Fast consensus hypothesis regeneration for machine translation
Texte intégral
Figure
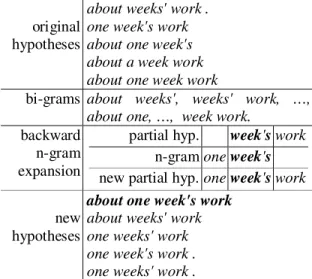
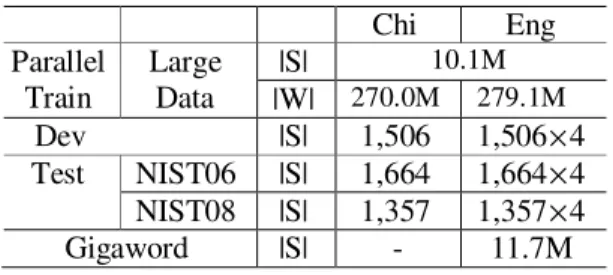
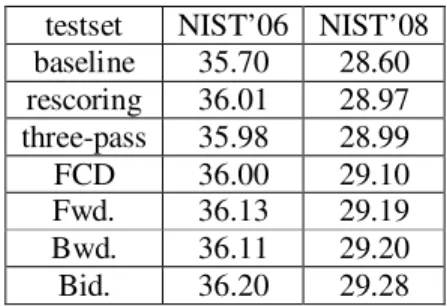
Documents relatifs
This paper has given a sketch of the GREYC machine trans- lation system that participated in the IWSLT 2007 evaluation campaign in the two proposed classical tasks: the translation
We explored the following features to weight the relevance of the bitexts and the individual sentences: corpus weights, alignment scores, recency of the data with respect to the
Both source and target phrases are used to rewrite the parallel corpus which is used to train the language and the translation models.. In section 2, we give an overview of the
The source side of the monolingual Turkish data used to create the synthetic corpus are translated to En- glish using two different TR→EN systems namely (E1) and (E2) where the
– Step 1: Starting from 25 features, we build 23 subsets, in which 1 contains all features, 1 contains top 10 in Table 1, and 21 sets of 9 randomly extracted features for each. •
Each approach is deployed with a different NMT model and a different dataset variation; a dataset with original translation, a dataset with hybrid back-translated (synthetic) data,
In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1:
Cette thèse s’intéresse à la Traduction Automatique Neuronale Factorisé (FNMT) qui repose sur l'idée d'utiliser la morphologie et la décomposition grammaticale des mots (lemmes
