in
2011
with
funding
from
Boston
Library
Consortium
Member
Libraries
5
Massachusetts
Institute
of
Technology
Department
of
Economics
Working
Paper
Series
CONDITIONAL VALUE
-AT-RISK:
ASPECTS
OF
MODELING
AND
ESTIMATION
Victor
Chernozhukov,
MIT
Len
Umantsev,
Stanford
Working
Paper
01
-19
November
2000
RoomE52-251
50
Memorial
Drive
Cambridge,
MA
02142
This
paper can be
downloaded
without
charge from
the
Social Science
Research
Network
Paper
Collection
atAUG
1 5
2001
Massachusetts
Institute
of
Technology
Department
of
Economics
Working Paper
Series
CONDITIONAL VALUE
-AT-RISK:
ASPECTS
OF
MODELING
AND
ESTIMATION
Victor
Chernozhukov,
MIT
Len
Umantsev,
Stanford
Working
Paper
01
-1November
2000
Room
E52-251
50
Memorial
Drive
Cambridge,
MA
02142
This
paper
can be
downloaded
without
charge from
the
Social
Science
Research Network
Paper
Collection
atConditional
Value-at-Risk:
Aspects
of
Modeling and
Estimation
Victor
Chernozhukov
1 ,Len
Umantsev
2 * 1 Department ofEconomicsMIT
Cambridge,MA
02139 [email protected] 2 Departmentof
Management
Science andEngineering Stanford UniversityStanford,
CA
94305-4026Received: September30, 1999 /Revisedversion:
November
20, 2000Abstract
This paperconsiders flexibleconditional (regression)measures
of
market
risk. Value-at-Riskmodeling
is cast in terms ofthe quantilere-gression function - the inverse of the conditional distribution function.
A
basic specification analysis relates its functional forms to thebenchmark
models
ofreturnsand
assetpricing.We
stressimportantaspects ofmeasur-ingtheextremal
and
intermediateconditionalrisk.An
empirical application characterizesthekeyeconomic
determinantsof various levelsofconditionalrisk.
*
We
thank TakeshiAmemiya,
Herman
Bierens, Emily Gallagher, RogerKoenker,
Mary
Ann
Lawrence,Tom
MaCurdy, Warren
Huang, ananonymous
ref-eree,andparticipants ofseminarsatStanfordUniversity,UniversityofMannheim,
Midwest Finance Association Risk Session,CIRANO,
International Conferenceon Economic Applications ofQuantile Regression for
many
useful conversationsand/or comments. Very special thanks toBernd Fitzenberger
who
provided1
Introduction
and
Conclusion
Value-at-Risk (hereafter,
VaR)
is amost
widely usedmeasure
ofmarket
risk,
employed
in the financial industry forboth
the internal controland
regulatoryreporting.We
explorevarious aspects ofVaR
modeling
basedon
themedian/
quantile regressions ( cf.Hogg
(1975), Bassettand Koenker
(1978),
Koenker
and
Bassett (1978)):—
ConditionalVaR
modeling
is cast in terms of the regression quantile function - the inverse of the conditional distribution function.We
re-late the functionalforms ofconditional quantiles tothe basicstatisticalmodels
of returnsand
themodels
of asset pricingand
arbitrage.The
conditional quantile
models
are semi-parametric innatureand
are con-siderablymore
flexiblethan most
commonly
used parametricmethods
(section 2).
— The
key econometric aspects ofconditionalVaR
measurement
aredis-played (section 3). In particular,
we
address estimation, inference,and
specification analysis ofhigh
and
intermediate conditional risk.A
fun-damental
problem
inmeasuring
high conditional riskisthelack ofdataon
high risk events,which
requires the considerations ofextreme
value theory (seeChernozhukov
(1999a) for atheoretical account).—
An
extensive empirical section exposes the methods.We
estimateand
analyze the conditionalmarket
risk ofan
oil producer stock price asa function ofthe key
economic
variables.We
find that these variablesimpact
various quantiles of thereturn distribution in a very differentialand
nontrivialmanner.
The
key determinantsof theextremaland
inter-mediate
conditional risk are characterized.The
market
index (DJI) isfoundto
be
theonlystatistically significantdeterminantoftheextremalrisk.
The
other key variablesmay
also exhibitverylargeeffect.However,
thedirectionoftheeffect
can
notbe
isolateddue
to thescarcity ofdata
on
high risk events.We
hope
our views are useful to the reader.We
alsorecommend
otherworks
thatconsiderregressionquantilemodeling
invalue-at-riskand
relatedproblems
infinance:Bassettand
Chen
(1999),Engleand
Manganelli (1999), Heilerand Abberger
(1999), Taylor (1999),among
others.2
Modeling
Risk
Conditionally
In thissection
we
discussmodeling
VaR
and
relatedMarket
Riskmeasures
(MRMs)
via conditional quantilesand
other techniques.2.1 Preliminaries
The
settingwe
consider is asfollows:—
Y
t is theprice process of the security or portfolio ofsecurities.
—
X
t is takento be a"stateprocess" or"information" vector. In practical
applications,
Xt
usually consists of prices(or returns) ofsecurities,mar-ket indexes, interest rates, spreads, yields,
and
the like.We
may
allowX
t togrow
with the length ofthesampling
period.Lagged
values ofYtand
functions ofsuch laggedvalues (e.g. exponentially-weightedsample
volatility)
may
ormay
not be includedin Xt-1The
Return
ofa portfoliowith price process Yt over [t,t+
h) isy?
=
\nY
t+h-}nY
t.The
Conditional Value at Risk (VaR), Vt(p), is defined as a level ofreturn y^ over the period of [t,t
+
h) that is exceeded with probabilityp
(pe(o,i)):
2t£(p)=inf{i;:P
t(yth
<t;)>l-p}.
V
Alternatively, this
can
be
written in terms ofthe conditional distribution function ofy^:v?(j?)
=
F-
h1
(l-p\X
t),Vt
where
F~
h (-\Xt) isan
inverse ofthe cdfF
'h(-\Xt )orthe so-called conditional
quantile function. Let us call
p
and
r=
1—
p
- the confidence leveland
the index ofVaR,
respectively.The
ConditionalVaR
curve is the conditionalVaR
viewed as a function ofthe confidence level.Similarly, the
Extreme
VaR
may
be
defined asthemaximum
possiblelossovera periodof time. Inthisregard,the
extreme
VaR
may
be introducedasthe limit
form
ofthenon-extreme
VaR
for confidence levelsp
approaching1:
^(1)
=
limF~
l(l-
p\X
t)=
inf{v :F
t(y?<
v)>
0}.Correspondingly, extremal
VaR
areVaR
measures
withp
close to 1. 1Using thestandard notation, timesubscriptundertheexpectationE[],
prob-ability P(), dfF(), ordensity /() denotes conditioningon the information set
X
t.Thisdefinitionallows toavoidambiguity
when
thedistribution ofy^isatomic.p}-As
noted, thesuperscript hspecifiesthe length ofthetimeinterval.(We
drop
thesuperscript inthesequel to simplify notation.) Inthe practicalap-plications,
h
is typically chosen to be 2weeks
for the regulatory reporting3 (which
typically translates to 10 business days for local applications or 12 business days for around-the- globe trading applications, such as Forex
desks). 1-day intervals are used for the quality assessment of banks'
VaR
models
by
regulators. It is alsocommonly
used for the internal risk man-agement, although other values ofh (uptoonemonth)
arehotuncommon.
