HES-SO Valais-Wallis • rue de la Plaine 2 • 3960 Sierre
Travail de Bachelor 2018
Algorithms-to-Data infrastructure based on
Docker swarm mode
Étudiant-e : Lionel Engel
Professeur : Dr. Henning Müller
Déposé le : 3 décembre 2018
Source de l’illustration de titre
Capture d’écran d’un schéma réalisé dans Microsoft Visio par l’auteur de ce document le 08.11.2018
Résumé
L’objectif de ce travail de Bachelor est de produire une analyse de la technologie Docker et d’apporter des fonctionnalités et des informations complémentaires dans le cadre d’un projet d’analyses médicales mené à l’Institut Informatique de Gestion (IIG) de la HES-SO Valais. Ce projet vise à améliorer l’efficacité des analyses de volumes considérables de données en milieux hospitaliers.
Pour réaliser ce but, un état de l’art de l’outil Docker, de son mode Swarm et des risques lors de l’exécution de code étranger est effectué, ce qui permet notamment de comprendre le fonctionnement et de ressortir des impacts potentiels liés à l’infrastructure interne et aux données sensibles.
Nous continuons ensuite par l’installation de Docker, la réalisation d’un service Web utilisant un client Docker et l’utilisation de quotas de RAM et CPU, la définition d’un réseau permettant d’isoler les exécutions de codes et une interface Web permet une démonstration du développement effectué (cf. cahier des charges en annexe).
Pour finir, nous établissons une conclusion avec les améliorations futures de ce travail. Mots clés : Docker, containerization, mode Swarm, analyse de risques
Table des matières
Résumé... 3
Liste des figures ... 9
Liste des tableaux ... 11
Avant-propos ...12
Remerciements ...13
Liste des abréviations ...14
Glossaire ...15
1. Introduction ...16
1.1. Contexte ...16
1.2. Objectifs / étapes ...17
2. Etat de l’art de Docker ...18
2.1. Principes de Docker ...18
2.1.1. Containers ...18
2.1.1.1. Machines virtuelles vs. containers ...18
2.1.2. Docker Images ...20
2.1.2.1. Fonctionnement ...20
2.1.3. Services Docker ...22
2.1.4. Docker Engine ...22
2.1.5. Registres d’images Docker ...22
2.2. Versions de Docker ...22
2.2.1. Community Edition...23
2.2.2. Enterprise Edition ...24
2.3. Outils et méthodes Docker ...25
2.3.1. Docker Swarm ...25
2.3.2. Docker Compose ...26
2.3.3. Docker Hub ...27
2.3.5. Docker Cloud ...29
2.3.6. Docker Machine ...29
2.3.7. Docker Bench Security app ...30
2.4. Standards / best practices ...30
2.4.1. Taille des images Docker ...30
2.4.2. Persistance des données ...31
2.4.3. Fichier .dockerignore ...31
2.4.4. Sécurité ...32
3. Analyse des risques ...33
3.1. Infrastructure ...33
3.1.1. Surcharge de ressources ...33
3.1.2. Utilisation du stockage ...33
3.1.3. Panne / disfonctionnement ...34
3.2. Sécurité ...34
3.2.1. Menaces / failles possibles ...34
3.2.1.1. Kernel et hôte Docker ...34
3.2.1.2. Authenticité des images ...35
3.2.1.3. Container breakout ...35
3.2.1.4. Surcharge des ressources (déni de service) ...35
3.2.1.5. Man-in-the-Middle ...36
3.2.1.6. ARP Spoofing ...36
3.2.1.7. Crédenciales et Docker secrets ...36
3.2.1.8. Modification de données ...37
3.2.1.9. Accès à des volumes de données non-autorisés ...37
3.2.1.10. Fuite de données vers l’extérieur ...37
3.2.1.11. Accès non-autorisé aux résultats d’analyse ...37
3.2.2. Solutions d’analyse / protection ...38
3.2.2.1. Docker bench security ...38
3.2.2.3. Sysdig et Sysdig Inspect ...39
3.2.2.4. Anchore Engine ...39
3.3. Implications légales ...40
3.3.1. Principes de base de protection des données...40
3.3.1.1. Finalité ...40
3.3.1.2. Proportionnalité et pertinence des données ...40
3.3.1.3. Conservation des données ...40
3.3.1.4. Sécurité et confidentialité ...41
3.3.1.5. Transparence ...41
3.3.1.6. Respect du droit des personnes...41
3.3.2. Lois concernées ...41
3.3.3. Anonymisation et pseudonymisation ...42
3.3.4. Conditions d’utilisation des données ...42
3.3.5. Fuite ou modification non-autorisée de données ...43
3.3.6. Sanctions en cas de non-respect des lois ...43
4. Choix effectués ...44 4.1. Méthodologie / planification ...44 4.2. Technique (matériel) ...44 4.3. Technique (logiciel) ...45 5. Résultats ...46 5.1. Architecture générale ...46
