HAL Id: hal-02895983
https://hal.archives-ouvertes.fr/hal-02895983
Submitted on 10 Jul 2020HAL is a multi-disciplinary open access archive for the deposit and dissemination of sci-entific research documents, whether they are pub-lished or not. The documents may come from teaching and research institutions in France or abroad, or from public or private research centers.
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des établissements d’enseignement et de recherche français ou étrangers, des laboratoires publics ou privés.
ROBOTIQUE ET VISION PAR ORDINATEUR
Olivier Guye
To cite this version:
Olivier Guye. ROBOTIQUE ET VISION PAR ORDINATEUR. École d’ingénieur. France. 1984. �hal-02895983�
ROBOTIQUE ET VISION PAR ORDINATEUR
(S
UPÉLEC
M
ETZ
:1984 - 1987)
Résumé du cours :
Ce document est le support d’un cours destiné à des élèves ingénieurs en in de cursus : cet un ouvrage d’initiation aux techniques d’analyse d’images employées dans des applications industrielles.
Les application décrites dans ce document portent sur la métrologie, la localisation dans un espace de travail, le tri et l’identi ication d’objets, inspection et contrôle qualité, surveillance et contrôle d’environnement. Le premier chapitre porte sur la présentation de la vision arti icielle en robotique. Le second chapitre traite des techniques de perception de l’environnement. Le troisième chapitre se focalise sur les procédures de perception en vision par ordinateur. Le quatrième chapitre s’intéresse à la commande de systèmes robotisés. Le cours se termine sur les perspectives futures envisageables dans ce domaine. Il s’agit d’un document historique réédité de manière numérique et qui s’appuie sur les activités d’un groupe de travail actif au début des années 80 dans le domaine des applications industrielles de l’analyse d’images. Mots-clés : modèles de perception en vision arti icielle, reconnaissance statistique des formes, éclairage et géométrie de prise de vue, localisation, granulométrie, étalonnage, authenti ication et identi ication, analyse d'images, calcul d'attributs invariants aux transformations géométriques, reconnaissance des formes
Domaines : Traitement du signal et de l'image, Traitement des images, Algorithme et structure de données
Table des matières
Introduc on...7
1. Présenta on de la vision en robo que...9
1.1. Introduc on...9
1.2. Métrologie...9
1.3. Localisa on...11
1.4. Tri et iden fica on...13
1.5. Inspec on...14
1.6. Surveillance et contrôle d’environnement...15
1.7. Comparaison entre la vision humaine et la vision robo sée...17
2. Percep on de l’environnement...19 2.1. Présenta on...19 2.2. Percep on op que...19 2.2.1. 1D...19 2.2.2. 2D...19 2.2.3. 3D...20
2.3. Percep on non op que...24
2.4. Éclairage et géométrie de prise de vue...24
2.6. Digitalisa on d’images...27
3. Procédures de percep on en vision par ordinateur...29
3.1. Modèles généraux de percep on en vision ar ficielle...29
3.2. Faisabilité d’une applica on en vision par ordinateur...32
3.3. Prétraitement d’une image...34
3.4. Segmenta on d’une image...39
3.4.1. Approche régionale...40
3.6. Méthodes topologiques...46
3.7. Iden fica on d’objets sans recouvrement...47
3.7.1. Calcul d’attributs...49
3.7.2. Reconnaissance statistique...54
3.8. Iden fica on d’objets avec recouvrement...58
3.8.1. Extraction de primitives...59
3.8.2. Reconnaissance structurelle...61
3.9. Structure matérielle des systèmes de vision...63
4. Applica on à la commande de systèmes robo sés...65
4.1. Présenta on...65
4.2. Lecture de caractères...66
4.3. Contrôle qualité...67
4.4. Commande d’un manipulateur d’assemblage...72
4.5. Prise en vrac...76
4.6. Commande de robot mobile...77
5 Perspec ves futures...79
5.1 Vision 3D...79
5.2 Évolu ons prévisibles des systèmes de traitement...81
5.3 Images généralisées...84
5.4 Manipula on d’une image généralisée...86
5.5 Techniques de segmenta on...88
5.6 Modélisa on géométrique...89
5.7 Iden fica on de structures rela onnelles...91
5.8 Techniques interpréta ves...92
5.8 Architectures de calcul...93
Table des illustrations
Figure 1 : Applica on du traitement d’image à la métrologie (document Re con)...11
Figure 2 : Système d’assemblage de moteurs électriques de Wes nghouse...12
Figure 3 : Système de vidéo-contrôle de relais thermiques (document SOLEMS)...14
Figure 4 : Vue arrière du trafic sur une autoroute...15
Figure 5 : Formalisa on de la détec on et du suivi des véhicules...16
Figure 6 : U lisa on d’une lumière structurée pour la caractérisa on d’un objet...21
Figure 7 : Vue d’une bielle de moteur éclairée par une double nappe mono-chroma que...22
Figure 8 : Système de percep on 3D du robot mobile HILARE du L.A.A.S...23
Figure 9 : Typologie des éclairages employés en vision industrielle...26
Figure 10 : Système de reconnaissance des formes sta s que...30
Figure 11 : Système de reconnaissance des formes structurelle...31
Figure 12 : Complexité d’une scène visuelle...33
Figure 13 : Formes de la distribu on du signal vidéo...35
Figure 14 : Calcul des transi ons fond-objet dans une image...37
Figure 15 : Image des passages à zéro d’un Laplaciens...39
Figure 16 : Décomposi on hiérarchique d’une scène...41
Figure 17 : Contours internes et externe d’un objet...43
Figure 18 : Amincissement et squeleBe d’un objet...48
Figure 19 : Représenta on d’un objet en coordonnées polaires...50
Figure 20 : Localisa on d’un objet dans l’espace de vision...51
Figure 21 : Analyse et reconnaissance de formes par la théorie de la décision...57
Figure 22 : Primi ves linéaires...60
Figure 23 : Architecture d’un système de vision ar ficielle...64
Figure 24 : Lecteur de caractères imprimés...66
Figure 26 : Inspec on de carters de moteurs...69
Figure 27 : Recherche de défauts sur un circuit imprimé...70
Figure 28 : Inspec on de circuits imprimés après inser on de composants...71
Figure 29 : Cellule flexible d’assemblage...73
Figure 30 : Décora on de boîtes de chocolats...74
Figure 31 : Organigramme du système de vision...75
Figure 32 : Prise d’objets en vrac 3D semi-organisé...76
Figure 33 : Méthodes d’acquisi on ac ves en vision 3D...80
Figure 34 : Modélisa on surfacique d’objets tridimensionnels...81
Figure 35 : Systèmes d’informa on numérique : situa on présente...82
Figure 36 : Systèmes d’informa on numérique : possibilités futures...84
Figure 37 : Modèle de représenta on d’une image généralisée...85
Figure 38 : Schéma d’interpréta on en reconnaissance de la parole con nue...86
Figure 39 : Structure pyramidale des informa ons...87
Figure 40 : Structure de données hiérarchiques des images...89
Figure 41 : Décomposi on géométrique d’objets...90
Figure 42 : Microprocesseurs cascadables dans un réseau de communica on...94
Introduction
Ce document est le support d’un cours professé à la création de l’antenne de Metz de l’E=cole Supérieure d’E=lectricité. Il s’appuie sur les activité d’un groupe de travail de l’ADERSA en matière d’application industrielles de l’analyse d’images au début des années 80. Ce groupe d’activité s’est impliqué pendant un peu plus de vingt ans dans les domaines suivants au sein de l’ADERSA :−
les architectures de calcul temps réel et parallèle,−
l’acquisition et l’enregistrement de données,−
l’analyse d’image,−
l’analyse statistique de données,−
l’aide à la décision,−
la restitution visuelle. La majeure partie de ces activités se sont concentrées sur les secteurs suivants :−
les applications industrielles temps réel de l’analyse d’image,−
les techniques avancées d’analyse d’image et de résolution de problèmes. Les application décrites dans ce document portent sur la métrologie, la localisation dans un espace de travail, le tri et l’identi ication d’objets, inspection et contrôle qualité, surveillance et contrôle d’environnement. Elles ont fait l’objet d’études de faisabilité comme de réalisations effectives :−
classi ication de carcasses de bovins en abattoir,−
amélioration des performances de l’écartomètre d’un cinéthéodolite,−
authenti ication de personnes par analyse de l’iris,−
appariement automatisé de chaussettes en in de ligne de production,−
détection de de pattes repliées sur un circuit imprimé,−
décoration de boı̂tes de bonbons en chocolat,−
régulation de la cuisson de biscuits dans un four tunnel,−
contrôle de la dérive temporelle de mouvements d’horlogerie,−
commande de panneau de circulation en fonction du tra ic dans un carrefour routier. Au moment de la réédition en numérique de ce cours, il est clairement apparent que les technologies évoquées ont largement évolué, mais il n’en reste pas moins qu’en matière d’ingénierie les démarches décrites pour aborder les problèmes sont toujours valides.Que l’on ne soit pas surpris du manque de qualité des illustrations : le document original à été saisi avec les moyens techniques de l’époque, c’est-à-dire le texte à la machine à écrire, les dessins à l’encre sur une table à dessiner, les images à partir d’imprimantes thermiques réalisant des recopies d’un moniteur vidéo. C’est aussi un document d’initiation sur les applications industrielles de l’analyse d’images destiné à des élèves ingénieurs en in d’études et une très bonne introduction au tome 3 de la série des rapports de recherche sur la modélisation hiérarchique de données multidimensionnelles dans des espaces régulièrement décomposés : applications en analyse d’images ( https://hal.archives-ouvertes.fr/hal-01185368 ). La majorité des techniques d’analyse d’images évoquées dans ce cours sont décrites en détail dans cet autre ouvrage.
