Mining for Availability Models in Large-Scale Distributed Systems:A Case Study of SETI@home
12
0
0
Texte intégral
(2)
(3)
(4)
(5)
(6)
Figure
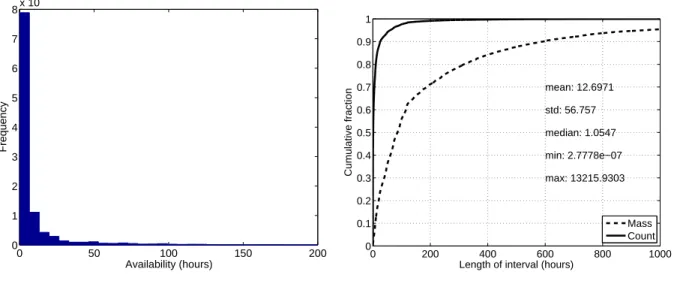
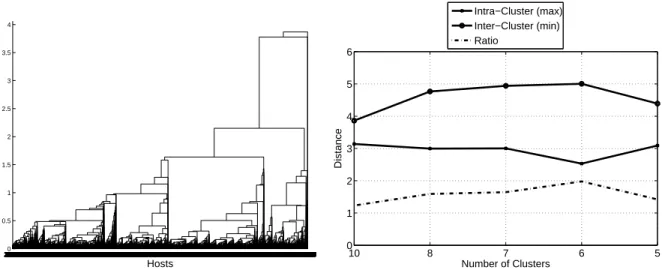

Documents relatifs
Any extensional K-model D that is hyperimmune and commutes with B¨ohm trees is inequationally fully abstract for the pure
We first introduce the notion of λ-K¨ onig relational graph model (Definition 6.5), and show that a relational graph model D is extensional and λ-K¨ onig exactly when the
Note that this paper does not endorse one type of business plan over another but that our case study partner Partneur is developing an online platform to enable people to
Traditionally, the control of large-scale systems is performed locally with decentralized pre-set control actions. The terms control and optimization consequently refer to
In Algorithm 1, compute intensive tasks are sorted in increas- ing order of communication times. It allows tasks to utilize the computation resource maximally and make enough margin
Markov chain models are known for their simplicity and their great ability to model reparable systems, thus, they are well adapted for modeling stochastic
The idea of the Raftery and Dean approach is to divide the set of variables into the subset of relevant clustering variables and the subset of irrelevant variables, independent of
We reviewed the literature to obtain the architectural tactics used to deal with availability in single systems and adapted one of them to develop an architectural strategy based
