République Algérienne Démocratique et Populaire
يـملعلا ثـحبلاو يـلاعلا مــيلعتلا ةرازو
Ministère de l’Enseignement Supérieur et de la Recherche Scientifique
No Réf :………
Centre Universitaire Abdelhafid Boussouf Mila
Institut des Sciences et Technologie Département de Mathématiques et Informatique
Mémoire préparé en vue de l’obtention du diplôme de
Master
En : Informatique
Spécialité : Sciences et Technologies de l’Information et de la Communication
(STIC)
Préparé par
:
ALI MOUSSA Ikram
MEDJANI Sarra
Devant le jury
Mme. BENABDERRAHMANE Fatiha. MAA C.U.Abd Elhafid Boussouf Président M. SELMANE Samir. MAB C.U.Abd Elhafid Boussouf Rapporteur M. BESSOUF Hakim. MAB C.U.Abd Elhafid Boussouf Examinateur
Année Universitaire : 2016/2017
Conception et Implémentation d’une Base de
Données Distribuée
Remerciement
Nous remercions dieu tout puissant pour nous avoir offert la force et la patience durant toutes ces années.
Nous tenons à exprimer notre profonde gratitude à notre encadreur : Mr. Salmane samir, pour son soutien constant, son aide précieuse et ses conseils attentifs durant tout le projet. Et qui nous ont assuré l’environnement adéquat afin de réaliser notre
travail.
Nous remercierons aussi les enseignants du département de l’informatique qui tout au long des années d’études nous ont transmit leur savoir sans réserves, et tous ceux qui nous ont apporté
une aide pour la réalisation de ce projet.
Sans oublier bien-sûre tous les amis et collègues d’études pour leur enjouement et soutient spécialement Benmakhelouf Riyadh et Graiche Younes.
Ikram & Sara.
Dédicace
Je dédie ce mémoire à :
Ma mère et mon père pour l'éducation qu'ils m'ont prodiguée ; avec tous les moyens et au
prix de toutes les sacrifices qu'ils ont consentis à mon égard, pour le sens du devoir qu'ils
m’ont enseigné depuis mon enfance
A mes chères frères Yacine et Aymen,
A mes chères sœurs Nouzha, Soumia,Amina et Rahma,
A mon neveu Mohemed Anes, et mes nièces Nesrine et Nermine, ces petits anges qui nous
comble de joie,
A mon binôme et mon amie Sara et toute sa famille,
A mes enseignants,
A tous mes amis(es), mes collègues de travail & mes collègues de 2eme année Master STIC
spécialement B. riyad et G.youness .
Dédicace
Au Début et avant tout, je veux remercier le DIEU qui ma donnée le courage à faire et finir ce
modeste travail.
A mes très chers parents «MOHAMED» et «SAMIRA» qui n’ont jamais cessé de
m’encourager que dieu les protège
A mes très chers frères« Mourad» et « Ishaq»
A mes très chères sœurs « Sabrina» et « Dounya »
A ma collègue de projet
et mon amie
« Ikram »
et toute sa famille
à ma tante « SAMIA » qui ma aider pendant tous mes études
Dédier spécial a mon collègue B.riyadh Qui était avec nous et nous a aidés
A toute ma famille « Medjani»
A mes enseignants
A tous mes amis surtout khawla ,ibtissem ,asma
A mes petites layane , rahil ,aya
A toute ma famille de STIC 2, mes sœurs et frères,
promotion 2016/2017, pour leur aide et tous ces moments
inoubliables que nous avons passés ensemble,
Je dédie ce mémoire
A la fin, je remercie tous ceux qui ont aidé de près ou de Loin à réaliser notre travail.
Sara
titre page
Introduction générale 2
Partie I : présentation du domaine d’étude
Chapitre I : Généralités sur les bases de données réparties
1. Introduction 5
2. Principe des bases de données réparties 5
2.1 . Définition 5
2.2 . Concepts des bases de données réparties 6
2.2.1. Schéma global 6 2.2.2. Schéma local 7 2.2.3. Schéma externe 7 2.2.4. Schéma conceptuel 7 2.2.5. Schéma interne 7 3. Avantages 8
4. Inconvénients de la répartition des données 8
5. Les objectifs des bases de données réparties 9
6. SGBD Réparti 10
6.1. Définition d’un Système de gestion de bases de données (Data Base
Management System) 10
6.2. Rôle d’un SGBD 11
7. Architecture des bases de données réparties 11
7.1. Architecture Client-Serveur 11
7.2. Architecture Pair-à-Pair (Peer-to-Peer, P2P) 12
8. Conclusion 13
Chapitre II Conception d’une base de données répartie
1. Introduction 15
2. Conceptions d’une base de données répartie 15
2.1 . Méthode de conception 15
2.1.2 . Conception ascendante (bottom up design) 16
3. Techniques utilisés pour la distribution des bases de données 16
3.1. la fragmentation 17
3.1.1. Définition 17
3.1.2. Objectif de la fragmentation 17
3.1.3. Les problèmes de la fragmentation 18
3.1.4. Types de fragmentation 18
3.2. Allocation des fragments aux sites 20
4. La réplication 20
4.1. Définition 20
4.2. Principe 21
4.3. Les Types de réplication 21
4.3.1. La réplication synchrone 21
4.3.2. La réplication asynchrone 22
4.4. Les avantages de la réplication 24
5. Gestion des Base de donnée réparties 24
5.1. Mise à jour des BDDR 24
6. Conclusion 25
Partie II : Etude de cas
Chapitre I étude préliminaire
1. Introduction 27
2. Élaboration du cahier de charge 27
2.1. Présentation de l’organisme d’accueil 27
2.2. Présentation du projet 28
2.3. Problématique 29
2.4. Objectifs de nouveau système 29
2.5. Grands choix techniques 30
3. Description de contexte du système 32
3.1. Identification des acteurs 32
3.2. Identification des messages 32
3.3. La méthode de conception 34
3.4. Modélisation du contexte 34
3.3.1. Diagramme de contexte dynamique 34
3.3.2. Description détaillée des messages 35
4. Conclusion 36
Chapitre II :capture des besoin fonctionnelle et technique
1. Introduction 38
2. Capture des besoins fonctionnels 38
2.1. Déterminer les cas d’utilisations 38
2.2. Description détaillée des cas d’utilisation 43
2.3. Identification des classes candidates 67
2.3.1. Définition 67
2.3.2. La liste des classes candidates 67
2.3.3. Responsabilités des classes 68
3. Capture des besoins techniques 72
3.1. Spécification technique du point de vue matériel 72
3.2. Spécification d’architecture 73
3.3. Capture des spécifications logicielles 74
3.3.1. Identification des cas d’utilisation techniques 74
3.3.2. Description des cas d’utilisation techniques 75
3.3.3. Organisation en couche du modèle de spécification 83
4. Conclusion 83
1. Introduction 85
2. Découpage en catégorie 85
2.1. La répartition des classes candidates en catégories 85
2.2. Elaboration des diagrammes de classes préliminaires par catégorie 86
2.3. Dépendance entre catégories 87
3. Développement du modèle statique 87
4. Développement du modèle dynamique 89
4.1. Diagrammes de séquences 89
5. Conclusion 106
Chapitre IV : Conception
1. Introduction 108
2. Conception préliminaire 108
2.1 . Développement du modèle du déploiement 108
2.2. Définition des interface 110
3. Conception détaillé 110
3.1 . Conception des classes 111
3.2 . Les opérations 114
4. Diagramme de classe détaillé 114
5. Le modèle relationnel 115
5.1. Les règles de passage 116
5.2. Les règles de gestion 116
6. Les tables de la base de données 118
7.Conclusion 119
Chapitre V : Implémentation
1. Introduction 121
2.