There
aretwo primary
reasonswhy we
are not interested inmeasuring
market
risk for time periods longerthan
onemonth:
(1)market
riskevents typicallyhappen
during short intervals,and
(2) lossesdue
tomarket
riskeventscan be relatively easily restored in short periods oftime (reduction ofbalancesheet, refreshment ofcapital, etc.), especially ifthe
market
riskevent isnot
accompanied by
the liquidity orsystemicriskevents. Thiscon-trastswith the
measures
ofthecredit risk,which have
to be estimatedoverthe instruments' lifetime (which could
be
as longas 10 to30 years).2.2
Market
RiskMeasures
and
ConditioningMRMs,
as statistical estimators, canbe
parametric, semi-parametric,and
non-parametric,depending
on
the strength of identifiability assumptionsmade
by
themethods.
4The
most
commonly
used parametric
MRM
is the variance-covariancemethod
thatassumes
(conditionally)normal
returns(implemented, forexample, inJ.P.
Morgan's
RiskMetrics).The
conditional quantilemethods
with parametricand
non-parametricfunctional forms fallinto the semi-parametric
and
the non-parametricclasses, respectively.3
See
FedReg
(1996) for the review ofthe 1996 RiskAmendment
to theBasle Capital Accord of1988.4
Another fundamentally different
method
is the stress-testing, in which onedefines "basis of probable events" (such as various parallel shifts of the
Trea-sury yield curve, changes ofthe yield curveslope, and others used in the
DPG
guidelines), "highlyunlikely events" (such asadrop by
25%
in theS&P500)
and"structurallyimpossible events" (suchasadropby
25%
intheS&P500
accompa-nied byalargeincrease inDJI) and examines thebehaviorofthe portfoliounder
various such events or shocks.
MRMs
of the last typemay
offer valuable insightabout the market-riskproperties ofasecurity oraportfolio.
The methods
areless statistical andmore
experimentation-basedin their nature,yetthey couldbeuse-fully combined with statistical methods, especially
when
datais not informativeThe
type ofconditioningis another vitaldimension
alongwhich
MRMs
can be classified.
The
followingtwo
types are not mutually exclusive, yetthe proposeddistinction will be useful.
(a)
Moving
Window
Sampling
-Regime
ConditioningMany
ofthe historicaland
parametricMRMs
arebasedon
the samplesof certain (often
moving) width
(e.g. awindow
of the last 100 returns).The
sample
is then weighted or not weighted tocompute
theparameter
estimates. Forexample, the "historical volatility"approaches5usegeometric
weighting. In this case, such
measures
may
be seen asGARCH
models
that have recursive conditional variances.6
Thus
suchmethods
could beinterpreted asthe regression
measures
described next.Oftentimes, however,
no
weighting isdone
and
no
interpretation oftheabove
kind is provided.What
is achievedby
such aform
ofconditioning?A
primary
goal is to robustify theMRM
against the structural changesor regime switches.
That
is, thewhole
historymay
not bean
appropriatesample
formeasurement/estimation
due
to structural changes thathave
occurredinthe past.Indeed, thedynamics
ofoilpricesinthe 70sisprobablyvery different
from
that now. Therefore, considering the equally weightedsample
ofmoving width
is,most
ofall, amethod
for disregarding un- ordis- informative data. Thus, such procedures could
be
seen primarily asmethods
ofconditioningon
theenvironment
and
as away
toguard
against misspecification w.r.t. a given historical period.(b) Regression - Conditioning
on
the informationXt
In addition to considering the informative data, a risk-modeler seeks to
produce
ameasure
ofrisk conditionallyon
theset ofthe keyeconomic
("state") variables Xt- For example,
one
may
wish to characterizevolatil-ity oftheoil return asa function ofthe oil spot price, key
exchange
rates,etc.
Such
aform
of conditioning is a regression characterization of risk.Regression seeks to describe the
moments
of return (generally,distribu-tion or quantiles) as functions of
X
t.The
sample
analogues of regressiondependencies are regression estimators.
Examples
ofMRM
ofthis kindin-clude frequently used parametric
methods,
such as thenormal
GARCH,
and
the class of quantile regressionMRMs
treated in this paper. Indeed,GARCH
represents volatility as a function ofX
t, the regression quantile5
Implementedin RiskMetrics.
6
Standard
GARCH
modelsalsoassigngeometric weightstothe squaresofpastinnovations, and the "moving window" resultsfrom truncating the
sum
once themethod
describes the quantiles of return distribution ofVt\X
t.Note
thatmost
non-parametricor "historical"methods,
such as unconditionalquan-tileor
moment
estimation arenotregressionmethods
inthat the regressiondependence
issimply not modeled.An
example
ofa non-parametricmethod
that gives a regressionmeasure
is a non-parametric estimator ofthe con-ditional density function (fromwhich
a conditionalVaR
estimate canbe
computed
- seeAit-Sahaliaand
Lo
(1998)).72.3 Quantile Regression
QR
flexibly allowsus to directlymodel
theconditionalVaR,
utilizing onlythe pertinent information that determines quantiles of interest. This is in
sharp contrast
with
the traditionalmethods
that use informationon
thecentral
moments
of conditional distribution- mean,
variance, kurtosis, etc.- toconstruct the
VaR
estimates. Thisprimary
feature ofQR
is especiallyimportant for
modeling
intermediateand
extremal conditionalVaR.
Envisioning the essence of the conditional quantile modeling is quiteeasy. Fix
any
p, a confidencelevel.Assume some
functionaldependence
ofVaR
on
the informationvariablesX
t:vt(p)
=
F-^rlXt)
=
m
p(X
t,(3(p))-For
any p
(oraset ofp's)we
couldsuitablypickone
ortheotherform
ofm
p tomatch
theobservedhistoricaldatasufficientlywellthrough
aset ofsam-ple
moment
restrictions.8Thismatching
isimplemented
through themeans
ofquantile regression
and
relatedmethods
(see section4). Inthis paperwe
exclusively confineour attention tothe linear (polynomial) analysis.
3
A
Basic Specification Analysis
Linear (Polynomial)
Models
7
To
name
a few disadvantages ofthefully non-parametric approach: (1)com-putational, and (2) due to model complexity, it often entails a significant loss
of predictive ability in moderate-sized samples and cases of
many
conditioningvariables.
