https://doi.org/10.4224/9174792
READ THESE TERMS AND CONDITIONS CAREFULLY BEFORE USING THIS WEBSITE.
https://nrc-publications.canada.ca/eng/copyright
Vous avez des questions? Nous pouvons vous aider. Pour communiquer directement avec un auteur, consultez la
première page de la revue dans laquelle son article a été publié afin de trouver ses coordonnées. Si vous n’arrivez pas à les repérer, communiquez avec nous à [email protected].
Questions? Contact the NRC Publications Archive team at
[email protected]. If you wish to email the authors directly, please see the first page of the publication for their contact information.
Archives des publications du CNRC
For the publisher’s version, please access the DOI link below./ Pour consulter la version de l’éditeur, utilisez le lien DOI ci-dessous.
Access and use of this website and the material on it are subject to the Terms and Conditions set forth at
NRC-IIT's ILT Group at the Cross-Language Evaluation Forum
Nadeau, David
https://publications-cnrc.canada.ca/fra/droits
L’accès à ce site Web et l’utilisation de son contenu sont assujettis aux conditions présentées dans le site LISEZ CES CONDITIONS ATTENTIVEMENT AVANT D’UTILISER CE SITE WEB.
NRC Publications Record / Notice d'Archives des publications de CNRC: https://nrc-publications.canada.ca/eng/view/object/?id=e6271d66-2145-47bc-bca4-d7223ed9edc9 https://publications-cnrc.canada.ca/fra/voir/objet/?id=e6271d66-2145-47bc-bca4-d7223ed9edc9
Institute for
Information Technology
Institut de technologie de l'information
NRC-ILT at the Cross-Language Evaluation
Forum *
Nadeau, D.
December 2004
* published as a Technical Report, 2004. December 2004. NRC 48080.
Copyright 2004 by
National Research Council of Canada
Permission is granted to quote short excerpts and to reproduce figures and tables from this report, provided that the source of such material is fully acknowledged.
Institute for
Information Technology
Institut de technologie de l’information
© Copyright 2004 by
National Research Council of Canada CLEF 2004
NRC-ILT at the Cross-Language Evaluation Forum
David Nadeau, National Research Council Canada
Table of Contents
Abstract ... 3
Notation... 4
1 Introduction... 5
2 The CLEF Conference ... 6
2.1 CLEF Tasks... 6
2.2 CLEF Participant Strategies ... 7
2.2.1 Information Retrieval Strategies ... 7
2.2.2 Translation Strategies... 7 3 Sbire’s Architecture ... 10 3.1 Input Parameters ... 11 3.2 Input DNA ... 11 3.3 Execution Sequence ... 12 3.4 System output ... 13
4 Commercial Off-The-Shelf Search Engines ... 16
5 Query Terms Selection... 18
6 Query Construction ... 20
7 Query Expansion... 23
8 Query Translation... 24
9 CLEF 2004 ... 26
9.1 More on Judges Work ... 26
9.2 Monolingual and Bilingual Tracks... 26
9.3 Invited Lecturer: Issues when building a system for CLEF... 27
9.4 Image & QA tracks ... 28
9.5 Breakout session... 28
9.6 Final Note ... 28
10 Conclusion... 29
11 Acknowledgement ... 29
Abstract
This technical report is an extended version of the article “Using COTS Search Engines and
Custom Query Strategies at CLEF” (Nadeau et al., 2004) published in the proceedings of CLEF
2004. It presents Sbire, a system for bilingual information retrieval using commercial off-the-shelf search engines (COTS).
The development of Sbire was motivated by a participation in the CLEF evaluation. For this reason, some development presented in this report cannot be applied to a real-word cross-language information retrieval. For instance, we present how to build a query from a textual topic and this “query construction” step is done by the user in a real-world IR system.
The report emphasizes on our experiments in the CLEF environment as well as on the final Sbire architecture. It is mainly intended for developers of cross-lingual information retrieval system that aspire to participate in CLEF or similar events.
Notation
Code will be in the “Courier New” font, using gray shading. The programming language will be specified at the beginning of the code in squared brackets.
Ex.:
[Java]
Boolean variable = Class.Method();
Here’s the legend of the functional diagram:
Symbol Description
Data repository (ex.: database, folder …)
Decision (ex.: which year, which language …)
DNA (genetic algorithm parameters)
General module (ex.: a seach engine)
1
Introduction
This report presents Sbire, a bilingual information retrieval system. Cross-lingual IR systems are useful to search and consult information in a foreign language (e.g. search a repository of Chinese text with English queries). Sbire is specifically designed to participate in the CLEF evaluation. Typically, the CLEF task consists in creating a query from a topic in a given language (query construction), sending the query to a search engine that index documents in another (or many other) language(s), and applying various refinement steps, like query expansion, to return the more relevant document possible. Sbire was designed for the CLEF task. Some modules are therefore not mandatory, or would be impractical, in a real-world information retrieval system. A central module of the cross-language IR task, however, is the translation module. It has no fixed place in the process since it can be use to translate the topics at the query time or to translate the entire document repository before indexation. In our experiments, we choose to use machine translation at query time.
Our approach to the CLEF event consists in the use of two commercial off-the-shelf (COTS) search engines which we use to perform boolean queries. We test many query construction techniques which vary the ways in which the terms are extracted from the topics. We then experiment with various approaches for querying the search engines by combining the terms using the boolean operators. We briefly explore a query expansion approach based on fuzzy logic. Finally, we investigate three different word-for-word translation methods.
The report is divided as follow: section 2 presents the CLEF conference and gives some insight on tasks and strategies used by participants in previous years. Section 3 shows the architecture schema of the Sbire prototype, tightly linked to the Java code. Section 4 to 8 detail the major strategies deployed in Sbire. Section 9 is a collection of comments written during the CLEF 2004 conference in Bath, UK. Finally, section 10 is the conclusion of this work.
2
The CLEF Conference
CLEF is an extension of the CLIR track (Cross Lingual Information Retrieval) that was held during the TREC1 competition (Text Retrieval Conference) between 1997 and 1999. The track was spinned-off in 2000 and sponsored by organizations like DELOS2 and the NIST3 [Peters, 2002].
CLEF is basically a competition between cross language information retrieval systems. It proposes a standard environment for participating systems to evaluate themselves. The methodology usually implies having a large corpora of text from which the participating system must extract the most relevant texts given a query. The relevance of sampled documents is noted by human judges.
The following sections go into more details, describing tasks that are proposed in a CLEF competition. Then, a section presents some of the strategies that were published by competitors.
2.1 CLEF Tasks
Many tasks are proposed in CLEF: multilingual, bilingual or monolingual retrieval, question answering, image retrieval, and more. Here are the two tasks (for 2004) that mainly interested us in the creationg of Sbire:
1. Bilingual Retrieval:
Query-Corpus pairs Italian/French/Spanish/Russian -> Finnish German/Dutch/Finnish/Swedish -> French Any topic language -> Russian
Any topic language -> Portuguese
Any topic language -> English (for newcomers only!) Goal Query in 1 language, return results in a foreign language.
2. Monolingual Retrieval:
Query language Finnish or French or Portuguese or Russian Corpus language Finnish or French or Portuguese or Russian
Goal Query in 1 language, return results in the same language. This evaluation allows highlighting differences of Information Retrieval among languages.
