A Deeper Look at Hand Pose Estimation
by
Battushig Myanganbayar
Submitted to the Department of Electrical Engineering and Computer
Science
in partial fulfillment of the requirements for the degree of
Master of Engineering in Electrical Engineering and Computer Science
at the
MASSACHUSETTS INSTITUTE OF TECHNOLOGY
September 2018
c
Massachusetts Institute of Technology 2018. All rights reserved.
Author . . . .
Department of Electrical Engineering and Computer Science
Aug 31, 2018
Certified by . . . .
Boris Katz
Principal Research Scientist
Thesis Supervisor
Accepted by . . . .
Katrina LaCurts
Chair, Master of Engineering Thesis Committee
A Deeper Look at Hand Pose Estimation
by
Battushig Myanganbayar
Submitted to the Department of Electrical Engineering and Computer Science on Aug 31, 2018, in partial fulfillment of the
requirements for the degree of
Master of Engineering in Electrical Engineering and Computer Science
Abstract
Hand pose recognition is a fundamental human ability and an important, yet elu-sive, goal for computer vision research. One of the major challenges in hand pose recognition is the sheer scale of the problem. The human hand is a notoriously agile object with 27 degrees of freedom. In a sense, it is an impossible task to collect a dataset with every major hand pose configuration. However, current state-of-the-art approaches rely too much on training data and generalize poorly to unseen hand poses. Furthermore, current benchmarking datasets are of poor quality and contain test sets that are highly correlated with the training set, which in turn encourages the development of data-reliant techniques for better accuracy only on paper. In this thesis, I introduce a better and more realistic benchmarking dataset, and propose a novel approach for hand pose detection that has the potential to generalize better to unseen hand poses.
Thesis Supervisor: Boris Katz Title: Principal Research Scientist
Acknowledgments
First and foremost, I am deeply grateful for the support and guidance that I received from Boris Katz and Andrei Barbu. They not only guided me to finish this thesis work but also paved my path to grow as a researcher. Boris, I want to thank you for always being supportive and asking the right questions at the right time that show the side of the problem I never considered. Of all questions you asked from me, I will always remember the one “What would you do if you had unlimited time and resources?”. This question motivates me to consider the things in the grand scheme and see the deeper meaning of what I am doing rather than just chasing the short term goals for the sake of solving problems. As a means of answering this question in this thesis work, I learned the power of knowing what needs to be done in the context of broader perspective. This experience fundamentally transformed me from being an engineer who offers a solution to a researcher who tries to ask the right questions. I will always be thankful for you teaching this important lesson to me.
Andrei, I want to especially thank you for always being there to answer all my questions related to this project and providing insights and ideas. I particularly appreciate the moments when you encouraged me to pursue the path of implementing things in a correct way that offers a deeper research insight in spite of technical complexity required for it. Your support helped me to grow as a technically capable researcher who can implement complex systems. I would have never asked for better mentors.
I also want to thank the InfoLab members who contributed to my thesis work either through supporting me or directly by helping the data collection work incor-porated into this thesis. And if this thesis is at all comprehensible, it is all thanks to my colleagues, Cristina F. Mata and Sue Felshin, proofreading my drafts.
I specially want to thank my little sister, Tergel Myanganbayar, for offering her unwavering help and providing annotations for over 90 hands, which is almost the one third of the total annotations required for this thesis work. Without her support, I would not have been able to achieve this. Finally, I would like to express my most
sincere gratitude for my parents. They provided me with all necessary opportunities, support, confidence, and love to bring me up to this point and be able to collaborate with these awesome people at MIT.
“Those, who are given opportunities, are responsible building better future for all.”
Considering the opportunities in my life given by MIT, my friends, and my family, I too will dedicate myself for building a better future for all.
Contents
1 Introduction 13
2 Background and Motivation 15
2.1 Hand pose recognition . . . 15
2.1.1 Significance of hand pose recognition . . . 15
2.1.2 Scope of the hand pose recognition problem . . . 17
2.1.3 Progression of hand pose recognizers . . . 19
2.2 A deep dive into the state of the art . . . 21
2.2.1 Data sets . . . 22
2.2.2 Techniques . . . 26
2.3 Building a hand pose recognizer in a perfect world . . . 29
3 Steps to building an ideal hand pose detector 31 3.1 Steps towards a realistic benchmarking dataset . . . 32
3.1.1 The MIT Occluded Hand Dataset . . . 32
3.1.2 Benchmarking current state of the art . . . 37
3.1.3 Human baseline . . . 38
3.1.4 Machine vs Human . . . 41
3.2 Steps to more generic hand pose detector . . . 41
3.2.1 Generative hand pose recognition framework (HandPicasso Frame-work) . . . 42
3.2.2 Custom hand generator (HandDoodle) . . . 45
3.2.4 Inference Engine . . . 58
3.2.5 HandPicasso on the go . . . 59
4 Future works 61 4.1 An alternative approach for the inference engine . . . 61
4.2 Generalizing HandNet to real images . . . 61
5 Contributions 65 6 Technical references 67 6.1 Synthetic hand generator (HandDoodle) . . . 67
6.1.1 Pose Generator . . . 67
6.1.2 Rendering Engine . . . 73
6.1.3 Blender tricks . . . 74
6.2 Hand annotation tool interface . . . 74
List of Figures
2-1 Locations of 21 keypoints in most used convention of hand pose
recog-nition literature. . . 16
2-2 Pictures of cups on ImageNet . . . 17
2-3 Collection of cropped hand pictures . . . 18
2-4 Hands under object and self occlusions . . . 19
2-5 Examples pictures of one of the best mono RGB camera based hand recognizers in 2013 . . . 20
2-6 Examples of detected hand poses from hand-object interaction by depth based methods . . . 20
2-7 Noisy examples of detected hand poses from hand-object interaction by depth-based methods . . . 21
2-8 Example pictures from Ego-Dexter dataset . . . 23
2-9 Example pictures from the CMU Panoptic Dataset . . . 23
2-10 Example pictures of the Rendered Handpose dataset . . . 25
2-11 Example pictures of CMU multi-view bootstrapping dataset (same hand pose shown from multiple perspectives) . . . 26
2-12 Architecture of Convolutional Pose Machines. . . 28
2-13 Examples of a CPM inferring locations of occluded points based on visible keypoints. . . 28
2-14 Architecture of Resnet 18 . . . 29 3-1 Pairs of pictures from the MIT Occluded Hand Dataset taken by methods 33 3-2 Pictures of a subject performing 4 different grasps with paper lantern. 34
3-3 PCK curve of Simon et al evaluated on NZSL dataset. . . 35
3-4 Pictures of all 150 objects included in the dataset. . . 36
3-5 Performance of current state of the arts in MIT Occluded Hands Dataset 37 3-6 Performance of human annotators on MIT Occluded Hands Dataset . 39 3-7 Human intercoder agreement . . . 40
3-8 Machine vs Human performance on MIT Occluded Hands Dataset . . 41
3-9 Block diagram of PICTURE framework . . . 43
3-10 Block diagram of HandPicasso framework . . . 44
3-11 Example renderings of generated hands by Libhand framework. . . . 46
3-12 Rendering of randomly generated hand poses by HandDoodle . . . . 47
3-13 Linear interpolation between hand poses by HandDoodle . . . 48
3-14 Hands generated using DOD data. . . 49
3-15 HandNet architecture . . . 51
3-16 Distribution of randomly generated distances in HandNet training data 53 3-17 Distribution of distances in HandNet training data . . . 53
3-18 Benchmarking of HandNet trained on Euclidean distance . . . 56
3-19 Benchmarking of HandNet trained on Angle joints . . . 57
4-1 Architecture of Cycle GAN . . . 62
4-2 Results of Cycle GAN . . . 62
6-1 Anatomy of human hand in comparison with our hand model . . . . 68
6-2 Joint in its default position . . . 68
6-3 Picture of hand model . . . 69
6-4 Twisting observed in hand model when bone roll is not set . . . 74
List of Tables
Chapter 1
Introduction
Human hands are complex objects and a key to our everyday interactions with the world around us. Accurate hand pose recognition consequently plays a crucial part in building algorithms and robots capable of naturally extending and assisting our everyday life in a significant ways. These range from creating sign language translators to making robots that understand the intentions of human action based on the hand pose. Potential applications of accurate hand pose trackers are immense but none of the current state-of-the-art technologies have come close to being practical for seemingly simple applications like reliable control of television with hand gestures. Ironically, the reported performances of current state-of-the-art hand pose detectors are quite good on their respective datasets. In this thesis, I will take a deeper look at reasons for this performance gap between the benchmark results and reality offer comprehensive solutions and insights for improving current techniques.
