HB31
.M415[DEWEY
working
paper
department
of
economics
CHOOSING
THE
NUMBER
OF
INSTRUMENTS
massachusetts
institute
of
technology
50 memorial
drive
WORKING
PAPER
DEPARTMENT
OF
ECONOMICS
CHOOSING
THE
NUMBER
OF
INSTRUMENTS
StephenG.Donald Whitney K.
Newey
No. 99-05 February, 1999MASSACHUSEHS
INSTITUTE
OF
TECHNOLOGY
50
MEMORIAL
DRIVE
CAMBRIDGE.
MASS.
02142
Digitized
by
the
Internet
Archive
in
2011
with
funding
from
1
Introduction
There
hasbeen
a resurgence of interest in the applicationand
properties ofinstrumentalvariables (IV) estimators.
An
important
problem
inIV
estimationis choosing thenumber
of
vahd
instruments, ormore
generally a subset of all the instrumentsknown
tobe
valid.The
properties ofestimators are sensitive to this choice (e.g. seeMorimune,
1983), evenin applied
work
withmany
observations (e.g. seeBound,
Jaegerand
Baker, 1996).We
address this
problem by
providing simpleapproximate mean-square
error(MSE)
criteria,that
can be minimized
to choose the instruments.We
give these criteria for two-stageleast squares (2SLS), limited information
maximum
likelihood(LIML),
and
the JacknifeIV
(JIVE)
estimator of Angrist, Imbens,and
Kreuger
(1995).We
alsocompare
theapproximate
MSE
of these estimators,and
findLIML
is best.Our
criteria isbased on
higher-order asymptotic theory,Hke
that ofNagar
(1959),Anderson
and
Sawa
(1979),Morimune
(1983),and
Rothenberg
(1983).Our
approximate
MSE
criteria are like those ofNagar
(1959), beingbased
on
theMSE
of leadingterms
inan expansion
oftheestimator.Thisapproach
is wellknown
to givethesame
answer
as theMSE
of leadingterms
inan
Edgeworth
expansion,under
suitable regularity conditions(e.g.
Rothenberg,
1984),and
hasbeen used
innonparametric
and
semiparametricmodels
by
Andrews
(1991a), Linton (1995),and
Powelland
Stoker (1996). Fork-class estimators our calculationsextend
those ofNagar
(1959)and Rothenberg
(1983) to the misspecifiedfirst-stage case.
We
also providenew
results for the jacknifeIV
estimator(JIVE)
of Angrist,Imbens
and
Krueger
(1995).A
number
of recent studieshave
considered the properties ofIV
estimatorswhen
instruments areonly
weakly
correlated with theendogenous
righthand
side variables. In particularNelson
and
Startz (1990),Maddala and
Jeong
(1992),Bekker
(1994),Bound,
Jaeger
and
Baker
(1996),and
Staigerand
Stock (1997)have
shown
thatstandard
IV
estimators, including the
2SLS
estimator, tend tobe
biasedtowards
the inconsistentOLS
estimatorand
that inferencesbased
on
2SLS
canbe
quite misleading,when
themat-ter, choosing the instruments
may
helpimprove
the approximation, particularlywhen
the source of
weak
correlation is extraneous instruments that shouldbe
excluded. For example,we show
that in data like that ofAngristand Krueger
(1991) our criteria willchoose the smallest
number
of instruments,where
there is less evidence of aproblem
ofweak
correlation.Our
criteria for choosinga subset of valid instrumentsis the estimatedMSE
ofleadingterms
inan
expansion. Thisapproach
is differentthan
Andrews
(1996),who
basesinstru-ment
choiceon
theGMM
criterion function.We
are choosing instrumentsfrom
a subset that isknown
to be valid while he is searching for the largest set of valid instruments.Our
approach seems
ideally suited tomany
applications inmicroeconomic
data,where
there is a large set ofinstruments all thought to
be
valid.Examples
include the draftlot-tery
number
asan
instrument for military service, as in Angrist (1990),and
interactions of covariates with instruments, as in Angristand Krueger
(1991).Our
results also applyto the choice of nonlinear functions to use in the efficient semiparametric instrumental
variables estimator of
Newey
(1990).Here
we
derive the optimal,MSE
minimizing
num-ber of instruments to use, answering the important question of
how
to pick thenumber
of instruments in optimal semiparametric estimation.
The
number
of instruments canbe thought
of as asmoothing parameter
for thenonparametric
component,
as hasbeen
consideredby
Linton (1995)and
Powelland
Stoker (1996) for other models.In Section 2
we
describe theIV
estimatorswe
consider, present the criteria forin-strument
choice,and compare
these criteria for different estimators, seekingtheone
withsmallest higher order
MSE.
In section 3we
derive theapproximate
MSE
forLIML,
2SLS
and
JIVE when
there areno
covariates. Section 4 studies the properties of the criteriatheoretically
and shows
that they canbe
implemented
in away
that is optimal in a certain sense. Section 5 allows for covariates in the theoretical results. In section 6we
present a
Monte-Carlo
experiment. Section 7 presents the results ofapplyingthe criteria in the Angristand
Krueger
(1991) appUcation.2
The
Model,
Estimators,
and
Instrument
Selection
Criteria
The
model
thatwe
consider is,Vi
=
1^1+
2:^/3+
ei, E\ei\x^=
0,V"ar(ei|xi)=
o\, Yi=
f{x^)+
Ui,E[ui\xi]=
0,Var{ui\xi)=al,
for i
=
1, ...,N,where
yi,and
Yi are scalars, x, is a dx
1 vector ofexogenous
variables,and
Xii is a diX
1 vector ofexogenous
variableswhich
areassumed
tobe
a subset ofXi,
where
we
assume
homoskedasticity throughout.We
alsoassume
that conditionalthird
moments
are zerothroughout
the paper.The
first equation is the equation ofinterest
and
the righthand
side variable Yi is possibly correlated with e, so thatgenerally E{uiei\xi)=
aue 7^ 0,The
second equation represents thereduced
form
relationshipbetween
Yiand
theexogenous
variables Xiwhich
is allowed tobe
nonparametric, withf{xi)
=
E{Yi\x,).Because
oftheconditionalmoment
restriction E{ei\xi)—
0, functions ofXjcan be used
as instrumentsinestimating the equationofinterest. Letipf
=
(ipiKi^i),,4'KK{^i))' be
a vectorofK
functions tobe
used asinstrumental variables,where
we assume
throughout
that xpf" includes Xu.They
couldbe
approximating
functions, such aspower
seriesor regression splines, as in
Newey
(1990).The
problem
we
consider ishow
to choosethis instrument vector so that the associated
IV
estimatorshave
good
properties. Forsimplicity
we
have
allowedK
to serve asboth
thenumber
of instrumentsand
the indexof the instruments, but
we
could proceedmore
generallyby
specifying a different indexfor the instruments. If
we
did that the criteria couldbe
used tocompare
instrumentalvariables estimators with the
same
number
of instruments.We
consider several differentIV
estimators.To
describethem
let^^ =
[ip^,...,ip^]'
be
thematrix
ofobservationson
the instrumentalvariables,P^
=
^'^(^^'^'^)~i^-'^' theassociated projection matrix, y
=
(yi, ...,yn)',Y
=
(Yi, ...,y„)',Xi
=
[xn, ...,Xin]',W
=
overA,
where
Pi=
Xi(XjXi)
^X[.The main
class ofestimators considered is the k-classwhich
includes estimatorswhich have
the form,6={{1
+ k)W'P^W
- kW'W)-\{1
+
K)W'P^y -
nWy)
where
the scalark
is given by,ad
+
j^
K
=
l-a9-j^
for constants a
and
b. This class of estimators includes2SLS,
where
a=
b=
0,LIML,
where
a=
1and
6=
0,and
a bias-corrected2SLS
estimator like that ofNagar
(1959),denoted
hereby
B2SLS,
where
a=
and
b=
K
—
(2+
di). This class of estimators issimilar to that considered
by
Rothenberg
(1983).The
other estimator considered is the JackknifeIV
estimator(JIVE)
proposed
by
Angrist,
Imbens
and Krueger
(1995). It has the form,(
IJ\
_
{
y'C'Y
Y'C'X,
\~
Y
Y'C'y \
[Pj
)-[
X[Y
X[X,
)
[X[y
)
where
C
is the matrix with Cij=
Pij/{1—
Pa) for i 7^ jand
Cu
=
0.Note
thatCY
has the interpretation as the vector of predictions of the Yi given all but the ith observation,hence
the Jackknife terminology.The
instrument selection criteria arebased
on
theapproximate
mean
square error(MSE)
for theendogenous
variable coefficient estimator 7.Implementing
these criteriarequires preliminary estimates of
some
of the parameters ofthemodel
and
agoodness
offit criteria for estimation ofthe reduced
form
using the instruments ipf. Let 6 denote apreliminary
IV
estimatorand
let e=
y—
W6.