5.2. Installation Docker et mode Swarm ...46
5.3. Exécution de conteneurs (Service web) ...48
5.3.1. Création de base d’un service Docker ...49
5.4. Quotas RAM ...52
5.4.1. Définition d’un quota dans le service Web ...53
5.4.2. Test d’exécution avec limite RAM ...53
5.4.2.1. Fonctionnement normal ...53
5.5. Quotas CPU ...56
5.5.1. CFS scheduler ...56
5.5.2. Real-time ...57
5.5.3. Définition d’un quota CPU (service Web) ...57
5.5.4. Tests d’exécution (CFS scheduler) ...58
5.5.4.1. Fonctionnement normal ...58
5.5.4.2. Stress test ...58
5.5.5. Conclusion ...59
5.6. Réseau Docker pour conteneurs ...60
5.6.1. Définitions ...60
5.6.2. Création d’un nouveau réseau ...61
5.6.3. Définition du réseau à utiliser (service Web) ...61
5.6.4. Tests de comparaison ...62
5.6.5. Conclusion ...64
5.7. Scheduler / queue Docker swarm ...65
5.7.1. Processus de gestion des services et tâches...65
5.7.2. Filtres ...66
5.7.3. Stratégies ...66
5.7.4. Conclusion ...67
5.8. Interface web cliente ...68
5.9. Registre Docker interne privé...69
6. Conclusion ...71
6.1. Bilan technique ...71
6.2. Améliorations futures / recommandations ...71
6.3. Problèmes rencontrés ...72
6.4. Respect du cahier des charges ...72
6.5. Conclusion personnelle...73
Références ...74
Annexe II : Product backlog ...79
Annexe III : PV séance kick-off 02.10.2018 ...81
Annexe IV : PV séance 2 10.10.2018 ...83
Annexe V : PV séance 3 17.10.2018 ...84
Annexe VI : PV séance 4 24.10.2018 ...85
Annexe VII : PV séance 5 31.10.2018 ...86
Annexe VIII : PV séance 6 06.11.2018 ...87
Annexe IX : PV séance 7 13.11.2018 ...88
Annexe X : PV séance 8 21.11.2018 ...89
Annexe XI : Liste de commandes Dockerfile ...90
Liste des figures
Figure 1 Architecture du système à implémenter ...16
Figure 2 Cargo containers ...18
Figure 3 Comparaison VM et conteneurs ...19
Figure 4 Exemple Dockerfile ...21
Figure 5 Etapes création de conteneur (couches) ...21
Figure 6 Exemple affichage de couches pour une image ...21
Figure 7 Plateformes supportées Docker CE ...23
Figure 8 Plateformes supportées Docker EE ...24
Figure 9 Swarm mode ...25
Figure 10 Exemple de fichier Docker Compose ...26
Figure 11 Page accueil Docker Hub ...27
Figure 12 Exemple images officielles Docker Hub ...28
Figure 13 Affichage organisation sur Docker Hub ...28
Figure 14 Docker Store ...29
Figure 15 Combiner les instructions RUN ...31
Figure 16 Début du script Docker-bench-security ...38
Figure 17 Architecture générale de ce projet ...46
Figure 18 Commande pour ajout nœud Swarm ...47
Figure 19 Affichage infos Docker ...47
Figure 20 Affichage des nœuds du Swarm ...47
Figure 21 Génération d'un modèle Spring Boot App ...48
Figure 22 Création de la fonction serviceCreate (dans service Web) ...49
Figure 23 Spécificités liées au conteneur (dans service Web) ...50
Figure 24 Spécificités liées à la tâche (dans service Web) ...51
Figure 25 Spécificités et lancement du service Docker (dans service Web) ...51
Figure 26 Spécification de limite mémoire (dans service Web) ...53
Figure 27 Exécution image Docker sans limite RAM ...53
Figure 28 Exécution image Docker avec limite RAM ...54
Figure 29 Service Docker avec sa tâche, utilisation RAM et ses processus ...55
Figure 30 Résultat stress test limite RAM ...56
Figure 31 Spécification de limite CPU (dans service Web) ...57
Figure 32 Propriétés conteneur: CPUQuota et CPUPeriod ...58
Figure 33 Résultat stress test limite CPU ...59
Figure 35 Définition réseau Docker à utiliser (dans service Web) ...61
Figure 36 Erreur: uniquement réseau de scope Swarm pour services Docker ...63
Figure 37 Traitement d'un service (scheduler Swarm) ...65
Figure 38 Création d'instance (Interface web cliente) ...68
Figure 39 Liste des instances (Interface web cliente) ...68
Figure 40 Fichier Docker compose pour création registre interne ...70
Figure 41 Login sur registre Docker interne ...70
Liste des tableaux
Tableau 1 Caractéristiques VM vs. conteneur ...20 Tableau 2 Tests comparaison réseaux Docker ...63
Avant-propos
Ce travail est proposé par mon professeur responsable et il fait partie d’un projet en cours d’implémentation par une équipe de l’IIG.
