Filtering conversations by dialogue act labels for improving corpus-based convergence studies
Texte intégral
Figure


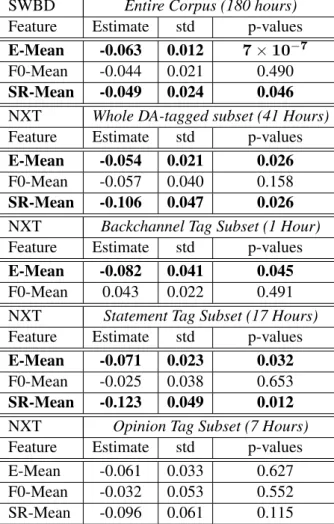
Documents relatifs
The pantograph voltage ( v p ) and current ( i p ) recordings were taken during long test runs in 2008 on the railway lines of four different European traction supply systems
Taking advantage of the availability of other data sets of relevance to the parameter under concern, though different, a method is proposed for the synthesis of the initial
Since the O(1/k) convergence rate of the testing cost, achieved by SG methods with decreasing step sizes (and a single pass through the data), is provably optimal when the
• grdraster reads a file called grdraster.info that describes the format of the file to be converted. • By default, GMT looks for grdraster.info
The proposal is based on query rewriting techniques that given an initial query they can provide sets of queries that can help data scientists to better exploit data collections..
In this Section, we prove our first main theorem, namely we give a counterexample to uniqueness for the anisotropic Calderón problem, at a nonzero frequency, for Riemannian
In particular, we combine the usage of a geotag- ging approach relying on a crowdsourced gazetteer containing toponyms related to the specific domain, with semantic searches on
With those three bridging functions, we hope to see similarities and properties that allow us to establish a more general method of reasoning with arithmetic, sets, cardinalities