8
In fact, the choice of
m
p could be arbitrarily flexible - non-parametric. Forexample,
m
p can be modeled through a composition of basis functions ofaA
fundamental
model
isthelinearmodel
of conditional quantilefunction (VaR):vt(
P
)=
F-^rlXt)
=
X[
/?(p), (3.1)where
X
t is a d-dimensional vector representingany
desired transforms(powers,etc.) of
X
t, includingaconstant.We
nextdiscussboth
theplausi-bility
and
restrictivenessofsuch model.(a) Location- Scale
Models
Linear
model
(3.1) naturally arises, for example,from
anAR
formula-tion ofthe returndynamics. Indeed, consider a simple linearlocation-scale
model:
yt
=
X'
ta
+
X'
t\u
t,Ut is independent of
Xt
,P
(ut<
0)=
1/2.Model
(3.2) is a location-scale model,where both
locationX'
ta
and
scaleX[\
>
are parameterized as linear functions. Furthermore, locationX[a
isthe conditional
median
function.We
shouldalsoimpose
scalerestrictionsto identifyA, e.g.
E\u
t\=
1or, alternatively, ||A|| =1.Sincemodels
like(3.2)are not used insequel,
we
omit
any
further discussion ofidentification.We
candefine the "shock"term u
t in a (perhaps)more
familiarway:yt
=
X'
ta
+
X[\u
t,u
t is independent ofX
t ,E
(ut )=
0,E
(uj)=
1.In this case, location
X[a
is the conditionalmean
function,and
X[X
>
is thescale ((X'
tX) 2
is the conditional variance).
Note
thatmodels
such as(3.3) are directlyjustifiable
from
thestandardAPT
and
other factormodels
(see
Campbell, MacKinlay,
and
Lo
(1997)).It is very plausible that either
model
generates a linear conditional quantilemodel.Denote by
F
u the distribution function ofu
t.Then
clearlyvt(p)
=
X[a
+
X'
tXF
u-\r)
=
X'
t(3{p).(b)
N
on- Location- ScaleModels
While
a linearlocation-scalemodel
implies alinearVaR/
quantilefunc-tion,the converse
may
notbetrue.Indeed, itiseasyto seethatthelocation-scale
model
necessarily involvesmonotone
coefficients /3(p) inthe quantileindexp,
whereas
(3.1) imposesno
such assumption. In eithermodel
(3.2)or (3.3), it is
assumed
that Ut is independent ofXt- In generalu
t will benot independent of
Xt
,and
all such casesform
the class ofnon-location-scale models. It is not difficult to see
how
these cases can generate the linear/polynomial forms.Polynomial Models
asApproximations
ofNon-linearModels
More
generally, thelinear/polynomialspecificationscan
be consideredasapproximationsofnonlinear
models
oftheform
yt=
/-i(Xt)+o-(Xt)ut.Sinceit is clear
how
thisapproximation
works,we
omitany
further discussion.RecursiveSpecifications
Models
thatwe
have
considered so far representVaR
as a function ofonly a few key
economic
variablesand
their transforms,X
t. Itmay
be
desirable to consider
models
that reflect thewhole
past information Xt-Nonlineardynamic models
allowforawide
variety ofsuchspecifications. For example, letX
t be the subsetofinformationvariables (ortheirtransforms)that
become
availableinthe r.-thperiodand
X
t-\be
variables {Xj}^Z.q, sothat
Xt
=
{X
t,Xt-i).A
general recursive specificationcan then be obtainedasfollows:
vt {jp)
=
X'
ta{p)+
b{jp)h{Xt,p)f
l{x
u
p)=
c{p)fl{x
t-uP)
+
h{Xtid{p))
Linearformsin (3.4) can be replaced
by
nonlinearforms. Restrictions, guar-anteeing stability of the model,must
beimposed
on
a,b,c,fi,f2-Models
of this sortwere
considered inWeiss
(1991),Koenker and
Zhao
(1996),Engle
and
Manganelli (1999).Models
like (3.4) are useful as parsimoniousregressionsthatrepresent value-at-risk/quantiles asa functionofallpast
in-formation. Incontrast,thesimpler
markovian
specificationspositthatmost
of relevantinformationis contained in a few past lags ofthe key variables.
The
model
(3.4)can
typicallybe
solved recursively to eliminate/i,yield-ing nonlinear
dynamic
functional forms,which
canbe
used in a usualnon-linear estimation.
One
example
involvesthemodel
f
1(X
u
p)=
a(Y
t-fH
\X
t), (3.5)where
o-2(yt
—
Ht\Xt) is the conditional variance ofthede-meaned
return. It can, for example, take theform
of aGARCH
model
(seeKoenker and
Zhao
(1996) for discussion). In practice, a simple strategy to accommo-datea
model
like (3.4) -(3.5) into a linearframework
is to first estimatea(yt
—
fJ-t\Xt ) via aGARCH
model and
use it as a regressor in the earlierlinearmodel:
X
t=
{X't,a(y
t-
Ht\X
t))''Of
course,thattheregressorisesti-mated
can beaccommodated
intheinference analysis or, alternatively,canbe
ignored for all practical purposes. In the empirical sectionwe
will notmake
use of the recursivity, sincewe
aremore
interested in theeconomic
determinants ofrisk, butmost
oftechniques discussed next applyboth
toConditionalValue-at-Risk: AspectsofModelingand Estimation 9
In
summary,
it isimportanttostressthatthe conditional quantilemodel
imposesno
strong assumptionsabout
the distribution function oftheun-derlying error term. This underscores the semi-parametric, flexible nature
ofthe conditional quantile models,
which
could be valuable tomodel
themarket
risk.4
Estimation/Inference
This section reviews
some
recent resultson
estimationand
inference. Sec-tion4.1 reviews regularasymptotic estimationand
inferenceinthequantile regression literature. Section 4.2 reviews results ofChernozhukov
(1999a)on
estimating highand
low (extremal) regression quantiles.4-1 Estimation
and
InferenceThe
ConditionalVaR
function, vt(p), is parameterized as m(Xt,/3(r),T), which, in our empirical setting, takes the linear-quadraticform
X^P(t).Hence
we
willdiscussthiscaseonly(tokeep notationsimple).The
nonlinearcaseis similar-just replace
X
tby
thederivativedm{X
t,P,T)/d(3\j}^,and
Xtfbym(X
t,(3,T).The
sample
analogueofmoment
conditionsthatdefinethequantilefunc-tion,integrated with respect to(3(t) yieldsthequantile regression objective
function
Qt
(Koenkerand
Bassett, 1978). /3(t) isdenned
astheargmin
ofQr-P(t)
=
argmin
fi
[q t
(P,t)=
£
p
T{vt~
X
t/3)] (4.6)t
where
pT(x)=
tx~
+
(1—
t)x +. For a givenr, \/T((3(t)—
/3(r)) isasymp-totically
normal
undergeneraldependence and
heterogeneity,9and,further-more, the regression
VaR
coefficientsconvergeto aGaussian
process G(-),10 asfunctionsofr11
JT{K-)
-W)
=>G(-).