✂✁☎✄✆✄✞✝✠✟✡☛✡☞✄✞✌✎✍✑✏✓✒✕✔✗✖✘✙✄✚✒✜✛✣✢✑✤☎✡ ✥ ✁☎✄✆✄✞✝✠✟✡☛✡✧✦✓✍✩★✢✓✘✑✪✚✔✑✢✣✍✫✒✕✖✍✗✖✬✒✭✝✓✖✬✒✏✮✔✗✌☛✒✕✖✄✭✡ ✯ ✁☎✄✆✄✞✝✠✟✡☛✡✱✰✲✰✳✰✴✒✕✔✗✖✘☞✄☞✒✬✛✣✢✮✤✧✡
2.2 CLEF Participant Strategies
Here’s an overview of some strategies published in proceedings of the CLEF event. Far from a complete coverage, this section proposes to name the diverse strategies and their associated results. Emphasis is given on winners and recurrent strategies.
First let’s make a distinction between A) Information Retrieval strategies and B) Translations strategies. Both are required for a successful system and are covered in the CLEF proceedings. However, in the context of SBIRE, translation strategies recover more importance. Indeed, the Information Retrieval task is to be serviced by a third-party system. The following sections present a short description of Information Retrieval Strategies and an in-deep description of Translation strategies.
2.2.1 Information Retrieval Strategies
Information Retrieval tools are somewhat complex systems that allow the indexation and retrieval of documents using queries. Here we look at two aspects of IR tools: the ranking algorithms and the morphological algorithms.
2.2.1.1 Ranking algorithms
2.2.1.2 Morphological algorithms
For the aim of cross-lingual retrieval, two morphological techniques emerge from the participant systems [Braschler, 2001]. Those techniques mainly allow systems to augment their recall:
1. Stemming: Consists in stripping word suffix to conflate word variants under the same root. It can be either done in a light manner with the handling of inflexional suffixes like singular, plural, feminine, masculine forms; or in a heavy manner with the handling of derivational suffixes like verbs and adverbs endings [Savoy, 2002a].
2. Decompounding: Consist of splitting compound terms in their constituent parts. Applies to languages like German and Dutch.
2.2.2 Translation Strategies
For bilingual or multilingual Information retrieval three main strategies can be highlighted. The great difference between them has a crucial impact on the design of the system. The first strategy consists in directly translating the source documents and to apply classic information retrieval. The second strategy consists in translating the input query and searching documents in the original language. The last strategy consists in applying query expansion, mixed with any of the preceding approaches, to further specialize the search. Let’s examine them:
1. Source Document Translation: This strategy consists in translating the source collection of documents and then applies classic information retrieval [Oard, 2001]. An alternative was also proposed where only key concepts of documents were translated [Lopez-Ostenero, 2002].
2. Query Translation: This is the strategy adopted by the majority of systems. Many variants exist. The idea is to translate the query to search the document collection in the target language:
Off-the-shelve Machine Translation [Jones,2002], [Savoy, 2002a]
Commercial systems like Systran (considered as the state of the art MT tool) can be use to provide the translation of the query.
Dictionary lookup
(a.k.a. Word-by-Word translation) [Sadat, 2002], [Savoy, 2002a]
Bilingual dictionaries can be use to perform a word-by-word translation.
Parallel Corpora-based Translation [Cancedda, 2003], [Nie, 2002]
Parallel corpora can be use to gather statistics about aligned expressions that match the query.
Translated Terms Combination [Jones, 2002], [Savoy 2002a]
Some systems combine two or many of the approaches above and either sends long queries (query expansion) or try to find the best translation by comparing outputs.
Corpus-based Disambiguation [Sadat, 2002]
When query is an expression, a corpus can be use to find the best translation of polysemous words. Mutual information can be use to find best word pairs in the context.
Parallel Corpora-based Disambiguation [Boughanem, 2002]
Parallel corpora can be use to find the best translation of query. If a query in the original language returns a given set of documents, the best translation should returns the corresponding set in the target language.
Bi-Directional Translation [Boughanem, 2002], [Nie, 2002]
For languages A and B, the best translation of the query from A B is the one for which the inverse translation from B A returns the original query.
Pivot Language
[Kishida, 2003], [Qu, 2003]
In multilingual experiments, some systems uses a “pivot” language (e.g.: English) to perform the translation from a language to another. This is mainly due to the fact that MT systems often offer translation of every language to or from English.
Best-N Approach [Bertoldi, 2002]
When many translations are possible for a query, N of them can be use for an initial retrieval and other mechanisms can allows an a posteriori ranking of documents.
3. Query Expansion:
Relevance Feedback
[Bertoldi, 2002], [Jones, 2002], [Sadat, 2002], [Qu, 2003]
Although many variants exist for relevance feedback, the core idea is to try to expand the original query by first retrieving relevant documents for it. Frequent co-occurent words within these documents can be added to the query (to help translation or to help final retrieval). Domain Feedback
[Sadat, 2002]
Same idea than above but the query expansion is done by classifying the query in a domain and adding domain specific terms to the query thereafter.
The conclusion of the majority of researches propose that a combination of many techniques taken from one or many of the strategies above is the key for a winner system [Braschler, 2001, 2002b], [Savoy, 2002a, 2002b], [Jones, 2002].
