Astronomical Image Denoising Using Dictionary Learning
Texte intégral
Figure






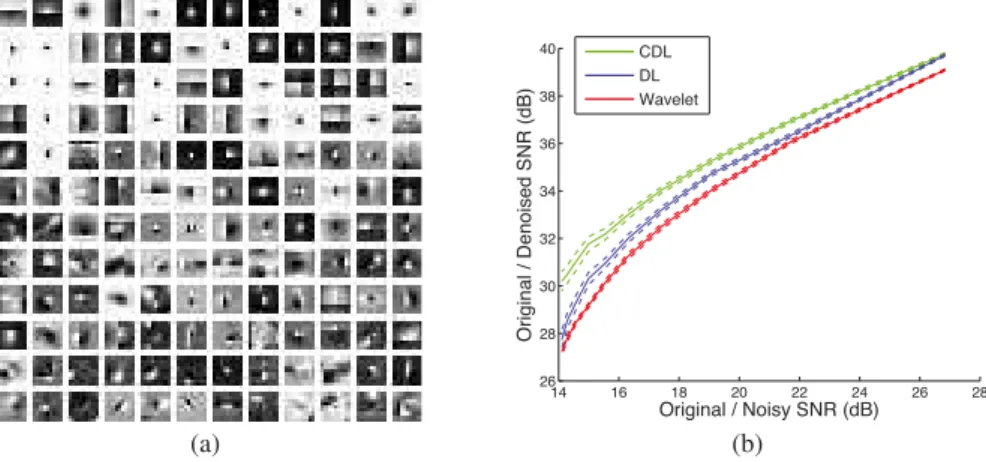
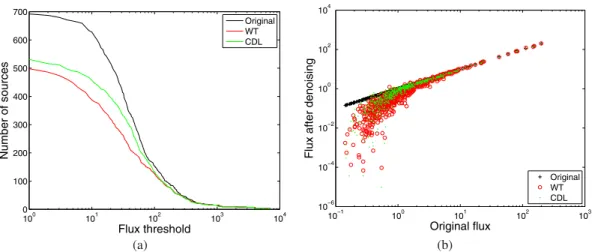

Documents relatifs
En este caso, es decir, para la generación de contenidos median- te la colaboración entre profesores de secundaria, hay muchos obstáculos a superar antes de que el modelo
Example results are (i) the mean and variance of the number of (possibly overlapping) ordered labeled subgraphs of a labeled graph as a function of its randomness deficiency (how far
Conclude to the existence and uniqueness of a global (in time) variational solution to the nonlinear McKean- Vlasov equation..
In conclusion, we have shown in this paper that highly excited strings are hardly produced at the end of inflation, because | β | 2 is highly suppressed by a exponential factor
cases are considered : the diffraction of an incident plane wave in section 3 and the case of a massive static scalar or vector field due to a point source. at rest
Au total il y a donc un seuil de perceptibilité des structures de petite taille et à faible contraste propre, et ce seuil est directement lié à la dose d'exposition ... 2-Un
Analysez chacun d'eux et dégagez la (les) piste(s) de possibles couples mère-fils.. Choisissez un des quatre documents et la piste qui vous lui avez
The software receives from the data analyst the training session parameters (mean, standard deviation, number of epochs, number of images per mini batch, learning rate