I intend this thesis to serve as a comprehensive guide to understanding hand pose detection techniques and their evolution instead of just being a technical narrative about improvements to current systems. Thus, I will present the exact definition and brief history of evaluation of hand pose detection methods along with laying out the strengths and bottlenecks of current state-of-the-art systems in Chapter 2. I also enumerate the necessary components to create the ideal hand pose detector at the end of Chapter 2, to illustrate the intrinsic motivation and deeper vision for the approaches and improvements proposed in Chapter 3. Future work and a technical description
of the tools and frameworks built for this thesis work are covered in Chapter 4 and Chapter 6 respectively.
Chapter 2
Background and Motivation
2.1
Hand pose recognition
Lets start off by rigorously defining the hand pose recognition task. It has perhaps the simplest precise one-line definition of any problem in computer vision:
“Given a picture of a human hand, locate 21 keypoints (Figure 2-1) cor-responding to the joints.”
Understanding the strengths and weaknesses of current state-of-the-art solutions to this problem is a bit more involved and requires more space than the description of the problem, as is usually the case for hard problems. In fact, I will dedicate the rest of Chapter 2 to the presentation of the current state-of-the-art hand pose recognizers and their components in detail, which will serve as foundation for understanding contributions and motivations of my work.
I also provide some historical development of hand pose recognition techniques in Section 2.1.3 to show the overall trend of solutions and give some intuition that will provide the basis to a deeper vision of contributions I propose in Chapter 3.
2.1.1
Significance of hand pose recognition
Before I start technical discussions, let me clarify the importance of hand pose recog-nition once again by answering this important question. Why would one be interested
Figure 2-1: Locations of 21 keypoints in most used convention of hand pose recogni-tion literature [20].
in accurately knowing the locations of these 21 keypoints? The general answer is that these points can fully specify the unique pose of a human hand, and knowing that unique pose has significant implications for our life.
As you see in Figure 2-1, your brain is already performing hand pose recognition and signaling us that the hand pose means “OK”. When you wave at someone, their brain is recognizing your hand pose and indicating that you are greeting them. When someone shows you how to use a new tool, your brain is recognizing the hand pose and making it easier for you to repeat the action later. Hand pose recognition is, therefore, an invisible but inseparable building block of social exchanges and means of learning new tasks.
Now, imagine what would happen if machines were able to understand hand poses in the same way that humans do. This would have far reaching consequences for our safety and well-being. The communication barrier between people who use sign lan-guage and the rest of society would be virtually non-existent if machines could under-stand sign language perfectly. The cross-infections at hospitals due to improper hand washing could be prevented by tracking areas of the hand that havent been washed. Robots would be able to interact with humans more naturally by understanding their hand poses in social contexts. With such a wide range of potential applications, no further explanations are required to see the significance and impact of studying the
Figure 2-2: Pictures of cups on ImageNet [6]
hand pose recognition problem in depth and developing solutions for it.
2.1.2
Scope of the hand pose recognition problem
The fundamental step to approaching the problem is understanding how hard it is compared to other well-known challenging problems and exactly what makes it harder or particularly easier than them. In this context, I will compare hand pose recognition with object recognition. Unlike object recognition tasks with thousands of different objects, the shape and anatomy of the human hand is very well-known and nearly the same for everyone. In that sense, one would expect the scope of the hand pose recognition task to be both smaller and easier than object recognition. However, that is not the case. Hand pose recognition has two main characteristics that makes it equally or more challenging than the object recognition tasks as I will establish below. Degrees of Freedom (DOF)
Most objects around us, and the ones included in the ImageNet dataset, show up in a few common configurations and typically have three degrees of freedom. For example, we can see that most pictures of cups (ImageNet [6]) show up on the table mostly from the top or front. Current object recognition techniques are focused on shallowly learning to recognize a wide range of objects in their most common representations, but a human hand pose has no common configuration and its appearance widely varies.
Figure 2-3: Collection of cropped hand pictures [20]
The human hand has 27 degrees of freedom:“4 in each finger, 3 for extension and flexion and one for abduction and adduction; the thumb is more complicated and has 5 DOF, leaving 6 DOF for the rotation and translation of the wrist” [7]. The depth of the problem increases exponentially in the space of 27 DOF. As we can see from Figure 2-3, it is impossible even to have a concept of common hand poses as there are nearly an infinite number of possible configurations of hand poses in different viewpoints.
Consequently, techniques and ideas of object recognition, which are designed to shallowly learn common representations of many objects, largely fail to be useful to the hand pose recognition problem. Thus, the hand pose recognition problem is narrower in breadth but deeper than object recognition and current computer vision techniques fail to cover the depth of the problem.
Occlusions
The human hand often appears occluded because of interaction with objects or self occlusions. This makes the full estimation of hand pose extra challenging since the problem not only requires identifying the visible keypoints but also inferring the occluded keypoints by utilizing extra information about hand structure.
The high degrees of freedom and heavy occlusions are what makes the hand pose recognition problem so challenging. The perfect hand pose estimation technique, therefore, needs to carefully address these two difficulties.
Figure 2-4: Hands under object occlusions (top) and self occlusions (bottom)
2.1.3
Progression of hand pose recognizers
Having established the main factors that make the problem hard, I will now briefly describe how the computer vision community historically approached the problem. The knowledge of limitations of different approaches presented here and intuition from it will serve as a basis to understanding the significance of the approaches proposed in later sections. Hand pose recognizers in their earliest forms required a person to put color mark on the location of 21 keypoints (Figure 2-1) [10]. Then, markerless methods were proposed that allow estimation of hand poses from single RGB pictures. I will refer to the systems that use single camera RGB pictures as mono-RGB methods. Instead of detecting keypoints based on color markers, they use statistical computer vision techniques such as feature descriptors and color clustering to identify the locations of visible keypoints. Then, they used complex objective function heuristics to fit synthetic hand models to those identified keypoints to infer the locations of other, invisible keypoints.
