Properties of the Stochastic Approximation EM Algorithm with Mini-batch Sampling
Texte intégral
Figure




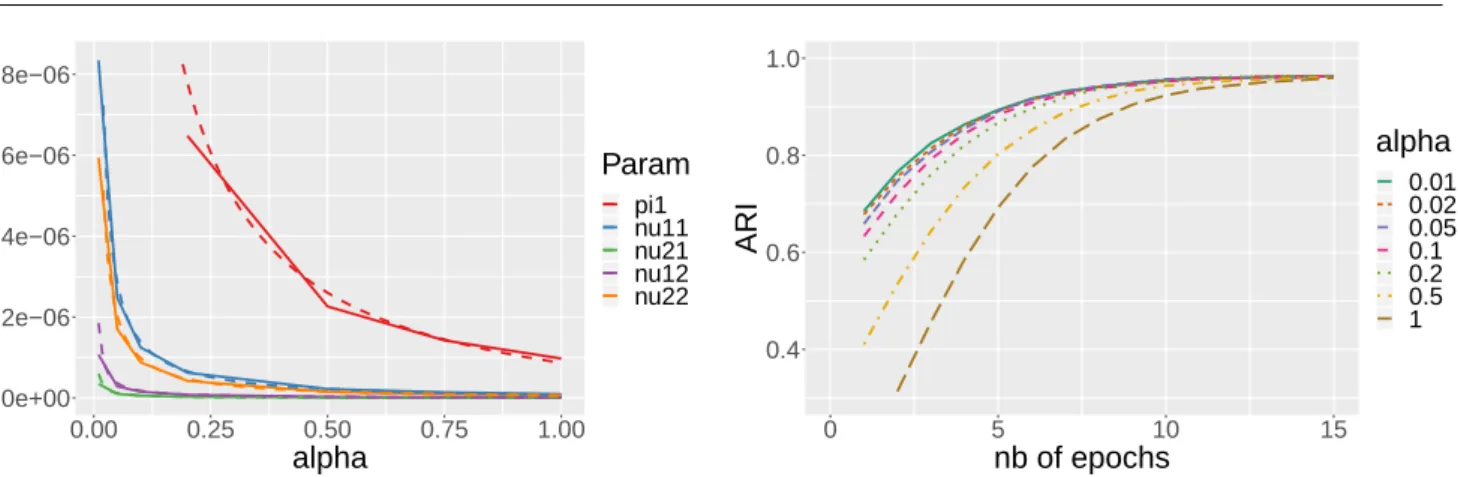
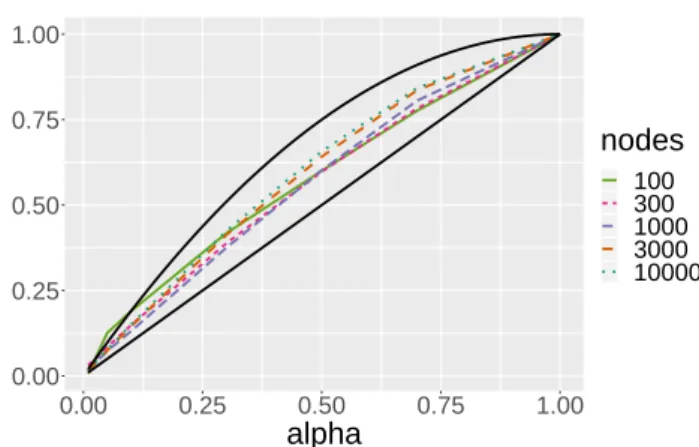
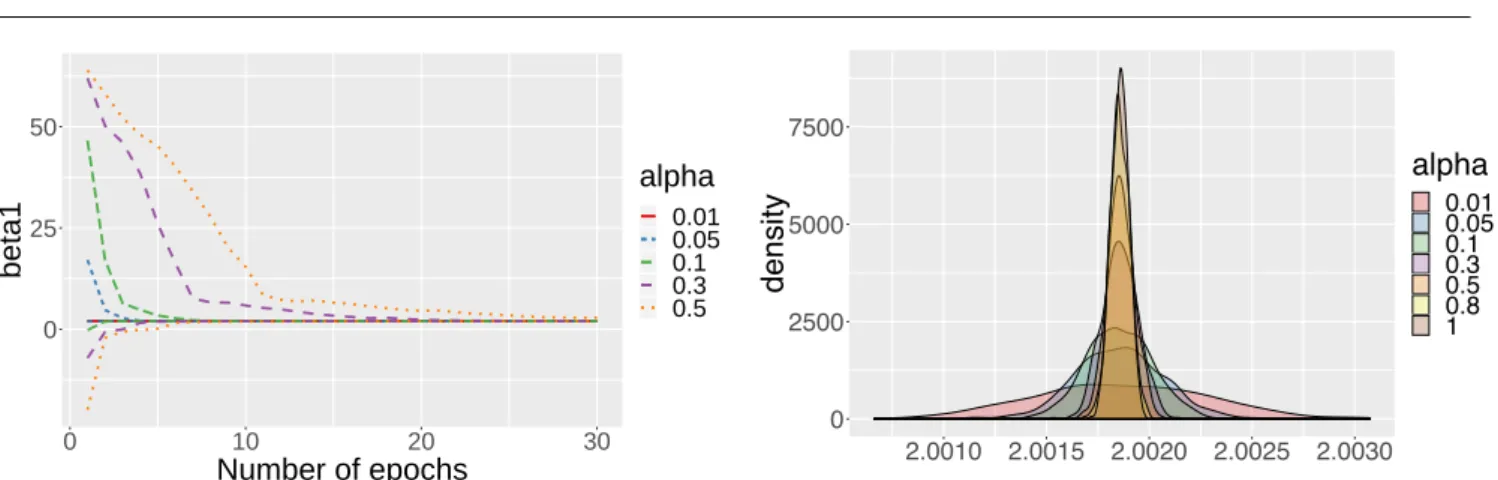
Documents relatifs
Finally, in the last section we consider a quadratic cost with respect to the control, we study the relation with the gradient plus projection method and we prove that the rate
We then establish the almost-sure convergence of the mini-batch version of the MCEM using an extension of the MISO framework when the surrogate functions are stochastic.. The
We prove that anytime Hedge with decreasing learning rate, which is one of the simplest algorithm for the problem of prediction with expert advice, is remarkably both worst-case
harveyi organ- isms in abalone organs (i.e., gills-hypobranchial gland, digestive gland, and foot muscle) and in hemolymph has elucidated the infection dynamics.. harveyi was
The dynamic initialization of the 5 starting matrices is provided through the initMatrix function, which has as input the matrix to initialize, its size, and the initial value that
In this work, a receding horizon observer is used to estimate the individual amounts of monomer in the reactor as well as the number of moles of radicals in the polymer (µ) using
We will show that, provided the decreasing step sequence and the constant pseudo-step T are consistent, this allows for a significant speeding-up of the procedure (as well as
An implicit solver, based on a transport equation of void fraction coupled with the Navier-Stokes equations is proposed.. Specific treatment of cavitation source
