APOT: Atomic Path Optimizing for Traits
by Thomas Lin
Submitted to the Department of Electrical Engineering and Computer Science in Partial Fulfillment of the Requirements for the Degree of
Master of Engineering in Electrical Engineering and Computer Science at the
Massachusetts Institute of Technology May 20, 2004 L
-Copyright 2004 Thomas Lin. All rights reserved.
The author hereby grants to MIT permission to reproduce and distribute publicly paper and electronic copies of this thesis and to grant others the right to do so.
4 ASSACHUSETS INST E OF TECHNOLOGY
JUL
2
52004
LIBRARIES
AuthorAh Department of Electrical Engineering and Computer Science May 20, 2004 Certified by______________ i bHarold Abelson Thesis Supervisor Certified by_ IPick K.P. Yue Thesis Supervisor Accepted by Arthur C. Smith Chairman, Department Committee on Graduate Theses
APOT: Atomic Path Optimizing for Traits
by Thomas Lin Submitted to the
Department of Electrical Engineering and Computer Science May 20, 2004
In Partial Fulfillment of the Requirements for the Degree of Master of Engineering in Electrical Engineering and Computer Science
Abstract
This thesis considers the design of automated tutoring systems that customize teaching material to accommodate individual student learning styles. In particular, we consider the
following problem: Begin with one or more presentations of a subject, and break them into
fragments
("atoms') each expressing a single idea. Given information about an individual student's learning style, how can one select the optimal choice and sequence of atoms ("path of atoms") to create the most effective presentation for that student? We have implemented several algorithms that automatically create such paths, and we investigate the tradeoff between number of constraints imposed by the algorithms and the number of paths they can find. We have tested one of these algorithms ("partitionsearch") in an experiment where student volunteers in computer science studied material about planning and artificial intelligence. The results of the experiment indicate that the algorithms can produce presentations that are effectively tailored to the different learning styles.
Thesis Supervisor: Harold Abelson
Title: Class of 1922 Professor of Electrical Engineering and Computer Science at MIT Thesis Supervisor: Dick K.P. Yue
Acknowledgments
I would like to thank Becky and my family for supporting me through this project. I would like to thank Professor Yue and Professor Abelson for their invaluable guidance and their financial support.
Table of Contents
A BSTR A C T ... 3
A C K N O W LED G M EN TS... 4
TA BLE O F C O N TEN TS ... 5
LIST O F FIG U R ES... 7
A BBR EV IA TIO N S A N D TER M S... 8
C IN TR O D U C TIO N ... 10
1.1 TEACHING M ORE EFFECTIVELY W ITH COMPUTERS... 10
1.2 EXPRESSING O NE A SPECT OF THE TEACHING PROBLEM ... 11
1.3 A LGORITHM S FOR THE PATH-OPTIM IZATION PROBLEM ... 11
1.4 SCENARIO SHOW ING OUR IMPLEM ENTATION ... 12
1.5 O VERVIEW OF O UR EXPERIMENT ... 14
2 BA C K G R O U N D LITERA TU R E... 15
2.1 INTELLIGENT TUTORING SYSTEM S ... 15
2.2 LEARNING STYLES RESEARCH... 16
2.3 A TOM IZATION ... 18
2.4 TRADITIONAL COURSE SEQUENCING... 19
2.5 CUSTOM IZATION SYSTEM S ... 20
2.6 H YBRID SYSTEM S... 21
2.7 IMPORTANCE OF CUSTOMIZING FOR CHARACTERISTICS IN RICH DOMAINS... 22
2.8 O PEN Q UESTIONS ... 22
3 A STUD Y O F TH E PR O BLEM ... 24
3.1 THE PROBLEM ... 24
3.2 CONSTRAINTS VERSUS POSSIBLE PATHS... 25
3.3 EXTREM ES... 26
3.4 W ALKSAT-STYLE... 27
3.5 BEAM SEARCH... 28
3.6 PARTITION/SEARCH ... 29
3.7 BEAM -PARTITION HYBRID ... 32
3.8 COLLABORATIVE FILTERING ... 33
3.9 DEVELOPING THEORY ... 34
3.10 SUM M ARY CHART ... 34
4 IM PLEM EN TA TIO N... 36
4.1 O BJECTIVES... 36
4.2 DOMAIN CHOICE ... 37
4.3 A TOMIZATION D ESIGN CHOICES ... 38
4.3.1 Atom Sizes... 38
4.3.2 Atom ID s... 40
4.3.3 Am ount of M aterial... .. 40
4.3.4 Algorithm s Usedfor Atom ization... 40
4.3.5 Atom ization Results... 41
4.5.2 D istance Calculations... 48
4.5.3 Creating the Postatom Table ... 49
4.5.4 W eb Implem entation... 51
4.5.5 Beam Search Results... 51
4.6 IM PLEM ENTATION OF PARTITION/SEARCH... 52
4.6.1 Partition/Search Algorithm ... 52 5 EX PER IM EN T ... 54 5.1 O BJECTIVES... 54 5.2 H YPOTHESES ... 54 5.3 PROCEDURES... 55 5.4 RESULTS... 57 6 D ISC U SSIO N ... 65
6.1 D ATA ANALYSIS AND FATE OF H YPOTHESES ... 65
6.1.1 Learning Styles versus Learning Preferences... 67
6.2 COM PARISON TO O THER RESEARCHERS' FINDINGS ... 68
6.3 LESSONS ABOUT THE N ATURE OF THE QUESTION ... 68
6.4 LESSONS ABOUT THE ANSW ER TO THE QUESTION ... 68
6.5 A SSUM PTIONS M ADE... 68
6.6 N OTES FOR FUTURE RESEARCHERS ON THIS TOPIC ... 69
7 CO N C LU SIO N ... 70
7.1 STATEM ENT OF W ORK D ONE... 70
7.2 CONTRIBUTIONS ... 70
7.3 FUTURE W ORK ... 71
7.3.1 Improving the System ... 71
7.3.2 Applying the Principles to Tangential Areas ... 73
7.4 CONCLUSION ... 74
8 BIBLIO G R APH Y ... 77
A ATO M S ... 79
A .1 TABLE OF A TOM S AND D ESCRIPTIONS... 79
A.2 CHART USED TO RATE LEARNING STYLE FITS FOR ATOMS... 82
B D A TA ... 83
B .1 LEARNING STYLES D ATA ... 83
List of Figures
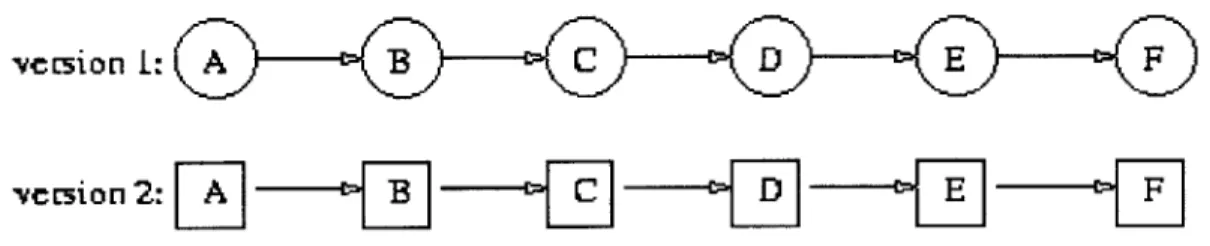
Figure 1. A Sample Atom ... 12
Figure 2. A History of Intelligent Tutoring Systems ... 15
Figure 3. Description of Four Learning Styles ... 17
Figure 4. Atomization Can Be Done at Different Levels... 18
Figure 5. Atomization Example... 19
Figure 6. Student Characteristics M odel... 20
Figure 7. Customization System Example... 21
Figure 8. Hybrid Systems Example ... 21
Figure 9. W hich Path Through the M aterial is M ost Effective?... 24
Figure 10. Graph of Constraints versus Possible Paths for Algorithms... 26
Figure 11. Beam Search Only Considers a Set Number of Atoms Per Level... 28
Figure 12. M aking Large Prerequisite Graphs Level by Level... 30
Figure 13. Partition/Search Divides the Atoms into Groups... 31
Figure 14. Path-Finding Algorithms Summary Chart... 35
Figure 15. Overall Implementation Steps... 36
Figure 16. How W e Atomized and Labeled Atoms... 39
Figure 17. Larger Concepts Graph ... 42
Figure 18. Actual Prerequisite Graph for Partition/Search on the Topic of "Planning" ... 43
Figure 19. Zoomed-In Prerequisites Graph ... 44