These methods were brittle to hand-object interaction since feature descriptors get confused by object parts, and were limited to an user moving their hand in front of a camera at close distances (Figure 2-5) [11, 23].
As researchers struggled to make hand-object interaction robust on mono-RGB methods, depth-based methods were proposed to circumvent the issue. In 2015 Rogez
Figure 2-5: Examples pictures of one of the best mono RGB camera based hand recognizers in 2013 [23]
Figure 2-6: Examples of detected hand poses from hand-object interaction [18] et al. [18] used Convolutional Neural Networks (CNNs) to produce the first depth camera based method that can reasonably estimate the hand pose when interacting with objects (Figure 2-6). The method suffered when seen new objects or noisy depth maps due to a cluttered background or when holding reflective objects such as glass (Figure 2-7).
Better depth based methods such as [14, 24, 27, 29] have been proposed, which are more robust to background noise and some object interactions. However, depth based approaches are intrinsically constrained to recognizing hands nearby the depth sensor and reflective surface areas will confuse depth sensors. For these reasons, depth based approaches will never be the complete solution for applications of hand pose recognition.
Mono-RGB approaches have no such intrinsic limitations and could be the most promising direction towards practical and accurate hand pose recognizers. Simon et
Figure 2-7: Noisy examples of detected hand poses from hand–object interaction [18] al. [20] in 2017 was the first to propose a mono-RGB method capable of recognizing hand-object interaction against various backgrounds. He improved the previously brittle keypoint detection methods using a CNN and trained it on pictures of anno-tated hand keypoints from multiple views. The CNN model learns the hand structure and relations between keypoints from training data, and eliminates the need for explic-itly fitting a hand skeleton to detected keypoints. Essentially, the richer the training data in hand poses from various viewpoints, the more robust the hand pose detector. This work is currently regarded as one of the state-of-the-art methods (even com-pared with depth methods), and showed the significance of quality of training datasets for creating better hand pose recognizers. Inspired by this insight, almost all of latter methods [5, 15, 21, 30] published in 2018 focused on enriching the training dataset with synthetic data. Simon et al. inarguably set the new standards and started the dominant trend in mono-RGB methods of diversifying the training data.
2.2
A deep dive into the state of the art
Knowing what makes current state-of-the-art approaches powerful and what is the current bottleneck to achieve better performance is crucial for anyone interested in improving current hand pose recognizers. In this context, I will present the three
main components of Simon et al. and other competitive approaches in this section. Furthermore, I will offer solutions addressing current bottlenecks, and propose a new hand pose detection method that challenges the traditional framework of thinking in Chapter 3. Because of their intrinsic limitations discussed in the previous section, depth based approaches will be excluded from this analysis.
2.2.1
Data sets
All state-of-the-art solutions to hand pose recognition problems are based on CNNs, and datasets are the most important element of any neural networks for training and assessing the performance of them. A good dataset can be defined by two metrics: distinction between training and test set, and closeness to practical usage. First, having a homogenous dataset with a highly correlated training and test sets results in a model with good performance on paper but that has poor ability to generalize to unseen data. Second, optimizing the model on an unrealistic part or sub-part of the actual use cases creates an illusion of solving the problem, and will never lead to a realistically good model. Essentially, the quality of the dataset from the perspective of these two metrics defines whether we will find optimal and practical solutions for hand pose recognition with CNNs. So, how good is the quality of current hand pose recognition datasets? Is building an accurate hand pose recognizer just a matter of optimizing the techniques instead of building a new datasets? The short answer is “no” as I explain below.
Common benchmark datasets
There are three major mono-RGB datasets for hand pose recognition: Ego-Dexter [16], Dexter+Object [22], and CMU Panoptic Dataset (CPD) [19]. Ego-Dexter and Dexter+Object datasets are a collection of frames from a single person performing various actions, including object interaction, in front of a webcam. Since the indi-vidual data points for both datasets are frames from video sampled every 15 frames, images of some hand poses are highly repetitive and correlated with each other.
Figure 2-8: Example pictures from Ego-Dexter dataset
Figure 2-9: Example pictures from the CMU Panoptic Dataset
Object interactions for these two datasets are very staged so as to show the most of the hand all the time and most of the frames in the dataset are a picture of the hand travelling to reach the object rather than interacting with it as shown in Figure 2-8. Dexter datasets not only fail to reflect complexity level of common object and hand interactions but also have poor distinction between the training and test set.
The CMU Panoptic Dataset consists of two parts: the core dataset and the multi-view bootstrapping dataset. I will leave a discussion of their bootstrapping data to the next section, since it is only used as additional training data, whereas the core dataset is used for benchmarking. Their core dataset is an annotated collection of frames from New Zealand Sign Language (NZSL), which is a series of videos of people telling stories using sign language.
Because NZSL videos are longer than the ones in the Dexter datasets, the CMU Panoptic Dataset selected frames 5 seconds apart from each other to ensure the
Dataset # of Frames # of scenes # of objects Distinct frames
Ego-Dexter 3,194 4 17 No
Dexter+Object 3,151 2 1 No CMU Panoptic
Dataset 2,758 3 0 Yes
Table 2.1: Summary of major hand datasets
hand poses are distinct and the number of repetitive frames is small. However, the dataset still suffers from similar artifacts of using video frames as Dexter. All NZSL videos share the same solid background and there were only three people in the entire series, two of which are shown in Figure 2-9. Furthermore, there are no object-hand interaction in NZSL videos, which greatly lowers the difficulty and realness of CMU Panoptic Dataset for benchmarking purposes. Current state of the art systems seem reasonable, predicting 80% of the keypoints within 15 pixels and 21.2 pixels on Dexters and CMU panoptic Dataset respectively, when the length of the entire hand is 212 pixels [15, 20]. However, one must consider this result with caution because all three major datasets lack even basic object and hand interactions and varied backgrounds.
Bootstrap datasets
The quality of available datasets for hand pose recognition is still immature and lacks the qualifications to provide meaningful insights for creating a practical hand pose detector. However, the task of building a good dataset is challenging, mainly because getting a full 21 point annotation for hands is a time consuming and difficult task. To put the matters in perspective, annotating just bounding boxes for objects and their types for a few objects takes about 30 seconds but annotating the locations of 21 keypoints could easily take two minutes. As we can see from Table 2.1, major hand benchmarking datasets have at most three thousand fully annotated pictures due to the large effort required for each annotation, while the typical CNN requires a dozen thousand images for training to reach good performance.
Figure 2-10: Example pictures of the Rendered Handpose dataset
generating the fully annotated data. The most notable and publicly available syn-thetic dataset is the Rendered Handpose dataset from Zimmerman et al. with 43,986 total images [30].
This dataset is generated by making the animation characters perform different gestures using the popular graphics framework Blender [2]. We should note that the Rendered Handpose dataset lacks any object interaction, and the texture of the annotated hands might be too different from real hands to help CNNs generalize to real hands.
The CMU multi-view bootstrapping dataset addresses these two concerns. They used a collection of 12 cameras distributed around the room to shoot videos of various people performing different actions such as playing musical instruments and interact-ing with various tools (Figure 2-11). Then, they used off-the-shelf hand pose detectors to annotate the hand pose for each of these viewpoints and cross validated the results against each other to correct erroneous hand keypoint detections from difficult view-points. This method results in the generation of mostly correct annotations without human involvement, and successfully produced 14,817 full annotations of hand poses from various viewpoints.