Also, letu
denotesome
preliminaryreduced
form
residual estimator, such as that obtainedfrom
the residualsfrom
the regression ofy
on
^^
forsome
fixedK.
Then
leto-,^
=
e'e/N,al=
u'u/N,
Uu^=
u'e/N.It is
important
inwhat
follows thatnone
ofthese preliminary estimatorsdepend
on
K.
For
example
Smight be an
IV
estimator with just one instrument for Yi, or itmight be
offit criteria given below. Similarly, the
reduced
form
residualu
might be from
the firststage regression
with
the best fit. Inany
case these estimatesmust
remain
fixed as thecriteria for different instruments sets is calculated.
The
reduced form goodness
offit criteria canbe
formed
in at leasttwo
ways. Letu^
denote
thereduced form
residual vectorfrom
regressingY
on'^^
.The
Mallows goodness
of fit criterion for the
reduced form
isR{K)
=
{u^'u^/N){l
+
~^)
The
cross-validationgoodness
of fitmeasure
is^f)
2Eitherofthese will
have
suitabletheoretical properties forusein theinstrument selectioncriteria.
The
preliminary estimatesofcovarianceparameters
can be
combined
with
thereduced
form goodness
of fitmeasures
toform
criteria for the choice of instruments foreach
of2SLS,
LIML,
and
JIVE
asS2SLs{K)
=
al^
+
aUR{K)
- al^)
suml{k)
=
^![m)~^^)
For each estimator, choosing
K
tominimize
the correspondingS{K)
will result in7
that has relatively smallMSE
asymptotically.These
criteria also will applywhen
K
is notthe sole index of the instruments, e.g. for
comparing two
different sets of instruments thathave
thesame
number
ofinstruments.Choosing
the estimatorwhere
the expressionon
the right-hand side is smallest will result in the bestasymptotic
MSE
in that case as well.It is interesting to
compare
the size of the criteria for different estimators,because
LIML
and
JIVE
criteria areboth
of smaller orderthan
the2SLS
criteria. This reflectsthat the bias of
2SLS
increases with thenumber
ofinstruments at a higher ratethan
theother estimators, a result previously established
by
Morimune
(1983). Consequently, forlarge
numbers
of instrumentsboth
LIML
and
JIVE
shoulddominate
2SLS
interms
ofMSE.
Also, the criteria forLIML
is smallerthan
that forJIVE,
so thatLIML
is bestamong
these three estimators.As
previouslyshown
by Rothenberg
(1983) for the fixedinstrument case, it turns out that
LIML
is bestmedian
unbiasedto the orderwe
considerin the k-class of estimators.
3
The
Mean
Square
Error
For
much
of this sectionwe
focuson
the simplestmodel
which
is a special case of themodel
considered in Section 2. In particularwe
focuson
the model:Vi
=
lYi+
Ci Yi=
f{x,)+
Uiforz
=
I, ...,N,where
yi,Y^and
e, are all scalarsand where
Yi is possibly correlated withCj. In Section 3.5
below
we
show
how
theMSE
criteriacan
be extended
tomodels
withcovariates as considered in Section 2. In this case, the estimator for
7
is given by,7
=
((1+
K,)Y'PY
-
kY'Y)-\{1
+
K)Y'Py
-
KY'y)where,
l-a9-j^
N
with
6 being theminimum
value of, X'Y'PY
X/
X'Y'Y
\.The
other specific estimator considered isJIVE, which
isdenoted
by,7j
=
(Y'C'Yy^Y'C'y
where
C
was
described in Section 2. UnfortunatelyJIVE
does notappear
to fit into the k-class of estimators so thatMSE
calculations willhave
tobe
performed
separately.3.1
Calculation
Our
approach
to finding theapproximate
MSE
is similar to that ofNagar
(1959). Firstwe
normahze
the estimator (let7
denote a generic estimator),ViV(7-7)
=H-^h
where
H
and
h
are different for different estimatorsand
have
population counterparts,h
=
i/'e
and
Then we
use the expansion.„_f'f
H-'h
=
[{I-{H-H)H-^)H]-\h +
Ch-h))
=
H-\h
+{H
- H)H-^h
+{H-
H)H-\h
-
h)+
{H
-
HfR-'^h
+
...and
note that sinceH"^
is acommon
factor for allterms
in the expansion, Avecan
calculate
an approximate
MSE
by
taking expectations of the square of the expression,Hy/N{^-^)
=
h
+
{H-H)H^^h
+{H
-
H)H-\h
-h)
+
{H-
HfH-'^h
+
...Then
followingNagar
(1959)we
find theMSE
of this expression using the largest (inprobability)
terms
inthe squareofthisexpression, althoughsincewe
are interestedin theselection of
K
and
allowK
—
>• 00we
include only thoseleadingterms
in theMSE
that arepertinent tothe choice of
K
for the estimator of interest.Thus
terms
thatdo
notdepend
on
K
willbe
omitted.Because
of this fact,terms
beyond
thesecond
willnot (ingeneral)contribute to the
approximate
MSE
criteria tobe used
for selection ofK
, eventhough
they
do
contribute to theMSE
in the casewhere
one has a fixedK
and
one
obtainsan
approximation
to theMSE
to0{\/N).
For the purposes of completenessand
to enable other types ofcomparisons
we
also provideapproximate
0{1/N)
MSE
calculations forfixed
K. These
calculations extend thework
ofNagar
(1959)and
Rothenberg
(1983) tothe case
where
there is a possible misspecification in the first stage. In such a calculationthe third
and
fourth termsdo
contribute to theapproximate
(to0{\/N)) MSE.^
Note
that the leadingterm
(which is 0(1)) in theapproximate
MSE
willbe
E{hh!)
