Predicate-based indexing for desktop search
24
0
0
Texte intégral
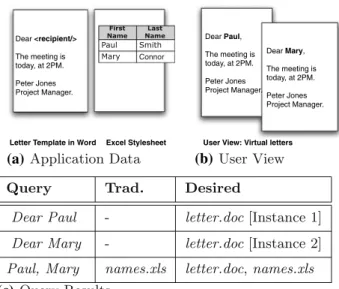
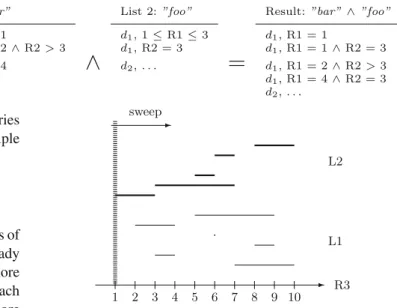
Figure



+7





Documents relatifs