Whether training on these bootstrapping datasets on top of the training sets from benchmarking datasets substantially helps CNNs generalize to real data is hard to evaluate since most of the benchmarking datasets have highly correlated training and test sets. In fact, Simon et al. reported little effectiveness of using a bootstrapping dataset when evaluated on their core dataset but observed better overall performance
Figure 2-11: Example pictures of CMU multi-view bootstrapping dataset (same hand pose shown from multiple perspectives)
for qualitative results. This finding suggests yet again the need for a better bench-marking datasets to gain further insight into optimizing current approaches.
2.2.2
Techniques
CNNs are the main workhorse of current state-of-the-art hand pose detectors. These methods1, Simon et al. and Mueller et al. [15], use a slightly modified version of
two popular CNN architectures, Convolutional Pose Machines [28] and Resnet [9], to generate confidence heatmaps for the location of each keypoint and use various post-processing techniques to derive the final hand pose. Current hand pose recognizers are therefore as powerful as the potential of the CNN architectures they are using. So, how powerful are these CNNs? Is the architecture of these CNNs rich enough to handle a high level of occlusion and high degrees of freedom of hands? As I will establish below, current CNNs are designed with features sufficient to address these tasks in theory but not in reality.
1Both Simon et al. and Mueller et al. reported the highest performance on CMU Panoptic and
Convolutional Pose Machines (CPMs)
Convolutional pose machines consist of a series of stages of convolution and pooling layers, as shown in Figure 2-12. The first stage has a smaller field of vision of 9 pixels and creates a confidence map for the location of each keypoint based on local image features. These confidence maps then feed the next stage of convolutional layers along with the original image features. Essentially, at each step, field of vision is increased and the confidence maps are refined based on higher level features. One can have more stages stacked together until the field of vision is equal to the desired level. This stacked structure of merging high and low level features allows CPMs to learn relations between individual keypoints and infer the position of occluded keypoints based on visible keypoints.
However, successfully doing so requires a non-trivial amount of training examples of a particular hand pose to optimize the parameters of each stage of CPMs. As a result, CPMs correctly infer the position of occluded keypoints if the overall pose is commonly represented in the training data but generalize very poorly to unseen hand poses (Figure 2-13). CPMs, therefore, might have all the theoretical capacities for solving the hand pose recognition problem but their performances are only as good as their training datasets. Since the space of possible hand poses is near infinite and collecting a large dataset is challenging, CPMs are an unlikely candidate for addressing the high degrees of freedom of the human hand.
The Resnet architecture
Resnet is a stacked layer of 34 convolutional layers but with a special property. Be-tween every two convolutional layers, there is a residual connection that carries the output from previous stages to the current feature vector, as shown in Figure 2-14. This connection facilitates the learning of identity functions as well as creating an association between lower and higher levels of the feature. Although associations between lower and higher level features are created in a less direct manner than in CPMs, Resnet architecture shares similar characteristics with CPMs in detecting
oc-Figure 2-12: Architecture of Convolutional Pose Machines. More details are at [24]
Figure 2-13: Examples of a CPM inferring locations of occluded points based on visible keypoints. It produces successful detections of common hand poses in the CMU multi-view bootstrapping dataset, such as holding a cup or a bowl, but fails to generalize to less common grasps, such as holding a keyboard.
Figure 2-14: Architecture of Resnet 18 [9]
cluded points, and offers no additional advantages over CPMs for generalizing better to unseen data.
2.3
Building a hand pose recognizer in a perfect
world
Current state-of-the-art mono-RGB hand pose recognizers have a few limitations. Pose detection techniques are overly reliant on their training datasets, but collecting a comprehensive training dataset with various backgrounds is a challenging task because of high degrees of freedom. Further, the lack of a realistic benchmarking dataset makes it harder to evaluate the true effectiveness of current state of the art techniques. So, it seems that the natural next step to alleviate immediate problems is to construct better benchmarking and bootstrapping datasets, and doing so would improve current hand pose detectors. Improvements might be perhaps marginal or substantial but it is not entirely clear whether fixing current pressing issues would eventually lead us to the ultimate hand pose detector. Instead of focusing my effort in addressing short term problems and bottlenecks, let us try to consider the problem in the grand scheme of things. What would we need to do to solve the hand pose recognition problem if we were living in a perfect world with unlimited time and resources?
Collecting a benchmark dataset that is challenging and realistic is the first task because we would need to evaluate the performance of hand pose detectors to optimize and refine their techniques. We could perfectly do so with unlimited resources. To make the hand pose detector perform well on that benchmark dataset, we could
train current CPMs on a bootstrap dataset that has billions of hand poses in various backgrounds and holding different objects. However, there will still be hand poses and objects that network has not seen when the space of possible hand configurations is near infinite. This signals that we need to find methods that are less reliant on training data and can generalize to unseen data better than CPMs, even in a perfect world. From this simple thought exercise, we can clearly see that building a realistic benchmark dataset and finding more generic pose recognition techniques are foundational steps for creating an ideal hand pose detector.
Chapter 3
Steps to building an ideal hand
pose detector
Having identified the essential components in the grand scheme of the hand pose recognition problem and established the limitations of the current state of the art, I will present the steps taken to bridge gap between what has to be done in a perfect world and what has been done as of now.
Toward the goal of creating better datasets, I will show a unique way of collecting a dataset that does not require any annotations but can be used for meaningfully benchmarking the performance of hand detectors in realistic settings. A new dataset with 12,000 images collected using this methodology, which I and my colleagues cre-ated, will be presented along with careful analysis and benchmarking of current state of the art methods on the new dataset. The richness and difficulty of this dataset brings us closer to an ideal benchmark dataset collected in a perfect world. I hope that this dataset will open exciting new ways for future researchers to find and improve on flaws of their approaches.
For the task of finding pose recognition techniques that generalize well to unseen data, I have conceptualized a novel generative technique based on my custom syn-thetic hand generator, and show the potential of this new technique in the realm of synthetically generated hands. Perfecting this technique to real hands and creating a fully working pose recognition method that generalizes well to unseen hand poses
are tasks well beyond the scope of this masters thesis and could be a whole research area on its own. Nevertheless, I performed the work in hopes of providing insight for future researchers and to emphasize the importance of having more generalizable and less data hungry methods. The synthetic hand generator used in this work is the first of its kind to follow the natural distribution of human joint lengths, which is a notable contribution towards building ultra realistic synthetic hand generators.
3.1
Steps towards a realistic benchmarking dataset
To reiterate our mission, we want to create a benchmarking dataset that accurately reflects the reality of common hand poses and interactions with objects in various backgrounds and contains at least a dozen thousand images. The first major chal-lenge in constructing such a dataset is the effort required for obtaining ground truth annotations as we discussed earlier. The second challenge is ensuring that the col-lected dataset covers the realistic scenarios of hand object interaction. I will present a data collection method that intelligently solves both challenges and introduce a new challenging MIT Occluded Hand Dataset that achieves both objectives. Furthermore, I will benchmark current state-of-the-art systems and establish human baseline per-formances and inter-coder agreement on this dataset to set clear expectations and performance goals for future researchers.