Langage et outils de développement
1212.1. Le langage de programmation java 121
2.2. IDE NetBeans 121
3.1. Oracle SQL Developer 123
4. Structure générale de la solution proposée 123
4.1.
Justification des choix 123
4.2.
Configuration du réseau 1244.3.Configuration ORACLE 124
4.3.1. Le processus d'écoute Oracle 124
4.3.2. Création des services de base de données 124
5. Implémentation de la BDR 125
6. Description de l’application 128
Liste des figures
Partie
Chapitre
Figure
Page
Partie I
Chapitre I
Figure I-1 : Exemple de BD Répartie 6
Figure I-2 :Schéma globale et local 7
Figure I-3: Schéma d'un SGBD 11
Figure I-4 :Architecture Client -Serveur 12
Figure I-5: Architecture serveur-serveur 13
Chapitre II
Figure II- 1 :Conception descendante d’une BDR 16
Figure II-2 :Conception ascendante d’une BDR 16
Figure II-3 :Décomposition d’une BDD global 17
Figure II-4: Fragmentation horizontale 18
Figure II-5: Fragmentation verticale 19
Figure II-6: Fragmentation mixte 19
Figure II-7 :Réplication de données 20
Figure II-8 : Réplication synchrone asymétrique 22
Figure II-9 :Réplication synchrone symétrique 22
Figure II-10 : Réplication asynchrone asymétrique 23
Figure II-11 : Réplication asynchrone symétrique 23
Partie II
Chapitre I
Figure I-1 : L’organigramme de différents services de la
commune du Mila
28
Figure I-2 : Le diagramme de contexte dynamique du
système
34
Chapitre II
Figure II-1 : Diagramme de cas d’utilisation générale 41
Figure II-2 : Diagramme de cas d’utilisation gérer carte
grise
42
Figure II-3 : Diagramme de cas d’utilisation gérer vente
locale
42
Figure II-4 : Diagramme de cas d’utilisation gérer fiche de
contrôle
42
Figure II-5 : Diagramme de séquence système ajouter
nouvelle carte grise
44
Figure II-6 : Diagramme d’activité ajouter nouvelle carte
grise
44
Figure II-7 : Diagramme de séquence système ajouter
duplicata
46
Figure II-8 : Diagramme d’activité ajouter duplicata 46
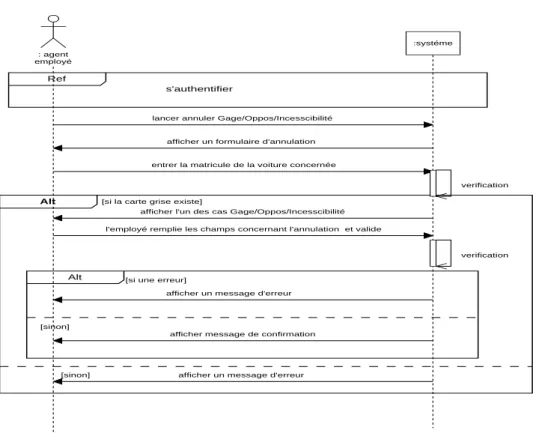
Figure II-9 : Diagramme de séquence système annuler
Gage/Opposition/Incessibilité.
Gage/Opposition/Incessibilité.
Figure II-11: Diagramme de séquence système modifier
carte grise
50
Figure II-12: Diagramme d’activité modifier carte grise 50
Figure II-13: Diagramme de séquence système radier
carte grise 52
Figure II-14: Diagramme d’activité radier carte grise 52
Figure II-15: Diagramme de séquence système ajouter
vente locale
54
Figure II-16: Diagramme d’activité ajouter vente locale 54
Figure II-17: Diagramme de séquence système annuler vente
locale
56
Figure II-18: Diagramme d’activité annuler vente locale 56
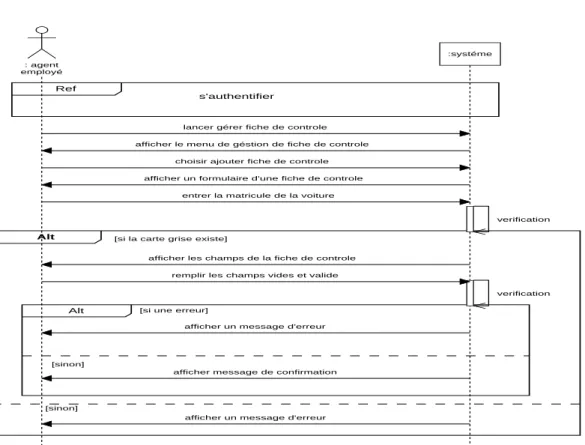
Figure II-19: Diagramme de séquence système ajouter
fiche de contrôle 58
Figure II-20: Diagramme d’activité ajouter fiche de contrôle 58
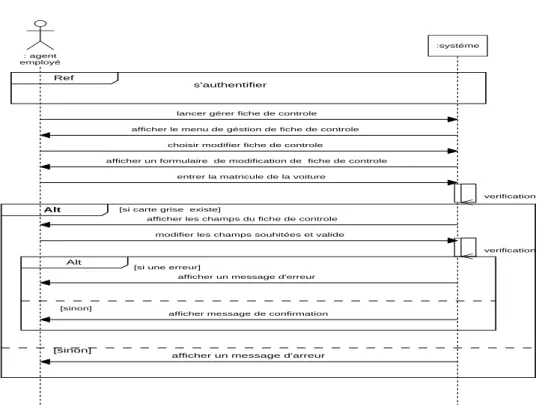
Figure II-21: Diagramme de séquence système modifier
fiche de contrôle
60
Figure II-22: Diagramme d’activité modifier fiche de
contrôle
60
Figure II-23:Diagramme de séquence système annuler
fiche de contrôle
62
Figure II-24:Diagramme d’activité annuler fiche de
contrôle
62
Figure II-25:Diagramme de séquence système établir avis de mutation
64
Figure II-26:Diagramme d’activité établir avis de mutation 64
Figure II-27:Diagramme de séquence système
rechercher carte grise 66
Figure II-28:Diagramme d’activité rechercher carte
grise 66
Figure II-29:La liste des classes candidates 67
Figure II-30:Responsabilité de la classe carte grise 68
Figure II-31:Responsabilité de la classe duplicata 68
Figure II-33:Responsabilité de la classe propriétaire 69
Figure II-34:Responsabilité de la classe fiche de contrôle 69
Figure II-35:Responsabilité de la classe fiche de
confirmation 69
Figure II-36:Responsabilité de la classe avis de mutation 70
Figure II-37:Responsabilité de la classe gage 70
Figure II-38:Responsabilité de la classe opposition 70
Figure II-39:Responsabilité de la classe incessibilité 71
Figure II-40:Responsabilité de la classe administrateur 71
Figure II-41:Responsabilité de la classe employé 71
Figure II-42:Responsabilité de la classe rôle 72
Figure II-43: Architecture 2 niveaux de notre système 73
Figure II-44:Cas d’utilisation gestion des employées 74
Figure II-45:Diagramme de séquence système
s’authentifier 76
Figure II-46:Diagramme d’activité s’authentifier 76
Figure II-47:Diagramme de séquence système créer un
compte 78
Figure II-48:Diagramme d’activité créer un compte 78
Figure II-49:Diagramme de séquence système
activé/désactivé un compte 80
Figure II-50:Diagramme d’activité activé/désactivé un
compte 80
Figure II-51:Diagramme de séquence système modifier
un compte 82
Figure II-52:Diagramme d’activité modifier un compte 82
Chapitre III
Figure III -1: Découpage en catégorie de notre système 85
Figure III-2: diagrammes de classes préliminaires de la
classe rôle 86
Figure III-3: diagrammes de classes préliminaires de la
classe carte grise 86
Figure III-4:Modèle structurel d’analyse 87
Figure III-5:Diagramme de classe détaillé de la classe
catégorie carte grise
Figure III-7:Diagramme de séquence de cas d’utilisation
ajouter nouvelle carte grise
90
Figure III-8:Diagramme de séquence de cas d’utilisation
modifier carte grise
91
Figure III-9 :Diagramme de séquence de cas d’utilisation
ajouter duplicata