Figure 20. Atoms W ithout Ordering Constraints... 44
Figure 21. Atom Arrangement W here Any Path W ill W ork ... 45
Figure 22. Learning Preferences Chooser... 46
Figure 23. Learning Styles Assessment... 47
Figure 24. Distances Table ... 49
Figure 25. W ebsite Diagram ... 50
Figure 26. Chart of Hypotheses for Experiment... 54
Figure 27. Experiment M ain Page ... ... 55
Figure 28. Flow of Experiment from Test Subjects' View... 56
Figure 29. Questions Independent of Curriculum Type ... 58
Figure 30. Single Question Statistics Part 1 ... 59
Figure 31. Single Question Statistics Part 2 ... 60
Figure 32. Paired Statistics Part 1... 61
Figure 33. Paired Statistics Part 2... 62
Figure 34. Bar Graph of Results for "M aterial W as Interesting"... 65
Figure 35. Bar Graph of Results for "M aterial W as Easy to Understand"... 66
Abbreviations and Terms
MIT Classes 6.034 ... 6.825 ... 6.834 ... Terms Atom ... Atom ization ... Custom Curriculum ... Larger Concept ... Number of Constraints ... N um ber of Paths ... Path of Atom s ... Postatom s ...Artificial Intelligence (Undergraduate Introduction) Techniques of Artificial Intelligence
Embedded Artificial Intelligence
A fragment of course material (e.g., two paragraphs). The process of creating atoms.
A course curriculum that is custom made to fit the attributes of a student.
A complete idea that can take several atoms to convey. Number of constraints imposed on possible paths of atoms by an algorithm.
Number of distinct possible paths an algorithm can find. A sequence of atoms put together to form a reading passage.
A list of atoms that can come after each particular atom in Beam Search.
Student Model ... The information on student characteristics and/or knowledge level that an ITS stores for each student. Learning Styles Terms
Activist ... Likes going out and doing things. Reflector ... Likes to reflect on things.
Theorist ... Likes concrete proofs.
Pragmatist ... Likes planning what to do next. General Abbreviations Al ... AIM A ... CGI ... ITS ... KR ... PERL ... POP ... Artificial Intelligence
Artificial Intelligence: a Modem Approach (textbook) Common Gateway Interface, used for web programming Intelligent Tutoring System
Knowledge Representation
A computer programming language. The Partial-Order Planning algorithm Intelligent Tutoring Systems Abbreviations
APOT ... Atomic Path Optimizing for Traits -a hybrid system AST ... Adaptive Statistics Tutor -a hybrid system
CoCoA ... Concept-based Courseware Analysis -a course verifier DCG ... Dynamic Course Generation -a traditional system ELM-ART ... ELM Adaptive Remote Tutor -a traditional system ID ... Interactive Documents -a hybrid system
Java Tutorial ... A customization system Variables b ... C ... d ... 1 ... m ... n ... y ...
Average branching factor for each graph hierarchy level Cohesion of a path, in terms of prerequisites and flow Average characteristics distance of a path of atoms Length of path of atoms
Number of atoms an expert can remember at one time Total number of atoms being used
Levels in the atom graph hierarchy Algorithms
Beam Search ... Involves assigning postatoms for each atom and finding paths where atoms can only be followed by their postatoms. Partition/Search ... Involves partitioning the set of atoms, creating a
1
Introduction
1.1 Teaching More Effectively with Computers
When MIT students go to class, they all get the same lecture. Live teaching is optimized toward each class's average in learning style, level, and interest. Years ago, this method worked well because the MIT student body was fairly uniform. However, there is much more diversity found in MIT's student body today. Admitted students come from diverse backgrounds and have more widely varying interests and learning styles.
For this reason, lecturing to the mean will now neglect the learning styles and interests of more students. Felder and Silverman [14] found that learning styles of most
engineering students are in many ways incompatible with the current lecturing styles of most engineering professors.
One way to try to address the individualization problem is by offering small recitation sections. However, there are still 10 to 30 students per recitation. Also, recitation instructors are often less knowledgeable than the lecturers.
The solution to this problem could be a web-based course sequencing computer system that gives high weight to individual student characteristics. (Course sequencing is the idea of reordering and selectively presenting course material). A perfect such system would be analogous to having the lecturer present material to each individual student that customizes not only for the knowledge level of the student, but also the student's
background, learning interests, and learning styles.
Good teachers employ several methods to be effective, and presenting the
material that is most natural for individual students is one of them. A teacher can take as input many books ofa curriculum and a student's learning style and naturally output a curriculum well-suited for a particular student.
We seek to reproduce this form of intelligence algorithmically. As input, the program takes many books of a curriculum and a student's learning style. The curriculum is then broken down into atomic fragments, each of which expresses a single idea. The program's goal is to put together an optimal curriculumfor each particular student from these atomic fragments.
It makes sense that people can learn better from some books than others. A student who learns best from examples might learn better from a book that emphasizes examples rather than theory. Also, receiving reading material from different sources is not new to today's students. Students are routinely asked to read different sections from different books to learn a topic.
This research differs from past research because (1) it integrates curricula from different textbooks, and (2) it can thus create curricula that aim to customize for learning styles. Most existing systems customize only for knowledge levels. This research
contributes not only toward the Intelligent Tutoring Systems field, but also toward our understanding of learning, teaching, and academic material knowledge representation.
