An active protocol architecture for collaborative media distribution
Texte intégral
Figure
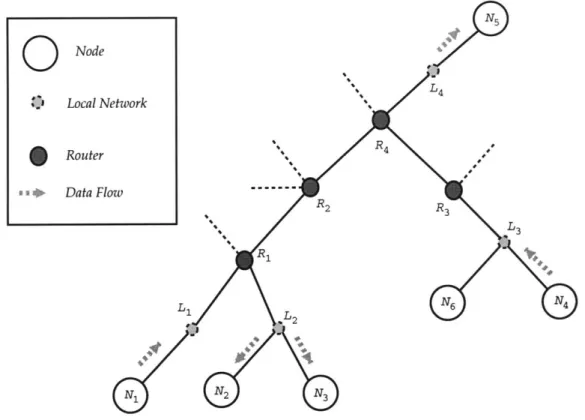
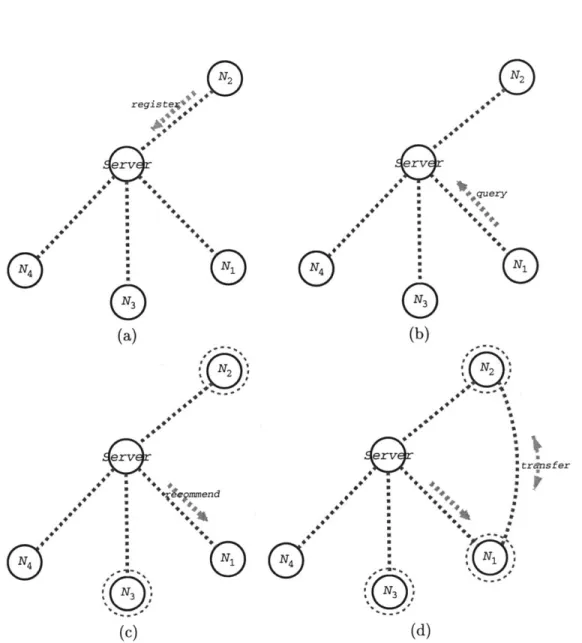
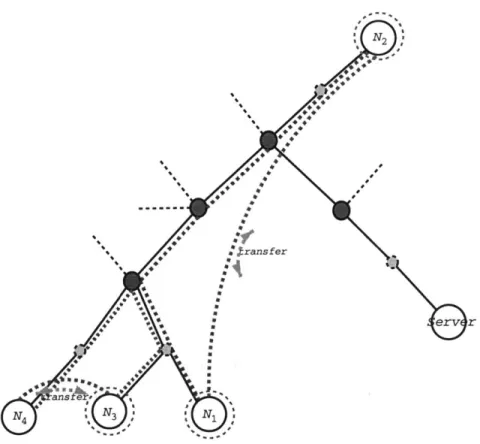
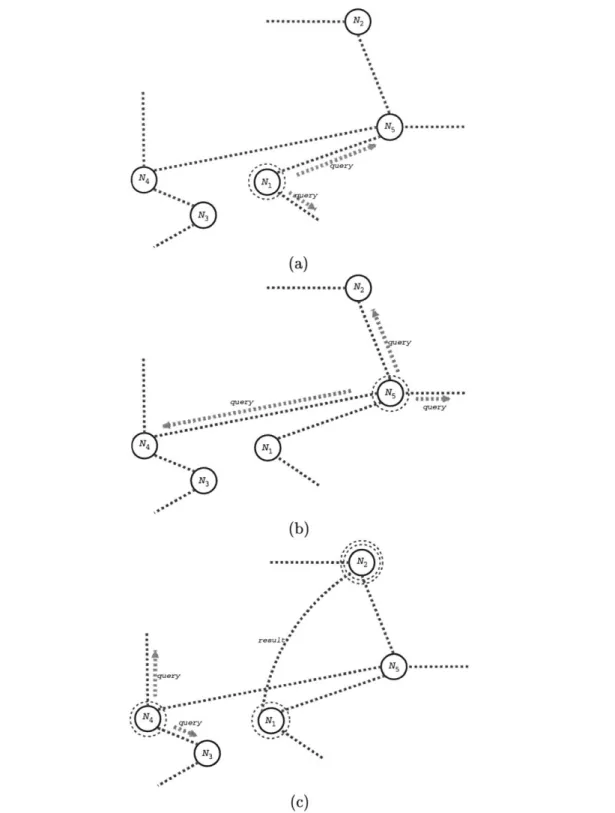
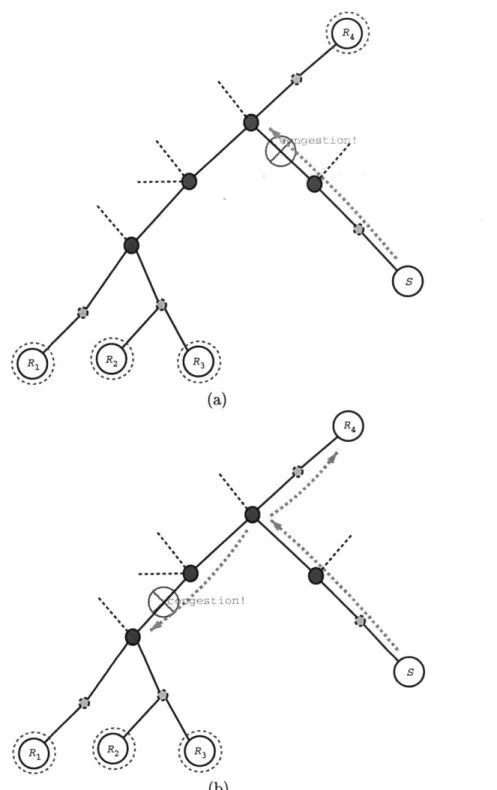
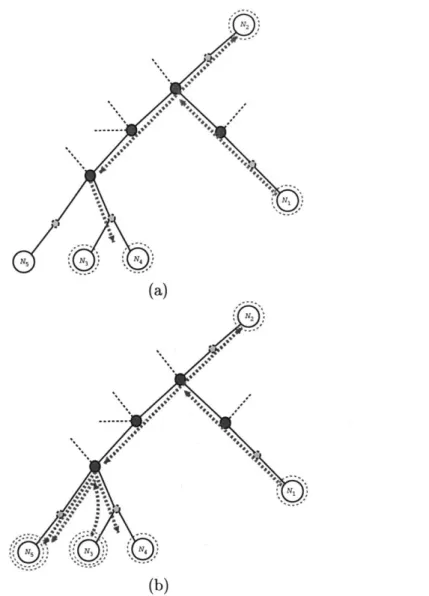
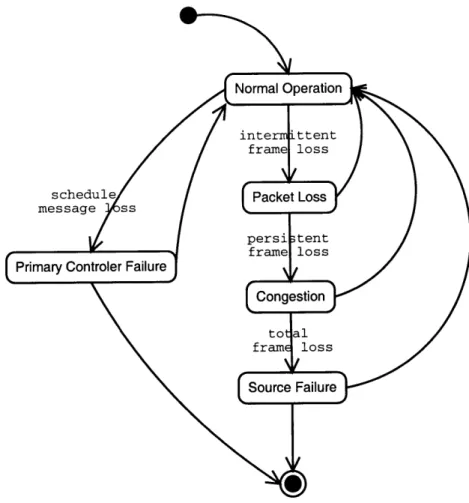
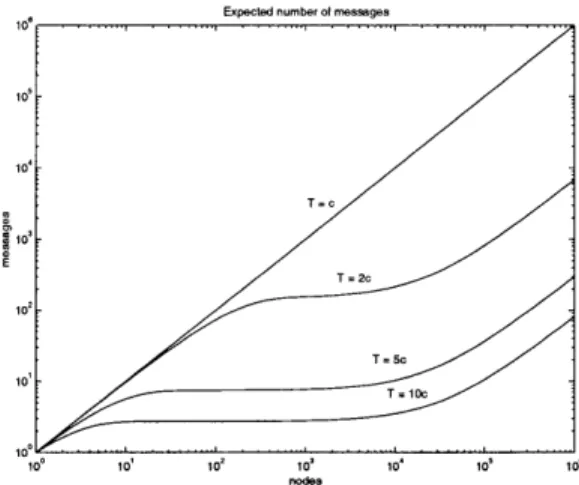
Documents relatifs
Reverse path forwarding (RPF) is a fundamental concept in multicast routing that enables routers to correctly forward multicast traffic down the distribution tree.. RPF makes use of
This paper recommends a new negotiation protocol that enables the possi- bility to negotiate cryptographic protocols instead of deciding upon and using only one version of the
This sums up to a novel, tool-supported, integrated test methodology for concurrent OS-system code, ranging from an abstract system model in Isabelle / HOL which was not not authored
For this aim, this paper proposes a new multicast routing protocol called Multicast Routing protocol with Dynamic Core (MRDC) which constructs and maintains a group- shared tree
DMPDC benefits from a logical infrastructure offered by Distributed Dynamic Routing algo- rithm (DDR) and constructs a group-shared multicast tree with a dynam- ically selected
In our protocol the key server switches among these proposed two schemes and the secret sharing scheme based on the number of leaving members and the real rekey cost corresponding
The disadvantages of the NuMesh approach are that bandwidth in the communication network may go wasted if the processor is unable to fill its reserved communication slots and
If the transmission delay is set according to a non-congested network, the points (messages) above the synchronization error limit (240 ms) at message reception are a total of