(4.7)9
See e.g. Portnoy (1991), Fitzenberger (1998), Weiss (1991) (nonlinear cases),
Koenker and Zhao (1996).
10
See Portnoy (1991) and also theresults in Chernozhukov (1999b) that allow
for non-linear specifications and variousforms ofdependent data.
11
Here => denotes weak convergence in £°° - see e.g. van der Vaart and
Well-ner (1996). G(-)
=
J"
:(l
-
-)GP f{W,), f(W,r)=
(1(7<
X'/3{t))-
t)X,
andInferenceisfacilitated
by
estimating appropriate variance-covariance matri-cesby
a moving-blockbootstrap (Politisand
Romano
(1994), Fitzenberger(1998)).
Test Processes
and
their FunctionalsTesting is discussed in detail in e.g.
Koenker and Portnoy
(1999)and
Weiss(1991).Koenker
and
Machado
(1999)and
alsoChernozhukov
(1999b) studyseveralformsoftestsand
testprocesses(teststatisticsviewedas func-tionsoft).These
test processes are variants ofWald,
Score, quasi-LR,and
specification test statistics,
viewed
as functions ofr
inan
intervalV
(e.g.V
=
[.1,.9]).The
quasi-LR,Wald,
and
rank-score test processes arein-troduced
and
studied inKoenker and
Machado
(1999) in the context ofindependent data
and
linear functional forms.These
test processes, as wellas
some
of their alternatives, are studied inChernozhukov
(1999b),un-der conditions of
dependence and
nonlinearities. Test processes areshown
to be asymptotically distributed as quadratic formsof
Gaussian
processes (P-Bessel Processes),and
each coordinate ofthe test statistics isasymp-totically distributed as chi-squared. Bootstrap inference is also discussed
there.
The
specification test process is introducedChernozhukov
(1999b).The
coordinates Sc{t) ofthe specificationtest process Sc(-) are defined asquadratic formsofthe usual specification test statistic ( such as
gmm-like
overidentification statistics or statistics like those in Bierens
and
Ginther(1999)).
A
simple, practical version defines Sc(t) as a quadraticform
oft
Stli [Wvt
—
X'
tf}{r))-
r)Zt],where
Z*'s are functions ofX
t or otherinformation variables (other
than
Xt).The
specification test process con-vergesweakly
toa generalizedP-Bessel process.By
selecting variousformsof Zt one can check:
—
conditionality-
abilitytoincorporateallrelevantpastinformation (withZt equal topast information variables)
—
functionalform
validity (with Zt equal tovarioustransforms of Xt).exactly a P-Brownian Bridge -cf. vander Vaart and Wellner (1996), whose
dis-tribution is defined by the finite-dimensional normal distributions and the
co-variancekernel
CV(f(W,n),f(W,
r,))=
limr-»<x>£
£f=i E(/
{W
t,n)f(W
t,r,)')+
ZLiHfCWt+k^fiWt,^)' +f(W
t,Ti)f(W
t+k,Tjy] ; and finally, J(t)is a fixed non-stochastic invertible matrix J(r)
=
limT-Kx>^
2t=i E
[fyt
{F~
t l{T\Xt)\Xt)XtX't]. Note that (4.7) is very succinct statement,
conve-niently characterizing thedistribution. For example, (v/
T(/3(tj) —f3{Ti), j
=
1,...I)converges in distribution to N(0,A), whereij-th blockAij
=
A'ji ofmatrixA
isVarious functionals of these processes
form
test statistics that enablesi-multaneous
testson
all t€ V.
For example, supTg.pSc(t) forms aglobalspecification test of the
Kolmogorov-Smirnov
type. Itexamines
validity of the functionalform
ofthe conditional quantile functionforallr inV
simul-taneously.12Simpler versions ofthe (pointwise) conditionality tests (that disregard thatP(t) is
an
estimatedquantity) canbe
constructedby
regressing(l(yt<
X[(3{t))
—
t)on
the lagged values ofitselfand
other informationvariables,and
then checking if the regression coefficients are zero.These and
othertestsaresuggested, toevaluate
VaR
models,by
Lopez
(1998), Christoffersen(1998), Crnkovic
and
Drachman
(1996), Diebold, Gunther,and Tay
(1998),Engle
and
Manganelli (1999),among
others.Such
proceduresoffer agood
simpleway
to quicklycheckifa givenVaR
model
ismore
or lessplausible.Lopez
(1998) offersavaluable detailed discussionon
thecriteriawithwhich
VaR
models can
be evaluated.Definitions of the Test Processesfor the EmpiricalSection
Inthe empirical section
we
compute Wald,
integratedWald, and
quasi-Scoretest processesat a sequenceof values of
p
inordertotestthehypoth-esis:
H
:Pi(t)=
0,where
f3=
(Po(t),Pi(t)')'»an
dA)(T) istneinterceptparameter. HypothesisH
statesthat the coefficientson
all conditioning variables are zero. IfH
istrue, it
means
that conditioning is statistically irrelevant.To
define these tests denote the constrained quantile regressioncoeffi-cient as J3
r
(t)=
arginf/3Qt(P,t)
s.t. /3i(t)=
0.Then
define theWald
Given the stochastic equicontinuity of the test processes, their distribution
can be approximated via finite subnets ofthe processes evaluated at thegrid of
equi-distant quantile indices {n,i £ 1,...K} for
K
sufficiently large. Thismeans
thatonly afinite
number
ofevaluations shouldbeconsideredtoapproximatewell, e.g.supT6.pSc(t) viasupTi Sc(n).Iftheapproximationerroristo vanish,
we
needand
Score testprocesses13:w(-)
=
t0
r
(.)-
p(-)yn
1T(-)0
R
(-)-
/?()),S(-)
= Tv
Q
T
R
(-),.)'n2T(.)vQ
T
R(-),).The
specification test process, as a function ofr, is definedas:1
T
Sc(-)
=
MO'rtsHOM-),
w
here /xr
(r)=
—
=£(l(y
t<
X[(3{r))-
r)Z
tv
-* t=iThe
specification test, as stated earlier, checks the validity of the given functionalform, as well asthe conditioning ability.144-2
Near-Extreme
Regression Quantiles(VaR)
While
the regular asymptotics iscertainly useful in alargesample
for non-extremal regression quantiles, amore
cautiousapproach
is needed todis-tinguisha separate kindof inference for near-extreme (extremal) regression quantiles,asdeveloped in
Chernozhukov
(1999a).What
followssummarizes
some
oftheseresults. Intuitively,thesample
quantile regressionisamethod
of generalizing thenotionoforder statisticstotheregressionsettings.