1.2 Expressing One Aspect of The Teaching Problem
The larger question is to explore how we can teach more effectively with computers. We have already mentioned how part of this can be seen as mapping
curriculum fragments and learning styles to customized curricula. Let us further specify the problem we are addressing as the following: Begin with one or more presentations of a subject, and break them into
fragments
("atoms') each expressing a single idea. Given information about an individual student's learning style, how can one select the optimal choice and sequence of atoms ("path of atoms") to create the most effective presentation for that student? We will call this the Atomic Path Optimization problem because itinvolves finding an optimal paths of atoms.
When looking for the right algorithm, we notice that we are looking for the right tradeoff between the number of possible paths an algorithm can find and the number of constraints imposed by the algorithm. On the one hand we want an algorithm that can consider all possible paths and find the best path for each student, but on the other hand we realize that this would be computationally infeasible. There are infinite possible paths if we do not restrict path length, an exponential number of paths if we do, and still a factorial number of paths if we insist that no curriculum presents the same atom twice.
1.3 Algorithms for the Path-Optimization Problem
paper, we will study the path optimization problem and discuss various strategies for approaching it. We discuss the random path strategy, the one-path-fits-all strategy, the WalkSAT strategy, the Beam Search strategy, the Partition/Search strategy, the Beam-Partition Hybrid strategy, the Collaborative Filtering strategy, and several other strategies.
1.4 Scenario Showing Our Implementation
After the discussion of the strategies, we conduct a study to try to learn more about the problem. The first part of the study is to implement the Beam Search algorithm and the Partition/Search algorithm to learn about the details involved. This section (1.4) briefly describes the specific scenario we addressed, and shows of what our implemented Beam Search and Partition/Search programs are capable.
We started with five textbook chapters (150 pages) of material on the topic of Al Planning: Chapters 11 ("Planning"), 12 ("Practical Planning") and 13 ("Planning and Acting") of Russell and Norvig's Artificial Intelligence: A Modern Approach, Chapter 15
("Planning") of Winston's Artificial Intelligence, and Chapter 13 ("Planning") of Rich and Knight's Artificial Intelligence.
BASIC REPRESENTATIONS FOR PLANNING
legn ai mmSie assa. inioossie = 1551mte lS pegn lends omis itoefliem plamnn algorithms. while mninng much of the expessiveess d n bs... calculus reenaions.
fonmdr ANN enoad tomb
Ihe Sims Iaips owns me represetd by comjuim of fmsdium-fieamend Iftersls. that is. sensoncaes applied so onsr symbs. possibly seiaed For exads. temin stsate for the milk-asd-baans problem might be described as
Ai(Hoiim) A -Hie(Milk) A -Aieeeiasenal) A ,Hae(Drilh A
As we mentionedemliea sar description does ensend to be coee. An inooqdm ag
desrinen s uch as m nebe obtaeindby as ig upoen in sanneseile anlenvi .ut or"ePeeds
so. ain dfpossible cenlem mano fortwhichbthe aenoud like toieben a sucessefud PIN.
M~any daseas system instad adopt te consmssmo-aalogsus en the "nellasn en fail=-eneaion med r i logic pegmmWg--ba if e eate description does not uenon a givn
posionvelimed then de limeda can be sssumed to bn falme
Goalsmeaso described by conjunctions of literads. For example. the shoppins goal ight
be represeenedas
Ai(liene) A Ha(Mildk) A H eW(itxas) A Haoe(Desll
Gols cn also contain variables. For exampe. the goal of beinga a sme tht sells milk would
be sepresened a;
Ai) A S1els(xMi&)
As itel gols livnmt tmm prMless. Ase smssbles me ussemel tobe existentialy qsasmile Howeverome musm dstinguis cearly bmnen a gal given t plamer d a gen ta
thsbot epsro M enr s fe nitu al squesnd go ls messed asin s g laniag syatam. illis quiteoonI~ fore soni psoess itself so mientain only seyboit speesuatiml of ates. Because men actilas obhnge ody small pan of As am he repreentaio. is me
elcient to keep truck of she clages We will see how this is done shotly.
I seseaanpmeeeos l-segiltaswhium5ashM-dise.On
Figure 1. A Sample Atom
Aiming to get atoms that each express a single idea, we designated small sections as atoms, diagrams as atoms, and broke larger sections into several atoms, each about the length of a small section. This division resulted in 150 atoms. Figure 1 shows a sample
atom that introduces the STRIPs language. After deciding how to divide the atoms, we scanned the 150 pages of material and used photo-editing software to divide and connect different pages so that we would end up with each atom as an individual image file. Next, we chose four learning style scales ("Activist," "Reflector," "Theorist," and
"Pragmatist"), and rated each of our 150 atoms as Low, Medium, or High on each of the four scales.
With that setup complete, we focused on developing algorithms that could map student learning styles to optimal curricula. The first such algorithm we implemented was a Beam-Search style algorithm. To set up Beam Search, we had an expert choose 5 atoms that could be plausibly presented after each atom. We chose a path length of 20 atoms, and also specified a few starting atoms. A valid Beam Search path is any path of 20 atoms where every atom following a given atom was one of the 5 atoms chosen by the
expert for that atom. There are 520 such paths.
A student using the Beam Search program is first given two learning style assessments, each of which rates the student as Low, Medium or High on the Activist, Reflector, Theorist, Pragmatist scales, to create a student model. Then, Beam Search uses the following method to return a valid Beam Search path that is a good fit for the student model:
1. Choose the starting atom that best matches the student model (by using a distance formula between the atoms' classifications and the student model).
2. Look at the 5 atoms that could come after the current atom, and pick the one that best matches the student.
3. Repeat step two until the path length reaches 20 atoms. Once a path is found, the program displays the 20 chosen atom images on the screen for the student to read.
The second algorithm we implemented was Partition/Search. Partition/Search works by creating a directed graph over all the atoms (with each atom as a node). The graph procedure takes O(n x log(n)) expert time (n = number of atoms) to set up, and is described in further detail later in this thesis. Partition/Search returns the path within its directed graph that has the smallest average atom distance from the student model.
whose atoms were as close to the student model as possible. For example, if there were only two possible Partition/Search paths (in our implementation there are actually over 20,000 possible paths), and they were the same except path A had an Activist=Low, Reflector-Medium, Theorist=Low, Pragmatist=High atom where path B had an Activist=High, Reflector=Low, Theorist=High, Pragmatist=Medium atom, then the program would choose and display path A because it is a better match.
The result is that we now have programs to generate curricula that are customized for individual students' learning styles.
1.5 Overview of Our Experiment
Having devised several atomic path optimization algorithms and implemented two of them, we decided to run an experiment to see if/how customizing for learning
styles actually improves the effectiveness of teaching. Our main hypothesis was that Partition/Search customizing for student learning styles could provide advantages for
students looking to learn Planning. We also had several secondary hypotheses concerning exactly what the advantages were.
For the experiment, we implemented a "worst fit" version of Partition/Search. The worst fit version returns the curriculum path that lies in the prerequisite graph but has the furthest average atom distance from the student model.