=
a'J-^
and
that this willbe
common
to all of ourapproximate
MSB's.
Since thisterm
hasno
bearingon
the choice ofK
and
since it iscommon
to all of our estimatorswe
omit
theterm from
the expressionswe
presentand
focuson
theremaining
terms. All calculations aredone
conditionalon
theexogenous
variables Xi,The
assumptions which
are used to derivean approximate
MSE
arenow
statedand
discussed.
Assumption
1Assume
that {xi,Ui,ei] are iid,and
satisfy,(i) E{u^\xi)
=
E{ei\x^)=
0,(ii)
<
E{uf\xi)=
al<
ooand
<
E{ej\xi)=
a^<
oo,(in) E{ui'ei^\xi)
=
0, forj+
k being a positiveodd
integer such that k+
j<
5,(iv) E{\ui\^\ei\^\xi)
<
oo, forany
positive integers jand
k such that k+
j<
5,(v) Xi have support
X
C
R^
that is the Cartesian product ofcompact
intervals.Assumption
l(i)was noted
in Section 2.Assumption
l(ii) is a homoskedasticityassump-tion that simplifies the calculations while
Assumption
l(iii) is asymmetry
assumption
which
implies thatboth
residualshave
symmetric
distributions. This willbe
satisfied iftheresiduals arejointly
normally
distributed.Assumption
l(iv) requires the existence ofat least five
moments
for the residuals.Assumption
l(v) is standard in the literatureon
series
based
nonparametric
regression.The
nextAssumption
concerns the nature of theoptimal instrument function /.
Assumption
2The
function f{xi)=
E{Yi\xi) is such that,(i)
f
:X
-^R
and
hasan
extension to all ofR^
that is s>
times continuouslydifferentiable in x,
(a) with probability 1,
<
c<
N~^
'^^^-^ f{xi)'^<
c~^ forsome
small constant cuniformly in
N
.
Assiimption 2(i) is a
smoothness
condition that allows one to obtainapproximation
rates for series
based
methods.
The
second part of thisassumption
isan
identificationassumption
that requires that /(xj) notbe
identicallyzerowhich
would
result in7
beingunidentified. This will
be
modifiedwhen we
consider the introduction of covariates intothe structural equation.
Assumption
3: LettingPa
denote the ith diagonal element ofP,
assume
thatsup
Pu
-^i<7V
as
N
^>- 00 withprobability one.It should
be
stressed that thisassumption
is not required forone
toshow
thatyN{'y
—
'y) is asymptotically normal,and
is only necessary to obtain tractable expressions for theMSE.
It requiressome
restrictionson
the rate atwhich
K
increaseswith
thesample
sizethat are
much
strongerthan
thoseneeded
toshow
asymptotic normalityoftheestimators.It should
be noted
however
that as long as s inAssumption
3 is sufficiently large therestrictions will allow for
K
to increase at a rate that results in the fastest possible rate ofconvergence oftheMSE
expression to zero.^Our
first result givesan approximation
to theMSE
for a subclass of the k-classestimators
we
are considering. In obtaining all ofourapproximations
we
have
restricted attention to k-class estimators thathave
values of aand
b that satisfy certain properties. In particular it isassumed
that a=
0(1)
while b=
0{K),
which
includes all of the Donald(1997) hasshownthatforpowerseriesonerequiresthatK^/N
—
>when
Xi hasa continuousestimators
mentioned above and
ensures that the estimators willbe
consistent.'^The
first subclass of estimators consists of those for
which
theapproximate
bias (to orderN~^^'^) is increasing in
K.
Unless otherwise stated allMSE
will refer to theterms
in the largesample
largeK
MSE
that aredominant
amongst
those that increasewith
K
and
those that decrease with
K.
Proposition
1Given Assumptions
1-3,assuming
that a—
0(1)
and
b=
0{K)
suchthat {l
—
a)— b/K
isbounded
away
from
0, theMSE
for\/N{'y—^)
is approximately[{l-a)K~bf
,,f'{I-P)f
crL-
U€h
+
(y.N
'N
It is straightforward to
show
that theapproximate
bias, to0{N
^/^) is of the form^[(l_a)/<-6-(2-a)]a„,
ff'fY'
/TV
\N
•^^-^
and
that for estimators in the classunder
considerationwhose
biasterm grows with
K
,
the leading
term
in theMSE
comes
directlyfrom
the squareof this bias.The
secondterm
in our
approximate
MSE
comes from
theapproximation
error inherent in the estimationof
/ by
a seriesbased
approximation.The
result in Proposition 1 leads directly toan
approximate
MSE
for2SLS
which
is the only estimatorunder
considerationwhich
fallsinto this class.
Corollary
1For 2SLS,
72, which has a=
and
6=
0, the approximateMSE
of^(72 —
7),under Assumptions
1-3, is given by,,
K^
J'{I-P)f
ut
N
'
N
Notethat,aswillbeseen,theseconditionsontheirowndonot ensureroot-Nconsistency. Ingeneral this will require restrictionson therate of increase ofK.
''See Rothenberg (1983) forexample. Also note that the expression forthebias isthesame asNagar
The
result in Proposition 1 does not reveal the largeK
approximate
MSE
for eitherLIML
orB2SLS
because neither of these estimatorshave
a bias (to 0{N^^^'^)) thatdepends on
K. Thus
we
need
to providean
additional result that will yieldapproximate
MSE's
for such estimators.Proposition
2
Given Assumptions
1-3,assuming
that a=
0(1)
and
b=
0{K)
suchthat (1
—
a)K —
b=
0(1), theMSE
for •\/iV(7—
7) is approximately{K -
2aK
-
2ab)K
J'{I
-
P)f
"^
N
"^"^
A^ '
N
This
resultcan
be used
to obtainapproximate
MSE's
forLIML
and B2SLS.
Corollary
2For
LIML,
'Jl,'whichhas a=
1and
b=
0, theapproximate
MSE
Jory/N{'^L—
7)
under
Assumptions
1-3, is given by,K^.
-0^+^.
—
-^
—
Corollary
3
For
B2SLS,
'^b,"which has a=
and
b=
K
—
2, theapproximate
MSE
for\fN{ffs
~
7)under
Assumption
1-3, is given by,/ 2 2
2^K
J'{I-P)f
The
expressions derived thus fardo
not allowone
to derive a criteria forJIVE.
Interestingly, the following resultshows
thatJIVE
has thesame
MSE
expression asB2SLS.
Proposition
3
For JIVE,
7j, the approximateMSE
fory/N{'yj—
7) is given by3.2
Discussion
Some
insight into the differencesbetween
theapproximate
MSE
for the estimators canbe
gainedby
looking at theterms
in theexpansionofeach that contributes to the leadingterms
in theMSE
expressions. For2SLS
thisterm
has the form,'Pe 1
/
^
ATw
\where
thefirstterm on
the rightreflectspartofthebiasthat occursdue
totheendogeneityin the
model
(i.e. correlation of Uiand
e,)and
which grows
with K.^The
square of thisbias
term
gives the leadingterm
in theMSE
for2SLS.