1. Présentation de la vision en robotique
1.1. Introduction
Assurer la compétitivité de produits industrialisés par :−
l’automatisation des chaı̂nes de production ;−
le contrôle systématique de la qualité à chaque étape de fabrication a in d’atteindre le « zéro-défaut »; est un des enjeux industriels actuels. Jusqu’ici les systèmes robotisés ne travaillant que dans un univers igé et préalablement connu. Les systèmes de vision arti icielle permettent à ces systèmes d’appréhender l’univers évolutif dans lequel ils agissent : c’est la robotique dite de « troisième génération ». Les systèmes de vision ont pour but d’identi ier, de localiser et d’effectuer des mesures sur les objets présents dans l’environnement d’un poste robotisé. Les domaines d’application de la vision en robotique vont être présentés.1.2. Métrologie
Dans ce domaine, on cherche à véri ier les côtes d’un objet fabriqué ou en cours de fabrication. Une des contraintes souvent présentée dans le relevé de mesure dimensionnelle est que l’opération puisse être mise en œuvre sans contact avec l’objet à analyser. Les meilleurs précisions sont obtenues avec l’emploi de dispositifs linéaires (barrettes). La igure n°1 présente trois applications de relevé de côtes à l’aide de barrettes : 1-1 La mesure du diamètre d’un objet cylindrique en cours de fabrication (contrôle d’étirage) ; 1-2 L’asservissement du bord d’une bande par un système de deux caméras (la résolution est1-3 Mesure de la hauteur d’objets en mouvement sur une tapis mobile.
Le contrôle de côtes à l’aide de capteurs linéaires est converti en un contrôle bidimensionnel pour des mesures échantillonnées lors du mouvement de l’objet à analyser ou du système d’analyse.
Figure 1 : Application du traitement d’image à la métrologie (document Reticon)
1.3. Localisation
La localisation permet de situer dans un environnement robotisé la position d’un objet et de commander un système de préhension pour en réaliser la saisie. C’est le cas d’une cellule d’assemblage où les pièces à assembler sont acheminées sur un tapis mouvant ou présentées sur un plateau d’approvisionnement. (cf. igure 2). La localisation d’un objet peut nécessiter la connaissance de sa position dans l’espace de travail, mais aussi son orientation dans celui-ci pour qu’une prise puisse être réalisée. Lorsqu’on utilise des systèmes d’acquisition de données réalisant une projection (caméra matricielle pour un univers tridimensionnel), la reconnaissance de la face d’équilibre de l’objet est nécessaire pour mener à bien une prise. Ainsi dans certains cas, la localisation ne peut se faire sans l’identi ication de l’objet analysé : c’est notamment le cas lorsque plusieurs objets sont présents dans l’espace de vision.
Le problème se complexi ie encore lorsque les objets se recouvrent les uns les autres de manière ordonnée ou non : c’est le cas de la palettisation en vue du stockage ou de la dé-palettisation lors de l’alimentation d’une chaı̂ne automatisée.
1.4. Tri et identi ication
Le tri est la forme la plus simple rencontrée en identi ication. Lorsque différents objets primaires participent à la composition d’un objet à assembler, la première démarche consiste à créer un poste d’approvisionnement par objet participant à l’assemblage d’un nouvel objet au niveau du poste d’assemblage. Cette démarche apparaı̂t irréaliste lorsque :−
les contraintes mécaniques et économiques limitent le nombre de postes d’approvisionnement ;−
la ligne de production est partiellement robotisée ou en cours d’automatisation (le cas le plus général à l’heure actuelle) : les transferts entre postes sont réalisés de manière manuelle ;−
le poste doit satisfaire à des contraintes de lexibilité (modi ication du processus de fabrication ou de la composition du produit inal). Pour ces raisons, on préférera exécuter le tri des objets participant à la réalisation d’un produit ini à partir d’un poste d’alimentation unique à l’aide d’un système de vision. Lorsque ce système possède des facultés d’apprentissage, la procédure d’identi ication peut être alors modi iée pour prendre en compte de nouveaux objets. Les méthodes mises en œuvre pour identi ier des objets permettent de distinguer ces objets dans un univers de classes restreint, comparé au pouvoir de reconnaissance humain, mais suf isamment pour une application industrielle (par exemple la reconnaissance des lettres de l’alphabet pour une police de caractères imprimés).Figure 3 : Système de vidéo-contrôle de relais thermiques (document SOLEMS)
1.5. Inspection
L’inspection a pour but de véri ier la qualité des produits en cours ou en in de fabrication.
Nous avons vu un premier aspect avec l’emploi de la vision en métrologie. D’autres critères de qualité peuvent être véri iés de manière visuelle :
−
la forme de l’objet en comparaison à un modèle (ébarbures présentes autour d’une pièce moulée, position des étiquettes sur des lacons) ;−
l’état de surface ou l’aspect de l’objet (présence de rayures sur des surfaces métallisées, bulles ou corps étrangers dans des objets en verre).La igure n°3 présente ainsi un poste de véri ication de conformité pour des relais thermiques par comparaison à un modèle pré-enregistré.
L’inspection représente les neufs dixièmes des applications en vision industrielle à l’heure actuelle. L’analyse des défauts de fabrication permet encore de localiser des machines déréglées ou en panne dans la chaı̂ne de production. Figure 4 : Vue arrière du tra4ic sur une autoroute
1.6. Surveillance et contrôle d’environnement
Le dernier domaine que nous abordons est la surveillance et le contrôle d’environnement. Ce cas se présente notamment pour résoudre des problèmes de protection de locaux ou d’entrepôts contre :−
des accidents naturels (feu, intempéries, émission de fumée) ;−
ou d’effraction (surveillance automatique de lieux sensibles). Mais aussi pour la conduite de chariots automobiles autonomes (évitement d’obstacle) ou la protection humaine (surveillance automatique du réseau routier, cf. igures n°4 et 5).1.7. Comparaison entre la vision humaine et la vision robotisée
2. Perception de l’environnement
2.1. Présentation
Selon le type d’application, le nombre de dimensions de l’espace à appréhender varie de un à quatre.
La perception multidimensionnelle d’un environnement peut être construite autour de solutions optiques, non-optiques ou mixtes, en fonction du problème posé.
En perception optique, la maı̂trise de l’éclairage est souvent une condition nécessaire au bon fonctionnement d’un système de vision industriel. Nous verrons les différentes façons de combiner des sources d’éclairage avec des capteurs optiques. En fonction des modes de perception possibles pour résoudre un problème de vision, la solution choisie entraı̂ne un certain nombre de conséquences sur l’image numérique qui devra être interprétée par le système de vision. C’est ce que nous aborderons pour clore ce chapitre.