NOTE: The scale of work required for MIT Occluded Hand Datasets is well beyond the capability of one person, and the results and data presented here is shared work between me and my awesome colleague Cristina F. Mata under the direct supervision of Dr. Andrei Barbu.
3.1.1
The MIT Occluded Hand Dataset
Collection Method
A group of two people is assigned a box of objects. One person holds an object and the other person takes a pair of pictures: one while the object is in the hand and the
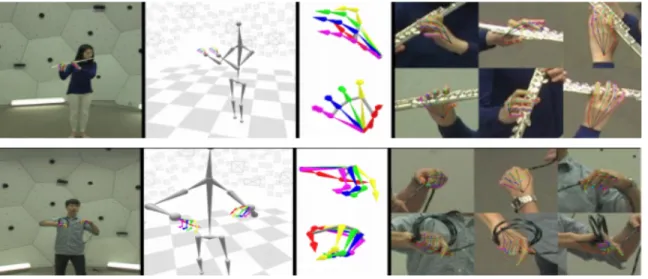
Figure 3-1: Pairs of pictures from the MIT Occluded Hand Dataset taken by methods described in Section 3.1
other after the object is taken away from the hand with the pose held still. (Note that the camera is in a fixed position on a tripod.) A pair of pictures collected in this way provides two views of the same hand pose with and without object occlusions up to a small error of body motion due to breathing in between the consecutive shots. A good hand pose detector should be able to recover from these natural object occlusions and produce consistent hand poses between a given pair of images; thereby, this method conveniently allows us to benchmark the quality of hand pose detectors based on self-consistency rather than costly ground truth annotations by people. More importantly, this self-consistency brings benchmarking focus to the hand-object interaction, which is the core application area for practical hand pose detectors.
Figure 3-2: Pictures of a subject performing 4 different grasps with paper lantern.
efficiency and quality of the dataset. We preselected various locations for photoshoots to cover drastically different backgrounds and numbered the objects in the box to keep track of object instance and background present in the images. We also asked the our participants to perform four different grasps per object in a given location to maximize the number of different hand poses and prevent participants from holding objects using the same grasp (e.g. holding objects from the bottom).
To make the grasps natural, we encouraged people to think of natural ways of holding the object when choosing the poses, such as giving the object to someone or inspecting it closely or at a distance. However, we avoided providing more specific instructions than that to avoid artificially biasing the dataset. Furthermore, we took the extra step of ensuring that objects in the dataset are common household items and used normal smartphone cameras for the photoshoots to make the benchmark pictures more real and practical.
As we can see from Figure 3-2, resulting hand poses look natural and highly variable even for the same object, serving as the first realistic baseline for hand pose detectors.
Figure 3-3: PCK curve of Simon et al evaluated on NZSL dataset. Dataset Statistics
I collected a total of 12,000 images with 150 objects (shown in Figure 3-4) in 10 different locations. All 150 objects are equally represented in the dataset with 40 pairs of pictures per object. It took approximately one hour for a group of two people to collect 100 pairs of images. A total of 60 hours distributed across four teams of two were dedicated for the data collection.
Since the dataset is collected using different smartphones, our images have variable dimensions and it is ambiguous to compute consistency metrics across the entire dataset. Therefore, we will convert a consistency metric computed on a full resolution image to the equivalent metric computed over an image size of 640x4801 for following sections. We found that the average size of a bounding box around the extremities of hand is 48x48 and the average area of an object is roughly same size as the hand, 47x47.
Performance metrics
I will use Percentage of Correct Keypoints (PCK) score, a popular criterion to eval-uate pose estimation, to quantify the consistency between occluded and unoccluded images for the rest of the benchmarking analysis. In PCK, keypoint annotation is defined to be correct if it falls within a given distance from the ground truth an-notation, and the percentage of correct points over all keypoints is visualized as a cumulative distribution function of a distance (Figure 3-3). In our case, annotations
1640x480 is a standard image size of Dexter datasets (Section 2.2.1) and chosen to conveniently
Figure 3-5: Performance of Simon et al. (blue) and Zimmerman et al. (red). (a) PCK as Cumulative function of distance (b) The histogram of euclidean distances between location of corresponding keypoint pairs on occluded and unoccluded images
in unoccluded pictures are treated as ground truth and then compared against oc-cluded pictures; essentially, measuring how consistently the system is reconstructing the keypoints between a pair of occluded and unoccluded images.
Although PCK provides full information about consistency and its specificity, it is hard to compactly represent it without the full graph. Thus, we additionally report the mean and standard deviation of euclidean distance between corresponding keypoints in pairs of occluded and unoccluded images, and will refer to this metric as mean error and standard deviation for convenience.
3.1.2
Benchmarking current state of the art
As introduced in Section 2.2.2, Simon et al. and Muller et al. hold the best perfor-mances over the CMU Panoptic and Dexter datasets respectively. However, Muller et al. did not release the code for their full framework. Thus, we will evaluate the performance of two systems: Simon et al. and Zimmerman et al.2 instead. Both
systems performed much worse on our dataset than their performance on NZSL and Dexter.
As shown in Figure 3-5, Zimmerman et al. produced keypoint annotations that
are 100 to 500 pixels apart from each other when the entire width of image is 640 pixels, and only managed to create consistent results within 40 pixels for 78% of the total keypoints when the average hand is 48 by 48 pixels. This essentially implies that Zimmerman et al. failed to find the location of the hand half the time (derived from Figure 3-5 (b)) and essentially produced the keypoints around a random location in the entire image plane.
The performance of the Simon et al. was slightly better. Most keypoints are detected within the hand region since almost 98 percent of the keypoint pairs had less than 48 pixel distance between each other as shown in Figure 3-5 (a). However, it performed very poorly on our dataset. Only 75% of the points were consistent within 10 pixels, roughly 0.2 in normalized hand distance, down from 87% on the NZSL dataset. Furthermore, the reported mean error and its standard deviation were 16.15 and 43.82 pixels respectively.
The large magnitude of standard deviation shows that keypoint predictions vary wildly across the region of the hand on the occluded images yet again showing the poor generalization of current hand pose detectors despite various bootstrapping datasets used for training (Section 2.2.2). This dataset is already providing us with new insights, such as allowing us to evaluate the effectiveness of bootstrapping methods for generalization, which previously was not possible to measure.
3.1.3
Human baseline
We have established the performance of current pose detectors and shown that they are very poor, mainly by comparing the mean and standard deviation of error to relative hand size. What then, if the standard deviation becomes significantly smaller than the hand size? Such performance would surely be better than the current state of the art, but could this be considered just better than most or very good performance? How do we know what reasonable performance is, especially when reaching a perfect consistency between occluded and unoccluded annotations is inherently impossible for any type of hand pose detector given that reconstructing the occluded keypoints is an under-constrained problem? For that reason, we will establish a human baseline
Figure 3-6: Performance of human annotators. (a) PCK as Cumulative function of distance (b) The histogram of euclidean distances between location of corresponding keypoint pairs on occluded and unoccluded images.
performance for our dataset, and treat the human baseline as a threshold for the best possible performances. Many other computer vision tasks such as object recognition follow this trend [17].