Cor-respondingly, for
any
givensample
size T, the r-th regression quantile fitcan
be seen as therT-th
conditionalorder (or rank) statistic.Depending
on
this rank, asymptotic approximationsreflect the extremal or rare dataconsiderations.Indeed, consider a simple
example
withno
covariates.A
.01-th quantile estimator in the
sample
of 100 isthe first order statistics,and
13
(a)
How
tochoose Oit, &2T, andQzt
?Each
ofthe testsprocessesisoftheform wt{t)' f2T{r)wT{r). For anyr, Qt(t) is chosen to be an inverse ofa
con-sistentestimatorofthe asymptotic varianceofwt{t).
One
caneither exploittheanalyticalexpressionsforthese variances (asdiscussedinChernozhukov(1999b))
or, as employed in the empirical section, use a moving-block bootstrap to
esti-mate
them.The
procedureisquite simple: usingsuchformofbootstrap,compute
statistics u)6t(t~) (for b
=
\,...B denoting the bootstrap replications, settingB
large).
Then compute
the variance matrix ofthe "sample" {wbT{i~),b—
1,...B}.(This procedure is consistent under the local alternatives, since then only the asymptotic
mean
ofwt{t) isshiftedandvarianceisunaffected.) (b) V/sQrmeans
^
E
t6yPAYt
-
Xi${T)), /=
{« :Yi#
X'J(r)}.14
In the empirical section
we
give the specification test process for the linearmodelwith
Z
tselected tobethe polynomial formsofX
t That is,we
havedevotedourattention tothe first problem. However, one can check the conditionality by
hence
one would
expect that regular asymptotic approximation does not apply here, butsome
other asymptotic theorydoes. Similar considerationsapplytoregressionsetting. Indeed, datascarcityis amplified
by
thepresenceof covariates.
To
that end, the concept ofeffective rank is useful. Effective rank,r, is the ratioofrank k= tT
(ift<
1/2,and
(1-
t)T
ift>
1/2 )tothe
number
ofregressors, k/d.To
motivate such anotion, considerthe"re-gression" quantile
problem
inasample
of1000 observationsand
10dummy
regressors, in
which
thetarget is the .01—
th conditional quantile function.The
constructed estimates ofslopes will be the 1-st lowest order statistics ineach of 10subsamples
corresponding to thedummy
variables.Hence an
extremal situationstill applies here.Let us
now
distinguishtwo
formal asymptoticconsiderations/statisticalexperiments that account for the data scarcity illustrated above. (In the
sequel,
we
alwaysassume
r<
1/2. Replace tby
(1—
r) ifr>
1/2):(i)
t
—
> 0,tT —
> oo (intermediaterank
behavior, or r is relatively low ascompared
tothesample
size),(ii)
t
—
» 0,tT
—
> k (extremerank
behavior, or t is very low ascompared
tothe
sample
size).Both
(i)and
(ii) intend to asymptotically captureforms
ofdatascarcity arisinginthe tailsofdistribution.Both
can beapplied forany
given quantileindexofinterest in a fixeddataset,
and
thesenotionsgiverisetoalternative inferencetechniquesthat can be appliedwhen
dealingwiththeextremalre-gression quantiles (VaR). Intuitively,these alternative inferenceapproaches should
perform
betterforthenear-extremeregression quantilesthan
forthecentral ones. Intheempirical section, thesealternative techniques areused
to construct the confidence intervals ofthe regression quantile coefficients.
A
"rule-of-thumb" choice ofthe (more) appropriateapproximation
theoryforinference purposesisas follows: ifr
<
10, onemay
selectmethod
(ii) (asillustrated inthe
example
above), ifr€
(10,25)-method
(i),and
ifr>
25-
the regular or central asymptotic approximations (previous subsection).A
briefdescription ofthe asymptoticsunder
(i)and
(ii) follows next.Assume
that the conditional distribution function ofyt—
X[(3{q) (q=
1/2 or 0) is tail-equivalent to
some
functionK(x)F
u(-), 15where
F
u is adistribution functionwith the extremaltail types.
We
say thatcdfF\ is tail-equivalenttocdfF2 at (saythe lower) end-point x, ifasz\
x,F\{z)JFi(z)—
>1.14 Victor Chernozhukov, Len
Umantsev
In thecase (i), the asymptoticdistributions are normal, but the
covari-ance
matrix depends on
the tail index: (forany
m
> 0,m
^
1)where
Q™
=
limT
£
Ef=i
EX
tX[,Q
n
=
limr
j,£
tT
=1
EX
tX[/U{X
t), Z isthe tail index of
F
u, 7i(x) issome
function ofx
thatdepends on
the tailtype of
F
u,and
\ix
= hm
r
^
Z!t=iEX
t. Furthermore, /j.'x
(/3(m,T)-
/?(t))can
be replacedby
X
(/3(mr)-
/3(r)), without affectingthevalidity oftheresult.
We
do
not state theexplicit forms here sincetheresult is used onlyindirectlytojustifytheresampling techniques(thatwill
be
usedtoconstruct the confidence intervals inthe empirical section- see the next section).In the case (ii), the asymptotic distributions are defined
by
arandom
variable that solvesastochastic optimization problem,
where
theobjective function isan
integral w.r.t. aPoisson point process:a
T
(/?(r)-
(3(r))A
c(k)+
arginf [-
k^
x
z+
J
(j-
x'z)-<IN(j, x)where
N
is a certain Poisson Point Process.The
mean
intensity function ofN,
constants c(k),and
scalingar
depend on
the underlying tail typeof
F
uand on
the tail heterogeneity functionK(x).
Again,we
do
not statethe explicit forms here since the result is used only indirectly to justify
the resampling techniques (that will be used to construct the confidence
intervals in the empirical section- seethe next section).
Furthermore,
Chernozhukov
(1999a) definesand
studies inference pro-cessesanalogoustothoseintheprevioussection16and shows
how
toconductinference
by
asymptotic orresamplingmethods.
In particular, estimatesoftail index £, 17 tail heterogeneity function
K(x),
and
scaling constantsax
16
Construction of quantile and inference processes is done by introducing an
indexI inaset [Zi, Z2], sothatprocess
or
1(3(t-)—
(3(r)I isa functionofI, etc. 17A
simple rule-of-thumb estimator for the empirical section is deduced fromthefollowing relationship
^
j T*l7 -1 /
m
~
^
—
> *' as T^
—
> oo,t\
( butmore
sophisticated estimators can beconstructed -see (Chernozhukov, 1999a)).Sothat
£l \ 1
X0(mr)-p(r))
„
£(m,t)
=
—
In—
—
^——
i—^i—[nm
X(P{t)
-
(?(rm-'))'In practice
m
shouldnot besettoo faraway from 1. E.g.in theempirical section,we
usedm
=
.75,m
=
1.25, and various values oft s.t. r, the effectiverank, isbetween 10 and 20.