We recruited 18 student test subjects by emailing the MIT Electrical Engineering and Computer Science mailing list. Each subject received a 30 minute best fit
Partition/Search reading and a 30 minute worst fit Partition/Search reading. The subjects filled out questionnaires about their impressions of each curriculum and also took short quizzes on the learning material.
Our data showed that the best fit curricula was more effective than the worst fit curricula in many ways. For example, we have statistically significant results showing that students thought the best fit curricula was easier to understand and more interesting, engaging, rewarding and meaningful. The results show that customizing for learning styles does make a difference in Intelligent Tutoring Systems teaching. So, the Atomic Path Optimization problem is indeed worth considering, and the work done here sheds some light on how the problem can be approached and might eventually be solved.
2
Background Literature
The idea of course sequencing is not new. Traditional course sequencing systems like DCG/CoCoA (Dynamic Course Generation / Concept-based Courseware Analysis) [6,10,15] and ELM-ART (ELM Adaptive Remote Tutor) [9] work by breaking course curricula into material on individual concepts, then customizing for student knowledge levels by giving students only the concepts they need to go from what they know to what they want to know.
There are also customization-oriented systems like Java Tutorial [24] which develop several versions of the curriculum, test for student learning styles, then give students the version of the curriculum that best fits their learning style.
Hybrid systems like AST (Adaptive Statistics Tutor) [22, 23] and ID (Interactive Documents) [8] perform traditional course sequencing first, then for each concept, decide which version (of the concept) to teach based on student learning styles.
The system we explore combines sequencing with customization, but in a different way than existing hybrid systems. The system expands upon some dynamic delivery ideas explored by Niewiadomska [I].
2.1 Intelligent Tutoring Systems
Most Intelligent Tutoring Systems (ITS) produce customized curricula for students. The idea of customized curricula is fairly intuitive: a human tutor presents different material to different students, so a computer system should be able to do so as well.
1960 1970 1980 1990 200
1960's: The earliest 197os-1 980's: Many 1990-2000's: ITS
adaptive response ITS developed. that focus more on
systems. Internet and
multimedia
1973: Basic outline 1983: First A rtificial
ITS rquirements Intelligence in
ITS have been around in some form or another for almost forty years, as shown in Figure 2. The majority of ITS have focused on how to accurately diagnose the knowledge level of the students as they learn and how to present the material most suitable for that knowledge level. ITS is also of particular interest to the distance learning community, because distance learners do not have regular access to teaching faculty. With the increasing popularity of the internet, some recent ITS research has focused on how the idea of ITS can interact with the online environment. As computer processing power has increased, people have also worked on creating animated ITS teachers to make students feel more comfortable.
The ITS topic we explore in this paper addresses a recent problem: more and more course material is available digitally. For many topics, there is much more material
available online than students have time to read. Some topics are taught in multiple subjects and students end up learning the same thing multiple times. There is a need for a system that can reduce all this material to a single curriculum that is best suited for each particular student.
2.2 Learning Styles Research
"Learning Styles" has been an active field of study in educational research. Honey and Mumford [25] describe learning as a repeating cycle of experiencing, reviewing, concluding, and planning. Many people develop a preference for one or two of these stages. The four learning styles, each corresponding to preference for a particular stage, are: Activists, Reflectors, Theorists, and Pragmatists.
* Activists get excited about new concepts, but can lose this enthusiasm quickly. They learn well when faced with challenges and competition.
* Reflectors like to spend time reflecting before making decisions. They learn better when they are able to reflect on the learning material beforehand.
* Theorists try to fit their observations into consistent models. They learn best when asked to make sense out of complicated ideas and problems.
* Pragmatists like to test out potential solutions right away. They prefer learning that has practical benefits, or learning where the potential applications are clear. [1]
Individual students will identify at some level with each of the four learning styles, and this forms the basis for their "learning style" classification. For instance, a learning style classification (on a ten-point scale) might be "Activist: 8, Reflector: 6, Theorist: 2, Pragmatist: 4." Learning style questionnaires exist for rating people on these four scales.
With learning styles come learning preferences. For example, most reflectors learn best from material that they have to think about and reflect on. Educational research has shown that in some cases, presenting customized material will help the student learn better. Refer to Figure 3 for a summary of the Activist, Reflector, Theorist, Pragmatist learning styles and preferences.
learning style description kind of material preferred
Activist Likes active participation, challenges and Examples and sample problems that
competition. encourage participation.
Reflector Like to spend time reflecting. Detailed descriptions of deep ideas that
encourage reflection.
Theorist Like to fit their observations to models. Complex, proof-style, precise material.
Pragmatist Likes learning when it provides practical Material that clearly relates to real-world
benefits. applications.
Figure 3. Description of Four Learning Styles
One caveat is that some students can switch learning styles depending on course constraints. However, many students might have difficulty switching learning styles, and even if they are able to, they might not be as comfortable with the style that they do not naturally use.
Another caveat is that instead of focusing on the styles the student is strong in, it may be useful to try training the student to become stronger in the other learning areas. However, this may be a difficult task for students who have already finished many years of schooling and are in college.
In addition, there have been other proposed learning styles classifications. Marton and SaIjo in Sweden have proposed a single learning styles scale that ranges from "deep learning" to "surface learning." Kolb [3] did studies where the student is assessed on "active vs. reflective" and "concrete vs. abstract" learning preferences. Kolb only has 2 scales compared to Honey-Mumford's 4 scales, so his final learning classifications contain less information. Similarities and differences between various scales are discussed in greater depth in a study by Cymeon [28]. We chose to use the
Honey-Mumford scale because a previous study by Niewiadomska used this scale, but the other learning style scales would have been equally valid choices.
2.3 Atomization
Atomization is the idea of breaking a course curriculum into individual pieces ("atoms"). These pieces can be sections, paragraphs, sentences, or other types of fragments. The idea of atomization was briefly covered in Niewiadomska [1]. While other intelligent tutoring systems have had to use some basic unit, most papers have not discussed in depth how they came to choose the particular units that they did.
~ .,...~..
= . *. ~ -. ~ .F
S.~-..---.-... - V. p~'s... ~
4FSF...~.
original material chapter by chapter Idea by Idea sentence by sentence Figure 4. Atomization Can Be Done at Different Levels
Atomization can be done at many levels. For instance, you could specify that every chapter was a single atom, and break the material down that way. Or, you could let every small independent idea be an atom. A finer grain like setting every sentence as an atom would give you many atoms but it would become harder later to meaningfully reassemble the atoms into a coherent curriculum. Figure 4 shows several levels that atomization could be done at. No "best" atom size has been established yet. Setting each idea as an atom works best for many applications, but even within this atom-size choice
there are finer classifications. Ideas come in many sizes, and it is not obvious what size of idea makes for the best atoms.
Course curriculum atomization and the problem of how to best reassemble the atoms has parallels to the "atomization" done in fields like nanotechnology. With course
atomization we have to decide what size atoms we should use and how we can better de-contextualize the atoms so that they can still fit together when combined with atoms from
other sources.
2.4 Traditional Course Sequencing
The course sequencing idea has been around for over 10 years. "Traditional course sequencing" systems work by atomization and overlaying knowledge models.