We selected a total of 200 pairs of images with varying level of occlusions and collected full 21 point annotations on them using a web annotation tool interface described in Chapter 6. To ensure the correctness and validity of the human baseline, we obtained annotations from four different people for each picture, one by in-house annotators and three by annotators from Amazon Mechanical Turk [3], then removed the outlier points created by human error for PCK computation. These outlier points as one would expect mostly occurred in Amazon Mechanical Turk annotations.
Human performance
We found that mean error of humans was 8.97 pixels with standard deviation of 7.29 pixels. The mean error is roughly two and standard deviation is six times smaller than the best machine performance. This suggests that humans are much more consistent in reconstructing the same hand pose in the presence of object occlusions. Furthermore, humans strongly agree with each other.
Figure 3-7: The intercoder agreement by hand keypoints. (a) only for unoccluded points (b) only for occluded points.
Human intercoder agreement
The intercoder agreement between people was 4.74 pixels (variance 5.90 pixels) across all points. The high variance is an artifact of discrepancy of intercoder agreement on occluded and unoccluded points, as shown in Figure 3-8. On unoccluded points, agreement is far higher with a mean of 3.0 pixels and variance of just 1.49 pixels, while the mean increases to 6.64 pixels (variance 3.10 pixels). We can further observe that some keypoints with vague definitions like the middle of the wrist have the lowest intercoder agreement, suggesting that actual human intercoder agreement may have been lower than 4.74 pixels.
Even with ambiguity in the definition of keypoints, having 4 pixel intercoder agreement on a annotation task with area of 2304 pixels (48x48) for 21 keypoints on average is remarkable accuracy. We can confidently conclude that humans are very accurate at hand pose recognition and their judgements are universally consistent. Thus, human baseline numbers reported here are a good threshold of high accuracy in our dataset.
Figure 3-8: Performance of Simon et al (blue) and Zimmerman et al (red) vs human gold data. (a) PCK as Cumulative function of distance (b) The histogram of eu-clidean distances between location of corresponding keypoint pairs on occluded and unoccluded images.
3.1.4
Machine vs Human
Having established the correctness of human annotations, we now compare machine with human performance by taking the human annotations on unoccluded images as ground truth and checking them against machine-produced annotations on occluded images. This comparison will give us insight on how correct the machine predictions are instead of measuring consistency in the presence of object occlusions.
The mean error of Simon et al almost doubles from 16.15 to 33.29 pixels, standard deviation also increases to 69.30 from 43.82 pixels. Such a huge change in performance suggests that current state of the art hand pose detectors largely lack the ability to correctly identify the hand pose under object occlusion and most numbers reported on their respective datasets do not reflect actual performance of those hand pose detectors in real life scenarios.
3.2
Steps to more generic hand pose detector
Apart from variations in keypoint detection and other pre/post processing methods, all modern hand recognition techniques (e.g. Simon et al., Mueller et al., and
Zim-merman et al.) to date can be summarized by one common bottom-up framework: determine the candidate keypoints on the RGB or depth image; then, fit a human hand model to those candidate keypoints to ensure a valid human hand pose. This pattern, seemingly natural from an engineering point of view, has gone unquestioned for many years.
I have explained that such bottom-up methods rely too much on training data to infer the positions of the occluded points based on unoccluded points, which leads to poor generalizations on unseen poses. We have also seen this poor generalization through how severely performance dropped on a new and more realistic benchmark from performing fairly well on a benchmark that encompasses relatively few con-figurations of hand poses. Now, I will propose a fundamentally different generative top-down approach that has the theoretical capacity to generalize to any unseen hand configurations. I will provide the working components for this method to complete my part of a journey towards building a ideal hand pose detector in the grand scheme of the problem.
I will introduce the overall design of the framework in Section 3.2.1, and present the details of individual components of the framework in following sections. Finally, my attempt at a proof of concept implementation is provided in Section 3.2.4.
3.2.1
Generative hand pose recognition framework
(HandPi-casso Framework)
We will base this framework on the simple intuition that using the structure of overall pose of the hand is easier and more reliable than identifying the location of individual keypoints based on low level features. So, in this top-down approach, for a given real image of hand, we will generate an initial candidate hand pose and iteratively refine the pose until it looks similar to the pose in the picture. Kulkarni et al. [13] showed that similar top-down approaches could be successful for body pose estima-tion. He created a generic probabilistic programming framework, PICTURE, that incrementally updates the pose of a synthetic 3D model of the human body until it
Figure 3-9: Original block diagram of PICTURE framework [13]
looks similar to the human pose in the real picture. We will draw inspiration from the PICTURE framework shown in Figure 3-9 and propose a new architecture that is more optimal for the hand pose recognition task.
Original PICTURE framework
I will provide a brief explanation of operations of the PICTURE framework to mo-tivate and clarify the design choices of our framework in next section. For a given picture of hand, the PICTURE framework first samples random renderings of syn-thetic body pose from the 3D body model specified in scene language, a probabilistic programming language designed for PICTURE [13]. Then, the representation layer converts the respective pictures into a feature vector. The likelihood comparator uses the Euclidean distance between these feature vectors to infer the current likelihood that the rendered hand is the same as in the observed image, and uses features from the feature vector to update the 3D human body model parameters to increase the likelihood [13]. Eventually, a similar body pose found iteratively.
Figure 3-10: Block diagram of proposed framework HandPicasso framework
The basic order of operations in our HandPicasso framework is essentially the same as the original PICTURE framework except the main components are different and tailored towards the hand pose recognition problem. First, our framework samples random hand poses from a custom-built hand simulator. Then, the CNN-based dis-tance function outputs the approximate disdis-tance between the observed and rendered hand poses. Based on the gradient of the distance function, the inference engine updates the hand pose in the simulator to minimize the output of the CNN based distance function until the observed and rendered hand poses are reasonably similar to each other.
Using the CNN-based distance function instead of the representation layer is a much more accurate choice for hand pose estimation. The representation layer in Kulkarni et als work is based on generic Chamfer matching, which matches the tem-plate of the object with its picture using edge detection and fine-to-coarse contour matching [25]. This approach is sensitive to environmental noises and to resolution. On the other hand, a CNN trained specifically for the task of measuring the distance
between two hand poses utilizes more abstract features of hand shape and creates a representation robust to background and resolution. In addition, we can tailor the architecture of the CNN to deal with specific scenes of hand pose estimation such as lower resolution and motion blur without modifying other parts of the framework (discussed more in Section 3.2.5).
Our inference engine assumes a generic distance function such as Euclidean dis-tance for determining disdis-tance between two hand poses. The inference engine will compute the gradient of the distance function with respect to hand simulator pa-rameters and updates the hand pose to minimize the distance between observed and rendered hand poses. The loop is repeated until convergence.
Strengths and weaknesses of the proposed framework
An inherent advantage of this approach is the fact that it does not rely on having seen certain pose configurations, since the synthetic hand generator can simulate every possible hand pose configuration. However, it also implies that a CNN-based distance function has to be not only accurate enough to lead us to correct hand poses but also convex enough such that gradients efficiently guide us through a large space of possible hand configurations. Rigorously ensuring that the CNN-based distance function has such characteristics is nearly impossible since current mathematical analysis tools for deep learning have not developed to that level yet. Therefore, there are no guarantees on behaviour of the CNN-based distance function, and experimentally creating a CNN with the desired properties might be tricky on real datasets. Nevertheless, I was able to create such a CNN without much trouble on synthetic data and will show the details of training and the architecture of the CNN along with details of the hand generator in the following sections.