We
thentook the median of{£(mi,Tj)} over all suchvalues ofmi
and Tj toobtain thefinal estimate£.are offered,
and
the validity ofsubsampling
is established. Alternativere-gression quantile estimators
emerge from
these results. For example,a
re-gression quantileextrapolationestimator18 is constructed as follows (for re
close to zero
and
r not close),and any
positive constantm
^
1:M/.uJ
T
eA)-
{-l
Fy-^Telx)
x'0{rnr)
-
P{t))+
x'$(tm-« -
1This also implicitly defines the extrapolation quantileestimates for (3{re) .
5
Empirical
Analysis
This section considers estimating the
VaR
of the OccidentalPetroleum
(NYSE:OXY)
security returns.The
dataset consists of2527
daily obser-vations19on
—
?/4, theone-day returns,—
Xt, a vector of returns (or prices, yields, etc.) ofother securities thataffect distribution of
Y
tand/or
lagged values of yt itself: a constant,lagged one-day returnof
Dow
JonesIndustrials (DJI), the lagged returnon
the spot price of oil(NCL,
front-month contracton
crude oilon
NYMEX),
and
the lagged return yt.Generally, to estimate the
VaR
ofa stock return,Xt
may
contain suchvariables as a
market
index of corresponding capitalizationand
type (forinstance,the
S&P500
Value
foralarge-capvaluestock),the industryindex,apriceof
commodity
orsome
othertradedrisk thatthe firmisexposed
to,and
lagged values ofits stock price. It is also conceivable to includesome
unobserved
factors, suchasSize,Value,Momentum,
orLiquiditypremiums,
whose
effecton
stockreturnsand
riskhasbeen
a subject ofnumerous
stud-ies.
However,
we
chose notto includeestimated variablesin theinformationset forthe sakeofsimplicity.
Functional
Forms
of
Conditional Quantile Functions
Two
functional formsofconditionalVaR
were
estimated:• Linear
Model
: v£(p)=
X[
6(p), • Quadratic Model: wth(p)=
X'
t8{p)+
X
tB{p)X'
t.18
Thisis adirect regression analogueoftheestimator ofDekkers and de
Haan
(1989) thatwas suggested for non-regression cases.
19
Conditional
Risk
Surfaces
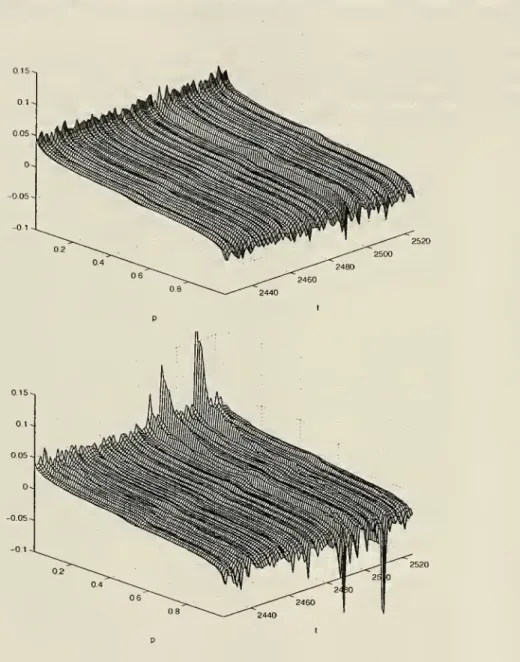
Figure 1 presents surfaces ofthe regression
VaR
functions plottedinthe time-probability level coordinates, (t,p). Recall thatp
is called theproba-bility levelof
VaR, and
r=
1—
p
is the quantile index.We
reportVaR
for all values of
p £
[.01, .99].The
conventionalVaR
reporting typically involves the probability levels ofp
=
.99and
p
=
.95. Clearly, thewhole
VaR
surfaceformed by
varyingp
in [.01,.99] represents amore
completedepiction of conditional risk.
Note
also that sinceone
can beeither longor shortthe security,estimation ofVaR
inbothtailsofthereturndistributionis ofinterest.
The
dynamics
depicted infigure 1unambiguously
indicate certaindateson which market
risk tends to bemuch
higherthan
its usual level. Thisby
itselfunderscores the
importance
of conditional modeling.We
also stressthatthe driving force
behind
thedynamics
is the behavior ofX
t.Model
Comparison
Figure 1 also
compares
thedynamic
evolution of the linearand
thequadratic
VaR
surfaces. Notably, the quadraticmodel
predicts higher riskmagnitudes than
thelinear model. Indeed, thefluctuations of thequadraticVaR
surface are significantlylarger.The
linearmodel
thus predicts amore
"smoothed
out"VaR
surface.Conditional Quantile
and
Quantile
CoefficientFunctions
The
nextseriesof figures presentsthestatistical aspectsoftheanalysis.For brevity,
we
choseto present the results in agraphical form.20Let ussetthedate at t
=
2500toanalyze theVaR.
Figure2depicts theestimated
VaR
2soo{p) for values ofp
inthe interval [.01, .99].21 This figurealso
shows
the95%
confidenceintervals (c.i.) obtainedby
the following pro-cedures:22 (1)regular inference,basedon
theasymptoticnormal
approxima-tion (labeled as "asymptotic"), (2) resamplinginference,
by
the stationarybootstrap, that is valid
under
regularand
intermediate rank asymptotics,and
(3)and
(4):subsampling
inference with different scaling schemes,de-notedas
"Subsampling
I"and "Subsampling
II," suitedfordependent
data,and
validunder
theextreme
rank asymptotics.Method
(1) is intended to20
We
have not presented here the formal statistical analysis ofthe quadratic
modelfor brevity.
Umantsev
and Chernozhukov(1999) offeradetailed analysis ofthe quadratic model.
21
We
computed
VaR(-) and coefficients forvalues ofplyingon agrid with cell size .01andinterpolatedinbetween.Thisisajustifiableinterpolation sinceVaR(-)and coefficient processes are stochastically equicontinuous.
22
givethe confidenceintervalsthat are bestforthecentral values
p
£ [.1,-9],method
(2) - forthe intermediate (near-extreme) values,p
€ [.04,.96],and
methods
(3)and
(4)- for theextreme
valuesp
<E (0, .04]and
[.96, l).24As
can
be seenfrom
figure2, thec.i.by
methods
(2), (3),and
(4) tendtobe roughly 1.5, 2,
and
2.5timeswiderthan
thestandardc.i.,respectively.Hence
additional significant estimation uncertainty is present in the tails,and
it is importantto properlyaccount forit.Accounting
foritmeans
that,within the c.i. by
methods
(2)- (4), near-extremeVaR
may
actually be asmuch
astwo
times higherthan
thepointestimates suggest.Figures 4-5 present the
same
analysis for the coefficient functions 6(-)ofthe linearmodel.
