Real-time prediction of severe influenza epidemics using Extreme Value Statistics
20
0
0
Texte intégral
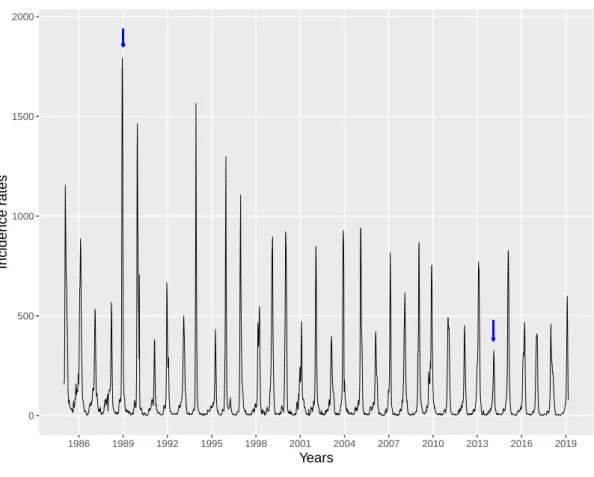
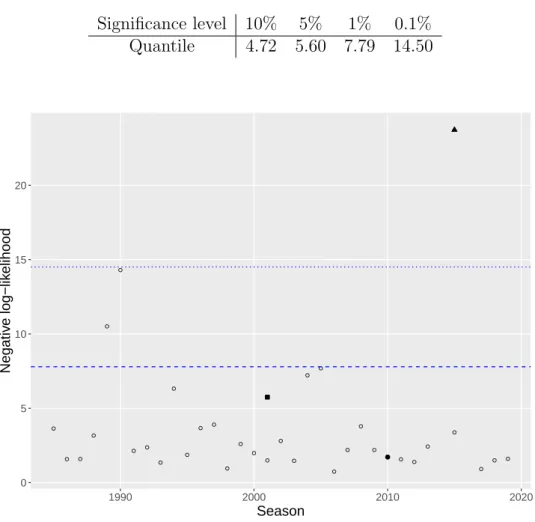
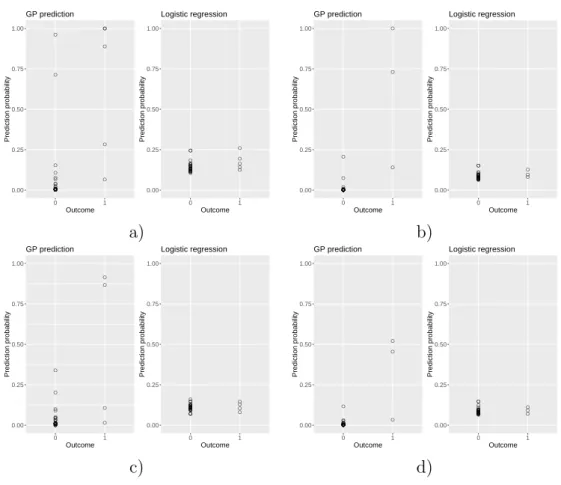
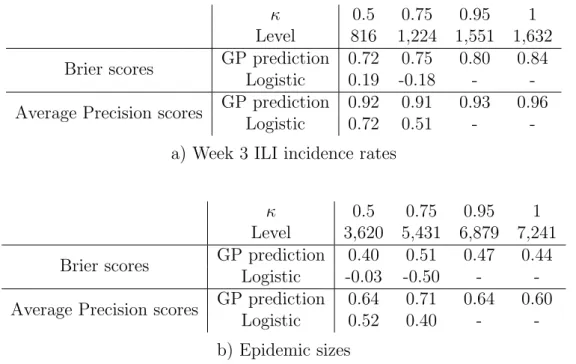
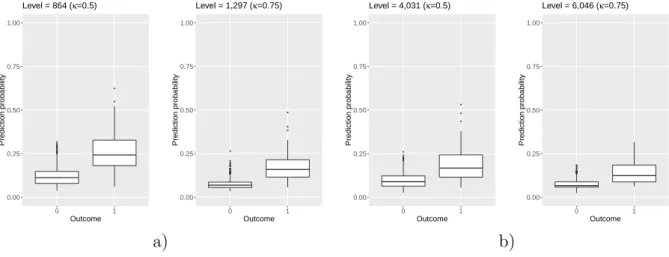
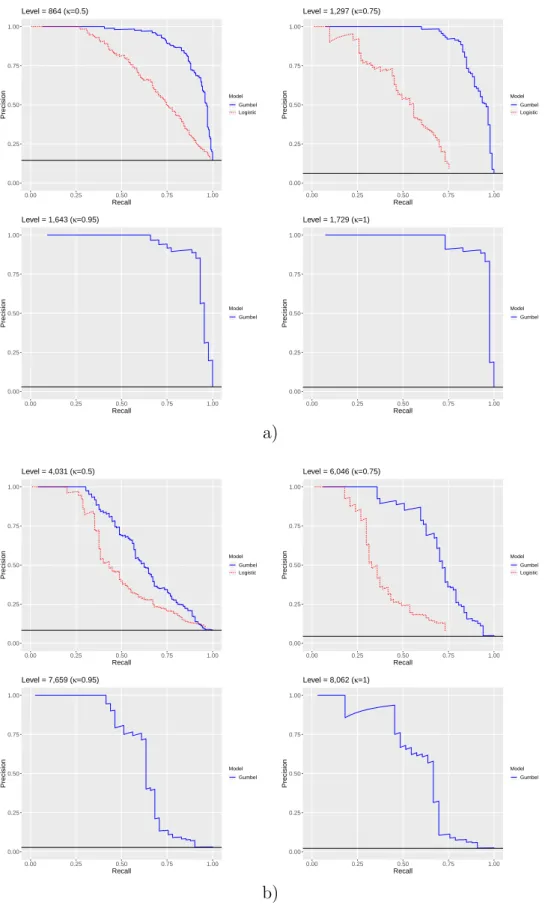
Figure
+3
Documents relatifs