2.2. Perception optique
2.2.1. 1D Les problèmes monodimensionnels se rapportent en général à la métrologie. On utilise en général des barrettes solides (CCD, CID) comme capteurs linéaires. Elles permettent d’obtenir des résolutions plus élevées que les capteurs matriciels : de 1024 à 4096 points de digitalisation en ligne. 2.2.2. 2D De nombreux problèmes de tri, de localisation et d’inspection peuvent être résolus à l’aide d’une vision bidimensionnelle.Le capteur est placé de manière à ce que son axe optique soit orthogonal au plan de travail (cf. igure n°2). On se contente alors de traiter les projections sur le plan de vue des objets présents dans le champ de vision. Pour des objets pouvant avoir plusieurs positions planes d’équilibre, il sera nécessaire de tenir compte de ces différentes positions si l’on cherche à l’identi ier.
Les capteurs employés sont soit des caméras à tube (caméras vidéo), soit des caméras solides matricielles (CCD ou CID). Les résolutions numériques obtensibles sur ces capteurs sont moins importantes que les barrettes :
−
jusqu’à 800 x 600 pour des caméras vidéo;−
des résolutions équivalentes pour des matrices solides rectangulaires. Lorsqu’une résolution bidimensionnelle élevée est exigée, on utilise un barrette alliée à un mouvement. Caméras vidéo et caméras solides ont des avantages et des inconvénients respectifs (notamment, les déformations géométriques induite par le balayage vidéo dans un tube). Ils permettent par contre d’obtenir des temps d’acquisition très rapides a in d’obtenir l’information complète sur une scène (20 à 40 ms). 2.2.3. 3D La perception des trois dimensions peut se faire par vision de plusieurs façons que l’on regroupe en général en deux classes : 2D1/2 et 3D vraie. 2.2.3.1. 2D/1/2 On dénomme ainsi les méthodes n’utilisant qu’un capteur 2D, la troisième dimension étant simulée par un artefact. Une première solution consiste à projeter une lumière structurée sur l’objet d’intérêt. Cette information connue à priori est déformée par l’objet et permet d’en restituer le volume.Les motifs lumineux généralement employés sont en forme de grille à maillage carré ou de lignes parallèles : le igure n°6 en est un exemple. Une autre approche mise en œuvre lorsque l’objet se déplace est d’éclairer celui-ci d’une double nappe monochromatique dont l’intersection se réalise sur le support de l’objet ( igure n°7). L’écartement des deux traces sur l’objet fournit une information sur l’élévation de celui-ci. Une seconde solution est réalisée en effectuant des prises de vue selon deux points d’observation différents et en corrélant les résultats issus de chaque point. C’est le cas par exemple de la vision stéréoscopique. Figure 6 : Utilisation d’une lumière structurée pour la caractérisation d’un objet (source : F. Rocher and A. Keissling, « Methods for Analyzing Three-Dimensional Scenes », Proc. 1975 Int’l Conf. On Arti icial Intelligence , pp. 669-673).
Figure 7 : Vue d’une bielle de moteur éclairée par une double nappe mono-chromatique (source : W. Myers, « Industry Begins to Use Visual Pattern Recognition », Computer, Vol .13 N°5, May 1980, pp. 21-31) 2.2.3.1. 3D vraie La vraie vision 3D nécessite en général de disposer d’un capteur complémentaire actif. Une première approche est celle adoptée pour le robot mobile HILARE du LAAS. Le robot dispose d’un système de vision plane couplé à un télémètre laser orientable (cf. igure n°8). Après analyse de l’image plane, le système oriente le télémètre vers les zones d’intérêt pour en calculer l’éloignement. Une autre approche a été mise au point par l’INRIA pour l’analyse d’objets industriels. Il s’agit d’un système composé d’un scanner laser et de deux barrettes en réception. Le scanner balaye l’objet d’un pinceau ponctuel, de la position d’un point ré léchi par al surface de l’objet sur chacune des barrettes, on calcule ses coordonnées dans l’espace par triangulation.
2.3. Perception non optique
Des capteurs non optique peuvent compléter les étages de perception d’un système de vision.
Ils peuvent être nécessaires à l’accomplissement d‘une tâche ou présenter une solution plus économique qu’une approche optique totale dans certains problèmes. C’est le cas des proximètres pour conduire l’approche inale d’un manipulateur dans un univers 3D vers un objet ou assurer la sécurité immédiate d’un chariot mobile en cours d’évolution à proximité d’obstacles. C’est encore le cas des barrières de détection employées par la synchronisation des tâches d’un système de vision. Ces dispositifs sont de nature optique ou non (ultra-sons, jet d’air).
D’autres capteurs sont encore employés pour appréhender l’univers, notamment dans le cas de manipulateurs employant des capteurs tactiles permettant de mesurer l’effort développé par les systèmes de préhension (jauge de contraintes, peau arti icielle).
2.4. Éclairage et géométrie de prise de vue
Nous allons nous intéresser essentiellement aux prises de vue bidimensionnelles qui représentent la majorité des applications en vision arti icielle. Pour qu’un système de vision industriel assume correctement la tâche qui lui a été assignée, l’éclairage doit être partiellement ou totalement maı̂trisé. Ainsi autant que le choix d’un capteur, celui de l’éclairage qui lui est associé importe pour s’assurer de son bon fonctionnement. Lorsque le sujet d’intérêt est bien contrasté par rapport à son environnement et n’est pas fait d’une matière ré léchissante, il est possible d’employer un éclairage direct (cf. igure 9.1).Dans ce cas, la géométrie de prise de vue se présente ainsi :
−
les sources lumineuses sont disposées autour de la caméra de manière à ce que leurs faisceaux convergent au centre de la scène pour minimiser les ombres portées.Lorsque les ombres portées sont trop importantes, les sources directes sont remplacées par un éclairage indirect en renversant celles-ci vers un panneau diffusant éclairant la scène (cf. igure 9.2).
Une autre approche pour résoudre ce problème est de rapprocher la source lumineuse du centre focal de la caméra. On le réalise en montant un éclairage annulaire sur l’objectif de la caméra. La igure 9.3 montre cette technique pour un éclairage placé directement dans la tête de l’optique. Lorsqu’on cherche seulement à analyser le contour externe et ceux des trous présents dans l’objet, on emploie un éclairage par ombres chinoises ( igure 9.4). Cette technique nécessite l’emploi de plateaux ou de bandes de convoyage translucides sur des chaı̂nes automatisées. Pour l’analyse de l’état d’une surface, on utilise plutôt un éclairage rasant ( igure 9.5) ; il arrive que l’on doive déplacer la caméra pour la positionner dans l’axe de ré lexion de l’éclairage de manière à augmenter la sensibilité du système de prise de vue pour l’analyse de petits défauts. En dehors des ombres et des ré lexions, un autre problème peut apparaı̂tre lorsqu’on effectue des prises de vue d’objets en mouvement : il s’agit des déformations géométriques dues au temps d’intégration de l’information visuelle par les capteurs. Cet effet de traı̂nage peut être contrecarrer par l’emploi d’un capteur à tube vidicon à longue rémanence et d’un lash déclenché par une barrière optique ( igure 9.6).
De cette manière le tube mémorise le temps de la digitalisation sur sa surface photosensible l’image de la scène igée par le lash.
2.6. Digitalisation d’images
Les systèmes de vision arti icielle sont en général construits autour d’un étage de calcul numérique qui procède à l’analyse du signal issu de son système de perception. Avant de traiter ce signal, celui-ci est digitalisé a in de construire une représentation numérique de l’image à analyser, compatible avec le système de représentation de données de l’étage de traitement. Pour des images planes monochromes, le but est de former une représentation de l’image sous forme d’un tableau numérique d’intensités lumineuses.En général, il s’agit dune matrice Im ,ntelle que chaque élément I(i, j)∈{0 , 1, ⋯, 2 K
1}, où
met n sont les nombres de lignes et de colonnes de l’image numérique et K est le nombre de bits de digitalisation du convertisseur analogique digital employé pour numérisé le signal issu du capteur.