The
variance of thecomplete
expression contributes0{K/N)
terms to theMSE,
and
these aredominated by
theleading bias squared term.
Both
LIML
and
B2SLS
have the leading biasterm
(whichdepends
on
K)
removed
and
so the leadingterms
in theirMSE
come
from
the varianceterms.
An
alternative derivation ofLIML
shows
how
this bias reduction occurs. In particular theLIML
estimator 7/, canbe
shown
tobe
the solution to the followingproblem,
mm
^^
where
Y
=
{y,Y),and
7;^=
(1,-7).Given
this, it is straightforward toshow
that theLIML
estimator satisfies the following first order condition,where
e{f)i)=
U~ IlY
Letting,y'<iL)
KlL)
=
we
can rewrite the first order condition as,1
(F-<5(7je(7L))'Pe(7L)
=
0. (3)Since 6 can
be
interpreted as being the coefficient in thehnear
regression ofy
on
e thefirst
term
in theabove
canbe viewed
as being the residualfrom
this regression,which
should then not
be
linearly related to e.Thus
theterm
forLIML
that corresponds to (2)has the form,
1 v'Pe
=
-. /N
N
N
\-=
IY^
v^SiPu+
J2Y1
""^^^-^v 1 (4)/N
where, O-ue Vi=
Ui -Ciis
by
construction rmcorrelated with Cj.Note
also that the leadingterm
in theMSE
expression forLIML
is equivalent to, cr^cr^.The
term
forB2SLS
corresponding to (2)and
(4) is equal to,(3)
Vn
^ f
N
N
N
\where
the leadingterm
has,by
construction, zero expectation. This, again, results in a lower order leadingterm
in theMSE
forB2SLS.
The
lower leadingterm
forLIML
compared
tothat ofB2SLS
comes about because
ofthe lower variance that arisesbecause
Vi is rmcorrelated
with
ejand
because Vi has a lower variancethan
tij. Finally, it is easyto see
why
JIVE
has thesame
leadingterm
asB2SLS,
sinceforJIVE
the expression thatis analogous to (2), (4)
and
(5) has the form,in
1 /^
^
2^2^zx,e,Q,
(6)v^
v^
V.=l ,^.which
has zero expectation. This expression resultsbecause
of the use of the Jackknifein the first stage.
3.3
Further
Comparisons
Our
discussionthus farhasindicated that,in termsofdominant terms
intheapproximate
(large
K) MSE,
LIML
dominates
JIVE
and
B2SLS
and
that all of these estimatorsdominate
2SLS
because of the larger order (inK)
leadingterm
of the latter.Another
type of
comparison
that canbe
made
is in terms of theMSE
for a fixed value ofK
for which, generally speaking, the chosen instrument set
may
be
suboptimal.The
nice feature ofthis comparison, is thatifthe expansion is takenup
toterms
oforderN~^
thenone
can see clearly theopposing
effects ofincreasingK
more
clearly. In addition suchan
expansion extends thework
ofNagar
(1959)and Rothenberg
(1983) to the misspecifiedfirst stage case
and
may
revealany
potential differencesbetween
estimatorswhen
one
uses
an
imperfect fixed set of fixed instruments in the first stage. ^Proposition
4:Given Assumptions
1, 2(i), 3,assuming
that a,band
K
are fixedand
that (forsome
small constant c),f'-Pf 1
0<c<
^-—^ <c-^
N
with probability 1, uniformly in N, then the
MSE
forviV(7
—
7) usingterms
upto those of
0{N~^)
is approximately2lf'PfY\
2[{l-a)K-b]'
ff'Pf^-'
N
J ""'N
\N
^ 2 ,{{K-2aK-2ab)-8[{l-a)K-b]}
\ /fPp
"' "^ IN
J \
N
, , .{K-2[{l-a)K-b]}
\ff'Pf
„
,'12-
Aa-a^\
ff'PfY^
, ,/4
-
2a\
ff'Pf
-2+2a
,,a{K-l)
+ b\f'{I-P)f
ff'Pf
N
N
\N
The
conditions used to derive the expression in Proposition 4 are thesame
asused
previously except thatwe
have
introduced a condition that modifiesAssumption
2(ii) to^Indeed our result reduces to that of Nagar (1959) in theperfect first stagecase when o
=
as heassumed. The expression obtained in Proposition 4 does differ from the
MSE
expression one obtainsfromTheorem 2 ofRothenberg (1983). Additionally, inthe a
=
case, the expression oneobtains from Rothenberg (1983) is not consistent with that obtained by Nagar (1959). The difference between that obtained from Rothenberg (1983) and Nagar (1959) andours is minorand appears appearto bedue totypographical error in thestatement ofTheorem 2 ofRothenberg (1983). Indeed asingle sign change
ensure identification in the fixed
K
case.Note
that the leadingterm
in this expression,when
taken to the Hmit, is the asymptotic variance of the estimator,when
K
is fixed.When
K
is fixedand
when
the instruments are imperfect (in the sense that theycannot
predict
/
perfectly) then it is the case that,since /'(/
—
P)f
>
which
follows because /—
P
is positive semidefinite. In factif the instruments are imperfect (in the sense that they
cannot
predict/
perfectly)then
it is the case that the inequality is strict.Note
that the expressionon
the rightof the inequality is the lowest variance possible for this particular problem.
Given
the expressionin Proposition4,one
can then see clearly that increasingK
willhave opposing
effects. First, increasing
K
will cause the limiting variance tobe
closer to the optimalapproximate
variance for the estimator.That
is,because
when
K
-^ oo thenby
Assumption
2, f'{I—
P)f/N
-^ 0.On
the otherhand
theother
terms
will generally increase.Our
expressions derived earlier, involve the largestterms
reflecting each of these effects.The
optimal choice ofK
, then, willbe
theone
that balances these
two opposing
effects.The
expression in Proposition 4 can alsobe used
tocompare
the different estimatorsin the class
under
consideration. In particular theapproximate
MSE
for2SLS
is,^^
1,^
+
r-
[
—
N
—
)
+^"^^^^/
[-^r)
for
LIML
we
have,and
finally forB2SLS
we
have,To
allowcomparisons
ofthese k-class estimators withJIVE
inthe fixedK
casewe
derivethe appropriate
MSE
expression forJIVE
below
in Proposition 5.Proposition
5:Given Assumptions
1, 2(i), 3,assuming
that a, band
K
are fixed,supjPii
=
0{N~^)
and
that,0<c<^<c-i
iV
with probability 1, uniformly in N, then the
MSE
for \/iV(7j—
7) usingterms
up
to those
ofO{N-^)
fPfV
, ..2 ,..J<
ff'P'fV"
, ,,0.2 , . . 2x 1ff'P'f
a'(^)
.«..x,f(^)-.(i..i...>n^(^)
^^^,,ni-p)p{i-p)f\
ff'P'f
-2N
\N
Note
the additional condition in the statement ofthe resultwhich
concerns the rateat
which
the largest diagonal of the matrixP
goes to zerowhich
is a strengthening ofAssumption
3and
is notneeded
forany
other result. Itis fairlyeasytoprovideconditionsthatjustify this conditionin the fixed
K
case considered in the result-
for instance giventhat
Assumption
2 holds onecan
verify this condition if the smallest eigenvalue of thematrix
"^'"^/N
isbounded away
from
zero.The
reason forimposing
this condition is to getan
estimate of,'f'PfY^
ff'C'f\
"^f'C'Cf ff'C'f\
"^N
J \N
J
N
\N
where
the complicatedform
forJIVE
comes from
the use of the Jackknife in the firststage,
and
similar to the results forLIML
and B2SLS,
introducesan
additional0{N~^),
term
in theMSE.