The methods
and
the resultsemployed
are like thosewe
havejust discussed.We
will givean
economic
meaning
tothe coefficientshapes later.
Specification
Analysis
Figure 6 presents the pointwise values of
Wald
and
quasi-Score teststatistics for testingthe hypothesis:
—
Is theconventional (unconditionalhistorical)VaR
model
statisticallynotdifferent
from
the conditionalVaR
model?
The
answer
isconclusive:the hypothesisis rejectedpointwise.Note
that the'p-values'25 forthiscase areallsmallerthan
0.01.That
is,the regression conditioning matters.Thiscanalsobe
seeninfigure4,where
theconfidenceintervals ofslope coefficients are plotted
throughout
the interesting rangeof
p
-these confidenceintervalsexclude 0s.Figure 6 (right) also depicts the specification test process (see earlier
section). Resultsofthe specification testingareclearly infavorofthe linear
model: the critical value (pointwise) for
10%
level is 6.25,which
isabove
Based on Monte-Carlowith thesamplesizeof1000 andthe considerationsof
the previoussection.
In this application, for transparency and clarity, the subsampling methods
wereoperationalized by assumingthetails areexactly algebraic, sothat therate ofconvergenceor divergence is ar
=
T~*. £ wasestimated to beapproximately.25 by the
method
described in the previous section. Hencear
=
T~'25 definedascalingfor thesubsamplingprocedure.
As
suggestedin Chernozhukov (1999a),the centering constant was taken to be J3T{k/b).
The
subsample size b was setto be1/10 ofthe whole sample T.
The
resulting confidenceintervals are labeled"SubsamplingII." For comparison,rateaT
=
T
01wasalsoused,andtheresultingconfidence intervalswerelabeled as "SubsamplingI." 25
any
of the values depicted. Obviously, since the critical value for the teststatistic
sup
T6[001j 99j5c(t) should be
above
6.25, the linearmodel
passesthisstronger
Kolmogorov-type
test, too !The
Determinants
of
Risk
We
now
provideboth
a statisticaland an economic
interpretation ofthe coefficient functions #;(•). Let us fix time period t
=
2500and suppose
for a
moment
that 9i(p)>
forsome
i>
0,p6
(0,1).As
VaR
t(p)=
vt(p)
=
0o(p)+
J2i9i(p)Xt,i, a positive coefficient in front ofX
t ,i impliesthat higher values of
X
tji correspond to higher values ofVaR
t(p), giventhat other elements of
X
t areunchanged.
Stated differently, if6i(p)>
0,then increases (decreases) of
Xt
ti are associated withupward
(downward)
shifts of
VaR
t{-) at pointp.Note
thatVaR
t(-) is the "reversed" inverseofthe
cdioiy
t\X
t, i.e.F'^l
-
-\Xt) [Take figure3 (middle)and
rotate it90°clockwise togetthe conditional cdf.].
Thus
positive shocksinX
t ,ishift thecdf
F
yt(-\Xt ) tothe right.Similarly, if9i(p) is negative, effects ofpositive
and
negative shocks inthe i th
information variable are reversed: positive shocks
move
VaR
t{p)down
and
cdf ofyt\X
t totheleftand
negative shocksmove
VaR
t(p)up
and
cdf ofyt\Xt tothe right.
The
effectsdescribedabove
arelocal,inthe sense that theyaffectVaR
t(•)and
F
yt(-\Xt ) onlylocally,around
pointsp
and
F'^l
—p\X
t), respectively.Transformations of these functions at other points caused
by
such shocksdepend on
the signand magnitude
of9i{p) at otherprobability levelsp.Suppose
next that 9 is positiveand
decreasing in the right tail ofdis-tribution of yt\Xt (e.g. #i(-)
on
(0, .2), see figure 4).A
positive shock inXi
willnow
shift the entire right tail ofcdf ofyt\X
t to the right,and
theeffect will be greater for
extreme
points (those close top
=
0), atwhich
9i(p) is higher.
The
effecton
the density ofyt\X
t is schematically depictedin figure 7. Thus, this particular
shape
of6>i(-) implies that positiveshocksofthe corresponding informationvariable result in the righttail ofdensity ofyt\Xt being stretched further tothe right
(more
positiveskewnessin theright tail).
A
similarshape
is observed for the coefficient function^(p)
foralmost allvalues ofp.
Thus, the shapesof0j(-)suchas#i(-)or^(-)infigure4 translate positive
shocksofthecorresponding informationvariables into the longer righttails
(favorable for holding long positions in Y).
On
the other hand, shapes of9i(-) similarto those of6>3(-) in figure4 translate such shocks into shorter
Finally,
we
provide theeconomic
interpretation of the slope coefficientfunctions#i(-), #2(')i ^3(
-)> correspondingtothe laggedreturns
on
oil spotprice,
Xi,
equity index,X2, and
priceofthe security inquestion,X3.
—
9\(-) is significantly positiveand
decreasing in the right tail ofthedis-tribution ofyt\Xt (figures 4
and
5,p
<
1/4). It is insignificantlypositivein the middle part (for
p
€
(.25,.95))and
then it is increasing in thefar left tail (p
>
.96), although values Q\(p),p
>
.96, are not as highas those for
p
<
1/4. This suggests that the Spot price of Oiland
the returnon
our stock are positively related, with the right tail of equityreturn being
much
more
sensitive to Oil price shocks, than the left tail.This effectcan be explainedby, for example,realoptionalityintrinsicto
the operation of the firm, or
by
a non-linear hedging policy (e.g., longpositions input options instead of
swaps
or futures,whose
payoffislin-ear in the underlyingprice
movements).
The
overalleffect ofapositiveshockin thespot oilprice
X\
is presentedin figure 7.—
#2(-)>
m
contrast, is significantly positive for all values ofp
with thepossibleexception ofthe far right tail ofyt\Xt, (p
€
(0,0.04)).We
alsonoticea
moderate
increaseintherighttailand
asharpincreaseinthelefttail(p closeto1).Thus,inadditiontothestrongpositiverelationbetween
the stock return
on
the individual stockand
themarket
return (DJI)(dictated
by
the fact that #2(-)>
on
(0,1)) there is also additionalsensitivity ofthe lefttail ofthe securityreturnto the
market
movements
(steep increase
on
(.94, 1)),which
is strongly consistent with the notionof highly correlated equity returns in
market
drops. For high positive returns,incontrast,market
returnhas amuch
weaker
effect (lowvalueson
(0,0.04)).The
effect of positive shock in themarket
return (X2) isdepicted in figure7.
—
#3(), in contrast, issignificantlynegative, exceptforvalues ofp
closeto0. This
may
be clearly interpreted as a"mean
reversion" effect in thecentral part of the distribution.