B A B C D
B
D
F
Figure 5. Atomization Example
In traditional course sequencing systems, the atoms are organized into a graph based on prerequisites and effects. In Figure 5, A is a prerequisite for B. B is a
prerequisite for C and E. This can be represented by a directed graph with arrows coming from prerequisites.
Two knowledge models are then used for each student: the first is for what knowledge the student already has, and the second is for what knowledge the student desires. For instance, Alice might know A and E, while desiring knowledge about C. Bob might know nothing beforehand, and desire knowledge about D.
The course sequencing system runs by finding a path through the material that connects what the student knows with what the student would like to know. So, Alice's path would be A-*B-*C, while Bob's path might be A-B-+C-+D.
DCG/CoCoA and ELM-ART are examples of traditional course sequencing systems. DCG forms a model of a student's current knowledge and desired knowledge,
and constructs a path. If it finds that the student is doing poorly, it generates a new path through the material that avoids the more difficult material.
One weakness of traditional course sequencing systems is that they do not
customize for student backgrounds and learning styles. Two students with vastly different backgrounds and learning styles would get the same path through the material as long as they had the same initial knowledge and same final desired knowledge.
2.5 Customization Systems
"Customization systems," on the other hand, give different learning materials to students with different backgrounds and learning styles.
Instead of "previous knowledge," the customization system's student model stores information like the student's background, interests, time allocated, and learning style (see Figure 6).
Student model categories
math / science background major / pedagogical information abstraction and other capabilities
interests and learning goals time allocated
learning style motivation / affective state Figure 6. Student Characteristics Model
A customization system also has several full sets of curriculum, as shown in Figure 7. The different sets of curriculum might be specially designed to suit different backgrounds or different learning styles.
When a new student enters the system, the student takes a psychology test to build the student characteristics model (of items described in Figure 6). Then, the student is
assigned to the stored version of the course that best matches his or her particular student model.
version .: A B
-version 2:
Figure 7. Customization System Example
Java Tutorial [24] is an example of a customization system. Java Tutorial is a system developed in Japan for teaching Java programming.
While customization systems offer the advantage of customizing towards a student's background and learning style, they also have disadvantages. These systems are expensive to set up, as even just two custom versions of the curriculum can take a long time to develop. Also, these systems will teach a student the full curriculum (A through F) even if the student just needed to learn one particular atom of information (e.g., D).
2.6 Hybrid Systems
There are existing hybrid systems that combine the traditional course sequencing approach and the customization approach in order to customize for both knowledge levels and user characteristics.
A B C -
D
E F
®EI
Figure 8. Hybrid Systems Example
If we have the two sets of curricula as shown in Figure 7, we do not necessarily have to present the full sets of the curricula to the student in order. We could run the traditional course sequencing first, and then the customization system part after a path is
determined. As shown in Figure 8, path planning would be done first, then if the path goes through E, the system would choose the version of E that fits better.
For instance, let's say that Alice knows A and E, while desiring knowledge about C. Meanwhile Alice's learning style best matches the learning style catered to in version 2 of the curriculum. The way the default hybrid system works would be to first run a
traditional course sequencing system to find the A- B-+C path for Alice. Then, it would run the customization system and realize Alice is closest to curriculum 2. It would then give Alice the A-*B-+C material from curriculum 2.
AST and ID are hybrid systems. AST's learner model is based on the user's background, preferences, and goals. Constant testing keeps the system aware of the user's knowledge level, so that AST can dynamically re-plan the traditional sequencing based on how well the student is learning.
At first glance, this approach combines the best of both worlds. Alice is only presented with what she needs to know (A->B-+C), and she is presented with material that suits her learning style (curriculum 2). However, instructors often do not have several good sets of curricula which cater to different backgrounds while covering identical concepts. Also, writing such custom curricula is very difficult [26].
2.7 Importance of Customizing for Characteristics in Rich Domains
Niewiadomska [1] explored the idea of how to dynamically deliver course material for the rich domain of fluid dynamics. "Rich domain" refers to domains where there are many ways to solve particular problems. She found that students' academic performance and class satisfaction is dependent on learning styles, and that giving different lectures is necessary for evaluating students most accurately.
2.8 Open Questions
In rich domains, there are often several possible correct ways to learn something. If we collect two textbooks in a rich subject, both of which teach D (see D from Figure
5), we are more likely to find A-+B--+C-+D in one textbook and A-+B-+E-+F--D in the other textbook, than A-+B-+C-+D taught with different styles in the two textbooks.
This scenario also arises when we only have one textbook which includes both paths, but the textbook covers more material than there is time to cover during the course. Plus, in the future as more and more courses (some of which teach overlapping concepts) are uploaded, there are sure to be multiple atomically different online paths for teaching the same concepts.
When faced with a setting like this, the hybrid system can provide no benefit over the traditional approach because it does not have multiple sets of atomically similar curricula to use. Existing systems have avoided this problem by staying with one book of material and using just traditional course sequencing, or by taking the extra effort to come up with extra sets of material.
If we want to take advantage of both knowledge sequencing and customization (in order to attain the best student performance and class satisfaction) without having to write substantial amounts of new educational material, then we need to look into developing a new system.
3
A Study of the Problem
3.1 The Problem
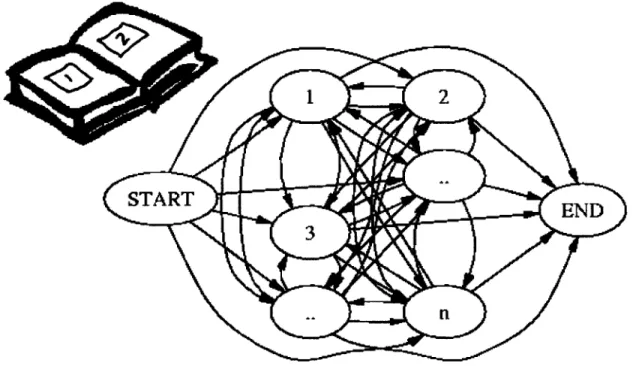
Before we go on, let's re-examine the question. The large AI/Computer Science question is: (Can/how can) computers help (us teach/students learn) more effectively? We can state one aspect of this larger question as the following problem: Given n atoms, from which of the n! paths through the atoms can the student learn the best (taking into consideration how much she learns, how long it takes, how easy it is for them to learn, etc.) ?
1 2
STARTEN
3
Figure 9. Which Path Through the Material is Most Effective?
Figure 9 illustrates this idea. We have books where the source atoms come from. After extracting the atoms, they get put into a graph. If there are no restrictions on which path to choose, then we end up with more paths through the material than a program would have the time to examine. So, we need a good algorithm for finding paths through this graph.
Now, let's consider some issues in choosing and designing an algorithm. For example, do we want an algorithm that could possibly output a chapter atom by atom
optimal path we could construct. Some algorithm choices (e.g., "random path" and possibly "beam search") will be able to output this kind of path, while other algorithms
(e.g., "partition/search") may impose constraints that prevent this kind of path from being chosen.