Les fréquences d’échantillonnage employées en traitement d’images sont très rapides : pour la digitalisation du signal on est alors limité à l’emploi de convertisseurs 1, 4, 6 ou 8 bits dont les prix grimpent de manière exponentielle en fonction de la résolution. Nous avons vu que lorsqu’une application demande un forte résolution spatiale, il est possible de remplacer des dispositifs matriciels par des systèmes linéaires alliés à un mouvement. L’emploi des fortes résolutions spatiales est souvent contraint par des impératifs de coût et de temps de réponse. En effet le volume de données à traiter évolue en fonction du carré de la résolution spatiale : les temps de réponse augmentent d’autant comme la taille mémoire permettant de stocker l’image. Les temps d’acquisition augmentent aussi sans qu’on puisse notablement changer les fréquences d’échantillonnage. Pour les capteurs solides, l’emploi de fréquences d’acquisition rapides nécessitent en complément d’augmenter aussi la puissance d’éclairage de la scène pour prendre en compte les contraintes d’intégration du signal lumineux du capteur. En in on se mé iera du fait que certains systèmes de perception ne fournissent pas des fréquences spatiales d’échantillonnage identiques en ligne et en colonne. C’est le cas de certaines barrettes et matrices pour lesquelles les cellules photo-sensibles ont une géométrie rectangulaire. Les mesures effectuées sur des images issues de ces capteurs doivent être corrigées pour tenir compte de la géométrie particulière du réseau de digitalisation.
3. Procédures de perception en vision par ordinateur
3.1. Modèles généraux de perception en vision arti icielle
Les procédures de perception en vision par ordinateur fonctionnent à l’image d’un « entonnoir »:le capteur délivre, après digitalisation, un grand volume d’informations sur une scène, plusieurs procédures sont mises en œuvre séquentiellement pour réduire ce volume sans perdre l’information pertinente qui permettra de délivrer une interprétation inale appartenant à un ensemble ini et réduit d’interprétations possibles (par exemple les 26 lettres de l’alphabet pour un système de reconnaissance de caractères imprimés). Pour mener à bien cette réduction, les procédures convertissent la représentation des informations présentes dans l’image numérique en une nouvelle représentation plus compacte appartenant à un espace différent de celui d’origine. Ces procédures combinent des fonctions de traitement de signal classique avec des fonctions de reconnaissance des formes a in d’aboutir à une interprétation d’une scène. Nous allons nous intéresser dans ce chapitre à trois modèles généraux de reconnaissance :
−
la corrélation de motifs (« pattern matching »);−
la reconnaissance des formes fondée sur la théorie de la décision ;−
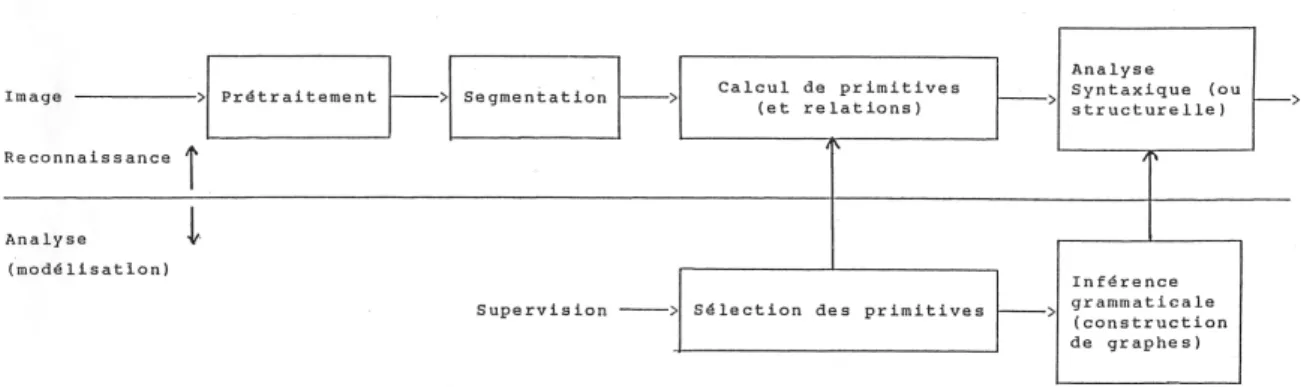
la reconnaissance des formes structurelle. Nous nous intéressons plus particulièrement aux deux derniers modèles, dont le premier relève à la fois selon le point de vue duquel on se place. Les igures n° 10 et 11 en montrent les principes de mise en œuvre de ces deux approches Pour chacune des deux approches, on retrouve des similarités :−
deux modes de fonctionnement, l’analyse et la reconnaissance ;−
deux étapes identiques, le prétraitement et la segmentation.L’analyse ou apprentissage permet au système, avec l’aide d’un opérateur (supervision), d’apprendre les objets qu’il aura à reconnaı̂tre ou les interprétations à produire sur une scène . La reconnaissance représente la phase opérationnelle du système. Figure 10 : Système de reconnaissance des formes statistique Le prétraitement permet au système de prendre en compte les dégradations subies par le signal ou dues à un certain nombre de modi ications de l’environnement externe ou au comportement du système de numérisation. La segmentation a pour but de construire une représentation des ensembles de données homogènes issues du prétraitement. Sur les données segmentées sont calculés dans l’un des cas des attributs et dans l’autre des primitives géométriques. Les attributs sont des mesures sur les ensembles de données homogènes, les primitives permettent d’élaborer une construction structurée de l’image de ces mêmes ensembles. Les objets représentés par des structures construites sur un ensemble de primitives élémentaires sont mémorisées pour être utilisées ensuite par une méthode de reconnaissance comparative.
Figure 11 : Système de reconnaissance des formes structurelle En reconnaissance des formes structurelle, deux approches peuvent être distinguées :
−
l’analyse syntaxique ;−
la théorie des graphes. Pour cette dernière, la structure de représentation est un graphe de primitives modélisant leurs relations les unes avec les autres pour décrire un objet dans la scène. La reconnaissance s’effectue alors par recherche d’isomorphismes entre graphes et sous-graphes d’un modèle et la structure issue d’une nouvelle numérisation. En analyse syntaxique, les primitives sont assimilées à un vocabulaire et l’objet à reconnaı̂tre par l’ensemble des phrases possibles sur ce vocabulaire. L’apprentissage consiste alors à construire la grammaire des règles permettant d’analyser ces phrases. La reconnaissance revient à véri ier que toute nouvelle phrase est admissible par cette grammaire. Cette voie est rarement implantée dans les systèmes de vision disponibles sur le marché car l’inférence automatique de grammaires pose encore des problèmes à résoudre. Par contre, il existe des systèmes dédiés à des domaines particuliers d’application qui suivent cette approche (véri ication de circuits intégrés ou imprimés). Il en est de même pour la corrélation de motifs bien que cette approche conserve la faveur des utilisateurs de systèmes de vision en inspection pour la facilité de mise en œuvre.3.2. Faisabilité d’une application en vision par ordinateur
Nous avons vu qu’en fonction du choix du capteur, certaines contraintes peuvent être dif icile à satisfaire :
−
le précision des mesures ;−
le temps de réponses.La rapidité d’exécution peut être obtenue par déport des problèmes logiciels sur le matériel (algorithmes câblés), mais à des coûts économiques qui ne permettent pas forcément d’amortir aisément l’investissement d’un tel matériel.
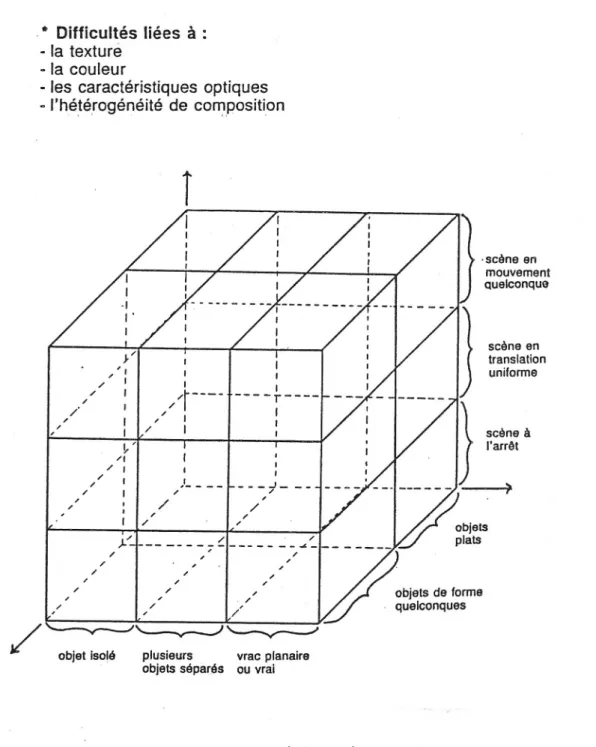
D’autres contraintes peuvent intervenir sur la faisabilité d’une application de vision par ordinateur .