3
Sbire’s Architecture
✂✁☎✄✂✆✞✝✟✡✠☞☛✍✌✂✎✑✏✒✌✂✎✔✓ ✕✗✖✘✖✂✙ ✓✂✎ ✚✜✛ ✚✒✢ ✚✜✛ ✣✥✤✧✦✑✤✩★✫✪✡✬✭✪✧✦✭✮✰✯✱✪✒✲✧✪✂✳✒✴✶✵ ✷✒✸ ✟✺✹ ✍✼✻✩✌ ✷✗✽ ✟✂✾✿✻✩✔✓✛☎❀✱✻✣✛✓✍ ✷❂❁ ✟✺❃ ✌❄✻✩✔✑✘ ★✻✑✄✞✖✢✫✔❆❅ ✢✗✦☎❀✗★✍ ✷❈❇ ✟✥❉❊❀✮✍✗✌●❋❍❃✫✍✗✌❏■▲❑ ✍✗★✍✣✏☞✄✞✖✢ ✔ ✷❂▼ ✟✥❉❊❀✮✍✗✌●❋◆❑✗✄✞✌❄✻☎✄✍✓✛✗❋ ✷✗❖ ✟✧❑ ✍✗✻✩✌✎✏ ✁◗P✩✔✓✛ ✖✔✓✍ ✷✗❘ ✟✥❉❊❀✮✍✗✌●❋◆P✼❙ ✝✗✻✗✔✮✘✮✖✢✫✔❆❅ ✢✣✦✒❀✫★✍ ❚❱❯❳❲✍❨❩❯ ☛✍✌✂✁❂❬ ✙ ✎❄❭❪❭✭✌✂✏✥✝❫◆✝❴✁ ❵✩✌✥✌✂✆✙ ✓✂✁❜❛✧❝ ✙ ✎❞✝✙ ✟ ❡ ✙ ✁✥❢❤❣✐❝ ✙ ✎ ✖ ❭✭✌ ❡ ✙ ✓✂✎✔❫✺✠❥✩✁✥✄✂✝❦✁ ✙ ❣✐❝ ✙ ✎ ✖ ✡❧♠✏✒✓✂✁☎✟❂✝✌✂✁ ☛❊✎ ✙ ✓✒❭ ✙✫♥♣♦ ☎☛rq ❫✗✌✧s❥✏✧✆❦✝✓✧✁✒❭t✎ ✙ ✟✗❝✂✆❭✭✟ ✉✇✈✶① ♦✇✙ ✆ ✙ ❬✂✓✩✁☎❫ ✙ ✓✥✟✗✟ ✙ ✟✗✟❂s ✙ ✁✒❭✭✟ ✡❬✂✓✧✆❦❝✜✓✺❭②✝✌✂✁ ③✼✌✥✌✂✏ ✚✜✛✥④❊✚✒✢ ☛✍✌✂✏ ✙ ✎✭✁✂✝❫ ✂✁✒❭✙ ✎✑✏✧✎❞✝✟ ✙ ❡ ✙ ✓✂✎⑤❫✺✠ ⑥⑦✆❭✭✓✡⑧❊✝✟⑨❭✭✓ ✂✁✒❭✙ ✎✑✏✧✎❞✝✟ ✙ ❡ ✙ ✓✂✎⑤❫✺✠ ✚✡⑩ ☛❊✆❝✧✟❈❭ ✙ ✎❞✝❦✁☎✄ ✚✡✟ ✙ ❝✧❢✧✌ q ♥ ✠ ✙ ✟✼✓✧❝❱✎❞❝✜✟ ✚✒❶ ❷❪✝✟✭❸❹❝✇✁✥❫❈❭②✝✌✧✁ ✡❧♠✠☎✓✥❝✧✟❈❭②✝❬ ✙ ❡ ☛ ♦ ✚✥❺ ❵✩✓✥✄ ♥ ✎✔✓✂✁☎✟ ❵✩✓ ✕✒✙ ✆❴❻✡✝✟✺✠ ♥✶✙ ✎❞s❤✝❦❝✂s ♥ ✝❭②✆✙✂❼ ❷ ✙ ✟✗❫✺✎❞✝❴✏✡❭②✝✌✂✁ ❂❧✧❭❹✎✔✓✥❫❈❭✭✌✂✎ ♥ ✝❭②✆✙✂❼ ❂❧✧❭❹✎✔✓✥❫❈❭✭✌✂✎ ♦ ✓✒❽ ♥ ✝❭②✆✙ ♦ ✓✒❽❾❷ ✙ ✟✼❫✺✎❞✝❴✏✡❭②✝✌✧✁ ✚✒❿ ✚✱➀ ❷➂➁✇⑥➂✛ ❷➂➁✇⑥❊✢ ❷➂➁✇⑥❊❿ ➃❊➄❱➅➆✯✗✪✒✲✂✪✧✳✒✴✶✵ ➇✶➈✥➉✍✸ ✟✂❑✂➊✓✖✌✎✍ ➋✡➌❈➍❊➎✂➌⑨➏⑨➐❦➑②➒✼➏✼➐➓➍❊➔ →✧➣❩↔✗↕②➐❴➏✿➙❈➌⑨➏✼➛✿➜✔➑ ➇✶➈✥➉✂✽ ✟❱➝✒✻✓✛✼❃ ✌❄✻✗✔✮✘ ➞❂➟ ➛✿➠❴➏❩↔❳➠❴➡➂➏❳➢➤✗➥✿➠ ➦❈➣✿➤②➒✺➐✞➣✼➛✿➔✿➧②➡➂➏⑨➢➤✗➥✿➠ ➦❈➣✿➤②➒✺➐✞➣✼➛✿➔✭➨⑨➡➂➏⑨➢➤✗➥✿➠ ➇✶➈✥➉❱❁ ✟ ✷ ✘✱✍✺❀✓✦✣✢✗✪⑤❃ ✁✑✍✮✘⑨✻✺❀✗✌✔❀✮✘ ➦❈➏✿➔❞➠➩➋ ➋✡➌❈➍➭➫❩↔✗➯❩➣✼➛✿➔✭➢➟ ➛ →✂➢➛❈↕②➐❴➏✿➙✗➲✡➏②➳❈➢➣✿➠➩➢➟ ➛ →✧➣❩↔✗↕②➐❴➏✿➙⑨➎✂➌ ➟ ➠➵➢➏❈➛✿➠ →✂➢➛❈➸❈➏❳➺➏②➳⑨➣❈➛✿➜❞➏ ❻✒✎ ✙ ✁✥❫✺✠❜☛✍✌✂✎✑✏✒✌✂✎✔✓ ✕✗✖✘✖✂✙ ✓✂✎ ✚✜✛ ♥ ✌✂✏✧✝❫✗✟ ✕✼✖❜✖✧✙ ✓✂✎3.1 Input Parameters
Parameters are options the system has in hands to perform a full loop. For each option, one module must be chosen from the given alternatives. In our experiments, all combinations were tested to find the optional strategy. Parameters are the following
P1 Year: Each year (from 2000 to 2004) has its own corpus of text, its own set of topics and its own relevance assessment file. Years 2002-2003 were available for training and testing.
P2 Language: The search for relevant documents can be made either on French texts or on English Texts. In both cases, the topic file is the same and is in French. That mean the system can participate in (1) the French monolingual task and in (2) the French English task.
P3 Translation Module: When running in bilingual mode (P2 = English), A translation module must be chosen. It allows translating the keywords extracted from the topic (see
section 8). Modules are BagTrans, Babel Fish and Termium™.
P4 Query Term Selection: There is various ways to extract keywords from the topic. The query construction module focuses on the fields used from the topics (see section 5).
P5 Query Strategy (also called Query Construction in Java code): When it is the time to send a query to a search engine, one or many queries must be constructed using Boolean operators (see section 6).
P6 Search Engine: The query is issued to a particular search engine. Each search engine has its own ranking algorithm and meta-data handling capabilities (see section 4). We used and compared Copernic and AltaVista.
P7 Query Expansion Module: Once results are returned from the search engine, the best results can be use in a retroaction loop (see section 7).
3.2 Input DNA
At some places in the process, specialized set of parameters – called DNA – must be defined. DNA is usually a set of numeric parameters used as weight and thresholds in algorithms. Moreover, when evaluating the performance of Sbire, DNA can be set automatically using a genetic algorithm engine. It means that multiple loops are automatically performed, varying the DNA and trying to obtain an optimal score in a way that mimics natural selection process. Here are the three DNA of Sbire:
NumQueryTerms: Maximal number of terms extracted from the topic.
MaxFrequency: Maximal frequency, on the corpus, allowed for a term. Terms
with high frequencies are considered as stop words.
DNA2 BagTrans:
ContextWeight: When translating a term, the term under examination is
considered as the “main” term while the other keywords in the query are the “context” terms. Context terms receive a fraction of this weight depending of their cardinality in the estimation of the correct translation. So, weight of a context term = (ContextWeight / Number of Context Terms). The main term has a weight of 1 - ContextWeight. The sum of all weights is 1.
BagTrans1Weight: The 2 versions of BagTrans can be combined. In such a case,
this is the weight of the first version.
BagTrans2Weight: This is simply 1 - BagTrans1Weight
DNA3 Pseudo-Thesaurus:
BestN : Number of documents taken from the top of the hit list to perform
relevance feedback.
NumExpansion : Number of expansion to add to the original query.
MinFreqDeviation : This is an internal threshold of the pseudo-thesaurus
algorithm.
