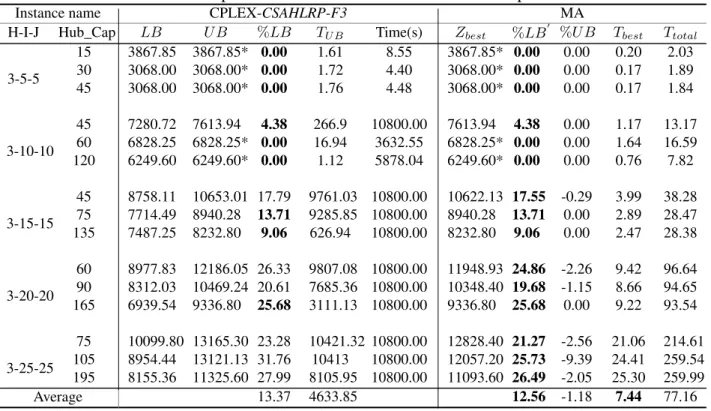
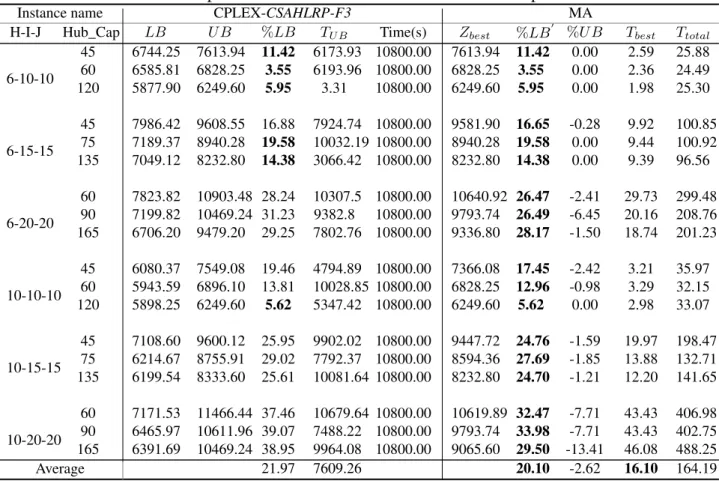
Hub location routing problem for less than truckload shipments of freight transport providers
180
0
0
Texte intégral
Figure
+7
Documents relatifs