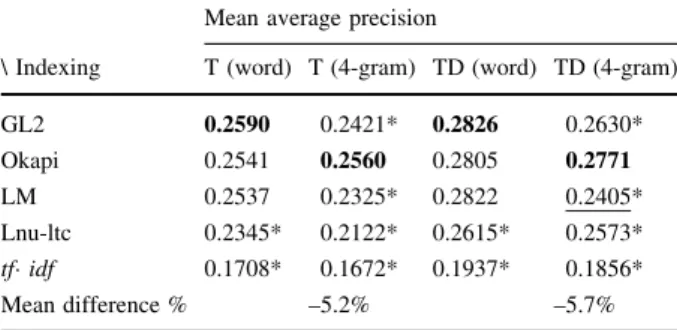
Searching strategies for the Bulgarian language
21
0
0
Texte intégral
Figure

+7


Documents relatifs