Elles viennent principalement de la complexité de la scène à analyser : le diagramme issu de [1] tente d’en construire une classi ication ( igure n°12).
La complexité croı̂t lorsque l’on se déplace sur la diagonale du cube depuis l’origine.
Nous avons vu que le mouvement pouvait être un atout (pour satisfaire une bonne précision avec une barrette grâce à une translation uniforme) comme un défaut (vitesse de déplacement trop élevée en comparaison du temps d’acquisition).
Lorsqu’on utilise des systèmes de perception bidimensionnelle pour appréhender un univers tridimensionnel, ces systèmes ne prennent en compte que la vue projective des objets dans un plan de vision : cela limite la possibilité d’analyse des objets dans l’espace.
De plus lorsque ces objets ont plusieurs positions d’équilibre planaire, celles-ci doivent être distinguées par le système de vision pour mener sans erreur une procédure d’interprétation.
Figure 12 : Complexité d’une scène visuelle En in le dernier axe modélise l’arrangement des objets dans une scène : les objets peuvent être traités de manière isolée (un seul objet par prise de vue), présentés ensemble de manière séparée (sans contact) ou en vrac. Pour les objets en vrac, on distingue :
−
le vrac planaire (objets en contact ou en recouvrement partiel sur un plan) ;−
en vrac vrai (objets empilés en hauteur).Et le vrac peut être quali ié d’ordonné, de semi-ordonné (palettes de stockage ou de transfert) ou non. Nous verrons par exemple que les modèles de vision fondés sur la théorie de la décision supportent mal les organisations en vrac.
3.3. Prétraitement d’une image
Le prétraitement représente une phase préparatoire à la segmentation d’image. D’une part, il permet d’éliminer les dégradations subies par une image (amélioration, restauration d’image). D’autre part, il permet de fournir les données suivantes à l’étage de segmentation pour que celui-ci identi ie les zones homogènes de l’image. En réalité, le volume d’informations à traiter est tellement important que les seules procédures de iltrage mises en œuvre sont celles qui sont nécessaires à la segmentation et que l’on se satisfera de travailler sur l’image brute sans l’améliorer. Deux manières de préparer une segmentation d’image sont :−
binariser l’image pour séparer les objets d’intérêt du fond de la scène;−
d’appliquer un iltre de dérivation pour détecter les frontières des zones d’intérêt. Pour binariser une image à niveaux de gris, il faut choisir un seuil de binarisation. Pour déterminer ce seuil, on analyse en général l’histogramme de l’image (cf. igure n°13). On se place dans la situation où l’objet d’intérêt a une réponse lumineuse opposée à celle du fond de la scène (objet foncé sur fond clair dans le cas présenté dans la igure). L’histogramme de l’image présente alors deux modes : un maximum pour l’objet et un autre pour le fond séparés par une vallée (un minimum) séparant les deux modes. Lorsque l’objet produit des ombres sur le fond, un troisième mode apparaı̂t dans l’histogramme : on choisit alors la vallée la plus proche de l’objet pour agréger les ombres dans le fond de la scène.Le choix du seuil est réalisé de préférence sur la version lissée de l’histogramme pour supprimer les modes parasites du bruit de numérisation.
Il faut remarquer que ce choix doit être mis à jour à chaque nouvelle acquisition pour s’affranchir des variations d’ambiance lumineuse et de la dérive thermique des étages analogiques.
Cette démarche est mise en œuvre ainsi :
−
calcul de l’histogramme de l’image :{H (l), l= 0 , 2K
1} / H (l) = Card ({I (i, j)=l});
−
lissage de l’histogramme par un opérateur intégral : H1(l)=∑
m= p + p H(l p)⋅A( p) ;−
recherche des modes : mi / H1(mi) = Max{H1(l), l∈{mi p ,mi+ p}} ;−
choix du seuil :s / H1(s) = Max {H1(l),l∈[m1,m2]} ;−
binarisation de l’image : I(i, j)∈{ 0 , 2K 1}→B(i , j)={
1 si I(i , j)≥s0 sinon
}
.Cette approche a pour désavantage que le seuil conserve une valeur ixe pour l’ensemble de l’image,par elle a pour avantage que les régions ainsi dé inies sont bien connexes.
Si l’on se restreint à ne s’intéresser qu’aux frontières des régions, on pourra se satisfaire d’une représentation dérivée de l’image binaire : I(i, j)→{(Yf, Xf)/B(Yf, Xf)=1 a un voisin nul} et
plus particulièrement le dérivé en ligne (transitions) : I(i, j)→{(Yn, Xn,Tn)n=1, N , Tn≠0} où
Tn=B (Yn, Xn) B(Yn, Xn 1).
Figure 14 : Calcul des transitions fond-objet dans une image
L’intérêt de conserver une information de type frontière plutôt que de nature régionale est de réduire le volume d’information à traiter.
On peut obtenir cette information portant sur la frontière des objets en appliquant directement sur l’image originale des opérateurs convolutifs de dérivation :
Hf(i , j)=
∑
m= p + p∑
n= p + p I(i+m, j+n)⋅A(m, p).Par exemple, voici les composantes verticales et horizontales de iltres de dérivation à l’ordre 1 :
−
Prewitt : Ay=[
1 1 1 0 0 0 1 1 1]
, Ay=[
1 0 1 1 0 1 1 0 1]
,−
Sobel: Ay=[
1 2 1 0 0 0 1 2 1]
, Ay=[
1 0 1 2 0 2 1 0 1]
,−
etc. dont on tire le module et l’angle du dérivé de l’image par :−
|
If(i , j)|
=√
(I (i , j)⊗ Ay) 2 +(I (i , j)⊗Ax) 2 etθ
(i , j)=arctan(I(i , j)⊗ Ax I(i, j)⊗ Ay). Les points frontière seront ceux dont le module sera le plus élevé : {(Y , X ,θ
)/|
If(i , j)|
>s}. A l’ordre 2, les opérateurs de dérivation employés sont des Laplaciens :−
AL=[
0 1 0 1 4 1 0 1 0]
,[
12 1 2 4 2 1 2 1]
, etc. Les points frontière seront ceux dont le module est nul (pente maximum de changement de luminosité entre le fond et l’objet) : {(Y , X)/|
If(i, j)|
<ε
}.Figure 15 : Image des passages à zéro d’un Laplaciens
L’avantage des opérateurs convolutifs est d’être mieux adaptés aux variations locales de luminosité dans une image.
Par contre, les contours d’objets qu’ils délivrent ne sont pas forcément connexes et d’épaisseur unitaire.
Cela rend dif icile l’identi ication des composantes connexes dans une image que l’on cherche à segmenter.
Pour satisfaire aux exigences du temps réel, ces opérations sont généralement partiellement ou totalement câblées.
3.4. Segmentation d’une image
Selon la forme sous laquelle on dispose de l’information issue du prétraitement, deux approches permettent de segmenter une image:
−
l’autre frontière.Le but de la segmentation est d’identi ier toutes les composantes homogènes de l’image.
