Comparison of Different Lexical Resources With Respect to the Tip-of-the-Tongue Problem
61
0
0
Texte intégral
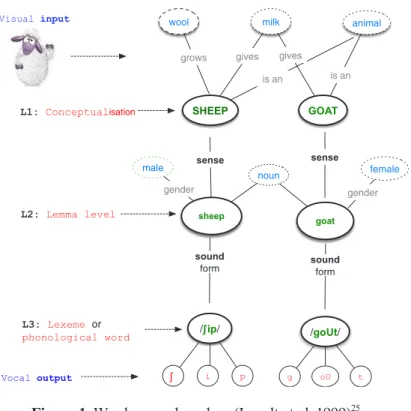
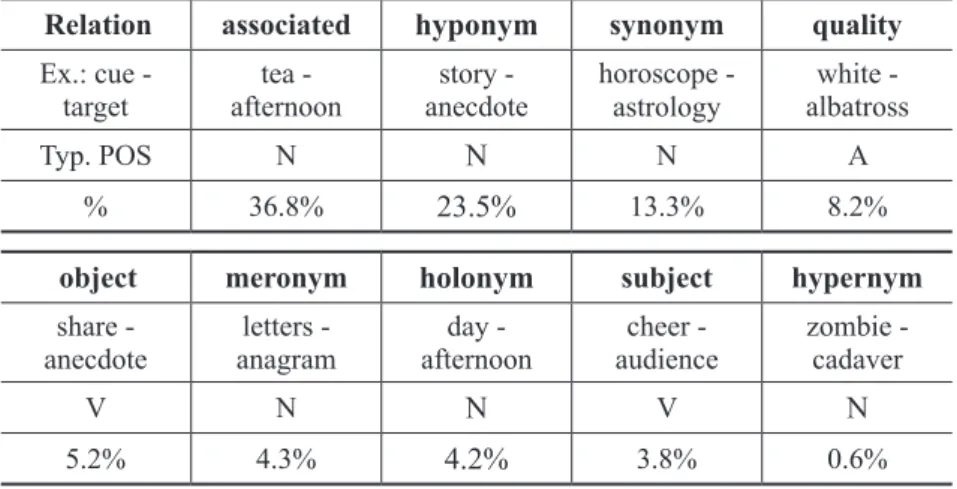
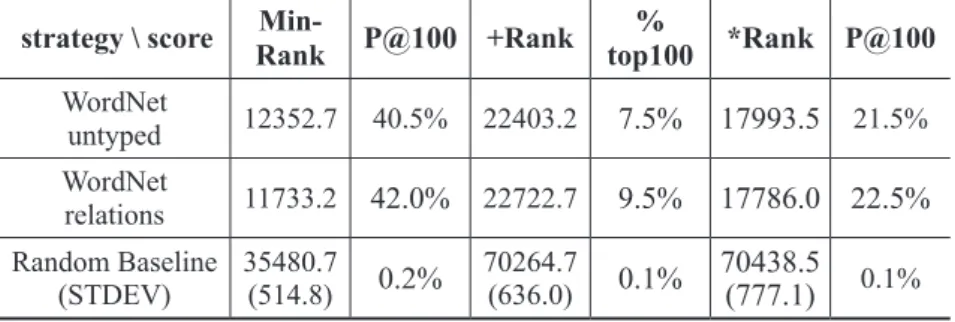
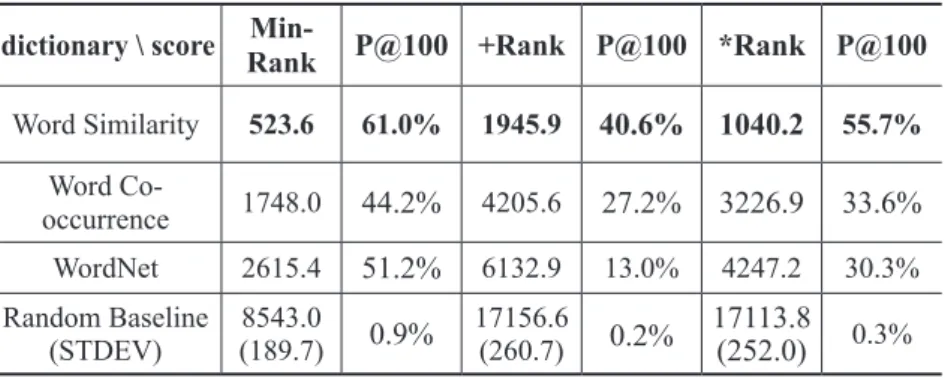
Figure
Documents relatifs