Algorithms and lower bounds in the streaming and sparse recovery models
Texte intégral
Figure
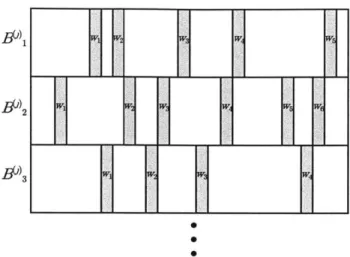
Documents relatifs
To the topic of this work brought me my interest in archaeology of the Near East and with it associated my first visit of the most important Musil´s archaeological
Prof Indemnité de Nuisance Indemnité de travail Posté Prime de Rendement Salaire de Poste Indemnité Panier.. Indemnité de transport Salaire de Brut
inhabitants in the 1970s; a basic program concerning environmental quality; an attempt to understand the character of people, society, and nature, to
ASD- associated behaviors (decreased social interaction, aug- mented repetitive behaviors) displayed by PV+/− mice are strongly ameliorated, if PV expression is restored close to
Japan-Varietals, WT/DS/76/AB/R paras 126 and 130.. A final area in which the SPS necessity test has shaped GATT necessity jurisprudence is seen in the attention paid to the footnote
The main objective of this thesis is to investigate the performance of channel estimation in UWB systems based on the new Compressed Sensing theory [6]-[7] using a frequency
Since bigger g denotes higher orthogonality in structure for a matrix with a given degree d, LDPC matrices construction algorithms are also available to construct measurement
We propose exploiting the sparse nature of the channel through the use of a new greedy algorithm named extended OMP (eOMP) in order to reduce the false path detection