Ces composantes homogènes sont les composantes connexes satisfaisant à un prédicat : un ensemble
V de points de l'image sera connexe si ∀
(
A1, A2)
∈ V ×V il existe une chaı̂ne de points adjacents reliant A1 et A2 véri iant la même propriété, en général le prédicat d'isocoloration.Sur un maillage carré, deux distances permettent de dé inir l'adjacence de deux points :
−
d1(
A1, A2)
, somme des valeurs absolues des différences des coordonnées des deux points ;−
d∞(
A1, A2)
, maximum de ces mêmes valeurs. Les points A1 et A2 seront appelés :−
4 - connexes si d1(
A1, A2)
≤ 1 ;−
8 - connexes si d∞(
A1, A2)
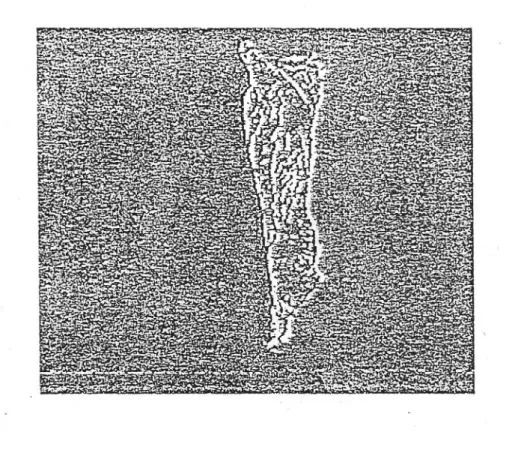
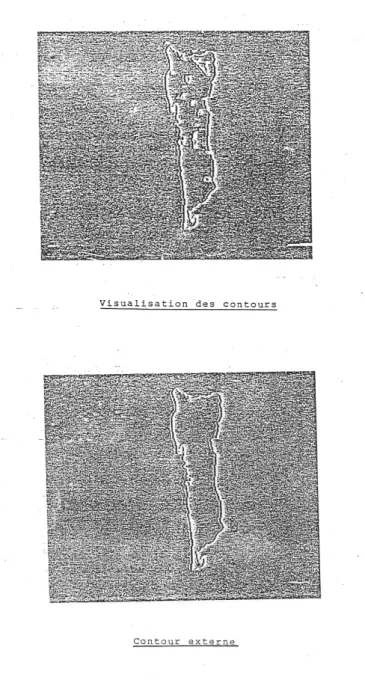
≤ 1 ; Les composantes connexes dans une image seront identi iées selon l’un ou l’autre de ces distances. 3.4.1. Approche régionale Cette approche est rarement employée étant donné le volume d’informations à manipuler. Pour des considérations de rapidité, on lui préfère actuellement l’approche par frontière. Dans une image binaire, les composantes connexes sont identi iées par une procédure récursive d’étiquetage des points de l’image (Rosenfeld). Cette approche pourrait être remise au goût du jour avec l’apparition d’opérateurs systoliques sur le marché.3.4.2. Approche frontière Lorsqu’on dispose de l’ensemble des points appartenant à la frontière des objets présents dans une scène, le but est de retrouver les frontières de chaque objet. En utilisant les relations de connexité entre points, on peut alors identi ier les chaı̂nes de points connexes. Lorsque ces chaı̂nes sont fermées, elles correspondent soit aux frontières extérieures des objets, soit aux frontières des trous à l’intérieur des objets (cf. igure n°16) : ces chaı̂nes forment des cycles. Le but de la segmentation repose alors sur la détection de cycles parmi les chaı̂nes de points connexes parmi l’ensemble des points frontières d’une image et l’ordonnancement de ceux-ci en fonction de leur relation d’intériorité pour distinguer les frontières extérieures des frontières intérieures des objets. La scène est représentée sous la forme d’un arbre dont les niveaux sont fondés sur cette relation d’intériorité. Figure 16 : Décomposition hiérarchique d’une scène Divers algorithmes permettent d’obtenir ce résultat. Nous en présentons formellement un qui s’assimile au graphe d’adjacence linéaire de Pavlidis.
Pour cela nous supposerons ne disposer sur l’image que des coordonnées et du sens de transition de la dérivée en ligne d’une image binarisée : {(Yk, Xk,Tk), k =1 , N }
On va établir les chaı̂nes de points connexes en calculant pour chaque point son successeur succkselon le sens des transitions montantes (positives). On commence par rechercher les connexions en colonne selon la règle : succk=
{
nil si V=∅ n / |Xn Xk|=Min{|Xl Xk|, l∈V }}
c’est-à-dire le plus proche voisin dans l’ensemble des candidats : V={l / Yl=Yk signe(Tk), Tl=Tk & (Xl 1, Xl)∩( Xk 1, Xk)≠∅ ou (Xl, Xl+ 1)∩(Xk, Xk+1)≠∅} Les connexions en ligne se déduisent des connexions en colonnes :si succk=nil alors
{
si succk 1=k alors succk=k+1
si succk+1=k alors succk=k 1
}
Pour retrouver les contours, il suf it de rechercher les cycles dans l’ensemble des liens
{succk, k=1 , N } , c’est-à-dire toutes les chaı̂nes telles que succk=succ *
(succk) .
La igure n°17 visualise pour le sujet précédemment présenté les contours internes et externes, puis le contour externe de manière isolée.
Figure 17 : Contours internes et externe d’un objet Dans cet exemple, les relations d’intériorité entre les contours ont été détectées lors du calcul d’attributs. La segmentation d’objets en employant les relations de connexité entre points d’une même régions ou de sa frontière permet d’isoler plusieurs objets dans une même scène. Par contre les objets en recouvrement ou en contact seront agrégés, ce qui ne permettra pas de les identi ier avec des mesures globales calculées sur les régions ainsi trouvées.
La recherche de connexités sur des frontières rend dif icile le traitement des données issus d’un certain nombre d’opérateurs de dérivation car cette classe d’algorithme suppose que les frontières soient sans trous et d’épaisseur unitaire.
3.5. Corrélation de motifs
C’est une voie qui a été souvent utilisée en inspection visuelle car elle est simple à mettre en œuvre. Elle nécessite d’importantes ressources de calcul et ne parvient pas à l’assurance de produire des résultats de bonne qualité. Lors de l’acquisition d’une image, il s’agit de retrouver le motif {D(k ,l)}dans l’image numérique {I (i , j)}, si celui-ci existe.Cela équivaut à trouver (i0, j0)tel que D(k , l)=I (i0+ j0+l)∀(k ,l)∈motif .
Comme la situation est impossible à observer exactement, on cherche à identi ier le sous-ensemble de {I (i , j)} approchant le mieux {D(k ,l)} : (i0, j0)=Min (i , j) {
∑
k ,l (I (i+k , j+l) D(k ,l))2 }. Soit encore (i0, j0)=Max (i , j) {∑
k , l (I (i+k , j+l)⋅D(k ,l))}. Cette valeur représente la mesure de corrélation entre un sous-ensemble de l’image et le motif recherché. Le motif appartiendra à l’image si∑
k ,l(I(i+k , j+l)⋅D(k , l))>s, où s est un seuil calculé par apprentissage. Pour alléger la charge de calcul, on ne calcule pas le maximum mais une mesure de corrélation entre l’image totale et le motif :
∑
i , j [∑
k , l (I (i+k , j+l)⋅D(k ,l))].On utilise généralement ma valeur normalisée de cette mesure :
∑
i, j [∑
k ,l (I (i+k , j+l)⋅D(k , l))]√
∑
i , j I(i, j)2 ⋅√
∑
k, l D(k , l)2 . L’un des désavantages de cette approche est que l’on ne peut détecter que des motifs invariants en rotation. Elle est aussi sensible aux « hallucinations », lorsque des objets de forme proche du motif à découvrir sont présents dans l’image : il est dif icile de les distinguer par corrélation des motifs recherchés. Les mesures de corrélation sont en réalité peu sélectives. Lorsqu’on travaille sur des images binaires, on peut s’affranchir de l’invariance en rotation en adoptant une démarche de type syntaxiques sur des motifs circulaires. On considère le motif circulaire comme étant une chaı̂ne de caractères sur l’alphabet binaire {0 ,1} : {D(k ,l)} = d = d1d2⋯dm , di∈{0,1} . On concatène la chaı̂nedsur elle-même : d' = d1d2⋯dmd1d2⋯dm 1.Reconnaı̂tre le motif {D(k ,l)}dans l’image {I (i , j)} revient alors à retrouver l’occurrence
{I (i0+k , j0+l)} = p = p1p2⋯ pn , pi∈{0 ,1} tel que p soit une sous-chaine de d ' . Comparer deux chaı̂nes de caractères revient alors a trouver la procédure d’édition permettant de convertir l’une en l’autre avec le minimum d’opérations élémentaires. Si chaque opération élémentaire a un coût, on peut alors calculer le coût de la conversion, appelée distance d’édition entre deux chaı̂nes. Ces opérations élémentaires sont :
−
la substitution d’un caractère par un autre ;−
la suppression d’un caractère ;−
l’insertion d’un nouveau caractère.Pour un alphabet binaire, la calcul de la distance d’édition est très simple à réaliser. Le motif est reconnu si cette distance passe par une valeur minimum suf isamment faible dans l’image. Lorsque c’est le cas, la position de la sous-chaine dans le donne l’angle de son occurrence dans l’image. C’est une méthode simple de reconnaissance qui a été mise en œuvre pour identi ier et localiser des objets. Ainsi la corrélation de motifs peut-être vue comme une méthode de reconnaissance statistique ou structurelle.