Le but est donc de se baser sur l’existant et fournir des analyses complémentaires, ainsi qu’un prototype (proof-of-concept) qui illustre les tests réalisés et les résultats qui en découlent. Ces éléments peuvent ensuite être inclus dans le projet de l’IIG.
J’ai choisi ce thème, car j’éprouve un grand intérêt en ce qui concerne l’informatique médicale, la configuration de systèmes, la protection des données et la sécurité. De plus, j’ai au préalable beaucoup entendu parler de Docker et je veux en apprendre d’avantage sur cette technologie et son principe d’utilisation.
Ce rapport est basé sur la norme de mise en forme de l’American Psychological Association (APA), 6e édition.
Remerciements
Je tiens à remercier toutes les personnes qui m’ont apporté leur aide et soutien dans le cadre de ma formation et de ce travail et en particulier mon professeur, Dr. Henning Müller, pour le temps qu’il a consacré à me suivre, me conseiller et me corriger, ainsi que M. Ivan Eggel, chercheur et développeur à l’Institut Informatique de Gestion de la HES-SO Valais, pour son précieux suivi technique du projet.
J’adresse aussi un très grand remerciement à mes proches pour leur soutien et la relecture de ce document.
Liste des abréviations
IIG Institut Informatique de Gestion (HES-SO Valais)
OS Operating system (Système d’exploitation)
API Application Programming Interface
REST Representational State Transfer (Type architecture Web)
LDAP Lightweight Directory Access Protocol
AD Active Directory (Services annuaire de Microsoft)
CPU Central Processing Unit (processeur)
YAML YAML Ain’t Markup Language (langage de programmation)
HTTP HyperText Transfer Protocol
LPrD Loi sur la Protection des Données Personnelles (Vaud)
LPD Loi fédérale sur la Protection des Données (Suisse)
P-LPD Projet de révision de la LPD (Suisse)
RGPD Règlement Général pour la Protection des Données (Europe) CNIL Commission Nationale de l’Informatique et des Libertés (France, Europe)
Glossaire
Dockerfile : fichier qui contient les commandes qui seront exécutées lors de la création
d’une image Docker
Deep learning : « Le deep learning ou apprentissage profond est un type d'intelligence artificielle dérivé du machine learning (apprentissage automatique) où la machine est capable d'apprendre par elle-même, contrairement à la programmation où elle se contente d'exécuter à la lettre des règles prédéterminées. »1
Cluster : Groupe de machines (serveurs) indépendantes qui sont connectées à travers un
réseau spécifique afin de fonctionner en tant que ressource « unique » centralisée.2
Product Backlog : Terme provenant de la méthodologie Agile, fichier contenant les
fonctionnalités / composantes d’un projet souhaitées par le client (utilisateur final)
Hacker : Individu dont le but est de mettre à profit des compétences, des principes ou des
logiciels afin de pénétrer dans une infrastructure informatique et d’y dérober, dans notre cas, des informations
1
https://www.futura-sciences.com/tech/definitions/intelligence-artificielle-deep-learning-17262/, consulté le 15.10.2018
1.
Introduction
1.1.
Contexte
Le contexte ci-dessous est basé sur le rapport d’Ivan Eggel et al. (2018).
De nos jours, la quantité de données collectées et les possibilités offertes par la technologie pour leur analyse (par exemple l’intelligence artificielle, les algorithmes, le deep learning, le matériel) augmentent de façon exponentielle, comme dans le secteur médical où l’informatique joue désormais un rôle conséquent.
Or, le partage de ces données peut être réalisé en envoyant des disques durs par voie postale ou via Internet, ce qui nécessite de larges bandes passantes et cela peut prendre un temps considérable de téléchargement. De plus, la protection des données personnelles et sensibles implique que les données médicales (dans notre cas) soient anonymisées ou pseudonymisées. Le consentement du patient doit être recueilli et des conditions de traitement doivent être approuvés par les chercheurs, ce qui implique des procédures administratives et peut mener à un manque de données dans le cadre d’une recherche.
C’est pourquoi un projet réalisé à l’IIG propose une solution qui permet un traitement plus rapide, léger et adaptable de données personnelles et sensibles, stockées en interne. Uniquement l’image Docker créée par un chercheur, contenant le code d’analyse, a accès aux données et celui-ci ne voit que le résultat de l’analyse.
L’architecture souhaitée est représentée par la figure 1 ci-dessous :
Figure 1 Architecture du système à implémenter. (1) Création de l’image Docker avec le code d’analyse et
envoi sur le dépôt Docker public ; (2 et 3) Lancement d’exécution d’analyse à travers une interface Web ; (4) récupération de l’image concernée sur le dépôt par le serveur interne dans le réseau hospitalier ; (5) Exécution du
code à l’intérieur de cette image en accédant aux données concernées ; (6) Affichage du résultat sur l’interface Web pour le chercheur.
