoked.
init_source.c:29: matrix integer error handler invoked.
init_source.c:29: matrix integer error handler invoked.
parse error parse error
init_source.c:29: matrix integer error handler invoked.
init_source.c:29: matrix integer error handler invoked.
parse error parse error
init_source.c:29: matrix integer error handler invoked.
p j l n m Z z s f d k t 0 0,4 0,8 1,2 1,6 BREF 1 1,55 1 1,2 1 1,06 1 1,3 1 1,13 1 1,12 1 1,09 1 1,09 1 1 1 1,23 1 1,09 1 1,19 1,13
dimensionn1 must be positive GSL
1: 1,02 0,98
dimensionn1 must be positive GSL
dimensionn1 must be positive GSL
dimensionn1 must be positive GSL
1: 1: 0,9 1,43
dimensionn1 must be positive GSL
dimensionn1 must be positive GSL NCCFr init_source.c:29:matrix integer handler invoked. error init_source.c:29:matrix integer handler invoked. init_source.c:29:matrix integer handler invoked. init_source.c:29:matrix integer handler invoked. error error init_source.c:29:matrix integer handler invoked. init_source.c:29:matrix integer handler invoked. p j l n m Z z s f d k t 0 0,4 0,8 1,2 1,6 BREF ESTER 1 1,24 1,32 1 1,22 1,23 1 1,25 1,3 1 1,26 1,4 1 1,21 1,23 1 1,21 1,36 1 1,14 1,29 1 1,24 1,3 1 1,21 1,34 1 1,22 1,27 1,21 1,16 1,16 1,24 1,17 1,21 i O A I x y u a E e 0 0,4 0,8 1,2 1,6 BREF 1 1,32 1 1,23 1 1,3 1 1,4 1 1,23 1 1,36 1 1,29 1 1,3 1 1,34 1 1,27 1,21 1,16 1,17 NCCfr i O A I x y u a E e 0 0,4 0,8 1,2 1,6 BREF ESTER 1 1,74 1,44 1 1,25 1,28 1 1,13 1,1 1 1,17 1,24 1 1,16 1,16 1 1,06 1,09 1 1,16 1,17 1 1,43 0,98 1 1,46 0,94 1 1,19 1,24 1 1,06 1,04 1 1,35 1,07 1,18 1,19 1,14 1,26 0,92 0,94 1,12 1,22 1,18 1,18 1,23 1,03 1,02 1,08 1,31 1,37 p j l n m Z z s f d k t 0 0,4 0,8 1,2 1,6 BREF 1 1,44 1 1,28 1 1,1 1 1,24 1 1,16 1 1,09 1 1,17 1 0,98 1 0,94 1 1,24 1 1,04 1 1,07 1,18 1,14 0,92 1,12 1,18 1,23 1,02 1,31 NCCFr p j l n m Z z s f d k t 0 0,4 0,8 1,2 1,6
Figure 6: spectral variance extension ratio for the ESTER and NCCFr corpora compared with BREF for different word classes. first line : function words, second line : content words
prepared journalistic speech than for casual sponta-neous speech.
We have nevertheless been able to observe a strong spectral space reduction for short segments, quite fre-quent in our spontaneous speech data.
Considering the role of words, we have seen that func-tion words tend to be more subject to spectral reduc-tion than content words. This is also true for the vari-ance extension phenomenon, which is more present on function words.
However interesting these results may seem, they have to be taken with some caution: the features are in-deed extracted at the middle of each phonetic segment, which might lead to false results in some cases, espe-cially when considering consonantal phonemes. Nevertheless, this approach provides a simple way of representing variations occurring between speaking styles, and we plan to carry on further experiments us-ing different features, amongst them prosodic features.
8.
References
Martine Adda-Decker, Philippe Boula de Mareuil, Gilles Adda, and Lori Lamel. 2005. Investigat-ing syllabic structures and their variation in spon-taneous french. Speech Communication, 46(2):119– 139.
M. Adda-Decker, C´edric Gendrot, and No¨el Nguyen. 2008. Contributions du traitement automatique de la parole `a l’´etude des voyelles orales du fran¸cais. Traitement Automatique des Langues, 49.
Petr Fousek, Lori Lamel, and Jean-Luc Gauvain. 2008. Transcribing Broadcast Data Using MLP Features. In InterSpeech’08, pages 1433–1436, Brisbane, Aus-tralia, September 22-26.
Sadaoki Furui. 2003. Recent advances in spontaneous speech recognition and understanding. In ISCA & IEEE workshop on Spontaneous Speech Processing and Recognition (SSPR).
S. Galliano, E. Geoffrois, Guillaume Gravier, J.-F. Bonastre, M. Mostefa, and K. Choukri. 2006. Cor-pus description of the ester evaluation campaign for
the rich transcription of french broadcast news. In Language Evaluation and Ressources Conference. K. Itou, M. Yamamoto, K. Takeda, T. Takezawa,
T. Matsuoka, T. Kobayashi, K. Shikano, and S. Ita-hashi. 1999. Jnas: Japanese speech corpus for large vocabulary continuous speech recognition research. Journal of the acoustical society of Japan, 20(3):199– 206.
L. Lamel, J. L. Gauvain, and M Eskenazi. 1991. Bref, a large vocabulary spoken corpus for french. In Eu-rospeech.
K. Maekawa. 2003. Corpus of spontaneous japanese: its design and evaluation. In ISCA & IEEE work-shop on Spontaneous Speech Processing and Recog-nition (SSPR).
Masanobu Nakamura, Koji Iwano, and Sadaoki Furui. 2008. Differences between acoustic characteristics of spontaneous and read speech and their effects on speech recognition performance. Computer Speech and Language, 22:171–184.
F. Torreira, M. Adda-Decker, and M. Ernestus. in press. The nijmegen corpus of casual french. Speech Communication.
R. J. J. H. van Son and Louis C. W. Pols. 1999. An acoustic description of consonant reduction. Speech Communication, 28(2):125 – 140.