3.6. Méthodes topologiques
Ce sont les opérateurs de morphologie mathématique appliqués aux images binaires.Rappelons que les voisins d’un point de coordonnées (i, j) dans une image I forment l’ensemble :
Bd(i , j)={(k , l)/(k ,l)≠(i, j)∧d ((i, j),(k , l))⩽1}
La distance dstructure topologiquement l’image I. Pour des ensembles plans discrets, les distances le plus couramment employées sont :
−
d∞((i, j),(k , l))=max {|i k|,|j l|} ;−
d1((i , j),(k ,l))=|i k|+|j l| ;−
d2((i , j),(k ,l))=√
|i k|2
+|j l|2
.
Les distances d∞ et d1 sont mises en œuvre sur des maillages carrés et d2 sur un maillage
hexagonal.
On dé init alors les opérateurs suivants s’appliquant à toute composante d-connexe V incluse dans
−
érodé (V ) = {(i, j)∈I / Bd(i , j)⊂V } ;−
dilaté (V ) = {(i, j)∈I / Bd(i , j)⊄V } ;−
ouverture (V ) = dilaté (érodé (V ))−
fermeture (V ) = érodé (dilaté (V ))Ces opérateurs sont de puissants outils de iltrage sur des images binaires.
Ils peuvent produire de bien temps de réponse que des iltres classiques de convolution, notamment lorsque l’on travaillent directement sur le frontière des objets à traiter.
D’autres opérateurs similaires à l’érosion et à la dilatation existent : ce sont l’amincissement et l’épaississement. Ils ont pour qualité de préserver le graphe de connexité des ensembles traités. La composition in inie d’un amincissement génère le squelette de l’ensemble sur lequel elle s’applique : les branches du squelette sont les axes médians de l’objet (cf. igure n°18) . C’est aussi un outil de reconnaissance de forme.
3.7. Identi ication d’objets sans recouvrement
Après segmentation d’une image en composantes homogènes, nous pouvons calculer des mesures sur les objets à reconnaı̂tre et les identi ier par des méthodes d’analyse statistique fondées sur la théorie de la décision. Dans cette approche, on tente de caractériser les objets manipulés par un vecteur de mesures qui par la suite permettra de discriminer les objets. Ces mesures sont réalisées de manière globale sur la surface entière de l’objet : elles représentent ses attributs. Elles permettent donc d’identi ier un objet si celui-ci est entièrement visible par le capteur et sans contact direct avec un autre objet.Ces mêmes mesures permettent aussi de localiser un objet dans le plan de prise de vue.
3.7.1. Calcul d’attributs Il serait vain de vouloir faire une liste exhaustive de tous les attributs connus. Aussi nous nous limiterons aux plus conventionnels. Selon le type de scène traitée, il est nécessaire qu’ils soient invariants aux transformations géométriques que peut subir un objet dans le plan image. Dans ce plan, ces transformations sont les similitudes:
−
translation;−
rotation ;−
homothétie. Dans l’espace à trois dimensions appréhendé par un capteur bidimensionnel, il faut y ajouter les projections. Pour cette dernière transformation, il n’est pas connu à l’heure actuelle d’attributs qui lui soient invariants (essentiellement parce que cette transformation est non linéaire). On peut classer les attributs en attributs intégraux et en attributs directs. Les uns étant calculés sur l’intérieur de l’objet, les autres sur sa frontière (le contour). Ces calculs peuvent s’effectuer sur la représentation dans un repère cartésien de l’objet ou sur sa représentation dans le repère polaire centré sur son centre de gravité (cf. igure n°19). Ainsi dans le repère cartésien associé au plan image, les attributs intégraux qui peuvent être calculés sur un objet sont :−
surface et moments du premier ordre dont on tire le coordonnées du centre de gravité de l’objet;−
les moments du second ordre dont on tire les axes d’inertie et l’angle de l’objet dans le repère du plan image;−
les asymétries. En repère polaire, le rayon moyen de l’objet et la variance de son rayon.−
le périmètre de l’objet;−
les cercles inscrits et exinscrits;−
les rectangles inscrits et exinscrits. Et par combinaison des attributs a-dimensionnels comme le facteur de forme qu’on dé init comme le rapport du carré du périmètre sur la surface de l’objet et qui mesure la compacité des objets. Figure 19 : Représentation d’un objet en coordonnées polaires Nous allons nous intéresser plus particulièrement aux attributs déduits des moments généralisés d’un objet. Ils ont l’avantage d’être:−
intégraux, donc moins sensibles au bruit de digitalisation ;−
invariants aux similitudes;−
mutuellement indépendants ;−
et permettent de localiser un objet dans le repère de prise de vue.Et par combinaison des attributs a-dimensionnels comme le facteur de forme qu’on dé init comme le rapport du carré du périmètre sur la surface de l’objet et qui mesure la compacité des objets. Figure 20 : Localisation d’un objet dans l’espace de vision Les moments d'un objet dans le référentiel image sont les suivants :
−
à l’ordre 0 : M(1)=∑
X ,Y∈ objet dm, la surface de l’objet ;−
à l’ordre 1 : M(X )=∑
X , Y∈objet X dm, M(Y )=∑
X ,Y∈objet Ydm ;−
à l’ordre 2 : l’ellipsoı̈de d’inertie M(X2 )=∑
X , Y∈objet X2dm, M(XY )=∑
X , Y∈objet XYdm, M(Y2 )=∑
X ,Y∈ objet Y2dm−
à l’ordre 3 : M(X3)=∑
X, Y∈objet X3dm, M(X2Y)=∑
X ,Y∈ objet X2Ydm, M(XY2)=∑
X ,Y∈objet XY2dm, M(Y3)=∑
X ,Y∈objet Y3dm M(1)représente la surface Sde l'objet. Les coordonnées du centre de gravité sont obtenues à l'aide des moments d'ordre 1 :−
l'abscisse du centre de gravité XG=M (X )/S ;−
l'ordonnée du centre de gravité YG=M (Y )/S . Les valeurs des moments d'ordre supérieur dans le nouveau repère (⃗XGx ,⃗YGy) deviennent :−
M(x2)=M ( X2) XG 2 S−
.−
.−
.−
M( y3)=M (Y3) 3 XG2M( y2) YG3 S Des moments d'ordre 2 se déduisent les axes d'inertie ⃗u1,⃗u2de l'objet : M(u12)=1 2(
M( x 2)+ M ( y2)+√
(
M( x2) M ( y2))
2+ 4 M ( xy )2)
M(u22)=1 2(
M( x 2)+ M( y2)√
(
M( x2) M ( y2))
2+4 M ( xy )2)
et l’angle de l’axe principal d’inertie : θ(⃗X ,⃗u1)=arctg(
M(u1 2) M ( x2) M( xy ))
à π près, que l’on assimilera à l’angle de l’objet dans le référentiel de l’image. Dans le repère propre de l’objet le moment croisé M(u1u2)s'annule et les moments d'ordre 3 deviennent: M(u1 3 )=cos3 θ⋅M ( x3)+3⋅sin θ⋅cos2θ⋅M ( x2y) +3⋅sin2 θ⋅cosθ⋅M ( xy2)+sin3θ⋅M ( y3) . . . M(u2 3 )= sin3 θ⋅M (x3)+3⋅sin2θ⋅cos θ⋅M ( x2y) 3⋅sin θ⋅cos2θ⋅M ( xy2)+cos3θ⋅M ( y3)Le sens des axes ⃗u1 et ⃗u2 est ixé en forçant le moment M(u13) à une valeur positive : M(u1 3 )< 0⇒ θ=θ+ π et l’on change le signe de chacun des moments d’ordre 3. Cela équivaut à donner à ⃗u1 le sens qui offre la plus forte excentricité de l’objet selon cet axe. Ainsi des moments généralisés jusqu’à l’ordre 3, nous pouvons calculer:
−
les coordonnées du centre de gravité XG, YG de l'objet ;−
l'angle θ que fait l'objet dans le référentiel de l'image ;−
des attributs invariants en translation et en rotation pour l’objet :−
M(1) la surface de l'objet ;−
M(u1 2 ), M (u2 2 ) les inerties de l'objet ;−
M(u1 3 ), M (u1 2 u2), M (u1u2 2 ), M (u2 3 ) les asymétries de l'objet. En abandonnant la surface et en normalisant ces valeurs par le inertie principale, les attributs deviennent invariant en homothétie. Pour obtenir des temps de réponse temps réel, on ne peut se permettre de balayer point à point un objet dans une image numérique pour calculer ses attributs. En ce qui concerne le calcul des moments généralisés, on diminue le nombre d’opérations en travaillant sur l’information frontière, notamment sur les transitions en ligne : sachant que{(X , Y )∈ objet}⇒ ∃(k1, k2)/Y (k1)=Y (k2)=Y et que les moments sont décomposables en
M(XiYj)=
∑
Y Yj∑
X Xidm,on peut alors évaluer rapidement les accroissements segment par segment pour calculer M(XiYj)=∑
(k1, k2)∈ objet dM(XiYj). Il faut noter que les meilleures performances en temps de réponse nécessitent de pouvoir conserver des structures de données homogènes d’une étape de traitement à l’autre.3.7.2. Reconnaissance statistique On désire pouvoir distinguer différents objets physiques les uns des autres et les nommer. Pouvoir les nommer revient à leur associer une étiquette, celle de leur classe d’appartenance. A chaque objet distinct, on assigne une classeCk . L'univers de reconnaissance est alors l'ensemble des m classes
{
C1,C2,⋯,Cm}
. Il suppose l’existence d’un univers de représentation dans lequel chaque objet est associé à un vecteur de mesures X . La phase d’apprentissage va permettre d’évaluer le partitionnement de l’espace de représentation par des classes Ck de l’univers de reconnaissance.L’évaluation de cette partition est effectuée sur l’ensemble des expériences issues de la phase d’apprentissage.