Les membres de l’IIG ont déjà mis en place les éléments suivants : l’installation de Docker
Swarm en local, la création d’une interface web pour lancer des conteneurs Docker liés avec
des données internes, le choix d’environnement d’exécution (haute mémoire, haute capacité de processeur et besoins graphiques), le stockage des résultats du code d’analyse de données et l’évaluation de ces derniers.
Le but de ce travail est donc d’apporter des compléments qui peuvent ensuite être repris dans l’implémentation de ce projet de l’IIG.
1.2.
Objectifs / étapes
Ce travail regroupe plusieurs objectifs. Nous réalisons d’abord une analyse de Docker (concepts, versions, standards, outils) et des risques liés à l’exécution de code étranger arbitraire. Ensuite, nous mettons en place un environnement local (Docker, Swarm, service web, interface web cliente). Enfin, nous analysons et testons la définition de quotas (mémoire et processeur), le blocage du trafic réseau qui n’est pas nécessaire au bon fonctionnement du
Swarm et d’un conteneur, et le système de mise en attente (queue) des conteneurs.
En fonction du temps restant, nous fixerons une durée de vie à un conteneur, nous trouverons des alternatives à Docker Hub, nous mettrons en place un registre d’images privé et nous établirons une procédure de « Conditions d’utilisation » des données. Pour plus de détails concernant les objectifs, veuillez vous référer au cahier des charges (Annexe I).
Pour finir, nous établissons un bilan technique et une conclusion générale avec des améliorations potentielles du projet.
2.
Etat de l’art de Docker
Docker est une plateforme Open Source mise en ligne pour la première fois en 2013. Elle utilise des conteneurs pour permettre le déploiement et l’exécution d’applications dans les Cloud d’entreprises ou publics. Nous présentons ci-dessous les principes, les versions, les standards, les outils et méthodes disponibles à travers Docker.
2.1.
Principes de Docker
2.1.1.
Containers
Docker est basé sur un fonctionnement en containers (ou conteneurs en français). Ce terme provient des conteneurs utilisés dans le transport de marchandises. Un conteneur représente
« une instance exécutable d’une Docker® image […] Chaque conteneur est une plateforme
d’applications indépendante et sécurisée à partir de laquelle on peut accéder à des bases de données ainsi qu’à des ressources présentes dans un autre conteneur. » (K. Laghzaoui, 2017).
Figure 2 Cargo containers 3
Un conteneur peut être démarré, arrêté, déplacé ou supprimé via l’outil Docker en ligne de commande ou à travers un API.
2.1.1.1.
Machines virtuelles vs. containers
Dans une machine virtuelle, un OS entier se charge, avec des processus et plusieurs applications qui peuvent n’avoir aucune utilité selon l’utilisation de la machine. Au contraire,
un conteneur Docker utilise uniquement les éléments nécessaires, définis dans l’image qu’il contient. Les ressources peuvent être partagées entre conteneurs.
Figure 3 Comparaison VM et conteneurs4
Un fonctionnement par conteneurs présente des avantages par rapport à une machine virtuelle, comme indiqué dans le tableau ci-dessous (K. Laghzaoui, 2017).
Tableau 1 Caractéristiques VM vs. conteneur
2.1.2.
Docker Images
2.1.2.1.
Fonctionnement
Comme mentionné dans le point 2.1.1, un conteneur Docker est constitué d’une image avec un identifiant unique. Cette image contient l’application, les librairies et tout autre fichier nécessaire au bon fonctionnement, tous accessibles uniquement en lecture.
Elle est composée d’une image de base à laquelle nous apportons des couches supplémentaires (images intermédiaires) en effectuant des modifications souhaitées via des commandes écrites dans un fichier appelé Dockerfile. Pour illustrer ceci, le Dockerfile en figure 3 sert à créer une image pour une application web NodeJS. Lors de la construction de l’image (création du conteneur), chaque commande est exécutée l’une après l’autre (Figure 4) et lorsque l’image est prête, nous pouvons afficher les couches (Figure 5). 5
5 https://medium.com/@jessgreb01/digging-into-docker-layers-c22f948ed612, consulté le
Figure 4 Exemple Dockerfile
Figure 5 Etapes création de conteneur (couches)
Figure 6 Exemple affichage de couches pour une image
Une liste d’instructions qui peuvent être écrites dans un Dockerfile pour configurer une image se situe en annexe.
2.1.3.
Services Docker
Les services Docker permettent d’échelonner les conteneurs et les distribuer sur plusieurs machines dans un Swarm (cf. chapitre Docker Swarm) sur lesquelles le processus dockerd est démarré. Les services peuvent être paramétrés à travers un fichier Docker Compose (cf.
Docker Compose).
2.1.4.
Docker Engine
Docker Engine est l’application de type client-serveur et le cœur de l’architecture Docker. Il gère les images, conteneurs, réseaux et volumes Docker. Il est composé principalement du processus « serveur » (daemon) dockerd, d’une API REST qui sert de lien entre les interfaces que les programmes peuvent utiliser et dockerd, et d’un client Docker en ligne de commande.6
2.1.5.