92
Figure III-10:Diagramme de séquence de cas d’utilisation annuler gage/opposition/incessibilité
93
Figure III-11:Diagramme de séquence de cas
d’utilisation ajouter vente locale
94
Figure III-12:Diagramme de séquence de cas
d’utilisation annuler vente locale
95
Figure III-13:Diagramme de séquence de cas
d’utilisation ajouter fiche de contrôle
96
Figure III-14:Diagramme de séquence de cas
d’utilisation modifier fiche de contrôle
97
Figure III-15:Diagramme de séquence de cas
d’utilisation annuler fiche de contrôle
98
Figure III-16:Diagramme de séquence de cas
d’utilisation établir avis de mutation
99
Figure III-17:Diagramme de séquence de cas
d’utilisation radier carte grise 100
Figure III-18 :Diagramme de séquence de cas
d’utilisation rechercher carte grise
101
Figure III-19 :Diagramme de séquence de cas
d’utilisation s’authentifier
102
Figure III-20 :Diagramme de séquence de cas
d’utilisation activer/désactiver un compte
103
Figure III-21 :Diagramme de séquence de cas
d’utilisation modifier un compte
104
Figure III-22 :Diagramme de séquence de cas
d’utilisation créer un compte
105
Figure IV-1 : Définition des applications dans le modèle
d’exploitation. 109
Chapitre IV Figure IV-2 :diagramme de classe détaillé 115
Chapitre V Figure V-1 : Capture écran de l’EDI NetBeans 122
Figure V-2 : Interface Oracle SQL Developer 123
Figure V-3 : Oracle Net Manager 125
Figure V-4 : interface d’authentification 128
Figure V-5 : Accueil employé 129
Liste des tableaux
Partie
Chapitre
Tableau
Page
Partie II
Chapitre I Tableau I-1:liste des messages d’administrateur 35
Tableau I-2:liste des messages du système vers
l’administrateur
35
Tableau I-3:liste des messages d’employé 35
Tableau I-4:liste des messages du système vert
l’employé
35 Chapitre II Tableau II-1 :La liste des cas d’utilisation du système de
la carte grise
39
Tableau II-2 : La liste des acteurs et des messages par
cas d’utilisation du système
39
Tableau II-3 :cas d’utilisation ajouter nouvelle carte grise. 43
Tableau II-4 :cas d’utilisation ajouter duplicata 45
Tableau II-5 :cas d’utilisation annuler
Gage/Opposition/Incessibilité.
47
Tableau II-6 :cas d’utilisation modifier carte grise 49
Tableau II-7:cas d’utilisation radier carte grise 51
Tableau II-8:cas d’utilisation ajouter vente locale 53
Tableau II-9:cas d’utilisation annuler vente locale 55
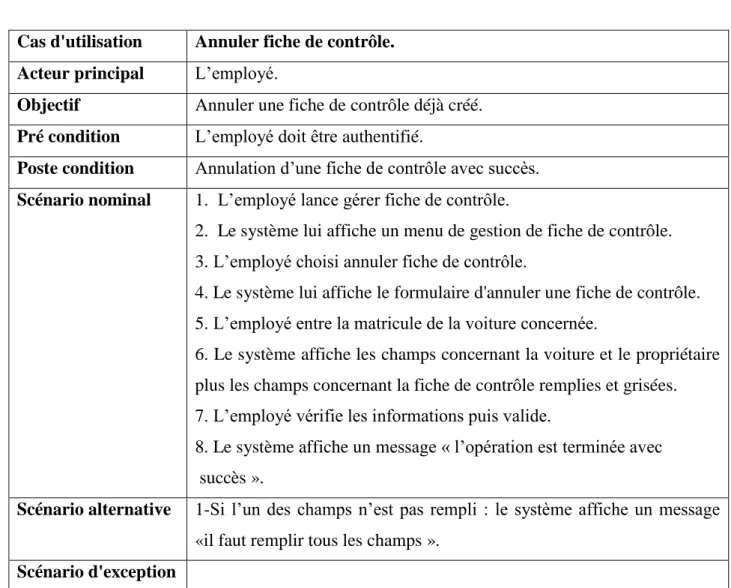
Tableau II-10:cas d’utilisation ajouter fiche de contrôle 57
Tableau II-11:cas d’utilisation modifier fiche de contrôle 59
Tableau II-12:cas d’utilisation annuler fiche de contrôle 61
Tableau II-13:cas d’utilisation établir avis de mutation 63
Tableau II-14:cas d’utilisation rechercher carte grise 65
Tableau II-15:cas d’utilisation s’authentifier 75
Tableau II-16:cas d’utilisation créer un compte 77
Tableau II-17:cas d’utilisation activer/désactiver un
compte 79
Tableau II-18:cas d’utilisation modifier un compte 81
Chapitre IV Tableau IV-1: Les interfaces de notre système
.
110Tableau IV-2: Dictionnaire de données avec Les classes
et les attributs
113
Tableau IV-3: Dictionnaire de données avec Les
opérations 114
Introduction
générale
2
L
e monde de l’informatique évolue très rapidement, alors que son but initial, était d’offrir des services satisfaisants, du point de vue vitesse d’exécution des tâches. Actuellement, de nouveaux besoins sont apparus notamment pour les grandes entreprises, celles-ci souhaitent stocker et échanger des informations qui sont géographiquement éloignées. La collecte et le traitement d’une grande quantité d’informations dispersées est une tâche très délicate. La solution qui s’impose est de distribuer les données et les organiser dans des bases de données sur différents sites de stockage. L’ensemble de ces sites constitue un système de bases de données réparties offrant la possibilité aux utilisateurs de manipuler les différentes bases via un réseau de manière transparente, comme dans une base de données unique.Durant le stage pratique que nous avons effectués dans le cadre du projet de fin d’étude Master 2 qui s’est déroulé au niveau de la Commune de Mila (APC) précisément dans le bureau de la carte grise, nous avons passé un temps considérable au sein de la commune, cherchant et discutant avec le personnel des différents services. Finalement nous avons constaté que le suivi de mouvements des dossiers de la carte grise au niveau de cette commune est une opération réalisée manuellement concernant la vente externe, ce qui exerce une contrainte multiforme sur le fonctionnement de la commune, vu le grand nombre de dossiers à traiter et le temps qui se déroule pour extraire une carte grise d’une voiture vendue hors wilaya.
L'objectif de ce travail est d'essayer de résoudre les problèmes posés par le système actuel de gestion de la carte grise. Pour cela, nous avons conçu et mis en œuvre une base de données répartie sous Oracle assurant une gestion efficace et transparente de la carte grise.
Notre mémoire est structuré en deux parties essentielles. La première partie présente le domaine d’étude qui est en fait une synthèse de la documentation faite autour du domaine d’étude et qui contient des définitions et des concepts fondamentaux des bases de données répartie et leur conception.
