Balancing appearance and context in sketch interpretation
Texte intégral
Figure
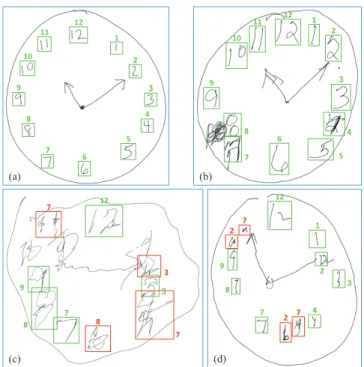
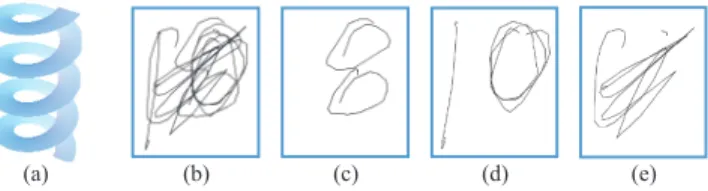

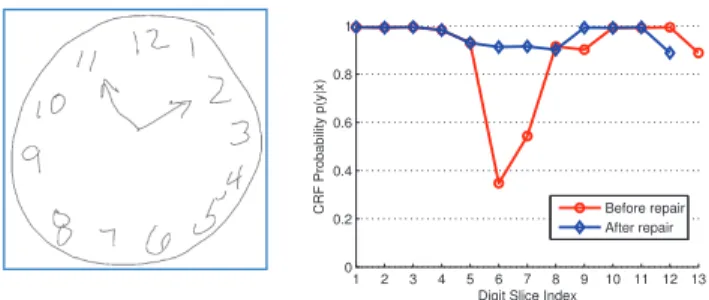
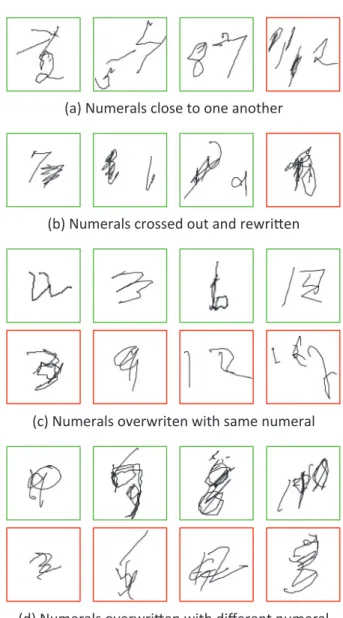
Documents relatifs
In previous editions the shared tasks organized at VarDial included dialects of Arabic, German, and the DSL shared task which featured similar languages and language varieties
This section presents the feature extraction methodology proposed in the context of this paper. The extracted features are able to quantify the degree of anomaly of each MOAS
The construction of this problem is similar to the construction of problem (4) in the linear case considering separation of approximate features ˜ φ(x i ) instead of data points x i
Now that we have introduced our feature-based context-oriented programming approach, in this sec- tion we present the tool we built to help program- mers visualise and animate
The key idea is that we collect meta- data about the attributes in the database (e.g., attribute data type), meta-data about the feature generative functions (e.g., id of the
Keywords: doping in sports, career, moral disengagement, bodybuilding, appearance and performance enhancing drug, interactions, qualitative
Keywords: doping in sports, career, moral disengagement, bodybuilding, appearance and performance enhancing drug, interactions, qualitative
These issues included the following: challenges related to rebuilding collapsed fisheries and threatened communities; the documentation of regional cod migration patterns;