Registres d’images Docker
Les images Docker peuvent être enregistrées dans un registre (registry en anglais) privé ou public.
2.2.
Versions de Docker
Comme indiqué par J. Chelladhurai et al. (2017), Docker propose deux versions de plateforme : Community Edition, pour les développeurs et les acteurs opératifs, et l’Enterprise
Edition pour les applications critiques et les partenaires qui apportent de la valeur ajoutée à
Docker. Nous présentons les deux versions, mais nous retenons seulement la Community
Edition dans la réalisation pratique de ce travail, étant donné sa gratuité et que les
fonctionnalités qu’elle offre sont suffisantes dans le cadre de ce projet de l’IIG.
2.2.1.
Community Edition
Docker Community Edition (ou Docker CE) peut-être installé sur 7:
• MacOS Desktop (macOS El Capitan 10.11 et supérieur) • Windows 10 Pro Desktop
• Linux CentOS 7 ou supérieur • Debian
o Buster 10
o Stretch 9 / Raspbian Stretch o Jessie 8 (LTS) / Raspbian Jessie o Wheezy 7.7 (LTS) • Fedora 26 à 28 (64-bit) • Ubuntu o Bionic 18.04 LTS o Xenial 16.04 LTS o Trusty 14.04 LTS
Figure 7 Plateformes supportées Docker CE8
7https://docs.docker.com/install/#supported-platforms, consulté le 18 octobre 2018
8 Capture d’écran de l’auteur depuis https://docs.docker.com/install/#supported-platforms,
2.2.2.
Enterprise Edition
Le fonctionnement de base de la version entreprise de Docker (payante) est similaire à Docker CE mais elle offre des avantages, tels que le libre choix d’infrastructures, une meilleure portabilité des applications, une gestion unifiée, des scans de vulnérabilités dans les images, une possibilité d’intégration avec un annuaire LDAP (AD) d’entreprise, un support de Docker le jour même ou le lendemain etc. 9
Cette version peut être installée sur des OS ou en solution Cloud, comme indiqué ci-dessous (Figure 7).
Figure 8 Plateformes supportées Docker EE 10
9 Datasheet sur https://www.docker.com/products/docker-enterprise, consultée le 19.10.2018 10 Capture d’écran de l’auteur depuis
2.3.
Outils et méthodes Docker
2.3.1.
Docker Swarm
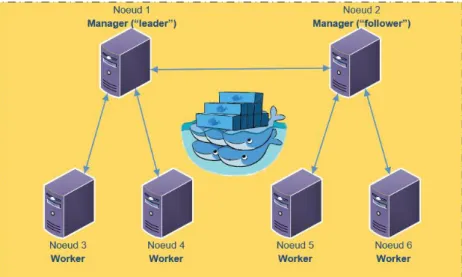
Docker Swarm permet de distribuer les conteneurs entre plusieurs machines hôtes regroupées dans un cluster en fonction de certains facteurs, tels que la taille de mémoire nécessaire, l’espace de disque dur et la vitesse de CPU.
Jusqu’à la version 1.12 de Docker, Swarm fonctionnait en standalone (plus d’information
sur https://docs.docker.com/swarm/). Depuis, il est remplacé par mode Docker Swarm.
Une fois le mode Swarm initialisé, deux rôles peuvent être définis :
• Swarm manager : la machine qui gère le fonctionnement du mode Swarm et tous les hôtes qui y sont connectés, appelés aussi nodes (nœuds en français). Il est recommandé d’utiliser un minimum de cinq managers en production afin de garantir une redondance optimale.
• Swarm worker : une machine hôte qui est connectée au mode Swarm et sur laquelle sont exécutés des conteneurs. Un nœud manager est par défaut également un
worker.
Figure 9 Swarm mode11
2.3.2.
Docker Compose
Une application peut être répartie sur plusieurs conteneurs. Docker Compose gère les services, les volumes et le réseau lors du lancement des conteneurs, à partir d’un fichier contenant des instructions YAML que l’on définit.
Docker Compose peut isoler les environnements les uns des autres via des noms de projet (par exemple éviter des conflits entre deux projets qui utilisent les mêmes noms de services, tels que « web », sur une machine hôte). De plus, des volumes utilisés lors de précédents conteneurs peuvent être récupérés dans le cas d’une nouvelle exécution. Enfin, en cas de non-modification d’un service donné, Docker Compose utilise les conteneurs créés auparavant.12
Vous pouvez voir un exemple de fichier docker-compose.yml ci-dessous (Figure 9). Plus d’informations sur https://docs.docker.com/compose/overview/.
Figure 10 Exemple de fichier Docker Compose
Remarque : l’indentation à l’intérieur du fichier docker-compose.yml est importante. De plus, les commentaires illustrés dans la figure 9 sont uniquement à titre indicatif dans ce rapport. Les commentaires, suivant où ils se situent dans le fichier, peuvent provoquer des erreurs d’exécution.
2.3.3.