Let us define a metric of path cohesion (hereafter "c") in terms of prerequisite satisfaction from 0 (low) to 1 (high). If we take a textbook and randomly generate a path, then c will be low and the student is more likely to get confused. We can approximate c by surveying people who have looked at (or tried to learn) from a path. Similarly, we define characteristics-match-distance (hereafter "d") for how well the path of atoms matches the student's characteristics (like learning style). A random curriculum should have a lower d value for a student than a curriculum that is custom-generated to match the student's characteristics.
For each student, there will exist a single optimal path (or a few equally-optimal paths) through the atoms that best fits her characteristics. If we are able to consistently
find the best path(s), then we could learn some interesting things. For example, will we notice that student A's best path requires fewer atoms than student B's best path? If so, would this mean that student A can learn just as well when presented with less material than student B? This would be an interesting result.
3.2 Constraints versus Possible Paths
The optimal strategy for our problem will involve adding constraints to what the path can be. Constraints (e.g., "paths must lie on a directed prerequisites graph" or "paths
cannot be longer than 40 atoms") are imposed by the algorithms to reduce the total number of paths being considered from a computationally infeasible number to a more manageable number. The optimal strategy will also involve many possible choices for what the path can be, because different paths work best for different students.
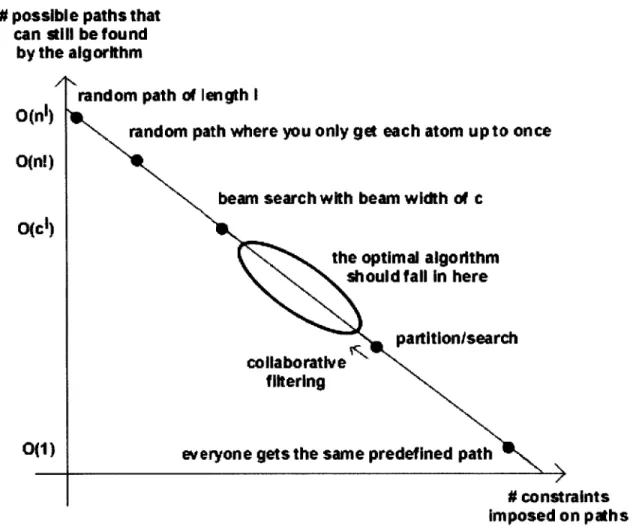
Figure 10 shows a graph where the x-axis is "# of constraints" and the y-axis is "#
of possible paths." All possible strategies for solving our problem lie somewhere along this graph. We want to find the optimal strategy, and where it lies on the graph.
# possible paths that can still be found by the algorithm
/11-random path of length I 0(n1)
random path where you only get each atom up to once O(n!)
beam search with beam width of c 0(cl)
the optimal algorithm
sh oul d f all In here
partition/search
collaborative V- a sac
f Iftering
0(1) everyone gets the same predefined path
# constraints
imposed on paths Figure 10. Graph of Constraints versus Possible Paths for Algorithms
3.3 Extremes
First, let us consider the strategies at the extremes of Figure 10.
If our strategy is to pick a random path of random length, then this imposes no constraints and allows all possible paths, so it lies on our graph near the Y-axis on a point like ( 0%, infinite ). If we constrain the path to have length at most I (because we know that realistically, the best path is not going to contain a million atoms), then we now have ni possible paths and a ( 1%, O(n) ) point. We could further constrain the solutions so that each atom can only appear once in the curriculum. This would reduce the number of possible paths to n!, and might lie at ( 2%, O(n!) ). However, it is possible that even this kind of constraint would filter out the best path. Perhaps the best path involves presenting an atom early on and coming back to the same atom again later in a different context.
If our strategy is to give all students the same textbook chapter, then this imposes many constraints leading to only one possible path, and it lies on our graph near the X-axis on a point like ( 100%, 1 ). The best strategy is clearly somewhere between these extremes.
3.4 WaIkSAT-Style
The "satisifiability problem" is the problem of finding satisfying assignments to a Boolean formula. For instance, a solution to (X and Y) could be the assignment [X=l, Y=l]. WalkSAT is an algorithm that incorporates random walks to solve the satisfiability problem. First, WalkSAT guesses a solution to the problem. In our example problem, maybe it guesses [X=0, Y=0]. Then, it picks one of the variables, and flips its value. So, X=0 could become X=1. The algorithm keeps doing this until it randomly "walks" onto a satisfying assignment. There are several heuristics used by WalkSAT for finding out which variable it can flip to have the maximum chance of walking closer to a solution.
A "WalkSAT-style" path-finding strategy would take a random path and refine it a large number of times. First, this kind of strategy would need a formula for determining how good a given path was (a "path-evaluating metric"). The path-evaluating metric could be another program that simulates a learner, or it could be a large formula that uses knowledge entered by the expert in the field. After the path-evaluating metric is
established, the algorithm picks a random path. Then, it picks an atom along the path to replace during each step of the walk. Eventually, the algorithm should be able to walk its way to a good path.
The key to finding a good path with the WalkSAT-style algorithm is to have a good path-evaluating metric. The number of constraints imposed by the algorithm is very low in theory because if you only run WalkSAT for one step, then it reduces to the
"random path" algorithm. However, some path-evaluating metric could impose many
constraints. If the metric was "A -> B -> D is the best path" and returned scores
corresponding to how close the given path was to A -> B -> D, then this would actually
be imposing many constraints on the final path. If WalkSAT was run for a million
The number of paths that can be explored by WalkSAT corresponds to the number of iterations that the algorithm is set to run for. If the algorithm is set to run for 3
iterations, then even though any path in the search space might be hit, the algorithm is really only considering 3 different paths during the run.
Because the number of constraints and number of paths both depend on the exact parameters that the algorithm is run with, it is difficult to place the WalkSAT-style
algorithm on any particular point in the constraints versus paths graph. However, individual instances of this algorithm could be plotted to the graph. For instance, there could be a point that corresponds to "WalkSAT-style with path-evaluating metric A and 100 iterations" and another point that corresponds to "WalkSAT-style with
path-evaluating metric B and 2 million iterations."
3.5 Beam Search
In the Beam Search strategy, a domain expert picks the next best constant number ("beam size") of atoms after any particular atom. The beam size can be arbitrarily set (e.g., "5" or "2"), or it can be a value related to the total number of atoms (e.g., "log(n)").
a ibi 'I
C
dj - i h f a
Figure 11. Beam Search Only Considers a Set Number of Atoms Per Level
Let's consider the atoms in Figure 11, and arbitrarily choose 2 as a good beam size for this number of atoms. So for Beam Search, the expert needs to pick the next best 2 atoms from every atom. For atom a, the expert might decide that the next best atoms are b and e. By picking b and e, the expert is saying that if all he knows is that atom a was just taught, then he thinks teaching atom b or atom e next would be most appropriate.