MaxFreqQuotient: This is an internal threshold of the pseudo-thesaurus
algorithm.
MinRelevance: This is an internal threshold of the pseudo-thesaurus algorithm.
3.3 Execution Sequence
The normal sequence is a trace in the schema shown at the beginning of section 3 from the start to the end. When using a year for which the relevance assessment was published, an evaluation loop is performed. The evaluation outputs the fitness of the current run, expressed in number of relevant documents found. Note that the Precision/Recall curve could be used for fitness. The later fitness can be use to feed the genetic learning loop or simply for the user to know the achieved performance.
The execution is launch using the Experiment method from the Sbire class. This method requires all the preceeding parameters and DNA to be given:
[Java]
// Launch the Experiment
Experiment( ClefSetup.YEAR_2004, ClefSetup.MONOLINGUAL, TranslateBoolQuery.TRANSLATE_TERMIUM, BagTransDNA(0.36, 0.64), QueryExpansion.QE_PSEUDO_THESAURUS, QueryExpansionDNA(10, 2, 3.3, 0.01, 8), IRWrapper.COPERNIC3, QueryingStrategy.STRATEGY_DISJUNCTION, Topic2BoolQueryCall.EXTRACTOR_QUERY, SbireDNA(0.25, 15, 3, 9) ); 3.4 System output
As expressed in the diagram, the system outputs “TREC-compliant results”. There are two possible scenarios:
1. We are running on the current year. We must output results and send them to the CLEF staff, for evaluation.
2. We are testing ourselves on a previous year. We must visualize our performance and obtains a “fitness”, for genetic learning.
In both cases, the system output is the same file. Each line starts with the number of the topic item, ex.: 201. It is followed by a legacy code “Q0” that is useless but kept by CLEF for backward
compatibility. Then come the unique identifier of a document in the corpus, ex.: GH950503-000083.
It is followed by the rank (0-based) we gave to this document. Then come the score [0-1] of this document. Finally, we find the name of the run, ex.: ltrcbifren1; in this particular example, the
name means “LTRC bilingual French English 1”.
[Text] 201 Q0 GH950503-000083 0 1 ltrcbifren1 201 Q0 GH950823-000149 1 0.5 ltrcbifren1 201 Q0 GH950130-000144 2 0.3333333333333333 ltrcbifren1 201 Q0 GH951111-000216 3 0.25 ltrcbifren1 201 Q0 GH950111-000090 4 0.2 ltrcbifren1 201 Q0 GH950105-000150 5 0.16666666666666666 ltrcbifren1 201 Q0 GH950218-000180 6 0.14285714285714285 ltrcbifren1 201 Q0 GH950926-000217 7 0.125 ltrcbifren1 201 Q0 GH950516-000179 8 0.1111111111111111 ltrcbifren1 201 Q0 GH950729-000158 9 0.1 ltrcbifren1
In the first case, it is sent as is, since this is the formatting that CLEF requires.
In the second case, the file is passed to an external program called “trec_eval.exe”. The later outputs various statistics that we put in an xml file. Here’s what it contains:
[XML]
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="http://0553-crtl/Stylesheets/clef_result_2.xsl"?>
<clef_result>
<experiment>[MonoFr1, Copernic 3.0, Raw Title plus Extractor Best, 9 Terms, No Query Expansion, Successive Constraints Relaxation (Frequency Order)]</experiment>
<queries> ... <query id="200"> <retrieved>1000</retrieved> <relevant>18</relevant> <retrieved_relevant>16</retrieved_relevant> <non_interpolated_precision>0.0369</non_interpolated_precision> <r_precision>0.0</r_precision> </query> ... <overall total_queries="52"> <retrieved>51740</retrieved> <relevant>946</relevant> <retrieved_relevant>895</retrieved_relevant> <non_interpolated_precision>0.3847</non_interpolated_precision> <r_precision>0.3373</r_precision> <precision_at_0>0.6134</precision_at_0> <precision_at_20>0.5047</precision_at_20> <precision_at_40>0.4315</precision_at_40> <precision_at_60>0.3525</precision_at_60> <precision_at_80>0.2883</precision_at_80> <precision_at_100>0.1967</precision_at_100> </overall> </queries> </clef_result>
This XML file is then pushed in the evaluation loop, where the fitness is easily accessible by the genetic algorithm (the fitness is the number from the field clef_result > experiment > queries > overall > retrieved_relevant.
It is rendered as HTML for visualization using the XSL and transformations. Here’s a screenshot of the result of a run:
Sbire’s result (red line) is always plotted against the best result that was achieved by a participant (blue line) in the given year.
4
Commercial Off-The-Shelf Search Engines
Two commercial search engines were used for our participation at CLEF. Both offer boolean query syntax rather than weighted queries. We realize that this may be a handicap in CLEF-like competitions. Researchers have found strict binary queries to be limiting (Cöster et al., 2003), and most of the best results from previous years rely on systems where each term in a query can be assigned a weight. UC Berkeley performed very well at CLEF 2003 using such a search engine (Chen, 2002). Yet the availability and quality of commercial search engines make them interesting resources which we feel merit proper investigation.
The first search engine that we use is Copernic Enterprise Search (CES), a system which ranked third in the topic distillation task of the Text Retrieval Conference (TREC) held in 2003 (Craswell
et al., 2003). Copernic’s ranking is based on term frequency, term adjacency and inclusion of
terms in automatically generated document summaries and keywords. It performs stemming using a multilingual algorithm akin to Porter’s (1980). Copernic also has the ability to handle meta-data and to take it into consideration when performing its ranking calculations. In our experiments we provided CES with the title meta-data which is found in the TITLE, TI or HEADLINE tags depending on the corpus.
The second search engine used is AltaVista Enterprise Search (AVES) which implements algorithms from the renowned AltaVista company. AVES ranking is based on term frequencies and term adjacency. It performs stemming but the exact algorithm is not documented. Meta-data was not taken into consideration for the searches performed with AVES.
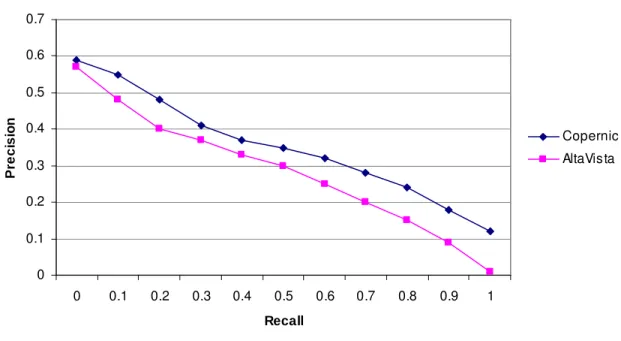
Copernic retrieves more relevant documents than AltaVista for the majority of the configurations which we tested on the 2003 data. This observation holds for the CLEF 2004 data. Figure 1 plots the precision-recall curves for both search engines using the 2004 Monolingual French data. The queries consist of a disjunction of the terms in the topic title. This simple strategy serves as our baseline. Our query strategies are explained in detail in the following sections.
Precision-Recall Values for Baseline Experiments 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Recall P re c is io n Copernic AltaVista
Fig. 1. Precision and recall values for the two search engines using our baseline strategy.