Docker Hub
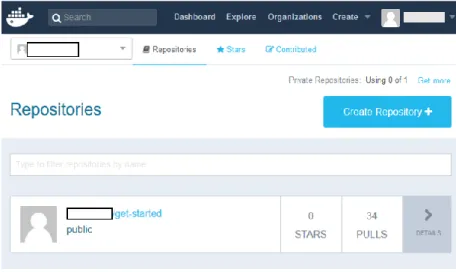
Le registre Docker Hub est un service Cloud qui permet de mettre à disposition des autres utilisateurs une image que nous avons créée ou de télécharger des images officielles ainsi que celles de la communauté Docker.
Lorsque vous vous connectez (https://hub.docker.com), la page d’accueil vous montre les dépôts (repository) que vous avez déjà créés manuellement ou à travers le chargement de votre image sur Docker Hub. Vous pouvez aussi ajouter un nouveau dépôt.
Figure 11 Page accueil Docker Hub13
Le bouton Explore situé dans la barre de navigation au sommet du site Docker Hub permet d’afficher une liste d’images Docker (dépôts) officielles comme par exemple Ubuntu, Redis.
Figure 12 Exemple images officielles Docker Hub14
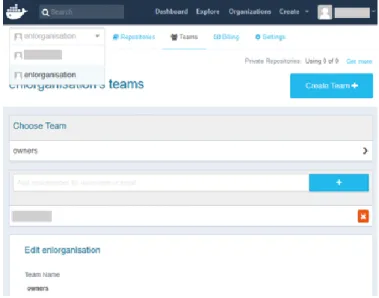
Il est également possible de créer une organisation sur Docker Hub. Une fois l’organisation créée, nous pouvons y ajouter des équipes et des membres et en modifier les paramètres comme illustré à la figure 12.
Figure 13 Affichage organisation sur Docker Hub15
14 Capture écran réalisée par l’auteur depuis https://hub.docker.com/explore/ 15 Capture écran réalisée par l’auteur depuis
2.3.4.
Docker Store
Docker Store sert de plateforme pour télécharger Docker CE et Docker EE, mais aussi des conteneurs officiels, d’autres images grâce à une option reliant le Store au Docker Hub et des modules Docker.
Figure 14 Docker Store16
2.3.5.
Docker Cloud
Docker Cloud est un service payant qui permet de démarrer et gérer des machines Docker situées chez des fournisseurs Cloud comme Amazon Web Service ou DigitalOcean.
2.3.6.
Docker Machine
Docker Machine est un outil qui permet d’installer et gérer Docker Engine sur plusieurs machines hôtes virtuelles localement ou dans un Cloud.
16 Capture écran réalisée par l’auteur depuis
2.3.7.
Docker Bench Security app
Nous pouvons installer le script applicatif Docker Bench Security basé sur des best
practices pour contrôler la configuration de la machine, du Docker daemon et de ses fichiers,
les images et les conteneurs. Vous trouvez plus d’informations sur
https://github.com/docker/docker-bench-security.
2.4.
Standards / best practices
2.4.1.
Taille des images Docker
Ce paragraphe traite de la taille des images, basé sur la documentation Docker en ligne. 17
Pour commencer, les images devraient être aussi légères que possible afin de permettre des opérations plus rapides (réseau, mémoire et autres ressources). Pour cela, il faut d’abord sélectionner une image de base appropriée aux besoins (par exemple, éviter de prendre l’image httpd si un serveur Web Apache n’est pas nécessaire).
Ensuite, Docker 17.05 et les versions supérieures offrent la possibilité d’effectuer des
multi-stage builds. Ceci signifie que nous pouvons écrire plusieurs instructions FROM dans le Dockerfile, ce qui a comme effet d’utiliser une image de base différente et de commencer une
nouvelle étape de build. Ainsi, les artefacts créés dans une première étape peuvent par exemple être récupérés dans une deuxième, en éliminant les éléments inutiles. Cette fonction est utile par exemple pour compiler une application Java avec une image de base java pour après l’exécuter avec une image Ubuntu. Si l’utilisation du multi-stage est impossible, il est recommandé de combiner au maximum les instructions RUN.
17 https://docs.docker.com/develop/dev-best-practices/#how-to-keep-your-images-small,
Figure 15 Combiner les instructions RUN18
En cas d’images avec des éléments similaires, il est préférable de créer notre propre base, dont les couches sont chargées en cache une seule fois, ce qui permet un chargement plus rapide et efficace.
Enfin, les étiquettes (tags) des images doivent être explicites (nom, version, canal de distribution), que ce soit dans le Dockerfile avec les instructions LABEL ou MAINTAINER ou lors du build de l’image (avec l’option -t <nom du tag>).
2.4.2.
Persistance des données
Docker conseille d’utiliser les volumes, bind mounts et secrets pour stocker des données d’applications, à la place des pilotes qui permettent le stockage dans la couche « écriture » du conteneur.19
2.4.3.