La deuxième partie du mémoire est consacrée à l’étude de cas. Elle constitue l’essentiel du travail d’ingénierie des systèmes d’informations que nous avons effectué. Elle s’articule autour des phases essentielles de la méthode 2TUP, et qui sont :
Introduction générale
3
Le chapitre 01 : « L’étude préliminaire» dans cette phase, nous présentons
l’entreprise où nous avons effectué le stage et définissons les notions importantes qui la concernent ensuite nous allons élaborer le cahier des charges qui contient une représentation plus formelles des activités de capture des besoins fonctionnels et de capture des besoins techniques.
Le chapitre 02 : « Capture des besoins » Ce chapitre comporte deux étapes : la
capture des besoins fonctionnels et celle des besoins techniques. La phase de capture des besoins fonctionnels formalise et détaille ce qui a été ébauché au cours de l’étude préliminaire, en donnant une description textuelle et une autre graphique pour chaque cas d’utilisation. La capture des besoins techniques couvre, par complémentarité avec celle des besoins fonctionnels, toutes les contraintes qui ne traitent ni de la description du métier des utilisateurs, ni de la description applicative.
Le chapitre 0 3 : « Analyse » Ce chapitre comporte les étapes de découpage en
catégories, de développement du modèle statique et développement du modèle dynamique. Le découpage en catégories consiste de découper le modèle UML en blocs logiques les plus indépendants possibles. Le développement du modèle statique va nous permettre d’illustrer les principales constructions du diagramme de classes UML durant l’étape d’analyse. Le développement du modèle dynamique va nous permettre d’illustrer comment décrire des scénarios mettant en jeu un ensemble d’objets échangeant des messages.
Le chapitre 04 : « Conception » Ce chapitre comporte la conception générique, la
conception préliminaire et la conception détaillée. Dans la phase de conception préliminaire on effectue la fusion des études fonctionnelles et techniques. La conception détaillée consiste à construire et à documenter précisément les classes, les interfaces, les tables et les méthodes qui constituent le codage de la solution.
Le chapitre 05 : « Implémentation » Dans ce chapitre on donne une description de
l'application, les technologies de programmation utilisées, ainsi que les interfaces graphiques de l'application.
Conclusion générale : La conclusion générale résume les résultats de notre travail, et
Partie I
Chapitre I
Généralités sur les bases de
données réparties
5
1. Introduction
Le développement des techniques informatiques depuis ces dernières années a permis d'appliquer les outils informatiques dans l'organisation des entreprises. Vu, l’immense volume de données manipulées par ces dernières, la puissance des micro-ordinateurs, les performances des réseaux et la baisse considérable des coûts du matériel informatique ont permis l'apparition d'une nouvelle approche afin de remédier aux difficultés causées par la centralisation des données, et ce en répartissant les ressources informatiques tout en préservant leur cohérence.
Les bases de données réparties sont un moyen performant pour diminuer les problèmes provoqués par l'approche centralisée, mais ne restent pas sans failles.
2. Principe des bases de données réparties
Les bases de données distribuées permettent aujourd’hui de muter notre mode de travail traditionnellement centralisé en un mode décentralisé. Cette technologie est certainement l’un des plus importants développements du domaine des systèmes de gestion de bases de données.
2.1 . Définition
Une base de données répartie (BDR) est une base de données dont différentes parties sont stockées sur des sites, généralement géographiquement distants, reliés par un réseau. La réunion de ces parties forme la base de données répartie.
Un système de bases de données réparti ne doit donc en aucun cas être confondu avec un système dans lequel les bases de données sont accessibles à distance (selon le principe client-serveur). Il ne doit pas non plus être confondu avec un système multi base. Dans ce dernier cas, chaque utilisateur accède à différentes bases de données en spécifiant leur nom et adresse, et le système se comporte alors simplement comme un serveur de BD et n'apporte aucune fonctionnalité particulière à la répartition.
Au contraire, un système de bases de données réparti est suffisamment complet pour décharger les utilisateurs de tous les problèmes de concurrence, de fiabilité, d’optimisation de requêtes ou de transaction sur des données gérées par différents SGBD sur plusieurs sites [1].
PARTIE I / CHAPITRE I GENERALITE SUR LES BASE DE DONNEES REPARTIE
6 A Titre d’exemple, une banque peut posséder des agences à Mila et à Constantine. Dans une BD centralisée, le siège social de la banque va gérer tous les comptes des clients et les agences devraient communiquer avec le siège social pour avoir accès aux données.
Dans une BD répartie, les informations sur les comptes sont distribuées dans les agences et celles-ci sont interconnectées (entièrement ou partiellement) afin qu'elles puissent avoir accès aux données externes (Figure 1). Cependant, la répartition de la base de données bancaire est invisible aux agences en tant qu'utilisateurs, et la seule conséquence directe pour elles est que l'accès à certaines données est beaucoup plus rapide et très fiable.
Figure I-1 : Exemple de BD Répartie.
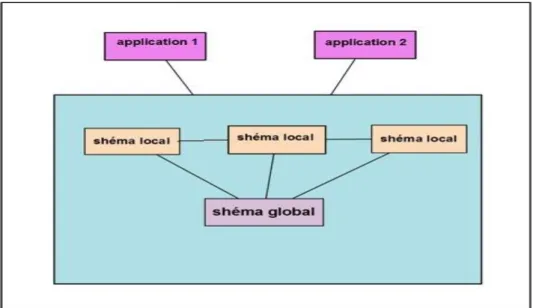
2.2 . Concepts des bases de données réparties
Une BDR reprend les mêmes principes que ceux d'une BD centralisée mais en étendant les techniques existantes ou en proposant certains concepts nouveaux qui sont particuliers à la répartition des données.
2.2.1. Schéma global
Le schéma global permet de définir l’ensemble des types de données de la base. Il ignore les concepts d’implémentation, chaque base locale en implémente une partie.
7
2.2.2. Schéma local
Une base de données locale comporte un schéma géré par le SGBD local.
Dans une BD répartie, chaque base locale rend visible toute ou une partie de la base aux sites clients.
Figure I-2 : Schéma globale et local. 2.2.3. Schéma externe
Le niveau externe décrit les données sous forme de vues, chacune d'elles étant adaptée à une classe particulière d’utilisateurs ; un schéma externe, élaboré à partir du schéma conceptuel, peut naturellement mixer des données stockées dans différentes bases.
2.2.4. Schéma conceptuel
Où les données sont représentées sans prendre en compte les contraintes techniques ou de mise en forme ; toutes les données sont décrites dans ce schéma en utilisant un modèle de données, indépendamment de leur localisation dans le système réparti.
2.2.5. Schéma interne
Le niveau interne global n'a pas d'existence réelle mais fait place à des schémas internes locaux, répartis sur différents sites. Ces schémas correspondent à la description de l'organisation physique de la base, notamment la spécification de la fragmentation des données et la localisation de ces fragments. [2]
PARTIE I / CHAPITRE I GENERALITE SUR LES BASE DE DONNEES REPARTIE
8
3. Avantages
Les bases de données réparties ont une architecture plus adaptée à l’organisation des entreprises décentralisées. [3]
- Plus de fiabilité : les bases de données réparties ont souvent des données répliquées.
La panne d’un site n’est pas très importante pour l’utilisateur, qui s’adressera à un autre site.
- Meilleures performances : réduire le trafic sur le réseau est une possibilité
d’accroître les performances. Le but de la répartition des données est de les rapprocher de l’endroit où elles sont accédées. Répartir une base de données sur plusieurs sites permet de répartir la charge sur les processeurs et sur les entrées/sorties.