An analysis of the 2003 data allows us to observe that the use of the title meta-data, meaning that the search engine assigns a better score to documents in which query terms are found in the title, accounts for about 20% of the difference between the two systems. It is a reasonable assumption that the remaining 80% difference is due to the different ranking algorithms. Since CES and AVES are commercial products, we use them as black boxes and cannot explain the difference in detail.
A future work should include combining results of both search engines. This is a very popular topic at CLEF. If two algorithms return results that differ, then it is often the optimal choice to combine algorithms. Combining search engine results can be done with a simple round-robin method (take one hit per search engine and loop) and is known to be efficient.
5
Query Terms Selection
The query term selection step consists in extracting important keywords from the topic. Each topic consists of a title, a description and a narrative field. Here is an example of a French topic:
[XML]
<top>
<num> C201 </num>
<FR-title> Incendies domestiques </FR-title>
<FR-desc> Quelles sont les principales causes d'incendie à la maison ? </FR-desc>
<FR-narr> Les documents pertinents devront mentionner au moins une des causes possibles d'incendie en général ou en référence à un exemple particulier. </FR-narr>
</top>
We investigated various methods for exploiting these fields. Our research focused on the following strategies:
S1. the use of the title in isolation (this is our baseline); S2. the use of the description in isolation;
S3. the use of the combination of the title and the description;
S4. the use of Extractor (Turney, 2000) keyphrases extracted from all fields; S5. the use of the title plus the best Extractor keyphrases.
In all cases we removed the words trouvez, documents, pertinents and informations from the French topics. These words are not stop words but are commonly used in CLEF topics. Stop words are later discarded as explained in the Query Construction section. Comparison of methods can be found in Figure 2.
We have established that it is not efficient to use the narrative in isolation due to the presence of many unrelated words and because the narrative often contains a sentence explaining what not to find, for example “Les plans de réformes futures ne sont pas pertinents”. More sophisticated natural language processing techniques are required to take advantage of these explanations.
Using the information contained in the topics, queries can consist of as little as two words, when using the title in isolation, or tens of words, when Extractor is used to select salient terms from the entire topic.
Exhaustive results are given in the next section but it is worth noting some interesting observations. First, the title in isolation performs well, even if it only contains a few words. Titles are indeed made of highly relevant words. All our best runs are obtained using the words in the title. Furthermore, Extractor is useful for selecting pertinent words from the description and
narrative parts. The best term selection strategy we found is the use of title words combined with a number of Extractor keyphrases.
Extractor can select noun phrases from a text. In our experiments, a noun phrase containing n words is considered as n independent words instead of one lexical unit. It would be worthwhile to investigate if any gains can be obtained by searching for exact matches of these multi-word-units.
Clearly, Extractor phrases should be used for exact match searching and multiple-word translation. It was ignored this year due to a lack of time.
6
Query Construction
We perform three major tasks when building our queries. (1) First, we remove stop words from the list of terms based on their frequency in the corresponding CLEF corpus. (2) Then, the terms are again sorted based on their frequency in order to create a query where the rarest word comes first. (3) Finally, we combine words using the boolean AND and OR operators. Some of our search strategies require several variants of the queries to be sent to the search engines. In this scenario, the first query usually returns a small number of documents. Then, a larger number of documents is obtained by appending the results of a second query, and so on.
Let’s study the term filtering step in greater detail. First, the words that do not appear in the corpus are removed. Then, we remove terms that occur above a specified threshold. We determined this threshold, as a percentage of the total number of documents. For example, the very frequent French stop word “le” appears in about 95% of documents, while the less frequent stop word “avec” appears in about 47% of the documents. We trained our system using the 2003 CLEF data and tested it using the 2002 data. Using these corpora we set our threshold for the exclusion of terms in a query at about 25%.
The second step involves sorting the terms according to their frequencies in the corpora, from least frequent to most frequent. This decision is based on the TF-IDF idea (Salton & Buckley, 1988) which states that a rare, infrequent term is more informative that a common, frequent term. These informative terms allow obtaining precise results. Sorting is useful with the strategy described next.
The last step is to issue the query to the search engine. Here we experimented with two variants. The first, which we use as baseline, is a simple disjunction of all terms. The second, which we call Successive Constraint Relaxation (SCR) consists in sending successive queries to the search engine starting with a conjunction of all terms and ending with a disjunction of all terms. The constraints, which are represented by the conjunctions, are replaced with disjunctions term by term, starting by the last term, meaning the least informative, in the query. When necessary, a query containing the previously removed terms is issued to obtain a list of 1000 documents for our results. Here’s a sample query for which the constraints are successively relaxed:
Given the following words with their frequency in the corpus: incendies (394), domestiques (194), causes (1694) and maison (4651), SCR issues:
Query 1: domestiques AND incendies AND causes AND maison Query 2: domestiques AND incendies AND (causes OR maison) Query 3: domestiques AND (incendies OR causes OR maison) Query 4: domestiques OR incendies OR causes OR maison
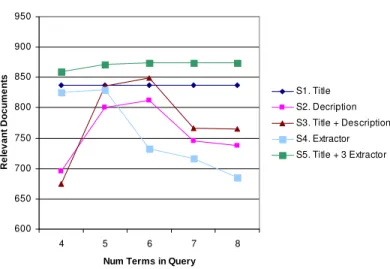
On Clef 2004 data, SCR produces 4% more relevant documents than a simple disjunction. Figure 2 shows the results of our query construction strategies using a disjunction of four to eight terms. Figure 3 shows the same experiments but using SCR. The results are plotted using the CLEF
2003 monolingual-French data. Precision is not plotted here, since experiment is conducted using a fixed (1000) number of documents.
Disjunction 600 650 700 750 800 850 900 950 4 5 6 7 8
Num Terms in Query
R e le v a n t D o c u m e n ts S1. Title S2. Decription S3. Title + Description S4. Extractor S5. Title + 3 Extractor
Fig. 2. Results of various term selection strategies using a disjunction.
Succe ssiv e Constraint Re laxation
600 650 700 750 800 850 900 950 4 5 6 7 8
Num Terms in Query
R e le v a n t D o c u m e n ts S1. Title S2. Decription S3. Title + Description S4. Extractor S5. Title + 3 Extractor
Fig. 3. Results of various term selection strategies using SCR.
We developed our strategies and trained our system using the CLEF 2003 data. We tested all combinations of preceding approaches on the 2002 data. We identified the following methods as being the best query term selection and query construction strategy:
- Use terms from the title plus the three best Extractor keyphrases from the entire topic. - Remove any words that appear in more than 25% of documents.
- Sort low-frequency first. - Keep at most 8 terms.
- Issue queries using successive constraint relaxation.
In the bilingual track, all our runs use this combination of strategies.
Successive Constraint Relaxation has two major weaknesses. First, it heavily depends on the assumption that low frequency words are more pertinent. Second, the step between the last query and the precedent one in the succession is too large.
The problem with low frequency words in our algorithm is that results will be quite bias toward them. In the case were these words are not really pertinent, results will be bad. Consider, for instance, this example:
domestique AND (incendies OR causes OR maison)
Results in this case must include the word “domestique”. Clearly, the topic talks about “incendies domestiques” but the term is restrictive. “maison” would have been a good replacement but it has not the same importance in the query because of its high frequency.
The second weakness of SCR is the too large difference of the last query compared to others. Using the same example, we see that all the first queries will have at most X results, where X is the frequency of the lowest-frequency word. The last query will return the union of all pages that contains any words. In some case, it is thousands of documents compared to less than ten.
