Continuation of Nesterov’s Smoothing for Regression with Structured Sparsity in High-Dimensional Neuroimaging
Texte intégral
Figure



Documents relatifs
The purpose of the next two sections is to investigate whether the dimensionality of the models, which is freely available in general, can be used for building a computationally
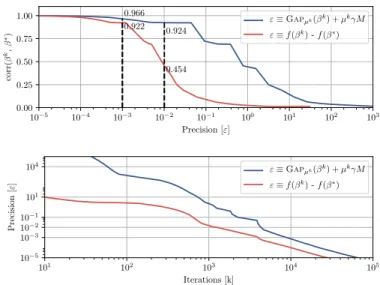
Figure 2(c) compares model complexity mea- sured by the number of parameters for weighted models using structured penalties.. The ℓ T 2 penalty is applied on trie-structured
The corresponding penalty was first used by Zhao, Rocha and Yu (2009); one of it simplest instance in the context of regression is the sparse group Lasso (Sprechmann et al.,
This is also the case for algorithms designed for classical multiple kernel learning when the regularizer is the squared norm [111, 129, 132]; these methods are therefore not
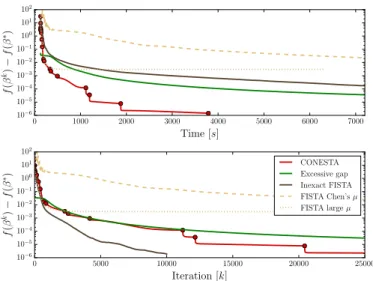
We consider a structured sparse decomposition problem with overlapping groups of ℓ ∞ -norms, and compare the proximal gradient algorithm FISTA (Beck and Teboulle, 2009) with
Abstract: For the last three decades, the advent of technologies for massive data collection have brought deep changes in many scientific fields. What was first seen as a
Keywords and phrases: Gaussian graphical model, two-sample hypothesis testing, high-dimensional statistics, multiple testing, adaptive testing, minimax hypothesis testing,
The most studied techniques for high-dimensional regression under the sparsity scenario are the Lasso, the Dantzig selector, see, e.g., Cand`es and Tao (2007), Bickel, Ritov