Such an
additionalterm
does notappear
in the expression for2SLS.
the variances
and
covariances but alsoon
the degree ofmisspecification ofthe first stage.It is interesting to notethat althoughthis misspecificationobviously affects allestimators
through
the leadingterm
(theapproximate
variance) it also affectsLIML,
B2SLS
and
JIVE
in the smaller order terms. Indeedone
could envision scenarioswhere
K
is fixedat
some
largenumber
and
where
there is still a great deal of misspecification in the firststage - in such a scenario it
may
be
possible for the finalterm
in theMSE
forLIML,
B2SLS
and
JIVE
tobe
largeand
indicatepoor
behavior of these estimators relative to2SLS.
One
can
do
more
generalcomparisons
of the estimators in the casewhere
there isa correct specification in the first stage so that
Pf
=
f
. In this case the lastterms
inthe
MSE
forLIML,
B2SLS
and
JIVE
would be
omitted.Comparing
the resultingMSE
reveals that althoughJIVE
and
B2SLS
have
similar bias reduction propertiesand
thesame
criteria for pickingK,
B2SLS
appears tobe
superiorwith
respect toterms
thatdo
notdepend
on
K
(at least using theapproximate
MSE
to0{N~^)).
A
comparison
ofthe
MSE
forLIML
and
B2SLS
reveals thatLIML
has a lowerMSE.
The
comparison
of2SLS
with
the other estimatorsdepends
on
the variancesand
covariances in the model.Not
surprisingly large (fixed) values ofK
and
reasonable levels of covariancebetween
theresiduals
would tend
to lead to superiorMSE
for the other estimators relative to2SLS.
The
expressions in Propositions 4and
5 alsomakes
it possible to considerwhat
happens
when
there isno
endogeneity problem, so that aue=
0.When
aue=
0, theoptimal
number
of instruments forJIVE
and
B2SLS,
using the criteriadeveloped
inSection 3.2, is exactly the
same
as forLIML,
which
is equal to the optimalnumber
ofterms
required forestimating/
in thefirst stage.On
the otherhand, theMSE
expressionjust given for
2SLS,
(when
a^e=
0) is monotonically decreasing inK
which
indicatesthat the optimal choice of
K
is as large as possible. This, not surprisingly,makes
2SLS
identical to
OLS, and
isdue
to the fact thatwhen
a^^=
0,OLS
is the Best LinearUnbiased
Estimator.The
reason that this does not occurwith
LIML
is that theLIML
estimator
would
no
longerbe
definedwhen
there areasmany
instruments as observations while the delete-one nature of the first stageused
inJIVE
makes
first stage predictionsbased on
asmany
instruments as observations very unreliable.Because
ofthedependence
ofcomparisons
on
the degree ofcorrelationbetween
resid-uals, it is difficult to use the expressions in Propositions 2and
4 to derivean
convenient optimal estimator in the classunder
consideration. It is possible,however
to describethe optimal estimator for classes of estimators that
have
similar bias properties.^The
first result will use the expression in Proposition 2 to give a class of estimators that are
optimal with respect to the large
sample
largeK
MSE
to orderK/N. The
classunder
consideration consists of those estimatorswhose
bias is of 0{N~^''^) (andhence have
asquared
bias of0{N^^))
which, asnoted
earlier, places restrictionson
aand
b that ruleout
2SLS
but includeLIML
and
B2SLS
as possibilities. This result is statedbelow
inLemma
1and
isan immediate consequence
of Proposition 2.Lemma
1 In the casewhere
K
^
oo in such away
that {l— a)K —
b=
0(1), the optimalestimator, with respect to the large
sample
(largeK)
MSE
to0{K/N)
must
have a=
\and
b=
0(1).Note
that this result does not pindown
a single estimator, sinceone
can pickany
constant value for band
stillhave
thesame
leadingterms
in theMSE
expansion, sinceterms
involvingK/N
willdominate
those of0{N~^)
for largeK.
It does suggest,how-ever, that
LIML,
beingone
such estimator, willhave
better (largeK)
MSE
propertiesthan
the other estimatorsunder
consideration. Note, again, that2SLS
does not fit intothe class of estimators
under
consideration because its bias is not 0{N~^''^) (again asK
—> oo) as the condition in the result requires.The
next result is for the class ofestimators that are unbiased to 0{N^^/'^)
and
follows similarlyfrom
Proposition 2.Lemma
2 Restricting attentionto estimators that are suchthat (1—
a)/C—
6—
(2—
a)=
0,the optimal estimator, with respect to the large
sample
largeK
MSE
to0{K/N)
must
have a=
1and
consequently 6=
1.''Indeed this was done by Rothenberg (1983) for theclass of(approximately) median unbiased esti-mators, in which
LIML
was optimal.This result states that the optimal estimator in the class of estimators that are
unbi-ased to 0{N~^/'^) is thebias adjusted
LIML
estimator. It shouldbe
noted, however, thatfor such
an
estimator the optimal choice ofK
is completely unaffectedby
the biasad-justment
and
that the criteria for choosingK
willbe
identical tothat obtained forLIML.
A
similar result to that inLemma
2 is obtainedwhen
oneassumes
thatK
is fixedand
considersapproximately
mean
unbiased estimators withM3E
givenby
the expression inProposition 4.
Lemma
3
Restricting attention to estimators that are such that {l— a)K—b—{2—a)
=
0,theoptimal estimator, withrespect to the large
sample
fixedK
MSE
to0{N~^)
must
have
a=
1and
consequently 6=
1.This result
shows
thatwhen
there is misspecification in the first stage (ashappens
in general
with
K
fixed) the bias adjusted LIA-IL estimator is optimalwith
respect tothe
MSE
to0{N~^).
This is aminor
extension, to the misspecified first stage case, ofthe conclusions
one
draws
from Rothenberg
(1983) concerning the optimality of the biasadjusted
LIML
estimatoramong
the classofapproximately
mean
unbiased
estimators. Inadditionto this,
Rothenberg
(1983)showed
that forfixedK
and
a correctly specified firststage
LIML
is optimal (with respect to theMSE
to0{N~^))
among
all (approximately)median
unbiased
estimators.Thus
based on both
thedominant terms
in largeK
MSE
and
peripheral or second order terms there appears tobe
ample
evidence to suggest the use ofLIML
or bias adjustedLIML.