- Faciliter l’accroissement : l’accroissement se fait par l’ajout de machines sur le
réseau.
4. Inconvénients de la répartition des données
L'inconvénient majeur de la répartition des données d'une BD entre plusieurs sites est la complexité résultant de leur coordination.
Cette complexité se répartit de la façon suivante : [3] - Le coût de mise au point du logiciel.
- Le nombre d'erreurs logicielles plus important. - Echange de messages.
- Calcul supplémentaire.
- Récupération de système plus complexe après panne (Réintégration des sites ou liaison en pannes).
5. Les objectifs des bases de données réparties
9 • Autonomie locale :
- La base de données locale est complète et autonome (intégrité, sécurité, gestion), elle peut évoluer indépendamment des autres.
• Egalité entre sites :
- Un site en panne ne doit pas empêcher le fonctionnement des autres sites. • Fonctionnement continu :
- La distribution permet la résistance aux fautes et aux pannes. • Localisation transparente :
- Accès uniforme aux données quel que soit leur site de stockage (fragmentation transparente).
- Les données répliquées doivent être maintenues en cohérence. • Requêtes distribuées :
- L’exécution d’une requête peut être répartie (automatiquement) entre plusieurs sites (si les données sont réparties).
• Transactions réparties :
- Le mécanisme de transactions peut être réparti entre plusieurs sites. • Indépendance vis-à-vis du matériel :
- Le SGBD fonctionne sur les différentes plateformes utilisées. • Indépendance vis-à-vis du SE :
PARTIE I / CHAPITRE I GENERALITE SUR LES BASE DE DONNEES REPARTIE
10
6. SGBD Réparti
6.1. Définition d’un Système de gestion de bases de données (Data Base
Management System)
Le SGBD (Système de Gestion des Bases de Données) est l'outil principal de gestion d'une base de données. Il permet d'insérer, de modifier et de rechercher efficacement des données spécifiques dans une grande masse d'informations. C'est une interface entre les utilisateurs et la mémoire de masse. Il facilite ainsi le travail des utilisateurs en leur donnant l'impression que l'information est organisée comme ils le souhaitent. Le SGBD est composé de plusieurs couches :
• Le SGBD externe (user interface handler). Sa tâche est d'interpréter les commandes utilisateurs.
• Le contrôleur sémantique des données (sémantic data controler). Il utilise les différentes contraintes définies sur la base de données afin de vérifier qu'une requête d'un utilisateur peut être effectuée.
• Le processeur de requêtes (query processor). Il détermine une stratégie afin de minimiser le temps d'exécution d'une requête.
• Le gestionnaire de transactions (transaction manager). Il assure la coordination des différentes demandes des utilisateurs.
• Le gestionnaire de reprise (recovery manager). Il s'occupe d'assurer la cohérence des données lorsque des pannes surviennent.
• Le système de gestion des fichiers (run-time support processor). Il gère le stockage physique de l'information. Il est dépendant du matériel utilisé.
Un SGBD réparti doit rendre la répartition des bases de données transparentes aux utilisateurs. La base de données étant répartie, il faut également répartir certaines fonctionnalités du SGBD. Le schéma d'un SGBD réparti est résumé dans la figure suivante [1].
11
Figure I-3: Schéma d'un SGBD
6.2. Rôle d’un SGBD
Le logiciel de gestion d’un système de base de données (SGBD) à pour rôle :
- d’assurer la confidentialité des données : implémentation d’un mécanisme d’authentification par compte avec un mot de passe, attribution de rôles aux utilisateurs permettant d’ouvrir ou de réduire la surface d’exposition des données ;
- d’assurer la cohérence des données : vérifier les connaissances d’unicité (clés primaires) et les contraintes d’intégrité fonctionnelles (s’assurer qu’une clé étrangère référence bien un clé primaire et que la suppression d’une clé primaire ne crée pas d’enregistrement orphelins) ;
- d’assurer la gestion des incidents : le système doit s’assurer que l’échec d’une requête ne remet pas en cause l’intégrité des données. Il doit également pouvoir procéder aux reprises sur incident suite à une panne du serveur hébergeant la base de données, par exemple.[1]
7. Architecture des bases de données réparties
Pour implémenter une base de donnée répartie en est besoin de deux types d’architecture suivant :
7.1. Architecture Client-Serveur
Une application est bâtie selon une architecture client-serveur lorsqu'elle est composée de deux programmes, coopérant l'un avec l'autre à la réalisation d'un même traitement. La première partie, appelée module client, est installée sur le poste de travail alors que la seconde, appelée module serveur, est implantée sur l'ordinateur (ou même des ordinateurs
PARTIE I / CHAPITRE I GENERALITE SUR LES BASE DE DONNEES REPARTIE
12 éventuellement situés dans des lieux géographiques différents) chargé de rendre le service (micro, mini ou grand système).
Figure I-4 : Architecture Client-Serveur
7.2. Architecture Pair-à-Pair (Peer-to-Peer, P2P)
C'est un type de communication pour lequel toutes les machines ont une importance équivalente. Il n'y a pas de machine qui a une importance hiérarchique par rapport aux autres. Dite aussi, l'architecture totalement répartie.
Chacune de ces architectures possède des avantages et des inconvénients. Le Client /Serveur avec sa structure plus hiérarchique est très sensible aux problèmes de panne des serveurs, bloquant ainsi les clients. En revanche, la prise de décision des serveurs est rapide.
Pour l'architecture Peer-To-Peer, comme les machines sont strictement équivalentes, la panne d'une machine peut rarement rendre le système un peu lent. Mais cette architecture engendre énormément de communication pour toute décision.
13
Figure I-5:Architecture serveur-serveur.
8. Conclusion
Ainsi, se termine cette première partie qui été une présentation générale des notions de base de données répartie qui représentent un domaine important pour la gestion de grand volume de données pour les entreprises réparties géographiquement. Dans la suite, nous allons exposer les techniques de conception et de gestion des bases de données réparties.
Chapitre II
Conception d’une base de données
répartie
15
1. Introduction
Comme dans tous les mécanismes, la phase de conception est la plus importante et déterminante dans la mise en place d'une base de données reparties. Le rôle du concepteur est nécessaire de bien comprendre les étapes de conception, de définir les différents fragments de la base et leurs localisations ; d'évaluer les différents coûts de stockage et de transfert, et les priorités à respecter car différentes méthodes de conception existent et chacune d'elles nous offre une approche très différente de l'autre.
2. Conceptions d’une base de données répartie
La conception d’une base de données répartie peut être le résultat de deux approches totalement distinctes, soit le regroupement d’une multitude de bases de données déjà existantes (approche ascendante) soit construite du zéro (approche descendante).
Pour la conception des bases de données réparties il faut prendre des décisions en fonction de critères techniques et organisationnels pour l’objectif de minimiser le nombre de transferts entre sites, les temps de transfert, le volume de données transférées, les temps moyens de traitement des requêtes... etc.
2.1 Méthode de conception
2.1.1 Conception descendante (top down design)
On commence par définir un schéma conceptuel global de la base de données répartie, puis on distribue sur les différents sites en des schémas conceptuels locaux.
La répartition se fait donc en deux étapes, en première étape la fragmentation, et en deuxième étape l’allocation de ces fragments aux sites.