3.2.2
Custom hand generator (HandDoodle)
Synthetic hand generators play a crucial role in the mass production of hundreds of thousands of training images for CNNs. However, there are not many publicly
avail-Figure 3-11: Example renderings of generated hands by Libhand framework.
able hand pose generators because of the complexity and effort required for building an accurate hand pose generator. The only hand pose generator that is publicly available is Libhand [26]. Overall, the rendering quality of the Libhand interface is quite realistic and is able generate all possible hand poses with a full 27 degrees of freedom.
However, Libhand uses only one model of a synthetic hand and does not feature the ability to change joint lengths, which is essential for our application. The variations in human finger joint length is quite significant, having standard deviation of 0.8 centimeters on average, and this difference increases to 1.5 centimeters between male and female hands [8]. So, if we do not take into account this vast difference in joint lengths in our hand generator, it may confuse the CNN distance function, leading to inaccurate results when the anatomy of the hand being considered is different from the model of the hand used by the hand generator. Thus, I built my own more flexible hand generator which not only samples different joint lengths but also samples according to a natural human joint length distribution provided by data from Department of Defense [8]. I will refer to this hand generator as HandDoodle
Figure 3-12: Rendering of randomly generated hand poses. HandDoodle supports different types of hands, e.g., african male (left) and caucasian female (right).
from now on. High level functionalities of HandDoodle are introduced below and implementation details are elaborated in Technical References Section 6.1.
Sampling of Random Hand Poses
There are a total of 19 joints in the human hand: 3 joints per finger, 4 metacarpal joints and one wrist joint. HandDoodle features the ability to randomly sample the position for each joint according to natural human hand constraints. The sampling method and joint motion constraints in our hand generator (explained in in detail in Section 6.1.1) ensures the generator can cover the entire space of possible hand poses.
Figure 3-13: Linear interpolation between reference (yellow) and target (green) hand poses.
Interpolation of hand poses
HandDoodle also offers a way to interpolate the intermediary hand poses between any two reference and target hand poses. As an example, I generated the 8 equally spaced intermediary hands in Figure 3-13.
We can see from Figure 3-13 that hand poses in earlier stages of interpolation look more similar to the reference hand and start looking more different as they approach the target hand pose. The interpolation feature comes in handy when controllably generating pairs of hand poses that look similar or dissimilar from each other. The training procedures for a CNN-based distance function described in the next section make heavy use of this feature.
Natural joint length sampling
The Department of Defense conducted the first and only comprehensive study on anthropometric variation of human hand in 1989 for the purpose of designing protec-tive gloves for soldiers. They measured the length and breadth of hand joints across 3,400 test subjects for both men and women [8]. Based on these measurements, they provided the mean and standard deviation for the length of each finger joint and computed the correlation matrix between all joints in the human hand. We will refer to these measurements as DOD data. However, DOD data only existed in a scanned PDF format and was not digitally accessible.
natu-Figure 3-14: Hands generated using DOD data. The pose of hands are kept the same to illustrate the variation in joint lengths.
ral human distribution had significant implications not only for the accuracy of my HandPicasso Framework but also for improving the overall realness of current syn-thetic hand generators. Thus, I put in effort to manually transcribe the DOD data to digital format using OCR software, and successfully integrated it into HandDoodle. The end result is shown in Figure 3-14.
3.2.3
The CNN based distance function (HandNet)
The task of the CNN-based distance function in HandPicasso is pretty simple: given a pair of hand pictures, produce a single number indicating the distance between them. The smaller this number, the more alike the hand poses, and the higher the number the more different the poses look. Conventional methods used in academia
for measuring the distance between two hand poses requires a full annotation of the hands. However, this CNN-based approach does not require explicit annotation and performs equally and sometimes better than current metrics. So, I want to emphasize that HandNet is not just a component of HandPicasso but also the first approach introducing the usefulness of CNNs for measuring the similarity between two hand poses. I will first define the two most popular hand distance functions, and then present the details of HandNet as well as demonstrate its capabilities in comparison to two conventional metrics described in the last part of this section.
Hand distance functions
Euclidean distance and angle joints are popular metrics used in academia for measur-ing the distance between two hand poses. Euclidean distance is simply defined as the sum of Euclidean distances between the corresponding keypoints of two hand poses and focuses on measuring the spatial similarity of the hand poses.
Angle joints distance is, on the other hand, more focused on measuring the simi-larity between the poses of hand joints. The pose of a human joint can be uniquely defined by the length and 3 angles (roll, pitch, and yaw) around axes defined in the ZYX Euler convention (more details in Section 6.1.1). Thus, angle joints distance is defined as the sum of the squared differences of those 4 parameters over each joint. More precisely, it is defined as,
AngleJ oints =X
i
(Li1− Li
2)2+ (θi1,r− θi2,r)2+ (θ1,pi − θ2,pi )2+ (θi1,y− θ2,yi )2
where Li1 and θ1,ri are the length and roll angle of joint i in the first hand pose. θi1,p and θi
1,y are similarly defined for pitch and yaw. The subscript 2 indicates the same
parameters for the second hand pose. HandNet architecture
The architecture of HandNet took inspiration from Resnet, described earlier in Section 2.2.2. The images are vertically concatenated together and fed to convolutional layers
Figure 3-15: Top: Architecture of HandNet, Bottom: Resnet 18 Architecture, layers used in HandNet are boxed in red. Note that there is a ReLU layer in between every convolutional stage of HandNet but these are not shown in the figure for clarity. from a pre-trained Resnet 18 architecture for feature extraction. I have used the first two stages of a convolutional block from a pre-trained Resnet 18 to extract only low level features of the images. Using pre-trained weights from Resnet 18 is advantageous for our purposes since it is already optimized for creating accurate feature representations for over 5,000 categories of objects and scenes from ImageNet [6].
These low level feature vectors are then fed to series of convolutional layers with larger kernel size to extract the high level features of hand components, and then averaged with a pooling layer before feeding into a series of fully connected layers to output the single distance. The average pooling layer here is crucial for HandNets ability to generalize to unseen hand poses since networks tend to overfit to the training data without this layer.
Training data
The training dataset for HandNet consists of 270,000 unique pairs of renderings of hand poses generated by HandDoodle with Euclidean distance and angle joints com-puted as labels from ground truth pose parameters and keypoint locations for each
pair. First, I tried generating the pairs by randomly sampling two hand poses from HandDoodle. However, it is exponentially more likely to get hand poses that are moderately apart from each other in a pair than getting hand poses that look similar or too different from each other. In fact, such phenomena are well observed in the distribution of distances. As shown in Figure 3-16, we can see that the distribution is unimodal, centered around the midrange of the hand distance metric. When trained on a unimodal dataset, our CNN will not be able to effectively learn to recognize similar hand poses.