3.4
Admitting
Covariates
In this section
we
generalize the results to the model,Vi
=
lYi+
x\iP+
ewhere
x^
is a rfjx
1 subvectorofx^.The
most
important
difference that arisesinthemore
/5i)'-However,
itcan
be
shown
that theMSE
of estimators of Pi are directlyand
positivelyrelated to the
MSE
of estimators of 7. In particular,assuming
thatXu
is included inthe instrument set (which
would be
the case if one were usingpower
series) thenany
estimator of/^jwillhave
the form,where
Xi
denotes theN
x
di matrix with zthrow
qual to Xu. ^ Since for all threeestimators the
MSE
of Pidepends
on
K
onlythrough
itsdependence on
7,we
can
focus directlyon
theMSE
of the7
in each case.When
covariates are present the estimatorsof
7
take the form,7
=
((1+
k)Y*'PY*
-
kY*'Y*)-\{1
+
K)Y*'Py
-
KY*'y)where
Y*
=
[I—
Pi)Y
with Pi being the projection matrixformed
using Xi.The
JIVE
estimator will take the form,
^j
=
{Y'C'{I-
Pi)YY'Y'C'{l
-
Pi)y.Before presenting the
MSE
calculationswe
modify
Assumption
2 as follows, letting ttdenote the population regression coefficients
from
the regression of Yion
Xu.Assumption
2'The
function f{xi)=
E{yi\xi) is such that,(i)
f
:X
^
R
and
hasan
extension to all ofW^
that is s>
times continuouslydifferentiahle in
x
and,(a) with probability 1
<
c<
N~^
X]i=i(/(^i)~
^'u^)'^
<
^~^ /'^'^some
small constantc uniformly in
N
(Hi) the smallest eigenvalue of
X'lXi/N
isbounded
away from
zero uniformly inN
with probability one.
The
adjustments
inAssumption
3' aredue
to thefactthat theidentification conditionnow
suggests that Xi explain Xjibeyond
that providedby
ahnear
regressionon
x^.^
The new
condition (iii) along withAssumption
l(v) isused
tobound
the elements ofthevector, (/
—
Pi)/
and
the variancesand
covariances ofelementsof[I—
Pi)u
and
[I—
P\)e.Indeed
these conditions ensure that the variance of a typical element of (/—
Pi)u, sayUi
—
P'liU (with Pii denotingcolumn
i of Pi), is equal to that ofw, plus aterm
that is0{N~^)
and
thatany
covariancesbetween
these elementsare ofsecond
order importance.The
same
holds true for the vector (/—
Pi)eand
for covariancesbetween
these vectors.Once
this hasbeen noted
one can obtain largeK
MSE
expressions for the estimatorsof interest that are the
same
as in the case ofno
covariates provided that the set basisfunctions
used
as instruments contain linearterms
in Xu.Corollary
4
Given
Assumptions
1,2'and
3 plusPPi
=
Pi the conclusions ofCorol-laries 1, 2
and 3 and
Proposition3
all hold.It is easy to see
why
this result holdswhen PPi
=
Pi.The
only difference thatwould
obtain
by
allowing forexogenous
covariates in the equationwould
be
that thesecond
terms
in theapproximate
MSE
would have
the form,/'(/
-
Pi)(/-
P)(/
-
Pi)//A^=
/'(/-
P)/
where
the equalitycomes from
the fact thatPPi
=
P\.A
simpleconsequence
of this result is that rules for choosingK
and
any optimahty
results discussed previouslyapply
carry over to the situationwith
covariates.4
Feasible
Optimal
Estimation
of
K
In this section
we
consider the properties of the estimatedMSE
criteria discussed inSection 2.
Throughout
this sectionwe
will use the followingassumptions
concerning the preliminary estimation of the parameters, o"^, o"^and
a^^.®This is essentially a relevance condition and Donald (1997) has considered tests for the failure of this condition in contexts wherethere are anarbitrary numberof righthand sideendogenousvariables.
Assumption
4
Assume
thefollowing,(^) ^l
-
ol,(n) al
^
al(Hi) Gut -^
O-uc-As
noted
in Section 2, this canbe
achievedby
usingsome
prehminary
set of estimatesof the
model
obtainedby
using thenumber
of instruments that provide the optimal fitin the first stage,
based
on
either the cross-validation orMallows
criteria.Note
that theother key ingredient used to
form
the estimated criteria isR{K)
which
can eitherbe
based
on
cross validation or theMallows
criteria as discussedin Section 2. Li (1987) hasshown
that each of these criteria are asymptotically optimal in the sense that the value ofK
that minimizes these criteria,denoted
K,
satisfies the condition,RJK)
, .
infx /?(/<) '
in probability.^° For a generic estimator
7
with estimated criteriaS{K)
and
true criteriaS{K) we
will define the data driven optimal choice of thenumber
ofinstruments by,K
=
argminS{K).
The
minimum
and
allinfimum
willbe
relative toan
index set ofK
values,which
may
require
some
restrictions in order to prove certain results. Also, notice that althoughR{K)
only estimatesR{K)
up
to a constant,which
does notdepend
on K, one
canremove
this constantfrom
R{K)
and hence from
S{K)
without affecting the choice ofK.
To
analyze the properties ofK
we
follow theapproach
of Li (1987)and
Andrews
(1991b). In our casewe
use the following definition of optimality.Definition:
A
method
ofselectingK
is defined to he "higher order asymptoticallyopti-mal
with respect to the criteriaS{K)
" ifit can beshown
that,s{k)
,inf;,5(/^)
^"Andrews (1991) proved the same results for appropriate adaptations ofthese criteria in the case
The
use of theterm
"higher order" is necessitatedby
the fact that the optimalMSE
convergence rate in all cases willbe
A'^"^ (asN
—
> oo)which
cannotbe improved upon,
and
the criteriabased
on
S{K)
concerns thenext largestterms
intheMSE
thatdepend
on
the choice ofK.
A
vital step inshowing
that the criteria are higher orderasymptotically-optimal, is
showing
thatR{K)
consistently estimatesR{K)
up
to the constant in the sense that, in probability,This is the condition
used
by
Li (1987) toshow
theasymptotic
optimalityoftheMallows
criteria
and
cross validation. Inordertobe
able toverify this resultwe employ
conditionssimilar to those of Li (1987).
Assumption
5:Assume
that thefollowing conditions hold,(i) E{u\\xi)
<
ooand
(a) inf^
NR{K)
-^ oo,and
in additionwhen
R{K)
is the cross validation criteria,assume
(Hi) the index set satisfies the condition that
sup^
sup^F^j -^ in probability.The
conditions (i)and
(ii) inAssumption
5 areneeded
forboth
theMallows
criteriaand
cross validation, to
show
that they satisfy (7).These were
employed by
Li (1987) toshow
that these criteria are asymptotically optimal. Here, this isan
intermediate step toshowing
higher orderasymptotic
optimality.The
second of these requires either that/
nothave
a finiteorder representationinterms
ofthebasis functions orelse that the lowerbound
on
the set ofK
values overwhich one
is doing the minimizationgrows with
A'^,which
isperhaps
undesirablefrom
a practical standpoint.The
condition (iii) is requiredonly forthe cross validation
based
method,
and
is similar to the conditioninAssumption
upper
bound
on
the rate atwhich
the index set cangrow
with thesample
size ^^The
followingresults
show
that for each estimator the estimated criteria provides ameans
toobtain higher order asymptotically optimal choices for the
number
of instruments.Proposition
6:Given Assumptions
4 o-'^d 5, then the rule "select the valueK
thatminimizes
S^{K)
" ishigherorderasymptotically optimalwith respect to the criteriaSl{K).