7
Query Expansion
It has been reported that query expansion using pseudo-relevance feedback generally improves results for Information Retrieval (Buckey and Salton, 1995) and is very effective in CLEF-like settings (Lam-Adesina, 2002). In our experiments, our query expansion strategy relies on a
Pseudo-Thesaurus construction approach (Miyamoto, 1990) making use of the fuzzy logic
operator of max-min composition (Klir & Yuan, 1995). The approach is to take the N-best search engine results (hereafter N-best corpus), to extend our initial query with other pertinent words from that corpus as determined by evaluating their fuzzy similarity to the query words. Texts from N-best corpus are segmented into sentences and a term set (W) of single words is extracted after filtering prepositions, conjunctions and adverbs from the vocabulary of the DAFLES dictionary (Verlinde et al., 2003). The number of occurrences per sentence for all words is determined. The association between every word pairs is then calculated using the following fuzzy similarity measure:
Let f
( )
wik be the frequency of the word wi∈W in the sentencek
from the N-best corpus.(
)
(
)
∑
∑
=
k jk ik k jk ik j iw
f
w
f
w
f
w
f
w
w
sim
)
(
),
(
max
)
(
),
(
min
)
,
(
Among all words, the closest ones to the original query terms were added to our query. We tried adding 1 to 10 terms when building the N-best corpus with 5, 10, 25 and 50 documents. This did not improve results, when tested on CLEF 2002 data. The same conclusion holds for 2004.
A possible explanation of the lack of improvement with our query expansion algorithm may be that search engines using only boolean queries may not be able to take advantage of these expanded terms. The extra words added to the queries can be unrelated to the topic, and should have a smaller weight than the initial query terms. The Pseudo-Thesaurus gives confidence levels for its expanded list of terms, but we were not able to incorporate this information into our final queries. More investigation is needed to understand why our query expansion attempt failed.
Interestingly enough, another group (Lioma et al., 2004) at CLEF 2004 reported bad results for query expansion in the monolingual task. They use the Rocchio’s algorithm (Rocchio, 1971) known to be useful in most cases. The main point why a relevance feedback system is not efficient is the relevance of the best-N results used. In Sbire, emphasis should be given to returning highly relevant first 5 results. A Rocchio model could also be compared to the Pseudo-Thesaurus approach.
8
Query Translation
A critical part of bilingual information retrieval is the translation of queries, or conversely the translation of the target documents. In our experiments we decided to translate the queries using three different methods. As a baseline we use the free Babel Fish translation service (Babel Fish, 2004). We compare this to (1) an automatic translation method which relies on TERMIUM Plus ® (Termium, 2004), an English-French-Spanish terminological knowledge base which contains more than 3 500 000 terms recommended by the Translation Bureau of Canada and (2) a statistical machine translation technique inspired by IBM Model 1 (Brown et al., 1993), which we call BagTrans. BagTrans has been trained on part of the Europarl Corpus and the Canadian Hansard. The following sections present Termium, BagTrans and, finally, the results obtained by all systems.
The terms stored in Termium are arranged in records, each record containing all the information in the database pertaining to one concept, and each record dealing with only one concept alone (Leonhardt, 2004). Thus the translation task becomes one of word sense disambiguation, where a term must be matched to its most relevant record; this record in turn offers us standardized and alternative translations. A record contains a list of subject fields and entries, all of which are in English and French, and some of which are in Spanish as well. Entries include the main term, synonyms and abbreviations. The translation procedure attempts to find an overlap between the subject fields of the terms in the query so as to select the correct record of the word which is being translated. If none is found, then the most general term is selected. Generality is determined by the number of times a term appears across all records for a given word, or, if the records themselves do not provide adequate information, generality is determined by the term frequency in a terabyte-sized corpus of unlabeled text (Terra and Clarke, 2003). When a word is not contained in Termium, then its translation is obtained using Babel Fish. More details about the translation procedure using Termium can be found in (Jarmasz and Barrière, 2004).
Given a French word, BagTrans assigns probabilities to individual English words that reflect their likelihood of being the translation of that word and then uses the most probable word in the English query. The probability of an English word e is then calculated as the average over all French tokens f in the query of the probability p(e|f) that e is the translation of f. Translation probabilities p(e|f) are derived from the standard bag-of-words translation IBM Model 1, and estimated from parallel corpora using the EM algorithm. Two different parallel corpora were used in our experiments: the Europarl corpus, containing approximately 1M sentence pairs and 60M words; and a segment of the Hansard corpus, containing approximately 150,000 sentence pairs and 6.5M words.
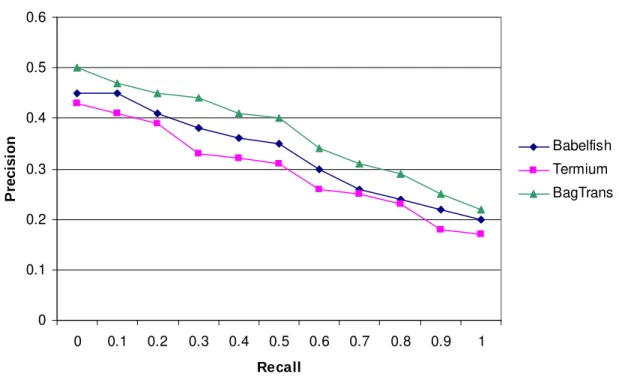
Figure 4 shows the precision and recall curves for the three translation techniques as measured using the CLEF 2004 data. The automatic translations strategies with Babel Fish and BagTrans do not perform any word sense disambiguation, whereas the ones using Termium attempt to disambiguate the senses by determining the context from the other terms in the query. Note that Termium found more relevant documents than Babel Fish but its precision-recall curve is lower.
Precision-Recall Values for Three Translation Strategies 0 0.1 0.2 0.3 0.4 0.5 0.6 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Recall P re c is io n Babelfish Termium BagTrans
Fig. 4. Comparison of the three translation strategies.
There are many ways in which our Termium and BagTrans translation systems can be improved. None have been customized or trained in particular for this CLEF competition. Since our search engines use boolean operators, an incorrect translation can have a big impact on the results. As we do not take context into consideration when using Babel Fish or BagTrans, it is not surprising that the translations are often incorrect. Termium, on the other hand, is a governmental terminological database and it may contain only specific senses of a word, which might be more correct in some official sense, yet less popular. Termium suffers from being normative. We will continue to pursue automatic machine translation methods which can be trained on specific corpora like BagTrans and which take into account the correct word senses for our future participations at CLEF.
9
CLEF 2004
CLEF 2004 was held in Bath, UK. The conference main aim is to present comparative results for all teams and to have presentation from the best / most original submissions. Our team did not submit for an oral presentation but we presented a poster.
Overall, there are good news and bad news. The bad ones are that our submission in the bilingual French English track was not completely evaluated. Since human resources at CLEF are limited and since this was not the most important language pair, judges only look at our “BagTrans” submission. It biases results toward this system and is not fair for other, namely Babel Fish and Termium. Section 10.1 explains why.
The good news, though, is that our participation was noticed and organizers devoted a part of the conference on issues we bring. Our use of commercial systems as “black boxes” is novel and of interest. To quote Mr. Savoy, from U. Neufchâtel: “If you obtain comparable results using only boolean operators, you surely have something interesting. ”
The next section gives details of judges’ work. Then, highlights of each conference session are given.
