Feature selection and classification in genetic programming: application to haptic based biometric data
Texte intégral
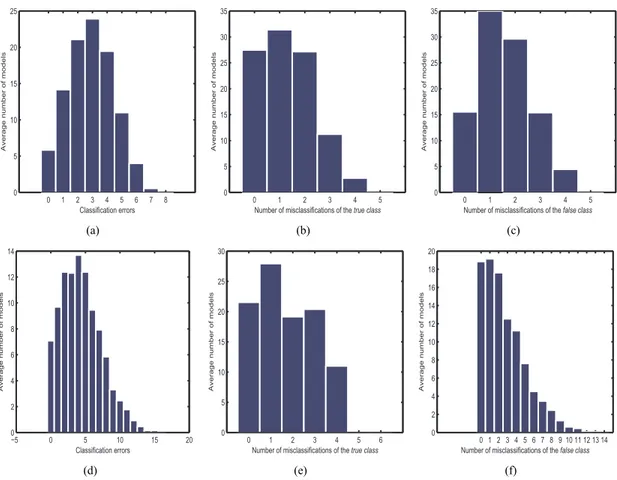
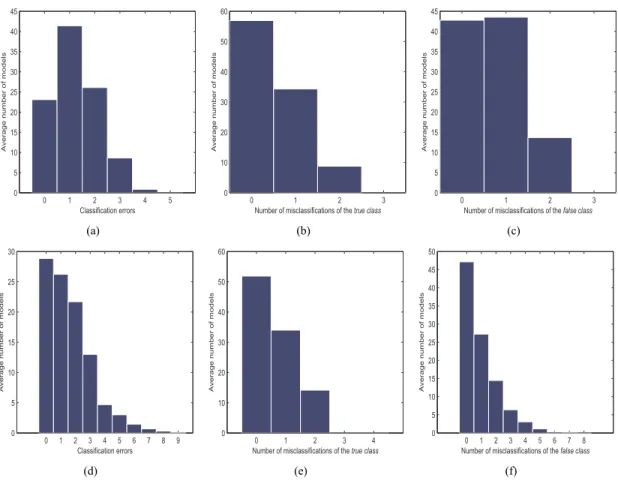
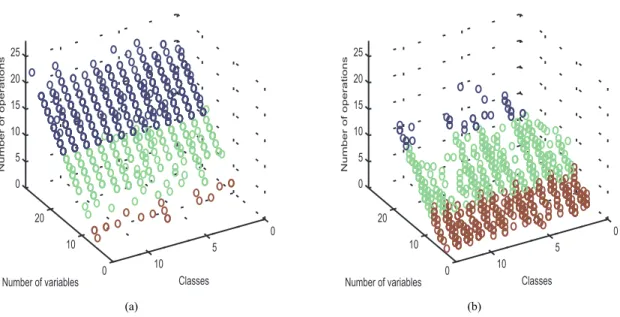
Figure
Documents relatifs
That is, given that for each scenario we are eliminating only one (song, synset) relation, the remaining directly related songs will be present in both sets retrieved when querying
Support Vector Machines (SVMs) are well-established Ma- chine Learning (ML) algorithms. They rely on the fact that i) linear learning can be formalized as a well-posed
We report the performance of (i) a FastText model trained on the training subsed of the data set of 1,000 head- lines, (ii) an EC classification pipeline based on Word2Vec and
This paper presents an approach to the shared task HaSpeeDe within Evalita 2018. We followed a standard machine learning procedure with training, valida- tion, and testing phases.
The features (byte image or n-gram frequency) were used as inputs to the classifier and the output was a set of float values assigned to the nine class nodes.. The node with the
In order to extract our features for the different datasets which are contained in the LOD cloud, we used the data corpus that was crawled by Schmachtenberg et al.. [15] and which
The history of previous algorithm duels is used to select the most promising challenger for the current best candidate algorithm, namely the method that most convincingly
The main contribution of this study is the reduc- tion from the sparse version of Learning Parity with Noise to the GAMETES problem and shows that solving the feature selection