Proposition
7:Given Assumptions
4 o-iT^d 5, then the rule "select the valueK
thatminimizes
S2{K)
" is higherorderasymptotically optimal withrespect to the criteriaS2{K).
Proposition
8:Given Assumptions
4and
5, the rule "select thevalueK
thatminimizes
Sj{K)"
is higher order asymptotically optimal with respect to the criteriaSj{K).
5
Simulation
Study
In this section
we
report the results ofa smallMonte-Carlo experiment
which
hasbeen
designed along the lines of that used in Angrist,Imbens
and
Krueger
(1995) (hereafterAIK). Three
basic designs are used. All experiments arebased
on
the estimation of theequation,
Yr
=
Po+
PiXn
+
e, (8)where
d^o,A)
=
(0, 1)and
where
X^
isan
endogenous
explanatoryvariable.Three
cases are consideredand
are distinguishedby
differencesbetween
Xn
and
a set of potentialinstruments.
Case
1: In this caseXn
is related to either A;=
10 or /c=
20independent standard
normal
random
variables, Z^jthrough
the linear equation,k
Xii
=
7^0+
^
'n-jZij +r]i (9)^^Asnotedbelow Assumption3, basedonDonald(1997) hasshown,usingtheresults in
Newey
(1995),that forpowerseries,ifx; hasa continuousdistributionwithdensitythat isbounded andbounded away
with TTi
=
0.3and
iVj=
for j 7^ 1, so that only the first Zij is relevant for predictingXii- In this case the residuals in the
two
equations are generated as,m
J
VV
y 'V 0-20 0.25
This case is identical to
Model
2 ofAIK,
who
used
acomplete
set of/c=
20 instrumentsin their experiments.
Case
2: This is thesame
as inCase
1, except thatnow
in (9) ir^=
0.3and
ttj=
forj
^
5 so that only the fifth instrument is relevant.Again experiments
areconducted
forboth
A:=
10and
A;=
20 potential instruments (in addition to the constant).The
errors are generated in thesame
way
as inCase
1.Case
3: This is thesame
asModel
3 ofAIK
and
specifies,Xi,
=
710+
^2
'^^^^^+
0-3Y.
4
+
^^0Y^
zy\^
(10)with
TTi=
0.3and
tt^=
for j 7^ 1, so that in addition to the first regressorbeing
relevant the others enter in a nonlinear fashion. Additionally, the errors in the first
stage are heteroskedastic.
The
selection process will, however, only consider using theZij variables themselves,
and
will consider eitherup
to the first /c=
10 instruments orthe first fc
=
20 instruments.The
residuals in the pair of equations (8)and
(10) aregenerated as,
^^\
Ajff
^\
f
1-00 0-807?zo y
Vv
y
A
0-so 1-00For
each of the three cases, experiments areconducted
withsamples
of size A'^=
100and
A'^=
400,and
using amaximum
number
of instruments of /c=
10and
k=
20.Thus
for each case a total of four different experimentswere
conducted.The number
of replicationswas
set at 5,000. In eachexperiment
the2SLS,
LIML
and
JIVE
estimatorswere
obtained using thenumber
of instruments thatminimized
the objective functionsdiscussed in the previous
two
sections.These
criteriawere
constructed using delete-one cross validation of the first stage relationship, alongwith
estimates of cr^^, a^and
cr^which were
obtained as discussed in Section 4, using a preliminary estimatorwhich used
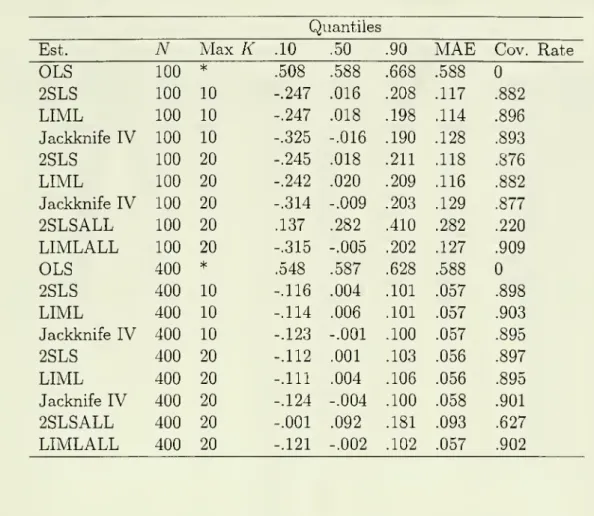
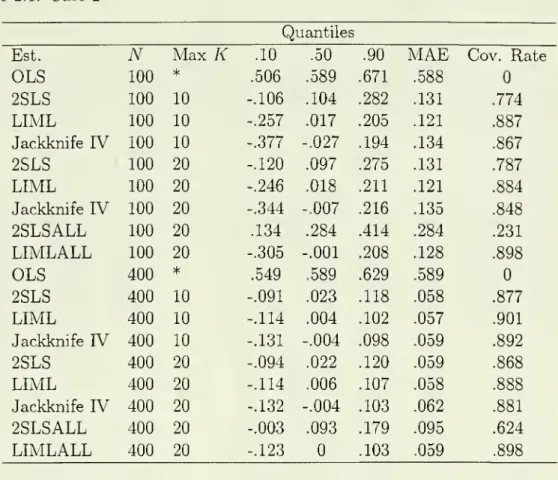
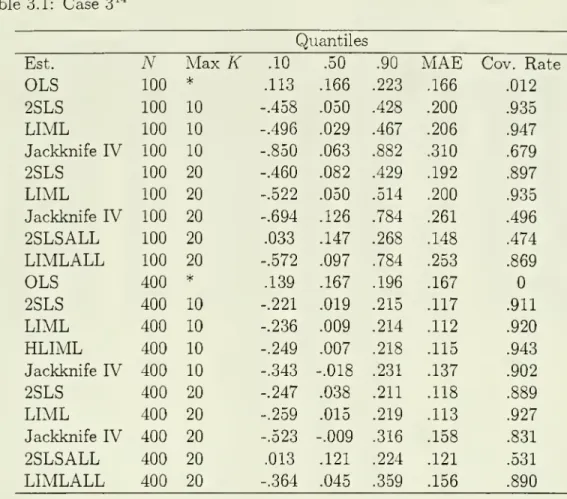
all ofthe instruments.Tables 1.1, 2.1
and
3.1 contain the relevantsummary
statistics for each of the three cases respectively. In each tablewe
report themedian
of the 5,000 estimates along withthe 0.1
and
0.9 quantiles ofthe estimates.The
differencebetween
thesecan be
considered away
ofmeasuring
dispersion. Additionallywe
report theMean
Absolute
Error of theestimates,
which
isan
alternativemeasure
of dispersion, and, finally, the coverage rate of anominal
95 percent confidence interval for each estimator. Additionallywe
reportthe relevant statistics for the
OLS
estimator as well as2SLS and
LIML
estimators that use all fc=
20 instruments.These
statistics were reported inAIK
(1995, Tables 2and
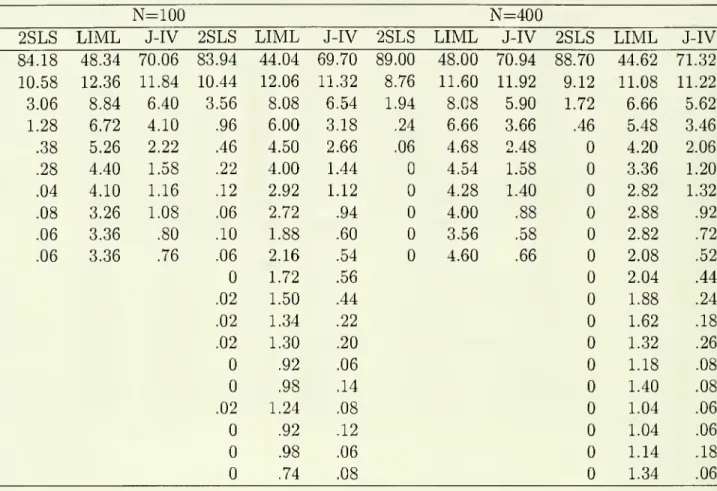