However, X3,
the lagged return, does notappear
tosignificantly shift thequantile function inthetails.Thus
X3
ismore
importantforthe determination of intermediaterisks(values ofp
in [.15,.85]).The
effect ofa positive shock inX3
is schematically portrayed in figure 7. Figures 4and
7 also capture theasymmetry
ofresponse tothenegative
and
positive return shocks- apositiveshockleadsto
mean
reversionand
intermediate risk contraction, whereas a negativeNote
thattheestimates ofnear-extremeVaR
should beinterpretedcare-fully, sincethe point estimates provided
by
regression quantiles are highly biased in the tails.Some
correction can be achievedby
using alternativeestimators that usethe regular variation properties oftailsin order to con-struct regression-likeestimates ofthe near-extreme
VaR
(seeprevioussec-tion). For example, asdepicted inFigure 3, the regression extrapolation
es-timatorintroduces a significant correction, but within the confidence
bands
constructedby
method
(4). Further conclusionsare stated insection 1.Fig. 1 VaR,(p)for Linear (upper)and Qudratic (lower) Models (
VaR
t{p) isone2 a 3 a-a o 1-1 "0 a 1 in II
'M.
Fig. 4 Estimates and
95%
(Pointwise) Confidence Intervals for 6> (-),24 VictorChernozhukov, Len
Umantsev
_r ' /'' /// '" v_l^ // / // ' OS / ' /// '/ -— /'' /// ''/ c 1—
/' /// '/ 3 V£S /,' I// ' '. " ' //I''/ c ^b J/ / / / ' / t-t '/' / / / '/' o ' /' / / / / CO ' / // / / ' nt >''/////'
= S-. IU G''/////'
' 1—4 ' ' /////' 1 Q> ' 'If
' U C ' 1111i i ' CD -n 1 (111i i ' <c ' 1111i ' i a ' 1i111 > o ' 1111j i-U
'III''
l *S ' ///// ' ' >n /// // ' ' ailllll
' -o ,////,/,', . , E : Io J3 I a CM o in <B O Ph J3 tf 5e o
References
Ait-Sahalia,Y.,
and
A.W.
Lo
(1998): "NonparametricRiskManagement
andImplied Risk Aversion," preprint.
Bassett, G.,
AND
H.Chen
(1999): "Quantile Style: Quantiles to AssessMu-tual
Fund
Investment Styles," aWorking
Paper,Presented at theInternationalConference on
Economic
ApplicationsofQuantile Regression, Konstanz, 2000.BASSETT, Jr.,
C,
and
R.Koenker
(1978): "Asymptotictheoryofleastabsoluteerror regression," J. Amer. Statist. Assoc, 73(363), 618-622.
BlERENS, H.,
AND
D. K.GlNTHER
(1999): "IntegratedConditionalMoment
Test-ing ofQuantile Regression Models," a
Working
Paper,Presentedat theInterna-tional Conferenceon Economic ApplicationsofQuantileRegression, Konstanz,
2000.
Campbell,
J., C.MacKinlay,
AND
A.Lo
(1997): Econometrics ofFinancial Markets.MIT.
CHERNOZHUKOV,
V. (1999a): "Conditional Extremes and Near-Extremes,"November, Ph.D. dissertation draft, Stanford.
(1999b): "Specification and Other Test Processes for Quantile
Regres-sion," August, a
Working
Paper, Stanford.CHRISTOFFERSEN,
P. (1998): "Evaluating Interval Forecasts," InternationalEco-nomic
Review, 39(4), 841-862.CRNKOVIC,
C,
AND
J.Drachman
(1996): "Quality Control," Risk, 9(9),138-144.
DEKKERS,
A.L. M.,AND
L.DE
Haan
(1989):"On
the estimationofthe extreme-valueindex and largequantile estimation," Ann. Statist., 17(4), 1795-1832.Diebold, F. X., T. A.
Gunther,
and
A. S.Tay
(1998): "EvaluatingDen-sityForecastswith ApplicationstoFinancial Risk Management," International
Economic
Review, 39(4), 863-883.Engle,
R. F.,AND
S.Manganelli
(1999):"CAViaR:
Conditional AutoregressiveValueatRiskbyRegressionQuantiles,"
UCSD
Economics Deaprtment Working Paper99-20 , October.FedReg
(1996): Risk-basedcapitalstandards: MarketRiskvol.61.FederalRegister.FlTZENBERGER,
B. (1998): "Themoving
blocks bootstrapandrobustinferenceforlinear leastsquares andquantile regressions," J. Econometrics, 82(2), 235-287.
HEILER, S.,
AND
K.ABBERGER
(1999): "ApplicationsofNonparametricQuantile RegressiontoFinancialData," aWorking
Paper, Presentedat theInternationalConferenceon
Economic
ApplicationsofQuantile Regression, Konstanz, 2000.Hogg,
R. V. (1975): "Estimates of Percentile Regression Lines Using Salary Data," J. Amer. Statist. Assoc, 70(349), 56-59.KOENKER,
R.,AND
G. S.Bassett
(1978): "RegressionQuantiles," Econometrica,46, 33-50.
KOENKER,
R.,AND
J.Machado
(1999): "Goodnessof Fit andRelatedInferenceProcessesfor Quantile Regression," preprint.
KOENKER,
R.,AND
S.PORTNOY
(1997): "The Gaussian Hare andthe LaplacianTortoise," Statistical Science, 12, 279-300.
KOENKER,
R.,AND
S.PORTNOY
(1999): "Regression Quantiles," preprint.KOENKER,
R.,and
Q.Zhao
(1996): "Conditional quantile estimation andinfer-encefor
ARCH
models," Econometric Theory, 12(5), 793-813.LOPEZ, J. A. (1998): "Regulatory Evaluation ofValue-at-Risk Models," Journal
of Risk, 1(2), 37-63.
POLITIS, D. N.,
and
J. P.ROMANO
(1994): "Thestationarybootstrap," J. Amer.Statist. Assoc, 89(428), 1303-1313.
PORTNOY,
S. (1991): "Asymptoticbehavior of regression quantilesinnonstation-ary, dependentcases," J. Multivariate Anal., 38(1), 100-113.
RESNICK, S. I. (1987): Extreme values, regular variation, and point processes.
Taylor,
J. (1999): "A Quantile Regression Approach toEstimating theDistri-bution ofMulti-Period Returns," J. Derivatives, Fall, 64-78.
Umantsev,
L.,AND
V.CHERNOZHUKOV
(1999): "Polynomial Regression QuantileModelingof Risk," September, a
Working
Paper, Stanford.VAN
DER Vaart,
A.W.,
AND
J. A.Wellner
(1996):Weak
convergence andempirical processes. Springer- Verlag,
New
York.Weiss, A. A. (1991): "EstimatingNonlinear