Partie I /Chapitre II CONCEPTION D’UNE BASE DE DONNEES REPARTIE
16
Figure II- 1 : Conception descendante d’une BDR 2.1.2 Conception ascendante (bottom up design)
L’approche se base sur le fait que la répartition est déjà faite, mais il faut réussir à intégrer les différentes BDs existantes en une seule BD globale. En d’autres termes, les schémas conceptuels locaux existent et il faut réussir à les unifier dans un schéma conceptuel global. Si les BDs existent déjà la méthode bottomup est utilisée.[3]
Figure II-2 : Conception ascendante d’une BDR.
3. Techniques utilisés pour la distribution des bases de données
La distribution de la base de données se fait en deux étapes, en première étape la fragmentation, et en deuxième étape l’allocation de ces fragments aux sites avec ou sans réplication. La distribution de la base de données est représentée dans la figure suivante :
17 .
Figure II-3 : Décomposition d’une BDD global
3.1 la fragmentation
3.1.1 Définition
La fragmentation est le processus de décomposition d’une base de données en un ensemble de sous bases de données. Cette décomposition doit être sans perte d’information.
L’utilisation de petits fragments permet de faire tourner plus de processus simultanément, ce qui entraîne une meilleure utilisation des capacités du réseau d’ordinateurs.
Elle se base sur les règles suivantes :
• La complétude : Pour toute donnée d’une relation R, il existe un fragment Ri de la relation R qui possède cette donnée.
• La reconstruction : Pour toute relation décomposée en un ensemble de fragments Ri, il existe une opération de reconstruction.
• Disjonction : une donnée n'est présente que dans un seul fragment, sauf dans le cas de la fragmentation verticale pour la clé primaire qui doit être présente dans l'ensemble des fragments issus d'une relation. [3]
3.1.2 Objectif de la fragmentation
Les applications ne travaillent que sur des sous-ensembles des relations. Une distribution complète des relations générerait soit beaucoup de trafic, soit une réplication des données avec tous
Partie I /Chapitre II CONCEPTION D’UNE BASE DE DONNEES REPARTIE
18 les problèmes que cela occasionne : problèmes de mises à jour, problèmes de stockage. Il est donc préférable de mieux distribuer ces sous-ensembles.
L'utilisation de petits fragments permet de faire tourner plus de processus simultanément, ce qui entraîne une meilleure utilisation des capacités du réseau d'ordinateurs. [2]
3.1.3 Les problèmes de la fragmentation
La fragmentation peut être coûteuse s'il existe des applications qui possèdent des besoins opposés. On est en quelque sorte dans le cas d'une exclusion mutuelle qui empêche une fragmentation correcte.
Par ailleurs, la vérification des dépendances sur différents sites peut être une opération très longue. [2]
3.1.4 Types de fragmentation
Il existe 3 types de fragmentations :
a. la fragmentation horizontale
La relation est divisée en plusieurs sous-relations contenant chacune un sous-ensemble des tuples (lignes) de la relation.
19
b. La fragmentation verticale
La relation est divisée en plusieurs sous-relations contenant chacune un sous-ensemble des attributs (colonnes) de la relation .La fragmentation horizontale a tout son intérêt pour une société dispersée aux quatre coins du globe et qui maintient une relation contenant ses employées. Cette relation logique, peut-être fragmentée horizontalement en plusieurs groupes contenant chaque fois les employés selon leur localisation.
La fragmentation verticale est plus complexe et moins intuitive. Les sous-relations ne contiennent pas tous les attributs mais tous les tuples. Un peu comme une vue permet de cacher les attributs inutiles selon le contexte, la fragmentation verticale peut-être utile d’un point de vue hiérarchique.[1]
Figure II-5: Fragmentation verticale c. La fragmentation mixte
Elle résulte de l'application successive d'opérations de fragmentation horizontale et verticale sur une relation globale. [2]
Partie I /Chapitre II CONCEPTION D’UNE BASE DE DONNEES REPARTIE
20
3.2 Allocation des fragments aux sites
L’affectation des fragments sur les sites est décidée en fonction des requêtes qui ont servi à la fragmentation. Le but est de placer les fragments sur les sites où ils sont le plus utilisés, et ce pour minimiser les transferts de données entre les sites.
L’allocation peut se faire avec réplication ou sans réplication. Sachant que la réplication favorise les performances des requêtes et la disponibilité des données, mais est coûteuse en considérant les mises à jour des fragments répliquas.[3]
4. La réplication
4.1 Définition
La réplication consiste à copier les informations d'une base de données sur une autre. Elle peut être accompagnée d'une transformation des données sources, voir souvent d'une agrégation. Dans tous les cas, il s'agit d'une redondance d'information.
L'objectif principal de la réplication est de faciliter l'accès aux données en augmentant la disponibilité. Soit parce que les données sont copiées sur différents sites permettant de répartir les requêtes, soit parce qu'un site peut prendre la relève lorsque le serveur principal s'écroule. Une autre application tout aussi importante est l'amélioration des performances des requêtes sur les données locales, et ceci permet d'éviter les transferts de données et d'accroître la résistance aux pannes.[2]
21
4.2 Principe
Le principe de la réplication, qui met en jeu au minimum deux SGBDs, est assez simple et se déroule en trois étapes : [2]
1. La base maître reçoit un ordre de mise à jour (INSERT, UPDATE ou DELETE).
2. Les modifications faites sur les données sont détectées et stockées dans un fichier ou une file d'attente en vue de leur propagation.
3. Le processus de réplication prend en charge la propagation des modifications à faire sur une seconde base dite esclave. Il peut bien entendu y avoir plus d'une base esclave.
4.3 Les Types de réplication
4.3.1 La réplication synchrone
Aussi appelée « Réplication en temps réel » La synchronisation est effectuée en temps réel puisque chaque requête est déployée sur l’ensemble des bases de données avant la validation (commit) de la requête sur le serveur où la requête est exécutée. Ce type de réplication assure un haut degré d’intégrité des données mais requiert une disponibilité permanente des serveurs et de la bande passante. Ce type de réplication, fortement dépendant des pannes des systèmes, nécessite de gérer des transactions multi sites coûteuses en ressources. La réplication synchrone est utilisée dans le cas des compagnies aériennes, des banques . . . etc.
Deux types de réplication synchrone :La réplication synchrone asymétrique et la réplication Synchrone symétrique.
a. Réplication synchrone asymétrique
Elle utilise un site primaire (maitre) qui pousse les mises à jour en temps réel vers un ou plusieurs sites secondaires. La table répliquée est immédiatement mise à jour pour chaque modification par utilisation de trigger sur la table maître.
Partie I /Chapitre II CONCEPTION D’UNE BASE DE DONNEES REPARTIE
22
Figure II-8 : Réplication synchrone asymétrique b. La réplication synchrone symétrique
Lors de la réplication synchrone symétrique, il n'y a pas de table maître. L'utilisation de trigger sur chaque table doit différencier une mise à jour client à répercuter d'une mise à jour par réplication. Cette technique nécessite l'utilisation de jeton.
Figure II-9 : Réplication synchrone symétrique 4.3.2 La réplication asynchrone
La réplication asynchrone stocke les opérations intervenues sur une base de données dans une fille d’attente pour les propager plus tard à l’aide d’un processus de synchronisation. Ce type de réplication est plus flexible que la réplication synchrone. Il permet en effet de définir les intervalles de synchronisation, ce qui permet à un site de fonctionner même si un site de réplication n’est pas accessible. Si le site distant est victime d’une panne, l’absence de synchronisation n’empêche pas la consistance de la base maîtresse.