After the expert sets up the table (hereafter the "postatoms table"), we can run Beam Search. Let's say you start the search at atom a. First, Beam Search adds atom a to your path. Then, it decides whether atom b or e is a better fit for your learning style. Let's say atom e fits you better. Now, Beam Search adds atom e to your path and looks at atoms f and g (which the expert chose as postatoms for atom e) next. This process continues until a pre-specified path length is reached or until a pre-specified end atom is reached (e.g., we could specify that all paths end after presenting atom i).
Beam Search can be run as a one-time search or as a memoryless one-step-at-a-time process. The main advantage of Beam Search is that it reduces the search space. If we wanted a path of length 1 but did not have any restrictions, we would have to consider nI possible paths. Beam Search reduces this number to (beam size)' (as shown on the right
side of Figure 11), which is considerably lower than n. Taking beam size to be log(n), Beam Search would lie around ( 5%, O(log(n)') ) on our graph.
One disadvantage of Beam Search is that the postatoms table takes O(n2) expert time to set up, and that is too much required time. If we had a thousand atoms, our expert would need to make over a million comparisons to set up the table. Another disadvantage
is that the Beam Search results are not very good (this results from the memoryless nature). So, we know that we want an algorithm with more constraints and fewer possible paths.
3.6 Partition/Search
The "Partition/Search" strategy adds edges to the atoms and creates a directed prerequisite graph, then it assumes that the best path for each student lies in the directed graph.
Partition/Search begins by creating a directed prerequisite graph in under O(n) time. We assume that the expert can keep m (maybe -10) things in his head at once, and that it is reasonable to ask an expert to create a directed prerequisite graph out of m atoms (this involves O(m2) work).
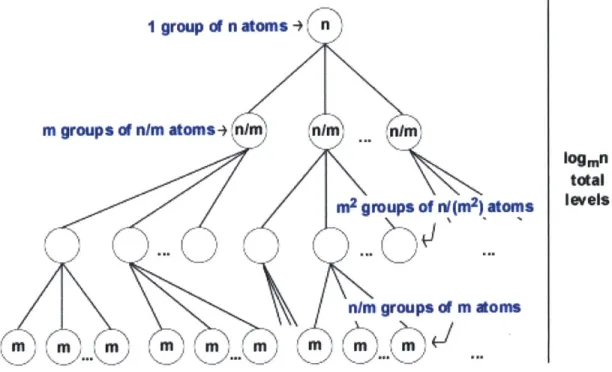
The graph-creating procedure involves hierarchically dividing atoms into
categories, and can work with any number of atoms. First, decide on m categories that the n atoms can be divided into. Now, assign each atom to one of the m categories. There
should be m groups of n/m atoms, as shown in Figure 12. Next, for each of the m groups, divide all the atoms in the group into m more categories. Repeat this process until the groups at the lowest level have <= m atoms. Each level takes O(n) work (the expert assigns each of the n atoms to one of the m categories in his memory) and there are logmn levels, so this takes O(n x logmn) work.
I group of n atoms +
m groups of nim atoms+ n/nM "I
m2 groups of nI(m2) atoms
nlm groups of m atoms
mm mm m~-mm
logmn total levels
Figure 12. Making Large Prerequisite Graphs Level by Level
For instance if you took all the knowledge in the world, this might be a billion atoms. At the highest level, we want m categories to divide the atoms into. One category might be "Scientific Knowledge" and another category might be "Common Sense." Each of these categories would have around 100 million atoms. "Scientific Knowledge" could then be further divided into m categories like "Physics" and "Chemistry." This division would continue for 9 (logol,000,000,000) levels until the categories in the lowest level each had under 10 atoms.
Now, we create directed graphs within every category and subcategory. Start at the lowest level, which has n/m groups of m atoms each. It takes O(m2) work to create a directed graph in each group. So, it takes O(n/m x m2) = O(n x m) work to create all the directed graphs at that level. Next, move up one level. There should be n/m2 groups, each containing m subgroups. Create a directed graph for each of the n/M2 groups. This should
take 0(n/m2 x m2)= O(n) work. Continue this process for each of the logmn levels in the hierarchy. The total amount of work needed is O(n x m x logmn). m is a constant, so this reduces to around O(n x log(n)).
We now take all our directed graphs and combine them into a single graph. Wherever we created a directed graph of groups, replace each of the groups with the directed graph of the particular group (from the lower level).
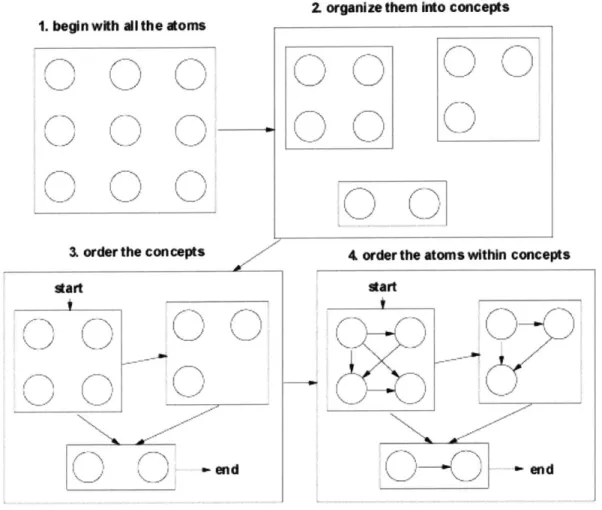
2. organize them into concepts 1. begin wfth ii the atoms
' 'N 6> 6> '* *N 6~> 6> I I K>
w;
2 N (~> ~> I 'I I,) ~ .'.order the concepts 7 4 order the atoms within concepts
atart ~ (~N I.. /"*"N, 'I I N,, ,' \~> ~ 6'N KI *~ 2 N ~ -"""N 6> n-end \.,.~/ \~2 tart end
Figure 13. Partition/Search Divides the Atoms into Groups
Figure 13 shows the general idea. We start with 9 atoms, then break them into a group of 4, a group of 3, and a group of 2. In step 3 we create a prerequisite ordering over groups. The ordering we made means that a student will always be given the 4-concept group first. After the 4-concept group, they could go to either the 3-concept group or the 2-concept group. If they went to the 2-concept group, then the curriculum would end
\~_2 (-~>
6~> K
2 '~__~ K>
6
they would get the 2-concept group next. In step 4, the individual atoms within the groups get ordered.
Once Partition/Search has the directed prerequisite graph, the challenge is just to find the best path in the directed graph for each individual student. One way to do this is to find the path that has the lowest "average atom distance" from the student. To calculate this, we need a distance formula dist(student model, atom information). Let's say a path
has 3 atoms, with respective distances 4, 5, and 6 from the student model. The average atom distance of this path is 5. We can find the overall path with the lowest average atom distance by using our hierarchical system. First, find the best path (lowest average atom distance) through each of the n/m groups of m atoms. Then, set the lowest average atom distance as the "distance" for that entire group, and find the best path at the next higher level using these distances. Eventually, you will have a best path at the highest level which can be expanded back to get the best overall path of atoms.
