Apprentissage séquentiel budgétisé pour la classification extrême et la découverte de hiérarchie en apprentissage par renforcement
Texte intégral
Figure
![Figure 2.2: Hierarchical-DQN ; figure tirée de [Kul+16]. Des réseaux neuronaux profonds sont utilisés pour modéliser deux fonctions de valeur : Q 2 correspond à la politique du contrôleur haut-niveau (meta controler) qui permet de choisir un but (intermédi](https://thumb-eu.123doks.com/thumbv2/123doknet/14714818.568515/31.892.158.682.247.805/hierarchical-neuronaux-utilisés-modéliser-fonctions-correspond-contrôleur-intermédi.webp)
![Figure 2.3: Achitecture Option-Critic ; figure tirée de [BP15b]. La politique π Ω per- per-met de choisir une nouvelle option ω qui choisit les actions à effectuer dans l’environnement](https://thumb-eu.123doks.com/thumbv2/123doknet/14714818.568515/32.892.259.689.346.757/figure-achitecture-option-critic-politique-nouvelle-effectuer-environnement.webp)
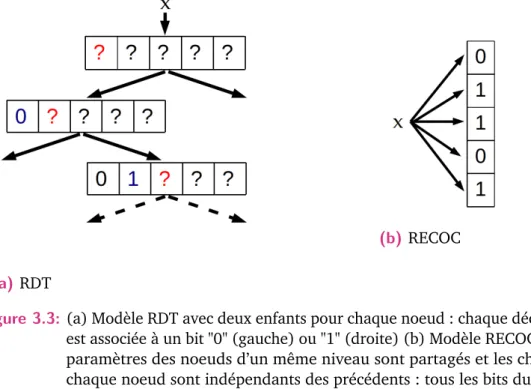

![Figure 4.8: Architecture Hierarchical Multiscale Recurrent Neural Network (HM- (HM-RNN), tirée de [Chu+16]](https://thumb-eu.123doks.com/thumbv2/123doknet/14714818.568515/77.892.195.647.102.363/figure-architecture-hierarchical-multiscale-recurrent-neural-network-tirée.webp)
Outline
Documents relatifs
À chaque gare centrale sont rattachées des gares satellites et on peut aussi aller directement d’une gare centrale à une de ses gares satellites rattachées.. Par contre, on ne peut
Dans de nombreuses situations, le résultat d’une action ne peut être prédit avec certitude. Par
I Arbre peu performant pour la prédiction Le bruit dans les exemples peut conduire à un surajustement de l ’arbre. I E15= (Soleil,Chaude,Normale,
– ε-Greedy: at each time step, explore uniformly over actions with probability ε or take the action with minimal average loss otherwise.. – Thomson-sampling: choose the action
L’insertion et la suppression utilisent la rotation ` a gauche et ` a droite d’un arbre lorsqu’il est trop d´ es´ equilibr´ e :.
Mike Assistant Prof 3 no.
Variantes de la base d’apprentissage obtenues par tirages aléatoires avec remise depuis la base initiale. (sorte de « bootstrap » duplication/disparition aléatoires de
{ Apprentissage automatique et évolution artificielle, revue extraction des connaissances et apprentissage, Volume1, n°3, éditions hermes, 2001. { Algorithmes d ’apprentissages