9.1 More on Judges Work
Judges assess the relevance of documents returned by systems. If, for instance, a systems returns 1000 results, judges will look at all of them and determine their relevancy. Then, if a new system returns 1000 documents, comprising 500 already attested and 500 new, judges will look at the latter, and so on.
However, not all runs are judged. A selection is made to assess the relevance of a representative portion of runs, giving priority to originality of submissions, importance of language pair and finally, trying to assess at least one run for each team.
In our bilingual experiment, only BagTrans was assessed. So, Termium and BabelFish were judge for their capacity to retrieve relevant documents among those of BagTrans. This is quite an important bias.
9.2 Monolingual and Bilingual Tracks
Presentations were given for what is called the “ad hoc” task (monolingual, bilingual and multilingual). Interesting details were given about the best way to tune algorithms and some general strategies to deploy. Here are some remarks:
• The most popular topic language are English, French, Russian (possibly because it was new this year) and German.
• Machine Translation is almost an anonymous choice for bilingual or multilingual tracks, in comparison to dictionary lookup.
• The use of commercial off-the-shelves systems was noted as an interesting novelty.
• Query translation is unanimous instead of document translation. Reasons are however obscure. Some participant explain it is because if the translation algorithm changes, we
need to translate again all documents. However, we feel it should not be a problem for a mature system.
• There was an advantage for veterans groups. Like every year, newcomers were behind.
• The first step to be effective in multilingual track is to be effective in monolingual track.
• Use of light stemming (only for gender and number) was noted to be better.
• Those who use many MT tools found their best results in combining tools.
• Generally, a probabilistic Okapi is better than a simple TF-IDF.
• For compound languages (e.g.: Finnish & German) – n-gram search is better.
• The “winning team” uses a relevance feedback with 3 documents.
• A good “baseline” or theoretical maximum in bilingual track can be obtained in creating a run using manual translation of the topics.
• An American team uses the IBM-3 model for its fertility concept.
• A team tried, without real success, to use dictionary entry to find the right translation among a list of candidate in matching context words with definitions.
9.3 Invited Lecturer: Issues when building a system for CLEF
An invited lecturer, Gregor Thurmair from the company Linguatec, presents some issues to consider when building a system for cross-lingual information retrieval.
He starts by presenting “Apache Jakarta Lucene”, an open source search engine in Java that is a real good start. He noted that a simple translation of input query and output document can form a reasonable cross-lingual IR system. In query translation, the main problem remains the multiword terms. For instance “money laundering” should not be translated word by word in “lavado de dinero”.
He noted that the approach that consists in translating the entire corpus is not a good idea. In the case of changes of translation algorithm, it would require to translate again the corpus.
Finally, he gets deeper in ideas and advices that could help a cross-lingual IR system. However, he gave no evidences that such techniques work nor he presents experimentations:
• Text classification may be interesting to reduce search space. That is if a query is in a certain domain, simply search among documents in this domain.
• Named entities should be useful. (no explanation)
• Phonetic search may be useful for typos that are frequent when using a foreign language.
• Indexing one language per index is better. Do not mix languages because of possible confusion when words are shared.
• Single word analysis is bad (should consider phrases)
• Specialized resources (dictionary, thesaurus) are often too limited to be useful in general cases.
9.4 Image & QA tracks
Two special tracks were presented at CLEF to handle image search and question answering. Both tracks were really popular.
Image Search consist in searching .jpg images using a text description and the image file itself. Teams are allowed to apply NLP techniques and image processing techniques (color diversity, borders recognition, textures) to perform the IR task.
QA consists in answering a question using the shortest string possible. It was presented as a mix of information retrieval and text summarization were the correct information must be found in mass of document and synthesize at its maximum.
9.5 Breakout session
To conclude the conference, it was confirmed that there will be a CLEF 2005. The “ad hoc” task will be back but more place will be given for ImageCLEF and QA since both are gaining popularity.
Some important facts are to be highlight:
• The Multilanguage task will be dropped. The emphasis will be putted on monolingual and bilingual tasks.
• Portuguese, Russian, Czech, Bulgarian will be the preferred languages to handle.
• There may be a new track where we can present work on past CLEF data. It means there would be no need to participate in the competition.
9.6 Final Note
CLEF 2004 was an enriching experience. Maybe on of the most profound impact is on what will be our future works. In our submitted paper, we say we should use “search engine which can perform weighted queries” in future participation. However, given the good comments and the potential advantages of using a strict boolean search engine, it would be interesting to push the idea further.
10
Conclusion
In our first participation in the Cross-Language Evaluation Forum (CLEF) we participated in the French monolingual and French to English bilingual tasks. We use two COTS search engines and implement various query strategies. The best setup we found consists in creating a query using all words of the topic title plus the 3 best keyphrases of Extractor. We filter stop words based on their frequency in the corpus. Then we sort terms from the rarest to the most frequent. We retrieved documents by issuing successive queries to the search engine, starting with a conjunction of all terms and gradually relaxing constraint by adding disjunction of terms. For the bilingual aspect, BagTrans, a statistical model based on IBM Model 1, yields the best results.
Two main points need more investigation. The first one is our unsuccessful use of the pseudo-relevance feedback. We believe that a strict boolean search engine may be problematic for this kind of algorithm. Indeed, the insertion of only one irrelevant term may lead to irrelevant documents. A weighted query may be the key to smoothen the impact of those terms, especially when our pseudo-relevance feedback algorithm has the ability to output confidence values.
Another pending question is why Termium found many more documents than Babel Fish while the latter present a higher precision-recall curve. We believe it means that Termium did not rank the relevant documents as well as the other strategies did. The explanation, though, remains unclear.
For our next participation, we plan to use a search engine which can perform weighted queries. We’ll concentrate on pseudo-relevance feedback, known to be useful at CLEF. We should also add a third language to our translation models to participate in another bilingual track.
For CLEF 2005, here are the main points to remember:
• In the genetic learning, P/R curve could be use for fitness;
• Copernic and AltaVista search engines could be combined;
• Extractor phrases should be taken into account for exact match searching and translation;
• Successive Constraint Relaxation has to be improved to cope with two major weaknesses;
• Emphasis should be given on returning high precision first 5 results for Query Expansion;
11
Acknowledgement
References
Babel Fish, (2004), Babel Fish Translation. http://babelfish.altavista.com/ [Source checked August 2004].
Bathie, Z. and Sanderson, A., (2001), iCLEF at Sheffield, University of Sheffield, UK, (online: http://www.ercim.org/publication/ws-proceedings/CLEF2/bathie.pdf)
Bertoldi, N., Federico, M., (2002), ITC-irst at CLEF 2002: Using N-Best Query Translations for
CLIR, Working Notes for the CLEF 2002 Workshop, Peters, C., (Ed), Italy.
Boughanem, M., Chrisment, C., Nassr, N., (2002), Investigation on Disambiguation in CLIR:
Aligned Corpus and Bi-directional Translation-Based Strategies, CLEF 2001, LNCS 2406,
Springer, Peters, C., Braschler, M., Gonzalo, J. and Kluck, M. (Eds.), Springer, Germany.
Braschler, M., (2001), CLEF 2000 – Overview of Results, CLEF 2000, LNCS 2069, Springer, Peters, C. (Ed.), Springer, Germany.
