Applying natural language models and causal models to project management systems
Texte intégral
Figure
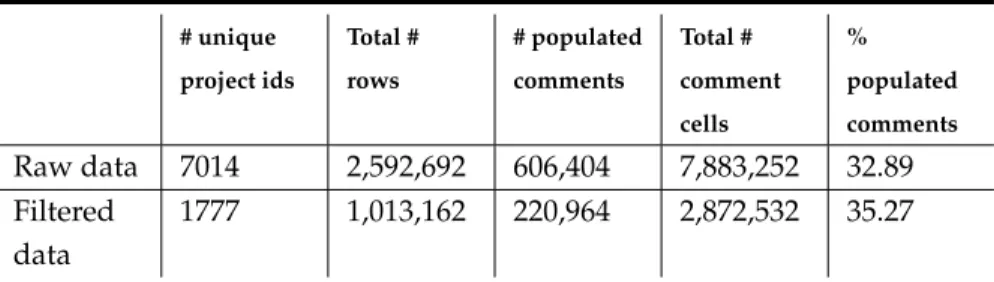


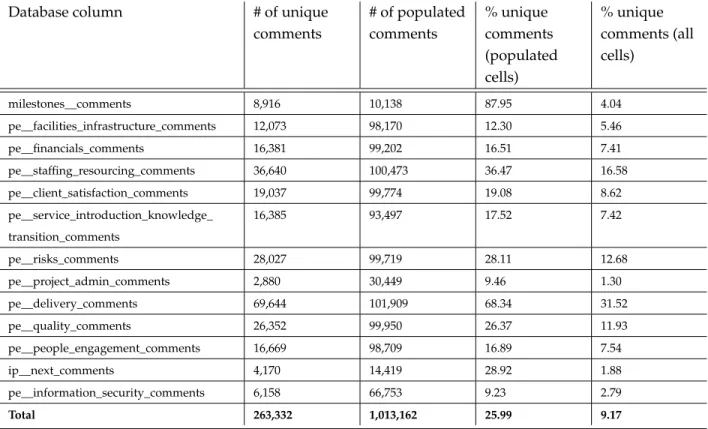
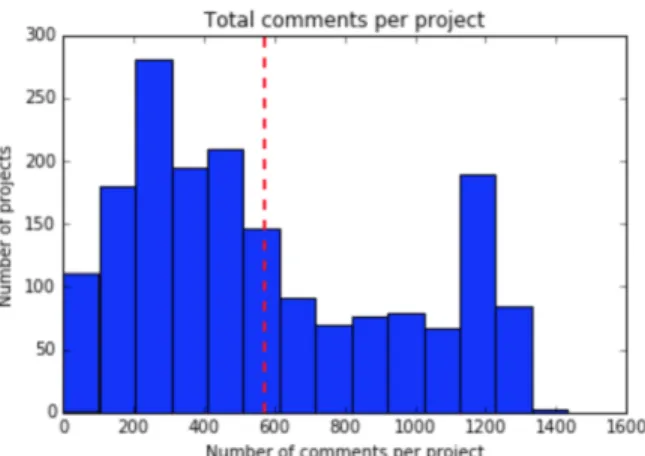
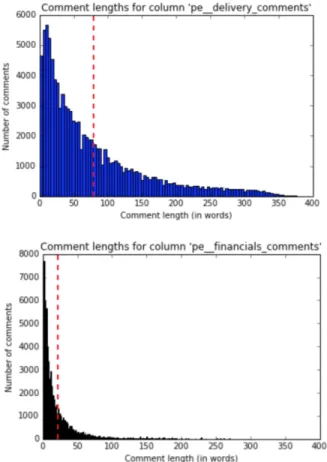

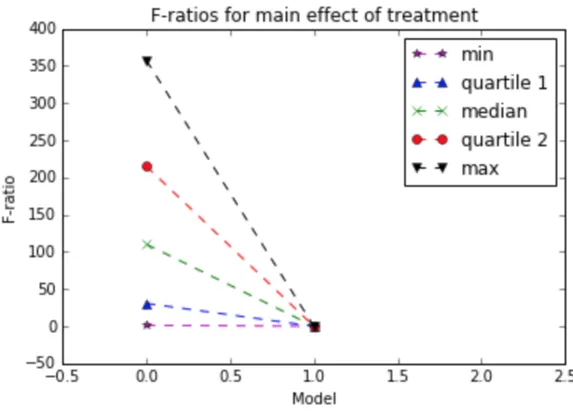

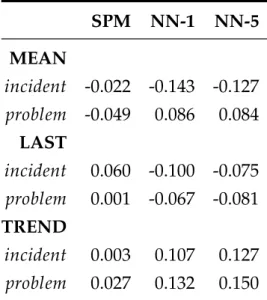
Documents relatifs
If new data would become available (e.g., relative to the released con- tainers at port exit – not necessarily ramped and departed on train containers), the neural network could
We first introduce the notion of λ-K¨ onig relational graph model (Definition 6.5), and show that a relational graph model D is extensional and λ-K¨ onig exactly when the
Downloaded by Universite du Quebec a Trois Rivieres At 07:33 16 April 2018 (PT)... Entrepreneurship and project
For the implementation of simulation model of IT Projects Risk analysis is developed about a system that decides to determine the probability of successful completion of the
Founded by a partnership between the Open University in the UK, the BBC, The British Library and (originally) 12 universities in the UK, FutureLearn has two distinc- tive
~ber 5 willkiirlichen Punkten des R.~ gibt es eine Gruppe yon 32 (involutorischen) Transformationen, welche auch in jeder anderen iiber irgend 6 besonderen
TLV1 Project management CL LL 29/08/12 Vcycle_b.odt.
Among these models, intestinal perfusion is the most common experiment used to study the in vivo drug permeability and intestinal metabolism in different regions of the
