Feature space selection and combination for native language identification
Texte intégral
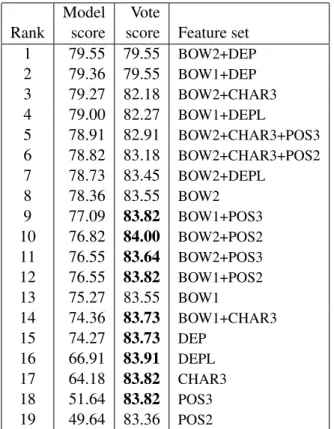
Figure

Documents relatifs
The article is structured in the following manner: in the section 2, we present briefly some basic theoretical aspects concerning the discriminant analysis; in the section 3 we
In order to go from a single brute force GMM per accent without phonetic knowledge to a frame based system or to our classifier using a speaker model, we rely on a phonetic
The numerous simulations (as done for the first example in table 1) have allowed to choose the type of kernel (Gaussian) and to set the values of parameters C and σ (C =
The extraction of numerical data (file number, customer reference, phone number, zip code in an address, ...) in a handwritten document whose
Classification error for a normalized polynomial kernel function with OSH offset correction as function of the degree of the polynomial function without noise and with various types
Now that we have introduced our feature-based context-oriented programming approach, in this sec- tion we present the tool we built to help program- mers visualise and animate
Built upon our previous work employing a Stacked Restricted Boltzmann Machine to predict effective drug combinations from ontology, literature and experimental data [6], we
The proposed work for NLI of 6 languages has used three models such as Multi Layer Perceptron classifier with Analysis of Variance -F value measure, MLP classifier with Chi -