23 La réplication asynchrone est appropriée pour une équipe de développeurs travaillant à distance sur une application.
Il existe deux types de réplication asynchrone :La réplication asynchrone asymétrique et la réplication asynchrone symétrique.
a. La réplication asynchrone asymétrique
Elle pousse les mises à jour en temps différé via une file persistante. Les mises à jour seront exécutées ultérieurement, à partir d'un déclencheur externe, l'horloge par exemple. [2]
Figure II-10 : Réplication asynchrone asymétrique b. La réplication asynchrone symétrique
Dans ce cas, la mise à jour des tables répliquées est différée. Cette technique risque de provoquer des incohérences de données.
Partie I /Chapitre II CONCEPTION D’UNE BASE DE DONNEES REPARTIE
24 Il est bien évident que la réplication synchrone nécessite des moyens beaucoup plus coûteux que l’asynchrone, en raison principalement de la bande passante nécessaire pour assurer un échange parfait entre les différents serveurs d’un réseau. Les solutions asynchrones sont donc privilégiées par les entreprises dont l’exigence en "temps réel" et en continuité de service est réduite.
4.4 Les avantages de la réplication
Les avantages de la réplication sont assez nombreux, selon le type on trouve :
-Allégement du trafic réseau en répartissant la charge sur divers sites. Par conséquent, rapidité des accès aux données.
- Amélioration des performances des requêtes.
- Résistance aux pannes par l'augmentation de la disponibilité des données.
5. Gestion des Bases de données réparties
5.1 Mise à jour des BDDR
La principale difficulté réside dans le fait qu'une mise à jour dans une relation du schéma global se traduit par plusieurs mises à jour dans différents fragments.
Il faut donc identifier les fragments concernés par l'opération de mise à jour, puis décomposer en conséquence l'opération en un ensemble d'opération de mise à jour sur ces fragments.
- Insertion
Retrouver le fragment horizontal concerné en utilisant les conditions qui définissent les fragments horizontaux, puis insertion du tuple dans tous les fragments verticaux correspondants. - Suppression
Rechercher le tuple dans les fragments qui sont susceptibles de contenir le tuple concerné, et supprimer les valeurs d'attribut du tuple dans tous les fragments verticaux.
25 - Modification
Rechercher les tuples, les modifier et les déplacer vers les bons fragments si nécessaire. [1]
6. Conclusion
Dans ce chapitre, nous avons présenté les principes de la répartition des données. Cette répartition peut se faire selon différents scénarios choisis par le concepteur, tout en prenant en compte les restrictions et les obligations de conception.
Nous avons vu également, comment gérer une base de données répartie avec les principes de réplication symétrique et asymétrique.
Partie II
Chapitre I
PARTIE I I/ CHAPITRE I ETUDE PRELIMINAIRE
27
1. Introduction
Dans ce chapitre nous allons déterminer la phase d’étude préliminaire qui permet de recueillir les informations initiales sur le système. Il s’agit dans cette phase de définir le contour du système, les différents acteurs, ainsi que les messages d’interaction avec le système.
L’étude préliminaire est la toute première étape du processus 2TUP. Elle consiste à effectuer un premier repérage des besoins fonctionnels et opérationnels, en utilisant principalement le texte, ou diagrammes très simples. Elle prépare les activités plus formelles de capture des besoins fonctionnels et de capture technique.
2. Élaboration du cahier de charge
2.1. Présentation de l’organisme d’accueil
La commune est la collectivité territoriale de base de l'État algérien, à la fois collectivité disposant de la personnalité morale, dotée de ses propres organes, délibératif et exécutif, et plus petite subdivision administrative de l'organisation territoriale de l'Algérie. Cette double compétence de la commune est exercée par le président de l'Assemblée Populaire Communale (A.P.C), qui est conjointement le représentant de la commune et le représentant de l'État au niveau communal. Mila la nouvelle ville a été fondée en 1877 et transformée en une commune par la publication 23/11/1890 La commune de Mila est l’un des Trente-deux commune de la wilaya algérienne de Mila.
La gestion administrative de la commune de Mila se répartie plusieurs services : ➢ Service d’administration et des moyens généraux.
➢ Service des affaires sociales, culturelles et sportives ➢ Service d’urbanisme et construction et équipement. ➢ Service de la route et réseaux divers biens.
28 Notre projet est à réaliser au niveau de service de réglementation générale, en particulierdans le bureau de carte grise. La figure suivante illustre l’organigramme de différents services de la commune du Mila:[5]
Figure I-1: L’organigramme de différents services de la commune du Mila
2.2. Présentation du projet
Notre projet consiste à un système d'information qui se base sur une base de données répartie pour la gestion des cartes grises au niveau de la commune de Mila.
Principalement les échanges d’informations est entre les différents systèmes de chaque wilaya lorsqu’il s’agit d’une vente externe et aussi avec le système central, lorsqu’il s’agit d’une mise à jour d’une carte grise ou bien une vente locale et aussi une nouvelle voiture.
Présentation du l’assemblée populaire et communale
Sécurité général Service d’administration et moyens généraux Service des affaire scolaire et culture et sportifs Service de réglementation générale Service d’urbanisme et construction et équipement Service de la route et réseau divers biens Bureau des élection et le service national Bureau d’états civile Bureau carte grise Bureau contentieux et affaire législatives
PARTIE I I/ CHAPITRE I ETUDE PRELIMINAIRE
29 Pour ce faire, il s'avère nécessaire de présenter l'organisme d'accueil qui est la commune de Mila afin de comprendre les activités principales qu'il exerce.
2.3. Problématique
Notre stage pratique a porté sur le suivie de la gestion de lacarte grise au sein du bureau du carte grise de la commune du Mila.
Malgré la présence d’un système de gestion de la carte grise, certains problèmes restent toujours posés et peuvent être résumés comme suit :
✓ Manque d’un réseau national qui relie les différents systèmes de chaque wilaya et aussi avec le système central, donc pour effectuer une vente externe et extraire la nouvelle carte grise cela peut prendre une longue durée.
Notre travail intervenant dans le domaine de la gestion de la carte grise qui consiste à la mise en place d'une application base de données pour la distribution des tâches relative à la gestion de la carte grise de manière à rendre flexibles et souples l'accès et la manipulation des informations.
2.4. Objectifs de nouveau système
La gestion de la carte grise est une tâche très difficile plus qu'elle est trop compliquée et demande beaucoup du temps c'est dans ce sens qu'on présente notre sujet qui consiste à réaliser une application distribué fiable et robuste qui élimine la majorité des problèmes poser dans l’ancien système. Pour répondre aux besoins des citoyens ainsi que les employés du bureau pour la bonne gestion du ces tâches.
En peut résumer les objectifs de notre application grâce à ces points : ✓ Faciliter la communication entre les serveurs de chaque wilaya.
✓ Lorsqu’un serveur local et en panne les opérations effectuer sur ce serveur vont être effectué automatiquement sur le serveur central.
✓ Automatiser la vente externe d’une voiture par l’interconnexion entre les différentes applications de chaque wilaya.
30
2.5. Grands choix techniques
Pour réaliser ce projet nous allons utiliser une approche itérative et incrémentale, fondée sur le processus en Y.
Nous avons choisi aussi un certain nombre de techniques –clés.Ces techniquesclés sont principalement :
✓ Le langage de modélisation UML.
✓ Le processus de développement en Y (2TUP).
✓ L’environnement de développement NetBeans . ✓ Le langage de programmation java.
✓ Le SGBDR ORACLE .
2.6. Recueil des besoins fonctionnel
Un premier tour d’horizon des besoins exprimés par les employés de la carte grise permetd’établir un cahier des charges préliminaire ; durant notre stage pratique on a constaté qu’il y a différents cas pour extraire la carte d’immatriculions des véhicules :[5]
➢ Cas de ré-immatriculation du véhicule dans la même wilaya : le propriétaire doit disposer le dossier suivant :
- Formulaire de demande d'immatriculation du véhicule signé et légalisé.