Braschler, M., Peters, C. (2002a). The CLEF Campaigns: Evaluation of Cross-Language
Information Retrieval Systems, UPGRADE, pages 78-81
Braschler, M., (2002b) CLEF 2001 - Overview of Results, CLEF 2001, LNCS 2406, Springer, Peters, C., Braschler, M., Gonzalo, J. and Kluck, M. (Eds.), Springer, Germany.
Brown, P. F., Della Pietra, S. A., Della Pietra, V. J., and Mercer, R. L. (1993). The Mathematics of Statistical Machine Translation: Parameter Estimation. Computational Linguistics, 19(2):263-311.
Buckley, C. and Salton, G. (1995), Optimization of relevance feedback weights, Proceedings of
the 18th annual international ACM SIGIR conference on research and development in information retrieval, 351-357.
Cancedda, N., Déjean, H., Gaussier, E., Renders, J.-M., Vinokourov, A., (2003), Report on CLEF
2003 Experiments: Two Ways of Extracting Multilingual Resources from Corpora, Working
Notes for the CLEF 2003 Workshop, Peters, C., (Ed), Norway.
Chen, A. (2002), Language Retrieval Experiments at CLEF 2002, CLEF 2002,
Cöster, R., Sahlgren, M. and Karlgren, J. (2003), Selective compound splitting of Swedish queries for Boolean combinations of truncated terms, CLEF 2003, Cross-Language Evaluation Forum.
Craswell, N., Hawking, D., Wilkinson R. and Wu M. (2003), Overview of the TREC 2003 Web Track, The Twelfth Text Retrieval Conference, TREC-2003, Washington, D. C.
Jarmasz, M. and Barrière, C. (2004), A Terminological Resource and a Terabyte-Sized Corpus for
Automatic Keyphrase in Context Translation, Technical Report, National Research Council of
Canada.
Jones, G.J.H., Lam-Adesina, A.M., (2002), Exeter at CLEF 2001: Experiments with Machine
Translation for bilingual retrieval, CLEF 2001, LNCS 2406, Springer, Peters, C., Braschler, M.,
Gonzalo, J. and Kluck, M. (Eds.), Springer, Germany.
Kishida, K., Kando, N., (2003), Two Stages Refinement of Query Translation for Pivot Language
Approach to Cross Lingual Information Retrieval: A Trial at CLEF 2003, Working Notes for the
CLEF 2003 Workshop, Peters, C., (Ed), Norway.
Klir, G. J. and Yuan B. (1995), Fuzzy Sets and Fuzzy Logic, Prentice Hall: Upper Saddle River, NJ.
Lam-Adesina, A.M., Jones, G.J.H. (2002), Exeter at CLEF 2001: Experiments with Machine Translation for bilingual retrieval, CLEF 2001, LNCS 2406, Peters, C., Braschler, M., Gonzalo, J. and Kluck, M. (Eds.), Springer, Germany.
Leonhardt, C. (2004). Termium ® History. http://www.termium.gc.ca/site/histo_e.html [Source checked August 2004].
Lioma, C., He, B., Plachouras, V. and Ounis, I. (2004) The University of Glasgow at CLEF 2004: French Monolingual Information retrieval with Terrier. CLEF 2004, Cross-Language Evaluation
Forum.
Llopis, F., Muñoz, R., (2003), Cross-language experiments with IR-n system, Working Notes for the CLEF 2003 Workshop, Peters, C., (Ed), Norway.
Lopez-Ostenero, F., Gonzalo, J., Peñas, A., Verdejo, S., (2002), Noun Phrase Translation for
Cross-Language Document Selection, CLEF 2001, LNCS 2406, Springer, Peters, C., Braschler,
Miyamoto, S. (1990). Fuzzy Sets in Information Retrieval and Cluster Analysis. Dordrecht, Netherlands: Kluwer Academic Publishers.
Nadeau, D., Jarmasz, M., Barrière, C., Foster, G. and St-Jacques, C. (2004) Using COTS Search Engines and Custom Query Strategies at CLEF, CLEF 2004, Cross-Language Evaluation Forum.
Nie, J.Y., Simard, M., (2002), Using Statistical Translation Models for Bilingual IR, CLEF 2001, LNCS 2406, Springer, Peters, C., Braschler, M., Gonzalo, J. and Kluck, M. (Eds.), Springer, Germany.
Oard, D.W., Levow, G.-A., Cabezas, C.L., (2001), CLEF Experiments at Maryland: Statistical
Stemming and Backoff Translation, CLEF 2000, LNCS 2069, Springer, Peters, C. (Ed.), Springer,
Germany.
Peters, C., (2002), Project Overview: Cross Language Evaluation Forum – CLEF, Presented at EU-NSF Digital Library All Projects Meeting, Rome, Italy
(online: http://videoserver.iei.pi.cnr.it:2002/DELOS/CLEF/CLEF-Rome.pdf)
Porter, M. F. (1980). An Algorithm for Suffix Stripping. Program, 14(3): 130-127.
Qu, Y., Grefenstette, G., Evans, D.A., (2003), Clairvoyance CLEF-2003 Experiments, Working Notes for the CLEF 2003 Workshop, Peters, C., (Ed), Norway.
Rocchio, J. J. (1971). Relevance Feedback in Information Retrieval. SMART Retrieval
System--Experiments in Automatic Document Processing, G. Salton ed., PrenticeHall, Englewood Cliffs,
NJ, Chapter 14
Sadat, F., Maeda, A., Yoshikawa, M., Uemura, S., (2002), Query Expansion Techniques for the
CLEF Bilingual Track, CLEF 2001, LNCS 2406, Springer, Peters, C., Braschler, M., Gonzalo, J.
and Kluck, M. (Eds.), Springer, Germany.
Sahlgren, M., Karlgren, J., Cöster, R., Järvinen, T., (2002), SICS at CLEF 2002: Automatic Query
Expension Using Random Indexing, Working Notes for the CLEF 2002 Workshop, Peters, C.,
(Ed), Italy.
Salton, G. and Buckley, C. (1988), Term-weighting approaches in automatic text retrieval,
Savoy, J., (2002a), Report on CLEF 2001 Experiments: Effective Combined Query-Translation
Approach, CLEF 2001, LNCS 2406, Springer, Peters, C., Braschler, M., Gonzalo, J. and Kluck,
M. (Eds.), Springer, Germany.
Savoy, J., (2002b), Report on CLEF 2002 Experiments: Combining Multiple Sources of Evidence, Working Notes for the CLEF 2002 Workshop, Peters, C., (Ed), Italy.
Termium (2004), The Government of Canada’s Terminology and Linguistic Database. http://www.termium.com/ [Source checked August 2004].
Terra, E. and Clarke, C.L.A.. (2003), Frequency estimates for statistical word similarity measures.
In Proceedings of the Human Language Technology and North American Chapter of Association of Computational Linguistics Conference 2003 (HLT/NAACL 2003), Edmonton, Canada, 244 –
251.
Turney, P.D. (2000), Learning Algorithms for Keyphrase Extraction, Information Retrieval, 2 (4): 303-336.
Verlinde, S., Selva, T. & GRELEP (Groupe de Recherche en Lexicographie Pédagogique) (2003). Dafles, (Dictionnaire d’apprentissage du français langue étrangère ou seconde) : http://www.kuleuven.ac.be/dafles/acces.php?id=/ [Source checked August 2004].