Thus, I generated image pairs in a controlled fashion to ensure that the distance distribution is bimodal, covering both hands that look similar and further apart from each other to increase the sensitivity of HandNet. I randomly generated a total of 45,000 seed hand poses. HandDoodles interpolation feature is used to generate hand poses that look similar to, moderately different and very different from the seed hand pose. The linear interpolation is scaled from 0.0 to 1.0 with 0.0 being the same as reference hand pose and 1.0 being the same as target hand pose when interpolating from reference to target handpose. For each seed hand pose, 6 other hand poses are generated by linearly interpolating in the range [0.02, 0.05, 0.10, 0.40, 0.8, 1.0] from the seed hand pose to another randomly generated hand pose in each interpolation stage. This methodology ensures that our dataset is bimodal since 3 similar looking pairs from the interpolation range 0.02-0.1 and 3 different looking hand poses from range 0.4-1.0 are generated per seed hand pose. The distance distribution for our final training dataset is shown in Figure 3-17.
Figure 3-16: Distribution of distances, (a) Euclidean distance (b) angle joints, between pairs of hand poses when pairs are sampled randomly
Figure 3-17: Distribution of distances, (a) Euclidean distance (b) angle joints, between pairs of hand poses when pairs are sampled in a controlled manner
Benchmarking HandNet
Two identical HandNet architectures, one for Euclidean distance and other for angle joints, are trained on the described training dataset with batch size of 256 and using AdamOptimizer with mean squared loss, defined as the difference between the cur-rent output of the network and a respective ground truth distance label. HandNet, consequently, learned to produce an estimate of the two distance functions for a given pair of pictures. Note that the magnitude of estimates from HandNet is smaller than the actual distance metric because of using big fully connected layers but the relative ordering is maintained: the smaller the estimated distance the more similar the hand pose looks. Therefore, direct comparisons of HandNet estimates against the under-lying distance function used in training are not possible. Instead, I will evaluate the performance of HandNet in comparison with the traditional metrics on the task of finding the closest hand poses to a given hand pose from a large database of random hands.
The database contains pictures of 400,000 hand poses randomly generated by HandDoodle. I also randomly generated a reference hand pose and ranked the entire database by the distance estimate from HandNet and by the ground truth distance metrics. The results of this experiment are shown in Figure 3-18 and 3-19 for HandNet trained on Euclidean distance and angle joints distance, respectively. As we can see from Figure 3-18, the performance of HandNet is comparable with respect to the traditional distance metrics. In some cases, the top 5 matches by HandNet have perceptually more consistent hand poses than Euclidean distance.
As for angle joints distance (Figure 3-19), we can draw different conclusions. HandNet, like Euclidean distance , found hands with more spatial similarity (e.g. similar overall orientation) to be closer despite being trained on angle joints distance, which prefers hands that are closer in the pose of each joint rather than overall ori-entation. This behaviour proves that HandNet architecture is learning the spatial similarity based on visual features rather than understanding the intrinsic pose struc-ture of the hand as one would expect from CNNs.
This qualitative benchmarking demonstrates that the capabilities and accuracy of HandNet are sufficient for the application of distinguishing similar hand poses from far-apart ones, and especially better at approximating the perceptual distance, which is a crucial characteristic in HandPicasso. The training procedures and architecture of HandNet, therefore, succeeded in creating all necessary and suitable characteristics for the proposed framework. Thus, one can assume that HandNet will not be the major performance bottleneck of HandPicasso, at least in the realm of synthetically generated hands.
Figure 3-18: Top 5 hand poses with the lowest distance scores to a reference hand pose (shown in left most column) according to HandNet (top rows, highlighted in gray) and ground truth Euclidean distance (bottom rows).
Figure 3-19: Top 5 hand poses with the lowest distance scores to a reference hand pose (shown in leftmost column) according to HandNet (top rows, highlighted in gray) and ground truth Angle joints distance (bottom rows).
3.2.4
Inference Engine
The inference engine is responsible for updating the hand pose in a simulator to decrease the distance estimate from HandNet based on the computed gradient of the distance function, in our case HandNet, with respect to the hand pose parameters of the simulator, in our case HandDoodle. The popular approach for accomplishing such tasks is nonlinear optimization.
I used a popular nonlinear optimization library, called NLopt [12] for this purpose. It offers a variety of solvers for general nonlinear optimization problems of the form Equation (3.1), which, as we will show in the following section, our HandPicasso framework can be conveniently reduced to.
min
x∈Rnf (x) (3.1)
Formulation
HandPicasso can be formulated as a nonlinear optimization problem of the following form:
min
x∈RnD(Ren(x), I
observed) (3.2)
where x is a vector of hand pose parameters; Ren is a function that produces an image of a hand from hand pose parameters, representing HandDoodle; Iobserved is
the observed hand image; and D is a distance function between two rendered images of hands, representing HandNet. In plain English, Equation (3.2) means that we are trying to find the hand pose parameters, x, such that it minimizes the distance from observed image, which exactly summarizes HandPicasso. Consequently, the inference engine of HandPicasso is simply the solver for the nonlinear optimization problem defined Equation (3.2).
For our convenience, let us define a parameter function, H, such that
Then, definition of optimization in Equation 3.2 can be simplified to
min
x∈RnH(x, I
observed)
Solver
There are two main algorithms in NLopt for finding solutions to nonlinear optimiza-tion problems: gradient-based, which uses the gradient of a differentiable objective function, f , to efficiently explore the space of possible values of x, and derivative-free, which is used when the objective function is non-differentiable. The objective function, H(x, Iobserved), in our problem is non-differentiable with respect to the hand pose parameters, x, since doing so would require computing the gradient of Ren(x), which is a simple bijection mapping hand pose parameters to a rendered image. Thus, I will use Derivative-free algorithms as the main solver.
Solver in action
The Derivative-free algorithm samples the value of the objective function at differ-ent values of x, and approximates the gradidiffer-ent of the objective function from those discrete points, then samples new points based on the gradient to reach the min-ima of the function. In our context, sampling the value of the objective function, H(x, Iobserved), consists of two steps. First, HandDoodle renders a new picture of
a hand pose corresponding to the given pose parameter, x. Then, the distance be-tween the original observed image, Iobserved, and newly generated image, Ren(x),is
computed by HandNet and outputted as a sample.
3.2.5
HandPicasso on the go
Having implemented all the components as described in previous sections, I put ev-erything together, and hit the go button. However, the proposed framework has been too slow to produce any meaningful results. The source of this speed bottleneck is the conjunction between the slow sequential rendering engine of HandDoodle and the
![Figure 2-2: Pictures of cups on ImageNet [6]](https://thumb-eu.123doks.com/thumbv2/123doknet/14671757.557004/17.918.135.781.110.296/figure-pictures-of-cups-on-imagenet.webp)

![Figure 2-5: Examples pictures of one of the best mono RGB camera based hand recognizers in 2013 [23]](https://thumb-eu.123doks.com/thumbv2/123doknet/14671757.557004/20.918.146.782.109.307/figure-examples-pictures-best-mono-camera-based-recognizers.webp)
![Figure 2-7: Noisy examples of detected hand poses from hand–object interaction [18]](https://thumb-eu.123doks.com/thumbv2/123doknet/14671757.557004/21.918.149.785.113.374/figure-noisy-examples-detected-hand-poses-object-interaction.webp)


![Figure 2-12: Architecture of Convolutional Pose Machines. More details are at [24]](https://thumb-eu.123doks.com/thumbv2/123doknet/14671757.557004/28.918.140.783.228.501/figure-architecture-convolutional-pose-machines-details.webp)