- Carte grise barrée du véhicule. - Acte de vente signé et légalisé. - Timbre Fiscal.
- Quittance de paiement de la taxe de transaction pour les véhicules concernés.
- Extrait de naissance délivré sur la base du livret de famille. - Fiche de résidence.
- Photocopie légalisée de la Carte Nationale d'Identité en cours de validité.
PARTIE I I/ CHAPITRE I ETUDE PRELIMINAIRE
31 - Photocopie légalisée du statut (si l’acheteur est une personne
morale).
➢ Cas de ré-immatriculation du véhicule transféré dans une autre wilaya : le propriétaire doit disposer le dossier suivant :
- Formulaire de demande d'immatriculation du véhicule signé et légalisé.
- Carte grise barrée du véhicule. - Acte de vente signé et légalisé.
- Fiche de contrôle visée par l’ingénieur des Mines de la Wilaya d’accueil.
- Timbre Fiscal.
- Quittance de paiement de la taxe de transaction pour les véhicules concernés.
- Extrait de naissance délivré sur la base du livret de famille. - Fiche de résidence.
- Photocopie légalisée de la Carte Nationale d'Identité en cours de validité.
- Photocopie légalisée du statut (si l’acheteur est une personne morale).
➢ Cas d’immatriculation de véhicule neuf :
- Formulaire de demande d'immatriculation du véhicule signé et légalisé.
- Carte d'immatriculation provisoire (carte jaune). - Certificat de conformité du véhicule.
- Attestation de vente délivrée par le concessionnaire. - Facture d'achat du véhicule.
- Timbre Fiscal.
- Quittance de paiement de la taxe de transaction pour les véhicules concernés.
- Extrait de naissance délivré sur la base du livret de famille. - Fiche de résidence.
32 - Photocopie légalisée de la Carte Nationale d'Identité en cours de
validité.
- Photocopie légalisée du statut (si l’acheteur est une personne morale).
2.7. Recueil des besoins opérationnels
Sécurité : Chaque utilisateur de l’application doit s’authentifier par un nom d’utilisateur et un
mot de passe, pour qu’il puisse utiliser le système et accéder à l’application.
Temps de réponse : Doit être acceptable.
Interface graphique : Doit être simple à utiliser et convivial.
3. Description de contexte du système
3.1. Identification des acteurs
Les acteurs sont des entités externes qui interagissent avec le système, comme une personne humaine, un autre système ou un robot. Dans notre application on distingue deux catégories d’acteurs :
Administrateur : est le responsable de l’application, il a le droit d’ajouter un compte,
activé/désactivé un compte et modifier un compte.
Agent employée : le responsable à gérer les opérations concernant la carte grise.
3.2. Identification des messages
On va détailler les différents messages échangés entre le système et l’utilisateur. ➢ Les messages émis par le système sont :
1. Les informations d’authentification. 2. Les informations d’une carte grise.
3. Les informations du gage /opposition/ incessibilité. 4. Les informations du gage /opposition/ incessibilité. 5. Les informations du duplicata.
PARTIE I I/ CHAPITRE I ETUDE PRELIMINAIRE
33 6. Les informations de radiation carte grise.
7. Les informations de la vente locale.
8. Les informations d’une fiche de confirmation. 9. Les informations d’un avis de mutation. 10. Les informations de recherche une carte grise. 11. Les informations d’un employé.
➢ Les messages reçus par le système sont : 1. La confirmation d’authentification. 2. La confirmation d’ajout de la carte grise.
3. La confirmation de modification de la carte grise. 4. La confirmation de radier carte grise.
5. La confirmation d’ajout vente locale. 6. La confirmation d’annuler vente locale. 7. La confirmation d’ajout fiche de contrôle. 8. La confirmation de modifier fiche de contrôle. 9. La confirmation d’annuler fiche de contrôle. 10. La confirmation d’ajout de fiche de confirmation. 11. La confirmation d’ajout l’avis de mutation.
3.3. La méthode de conception
Notre système consiste à réaliser une application distribué pour la gestion de la carte grise, chaque wilaya possède son propre serveur qui contient tous les mis à jour de la gestion de la carte grise ,le serveur local de chaque wilaya correspond au schéma local de notre base de donnée ,à partir de ses schéma locaux on va construire le schéma global de la base de
34 donnée donc notre conception va êtreest une conception ascendante ,on obtient le schéma global par la réplication des bases de données locales de chaque wilaya .
3.4. Modélisation du contexte
Après les étapes précédentes, et à partir des informations obtenues, nous allons modéliser le contexte de notre application. Ceci va nous permettre dans un premier temps, de définir le rôle de chaque acteur dans le système.
3.3.1. Diagramme de contexte dynamique
Figure I-2: Le diagramme de contexte dynamique du système 3.3.2. Description détaillée des messages
1 : l’administrateur système
• Les informations concernant le compte d’authentification (login et mot de passe). • La mise à jour des informations des comptes (active/désactive, ajouter).
Tableau I-1: liste des messages d’administrateur
2 :système
l’administrateur
• Confirmation des informations d’authentification. • Confirmation des mises à jour concernant les comptes.
Tableau I-2: liste des messages du système vers l’administrateur
:système
:Administrateur : employé 1 2 3 4PARTIE I I/ CHAPITRE I ETUDE PRELIMINAIRE
35
Tableau I-3: liste des messages d’employé
4 : système l’employé
• Le formulaire d’authentification.
• Les formulaires de gestion de la carte grise.
• Les formulaires concernant la vente locale et externe.
Tableau I-4: liste des messages du système vert l’employé
4. Conclusion
Après avoir dégagé les besoins fonctionnels et opérationnels et tous les critères qu’on doit prendre en considération, dans le prochain chapitre nous allons poursuivre la formalisation de ces besoins.
3 :employé
système
•
Les informations d’authentification.• Les informations de la gestion de la carte grise. • Les informations concernant la vente locale. • Les informations concernant la vente externe.
CHAPITRE II
CAPTURE DES BESOINS
FONCTIONNELS ET
Partie II/Chapitre II Capture des besoins fonctionnels et technique
38
1. Introduction
Ce chapitre vient pour compléter l’étude fonctionnelle et technique ébauchée durant l’étude préliminaire dans le chapitre précédent. L’objectif de la capture des besoins consiste à déterminer ce que le système doit faire, c.à.d. le « quoi » a fourni aux développeurs une meilleure compréhension des fonctionnalités du système qu’ils doivent développer, elle comporte deux étapes : la capture des besoins fonctionnels et la capture des besoins techniques.
2. Capture des besoins fonctionnels
Elle représente un point de vue « fonctionnel » de l’architecture système. Et pour ce faire nous utiliserons la notion d’Use Case. Chaque Use Case sera identifié, décrit, et organisé, classé en fonction de son importance dans le projet.
La capture s’effectue sur plusieurs étapes
➢ Identification des cas d’utilisation.
➢ Le diagramme de cas d’utilisation pour les besoins fonctionnels. ➢ Description préliminaire les différents cas d’utilisation.
➢ Description détaillée des différents cas d’utilisation. ➢ Identifier les classes candidates du modèle d’analyse.
2.1. Déterminer les cas d’utilisations
➢ Définition
Un cas d’utilisation « use case » permet de décrire ce que le futur système devra faire, sans spécifier comment il le réalisera. Il permet d’exprimer le besoin des utilisateurs d’un système, il est donc une vision orientée utilisateur.