Partition/Search assumes that the curriculum can be taught as successions of larger concepts, and takes O( n x log(n) ) work to set up. This strategy lies on the graph closer to the ( 100%, O(1) ) point than the ( 2%, O(n!) ) point because with this strategy, all the possible paths have in effect been "pre-approved" by the expert. This strategy takes a reasonable amount of expert work but filters out the many good paths that do not happen to lie in the directed graph. So, we want a solution with fewer constraints and more possible paths.
3.7 Beam-Partition Hybrid
Beam-Partition Hybrid is a hybrid algorithm between Beam Search and
Partition/Search. It runs just like Partition/Search, except that at the lowest level of the prerequisite graph it runs a Beam Search instead of creating an directed prerequisites graph. Setting up a Beam Search at the lowest level takes the same amount of work as setting up the directed prerequisites graph would have, so Beam-Partition Hybrid takes the same amount of work to set up as Partition/Search. However, Beam-Partition Hybrid is able to explore more possible paths than normal Partition/Search because the Beam
In summary, Beam-Partition Hybrid imposes more constraints than Beam Search but fewer constraints than Partition/Search. Beam-Partition Hybrid can explore more possible paths than Partition/Search, but fewer possible paths than Beam Search. Beam-Partition Hybrid takes around O( n x log(n)) work to set up. We know that the optimal
solution on our paths vs constraints graph is between Beam Search and Partition/Search, and Partition Hybrid is between Beam Search and Partition/Search, so Beam-Partition Hybrid may be worth exploring in greater detail.
3.8 Collaborative Filtering
Collaborative Filtering is a meta-approach. It requires us to use another strategy as a starting point, then it tries to find better results than the original strategy. It also requires us to choose parameters specifying how many "generated" solutions are
presented and how many "random" solutions are presented. Collaborative Filtering starts with a training period before it becomes effective.
Let's consider a Collaborative Filtering strategy that uses Partition/Search, with 3 generated solutions and 2 random solutions at each level. During the training period, many students are asked to use the system. These students are given the atoms one by one. After each atom, they are given 5 (= 3 + 2) atoms to choose from. 3 of the 5 are the next 3 atoms that Partition/Search would recommend, and 2 of the 5 atoms are randomly chosen. The student is asked to pick which of the 5 atoms she would like to see next, and gets the atom that she picks. This procedure is repeated until the student goes through the entire curriculum.
Collaborative Filtering tries to improve itself during the training period. Late in the training period, it is likely that the system will encounter students that have student models similar to past students. When this happens, the system includes the previous student's atom choice in the list of 5 atoms for the current student. If the current student chooses the same atom at the same point as the previous student, then it is likely that the chosen atom fits well after the given atom.
After the training period, the Collaborative Filtering system generates full
curricula for new students by finding the paths that were hand-picked by the past students with the closest student models, and recommending those paths.
Because Collaborative Filtering includes randomly chosen atoms during the training period, it is able to find the potentially best paths and does not stay restricted to paths that fit along the prerequisite graph. Collaborative Filtering uses the help of students to try to move along the constraints vs paths graph (Figure 10) toward the optimal solutions.
3.9 Developing Theory
If we develop a lot of theory about how to teach a subject, then we can approach the path-finding problem similar to the way we would approach a planning problem. The idea behind this is that we want to annotate every atom with plenty of pre-conditions and post-conditions. For instance, an atom on "How to drive a car" would have many pre-conditions checking if the user was ready to drive a car (e.g., "is-tall-enough," "knows-how-to-walk," "has-5-hours-free-time"). The better the theory we have about what knowledge is needed, the better the algorithm will turn out. The atom will also have many post-conditions describing what attributes the user has after learning the atom. The overall problem now becomes a matter of picking the necessary atoms to go from a starting state of conditions to a desired ending state of conditions.
3.10 Summary Chart
The following table (Figure 14) summarizes some of the algorithms for our path-finding problem, and describes some advantages and disadvantages of each.
strategy advantages disadvantages
Pick a random path of 0 Easy to set up. 0 99.99% of the time, you won't
(random/fixed) length. 0 No expert work involved. get a good answer.
(Allow/disallow) repeated 0 Can hit best solution.
atoms.
WalkSAT-style strategy 0 Can hit best solution. 0 A good prerequisite
0 Results will be better than enforcement score function is
pure random. hard to come up with, and may
take a lot of expert time or deep domain knowledge.
* Students with the same student
model might get different curricula.
0 Results are only as good as the
goodness-of-fit metric.
Beam Search -either 0 Simple to understand. 0 O(n2
) work to set up.
through the entire curriculum, o Can return paths an expert 0 Hard to efficiently add more
or as a memoryless 1-step-at- would give. atoms later.
0 Does not enforce prerequisites as well.
Partition/Search strategy. 0 Scales well if more atoms are * The large reduction of overall
added later. search space leaves good paths
* O(n x log(n)) expert work. but might cut out the best path
* Enforces prerequisites. and/or many clever paths.
A Collaborative Filtering 0 Can hit best solution. 0 Takes many students before
strategy. Pick an existing * Students can be given paths much improvement is shown.
strategy and choose how that other students have 0 If the material changes,
many options come from that chosen and done well with. adjusting the system requires
strategy and how many 0 System gets better with time. many additional student-hours.
random options to present.
A Planning Algorithm. For 0 There are many established 0 Planning is more about finding
instance, POP or FF. planning algorithms to choose "any good path" than "the best
from. path." Our problem is more
about finding the "best path."
Develop theory on the best 0 Can hit best solution if 0 Very domain dependent and
way to teach a topic and on detailed enough. requires theory on the best ways
the structure of the topic. For a Generally good solutions that to teach topics in the particular
each atom, mark what you account for starting domain.
need to know before and knowledge. 0 Gets complicated when looking
what you would learn. Then, at many factors per atom.
search from starting knowledge to desired knowledge.
Figure 14. Path-Finding Algorithms Summary Chart
"Dynamic delivery" of content is an interesting idea that normally takes the form of periodic quizzes and re-planning. On the one hand, we can create a system that outputs an entire curriculum for the user. On the other hand, we can create a system that evaluates the user as she is going along, and adapts to the user's performance. The algorithms explored in this chapter did not use dynamic delivery because our formulation of the problem (as optimal-path-finding across atoms) did not require dynamic delivery.
4
Implementation
4.1 Objectives
To further enhance the effectiveness of the course sequencing method, it is important to consider the following factors:
1. The ability of a system to use existing curricula instead of requiring development of new curricula.
2. Human teachers naturally teach examples and reading assignments from different sources. It would be useful for a system to be able to mix together material from different sources.
3. Greater emphasis on customizing for student characteristics.
The system developed for this project improves on traditional course sequencing with factors 2 and 3. It improves on customization systems with factors 1, 2, and the ability to do course sequencing. It improves on existing hybrid systems with factors 1, 2, and 3.
1 2,4,46
curricula postaton outputs
table custom
curricula
I LHMM
LJ beam
r- 0 search
xeroxed scanned atom learning outputs learning
pages atoms styles custom styles
lassifications curricula quizzes
F -1
partition
search
atoms prerequisites
graph
Figure 15. Overall Implementation Steps