Fichier .dockerignore
Nous pouvons écrire un fichier .dockerignore qui contient une liste de répertoires / fichiers que le processus Docker doit ignorer lors de la création d’un conteneur. Cela permet d’éviter l’utilisation de contenus larges ou sensibles.20
18 Capture d’écran de l’auteur depuis
https://docs.docker.com/develop/dev-best-practices/#how-to-keep-your-images-small, réalisée le 20.10.2018
19
https://docs.docker.com/develop/dev-best-practices/#where-and-how-to-persist-application-data, consulté le 20.10.2018
2.4.4.
Sécurité
Comme indiqué par R. Mckendrick et al. (2017), il existe certaines best practices de base en ce qui concerne la sécurité.
Pour commencer, il est fortement recommandé d’intégrer une seule application (ou module) par conteneur et d’installer le strict nécessaire au bon fonctionnement, ceci permettant de réduire les zones de cyber-attaque.
Ensuite, il faut accorder une attention particulière aux droits d’accès (qui, où, quand, comment, pourquoi) sur les images (et conteneurs).
Troisièmement, comme tout logiciel ou matériel, il faut maintenir un suivi des versions et des patchs de sécurité apportés par Docker et effectuer ces mises-à-jour si possible en fonction de l’utilisation en entreprise.
Enfin, de nombreuses documentations, des forums et les plateformes Docker sont mis à disposition et maintenus à jour par la communauté.
3.
Analyse des risques
Ce chapitre est consacré à l’analyse des risques liés à l’exécution d’images Docker qui contiennent du code étranger arbitraire écrit par les chercheurs sur une infrastructure interne avec un accès notamment à des données sensibles. Ces risques sont établis à partir de faits répertoriés ou en fonction de nos analyses et tests effectués dans ce travail. Nous étudions la question sous trois angles : les dommages sur l’infrastructure, les risques de sécurité et les implications légales.
3.1.
Infrastructure
Les risques mentionnés ci-dessus sont liés à Docker et ils peuvent se retrouver dans notre cas d’utilisation.
3.1.1.
Surcharge de ressources
Un premier risque est une détérioration matérielle ou une extinction non-désirable d’une ou plusieurs machines liée à une utilisation excessive de la mémoire vive (RAM), une surchauffe des processeurs (CPU) ou une surcharge au niveau des cartes graphiques.
Pour éviter cela, nous analysons la possibilité de fixer des quotas de RAM et CPU plus loin dans ce document. De plus, Docker Swarm utilise une ou l’autre des stratégies, ainsi que des filtres qui peuvent être définis dans un nouveau service, pour permettre de distribuer et démarrer un conteneur sur le meilleur nœud disponible. Par exemple, nous pouvons ajouter une étiquette « HighRAM == true » à un nœud qui offre une haute capacité mémoire et les tâches dans un service Docker qui contient cette contrainte sont distribuées sur cette machine.
3.1.2.
Utilisation du stockage
L’espace de stockage des disques durs peut être rempli par des conteneurs Docker qui n’ont plus lieu d’être ou qui contiennent des images trop larges par rapport à l’utilisation qui s’y rapporte.
Nous préconisons donc un moyen (automatique ou non) de supprimer à intervalles réguliers ces conteneurs.
Il est possible d’établir une limite de taille avec l’option --storage-opt size=<taille souhaitée>
nous exécutons cette commande sur le serveur, cette option ne peut être appliquée qu’avec
overlay si le système de fichier backup est en xfs et que l’option de montage pquota est utilisée.
Ceci n’est pas le cas pour notre installation de Docker puisque nous avons un système de fichier backup en extfs.
3.1.3.
Panne / disfonctionnement
Troisièmement, nul n’est à l’abri d’une panne ou disfonctionnement. Par exemple, un nœud
manager du Swarm peut être soudainement inaccessible et cela a une conséquence sur la
création de services Docker et la répartition des tâches. Il est donc vivement conseillé d’assurer une redondance entre les machines et les équipements réseau.
3.2.
Sécurité
Docker permet d’exécuter des programmes et codes dans un environnement sandbox (conteneurs). Mais, comme toute application de type Cloud, cela peut présenter des risques sécuritaires qui ne doivent pas être négligés, d’autant plus que des données médicales (donc sensibles) seront analysées et que les images Docker accéderont à un réseau interne. Nous allons décrire les menaces les plus plausibles et proposer pour chacune des actions de prévention.
3.2.1.
Menaces / failles possibles
Les points 3.2.1.1 à 3.2.1.7 de ce chapitre sont basés sur une publication de la société Sysdig21, ainsi que sur le rapport de Robail Y. (2018).
3.2.1.1.
Kernel et hôte Docker
Il est déconseillé d’utiliser des conteneurs Docker sur des machines vulnérables et compromises. Celles-ci doivent donc être sécurisées par l’emploi de mots de passes appropriés, des contrôles d’accès et des communications cryptées. De plus, il est important d’utiliser un système d’exploitation « minimal » approprié aux besoins et celui-ci doit être mis-à-jour régulièrement, tout comme l’instance Docker qui y est installée.