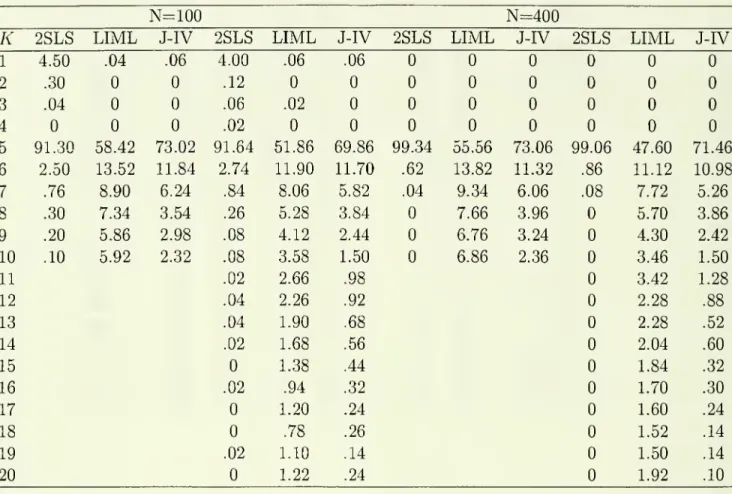
3). In Tables 1.2, 2.2
and
3.2we
report the frequencies withwhich
the various possibleK
valueswere
chosen in the experiments.A
few features ofthe results areworth
noting. First, themost dramatic improvements
occurinthe use of2SLS
with theoptimalnumber
ofinstrumentsbeingused.As
indicatedin Tables 1.1
and
3.1,2SLS
which
uses all the instruments has verypoor
properties,and
is biased towardsOLS.
Moreover, confidence intervals generallyhave
a verypoor
coverage rate with the worst occurring inCase
1 with A'^=
100where
thenominal
95%
confidence interval contains the true value just
22%
of the time.The
other cases are similarly poor.When
the criteria are used to choose thenumber
ofinstruments there isa substantial reduction in the bias (as
measured by
themedian)
and
the coverage ratesfor the confidence intervals are
much
closer to thenominal
rate of95%
generally beingaround 90%.
The
only exception to this isCase
2 with A'^=
100where
the coveragerate is
below 80%,
although this is a dramaticimprovement from
the23%
coverage ratewhen
all instruments are used.The
other noticeable difference in2SLS
when
the criteriais
used
is that the dispersion ismuch
lower as evidencedby reduced
MAE
and
a lower spreadbetween
the10%
and
90%
quantiles. It alsoworth
noting that theperformance
of
2SLS
using the criteria is not sensitive to themaximum
K
being considered.Indeed
the results for2SLS
when
one uses the criteria to pickK
with amaximum
possibleK
of 10 are almost identical to thosewhen
themaximum
possibleK
is 20.For
LIML
on
the other hand, themain
improvements
relative to the estimator thatby
MAE
or as the differencebetween
the .1and
.9 quantiles. This isbecause
LIML
performs
fairly wellwhen
all of the instruments are usedand
isapproximately
median
unbiased
and
provides confidence intervals thathave
a coverage rate that is reasonablyclose to the
nominal
rate of95%
beingaround 90%.
The
coverage rate forLIML
when
the criteria is
used
is slightly lowerthan
forLIMLALL
inCases
1and
2. InCase
3,however, there is
an
improvement
in the coverage ratewhen
the criteria isused with
therate being very close to the
nominal
rate.The
main
improvement
thatcomes from
theuse ofthe criteriais in the decreaseddispersion ofthe estimator
which
results in all cases.The
performance
ofJIVE
is a little bitmixed
relative to the other estimators.The
bias (using themedian)
ofJIVE
insome
cases appears tobe
the lowestamong
theestimators
and
other cases (notablyCase
3 with 100 observations) is the worst so thatthere is
no
clearly superior estimator as far as bias is concerned.What
is striking is that the dispersion forJIVE,
using either measure, is larger in practically all cases relative to either theLIML
or2SLS
estimators that resultfrom
the use of the criteria for picking thenumber
of instruments.There
is alsono
clearimprovement
in the coverage ratesfrom
the use ofJIVE
ratherthan
either2SLS
orLIML
estimators that use the criteria for picking thenumber
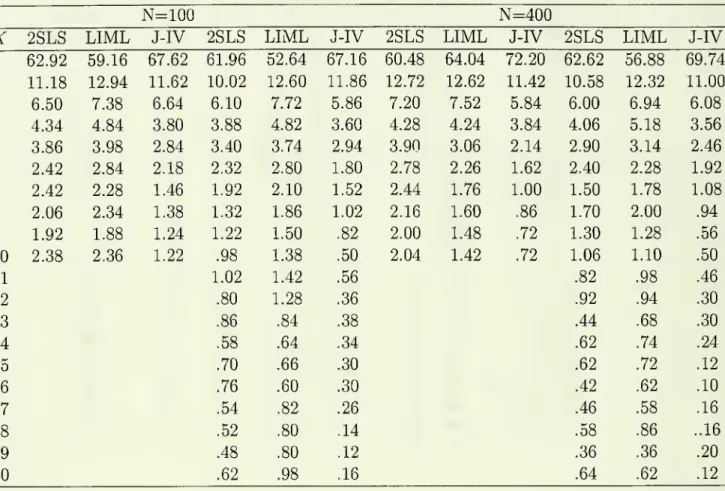
of instruments.In Tables 1.2, 2.2
and
3.2we
have
provided frequencieswith
which
the criteria chose the respectivenumber
of instruments for each estimator in each case.A
few
featuresstand
out. First, for all estimators the criteria usually points to a value ofK
that is at least as large as is required to include the relevant instrument-
in Cases 1and
3 this \sK
=
\ while inCase
2 this is /C=
5.What
is also interesting, is that inCase
2 thecriteria generally pick the correct
number
ofinstriimentsmore
than
halfthe time. Also,as
one
might
expectfrom
the discussioninSection 3, thecriteriafor2SLS
generallypointsto smaller values of
K
than
does the criteria forJIVE,
while the latter generally picks values forK
that are smaller (on average)than
those forLIML.
With
LIML
and
JIVE
the criteria