An Augmented Incomplete Factorization Approach for Computing the Schur Complement in Stochastic Optimization
Texte intégral
Figure



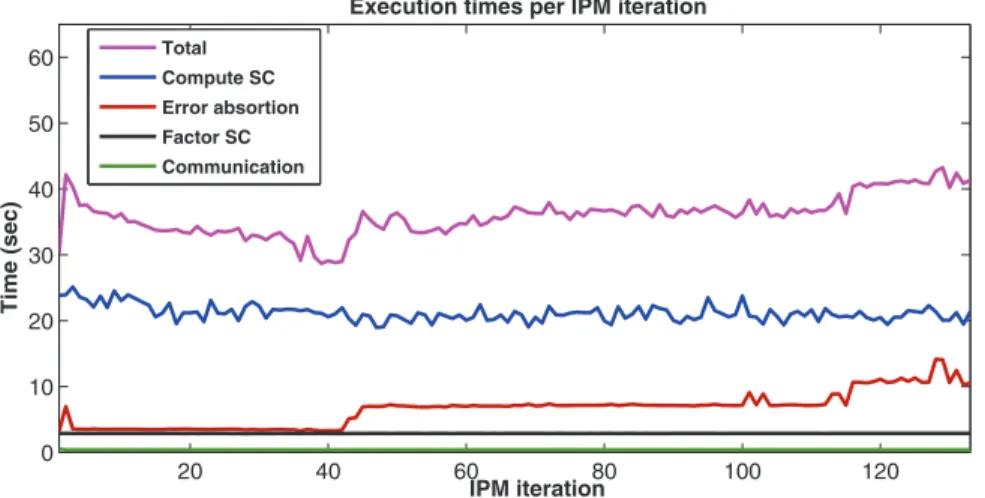


Documents relatifs
We obtain a branched spherical CR structure on the com- plement of the figure eight knot whose holonomy representation was given in [4].. We make explicit some fundamental
Of the four languages, there is only one, Italian, in which the link between the absence of a preposition before the locative complement and the nature of the website
In this study we obtained in vitro data supporting the hypothesis that Ide Ssuis is involved in complement evasion: (i) different recombinant Ide Ssuis constructs abolished
Nous avons mené une étude dans la zone de Niakhar à 150 km au sud-est de Dakar dans le village de Toucar de janvier 1998 à janvier 2000. Les objectifs de cette étude étaient de
Donne le nom de la cellule correspondant à.
We proved for a model problem that truncation of the unbounded computational domain by a Dirichlet boundary conditions at a certain distance away from the domain of interest is
The tools I used to sum is of course the integration on the complex plane and that I used to make the integral nonzero is naturally the Dirac distribution δ(C(z)) to give the
In Chapter 4, we propose an energy efficient user association, power, and flow control optimization algorithm. The algorithm aims at associating UEs to BSs such that: i) the