Cette évaluation faite, le système est alors capable de reconnaı̂tre lui-même la classe d’appartenance de toute nouvelle expérience, c’est-à-dire nommer correctement tout nouvel objet qui lui est présenté par le moyen d’un vecteur de mesures.
Les méthodes de reconnaissance statistique peuvent être regroupées en deux approches ([14]) :
−
des attributs invariants en translation et en rotation pour l’objet :les méthodes permettant d’estimer la densité de probabilité à l’intérieur des classes (méthodes bayésiennes) ;−
les méthodes permettant de construire les surfaces séparatrices (frontières) des classes (méthodes non bayésiennes).Chacune de ces deux approches peut se scinder en deux sous-familles :
−
les méthodes paramétriques où les estimations se font en évaluant les paramètres de fonctionnelles minimisant un critère d’erreur ;−
les méthodes non paramétriques où la dé inition de la classi ication est fondée sur des critères topologiques.−
paramétriques bayésiennes : l’estimation d’une densité de probabilité au sens du maximum de vraisemblance (dont nous allons en développer un exemple ci-dessous) ;−
paramétriques non bayésiennes :les fonctions discriminantes basées sur la séparation linéaire (les « perceptrons ») ;−
bayésiennes non paramétriques : les fenêtres de Parzen ;−
non bayésiennes non paramétriques : les plus proches voisins. A ces méthodes, on peut encore rajouter :−
les méthodes séquentielles de décision minimisant l’entropie d’un questionnaire ;−
l’analyse descriptive des données (analyse en composantes principales, analyse discriminante) qui permet de réduire la dimensionnalité de l’espace de représentation (sélection des mesures) ;−
la classi ication automatique : hiérarchies indicées et méthodes topologiques de partitionnement.Le but de la reconnaissance statistique des formes étant d’associer sans ambiguı̈té l’objet numérique
X dé ini par ses attributs à l’une des classes Ck : nous allons en présenter la méthode pour une méthode bayésienne paramétrique.
Cette méthode se propose d’approximer en moyenne quadratique les probabilités d’appartenance des objets aux classes en fonction de leurs vecteurs d’attributs.
Les probabilités d'appartenance d'un vecteur de mesures X aux classes
{
Ck}
sont représentées par le vecteur de dimension m :V=
(
P(
X/C1)
, P(
X/C2)
,⋯, P(
X/Cm)
)
Les probabilités à priori pour un vecteur X appartenant à l’un des classes sont ixées à :
W1=(1 ,0 ,⋯,0 )si X∈C1 ;
W2=(0 ,1 ,⋯,0 )si X∈ C2 ;
L
Wm=(0 ,0 ,⋯,1 ) si X∈ Cm .
Les classes d’objets sont décrites par une population d’apprentissage
{
x1, x2,⋯, xn}
, où n est le nombre d’expériences de la base d’apprentissage et x un vecteur d’attributs.On construit la base d’apprentissage étendue :
{
(
x1, v1)
,(
x2, v2)
,⋯,(
xn, vn)
}
où vi=wj si xi∈ Cj .Alors l'estimation linéaire ^v de v au sens des moindres carrés qui minimisera le critère:
v=
∑
i=1 n (vi ^vi) (vT i ^vi) sera l'expression : ^v =RvxRxx 1(
x Mx)
+ Mv , où Mx est la moyenne des vecteurs attributs, Mv est la moyenne des vecteurs de distributions à priori, Rvx est la matrice de covariance des variables v et x , Rxx est la matrice de variance de la variable x . La procédure de reconnaissance est mise en œuvre en recherchant pour toute nouvelle expérience quel vecteur wj est le plus proche de ^v :x∈Cjmin/ ( ^v wjmin) (^v wjmin)
T = Min{( ^v wj) ( ^v wj) T , j=1 ,m}, La reconnaissance est subordonnée à un seuil de rejet calculé lors d’un apprentissage complémentaire : sj= m1 j
σ
2 j+m2 jσ
1 jσ
1 j+σ
2 j , où m1 j,σ
1 j sont la moyenne et la variance de {^v (xi)/ xi∈Cj}, m2 j,σ
2 j sont la moyenne et la variance de {^v (xi)/ xi∉Cj}.Nous venons de présenter une méthode de reconnaissance de formes fondée sur l’estimation linéaire.
Figure 21 : Analyse et reconnaissance de formes par la théorie de la décision
Reconnaı̂tre des objets permet d’aborder les problèmes de tri et d’identi ication.
Si l’on traite des problèmes d’inspection, ces méthodes ne répondent pas expressément aux besoins.
Si il s’agit de véri ier la conformation d’un objet, on peut véri ier celle-ci par une approche similaire à celle que nous venons de présenter.
Au lieu d’évaluer une probabilité d’appartenance d’un objet à une classe, la véri ication de conformité d’un objet à un modèle peut être posé comme véri ier si les attributs de l’objet sont corrélés à ceux du modèle. Supposons, comme nous l’avons vu au chapitre précédent, que les objets soient représentés par leur vecteur de moments : ( M(1), M(u1 2 ), M (u2 2 ) , M(u1 3 ), M (u1 2 u2), M (u1u2 2 ), M (u2 3 )).
Si l’on estime l’un des attributs, comme par exemple la surface du modèle, en fonction des autres S=a xT + b pour véri ier que l’objet est conforme au modèle, il suf it alors de véri ier que la différence |S ^S| soit minimum. Le même algorithme de résolution peut alors servir à faire de la reconnaissance d’objet comme de la véri ication de conformation. Il faut remarquer qu’on normalise les attributs par rapport à eux-mêmes pour éviter des problèmes de mauvais conditionnement lors de l’inversion de la matrice Rxx. Pour conclure sur la reconnaissance statistique d’objets dans le plan, nous avons présenté, en igure n°21, les différentes étapes de traitement en fonction du but recherché.