Enfin, le processus Docker utilise le module de sécurité Linux AppArmor qui permet de créer et appliquer des profils sur les applications (et conteneurs Docker). Plus d’informations
sur https://docs.docker.com/engine/security/apparmor/.
3.2.1.2.
Authenticité des images
Les images Docker peuvent être accédées et téléchargées depuis Docker Hub ou d’autres dépôts en ligne. Il est donc nécessaire de vérifier la provenance de ces images (de préférence avec des preuves de sécurité à l’appui) et le développeur de l’image doit être considéré comme fiable.
Il est recommandé d’activer DOCKER_CONTENT_TRUST (export
DOCKER_CONTENT_TRUST=1) pour autoriser uniquement le téléchargement d’images de confiance (« signées »).
Il est possible d’installer un serveur de registre (dépôt) Docker interne à l’entreprise, pour que les images restent « sous notre contrôle », ce qui est un objectif secondaire du cahier des charges, qui ne sera pas implémenté par manque de temps restant.
3.2.1.3.
Container breakout
Ce terme container breakout représente le fait qu’un conteneur a réussi à passer outre les vérifications d’isolation et peut accéder à des informations sur la machine hôte interne ou acquérir des accès privilégiés.
Comme indiqué dans les Best practices Docker, il faut éviter dans la mesure du possible de démarrer des conteneurs avec des accès « super-utilisateur » (root par exemple).
Par ailleurs, comme indiqué dans la documentation Docker, les conteneurs ont la possibilité d’être isolés à travers des user namespaces.22
3.2.1.4.
Surcharge des ressources (déni de service)
Le principe d’une attaque de type « déni de service » (Denial-of-Service en anglais ou DoS) est de surcharger l’utilisation des ressources telles que la mémoire, les processeurs et les
interfaces réseau pour rendre un service inutilisable ou pour provoquer un manque de ces ressources pour d’autres processus (et conteneurs dans notre cas). Tel qu’indiqué précédemment, nous établissons des limites de mémoire et de processeur au niveau du service Docker.
3.2.1.5.
Man-in-the-Middle
Le terme Man-in-the-Middle (« Homme au milieu » en français) fait référence à l’intrusion une personne malintentionnée (hacker) au sein d’un réseau entre deux partis (par exemple entre un service Web et un autre serveur) pour visualiser, modifier, supprimer ou voler des informations transmises lors d’une communication.
Une solution à ce problème est d’isoler les réseaux, tel que nous le faisons plus loin dans ce document, afin d’éviter une intrusion externe dans le conteneur. De plus, nous pouvons utiliser des réseaux privés virtuels (Virtual Private Network ou VPN en anglais), mais nous ne nous attardons pas sur cette option à cause de manque de temps et ce n’est pas un objectif du cahier des charges.
Pour finir, il faut utiliser le protocole Web sécurisé (HTTPs) au lieu de HTTP, d’autant plus que dans notre cas, des résultats de recherche transitent entre un serveur et l’interface Web cliente notamment.
3.2.1.6.
ARP Spoofing
Les réseaux utilisent ce qu’on appelle des tables ARP (Address Resolution Protocol), ce qui permet de lier l’adresse physique unique (MAC) d’une machine à une adresse IP. Cette attaque permet donc à un hacker de lier son adresse MAC à une adresse IP du réseau interne (donc légitime) afin de surveiller, sniffer le trafic réseau et les informations sensibles qui y transitent, voire injecter des virus ou maliciels (malwares en anglais). Docker offre la possibilité d’utiliser ebtables pour filtrer le trafic et bloquer ces usurpations.
3.2.1.7.
Crédenciales et Docker secrets
Tous les mots de passes et les clés de sécurité doivent être protégés de façon adéquate. Par ailleurs, il est recommandé de ne pas utiliser des variables d’environnement pour accéder à des Docker secrets et de régler les conteneurs en lecture seule.
3.2.1.8.
Modification de données
Le code des chercheurs accède à des données sensibles. Il est donc absolument primordial que les données et leurs emplacements ne puissent pas être modifiés ou supprimés.
Lorsque nous ajoutons un point de montage avec bind mount dans un conteneur, il faut que celui-ci soit en lecture seule (readonly).
3.2.1.9.
Accès à des volumes de données non-autorisés
Il est important que le code d’un chercheur accède uniquement aux données correspondantes aux besoins de celui-ci, pour éviter des erreurs d’analyse ou un accès non-autorisé.Le service Web doit donc créer les points de montage vers les volumes corrects dans le conteneur Docker.
3.2.1.10.
Fuite de données vers l’extérieur
Les informations sensibles sont une mine d’or pour les hackers. Il est donc nécessaire, en plus des éléments cités précédemment, d’isoler le réseau d’un conteneur pour éviter une communication de ces données vers l’extérieur, ce qui peut avoir de graves conséquences au niveau des données du patient, pour la réputation de l’institution impactée et par rapport à la loi.
3.2.1.11.
Accès non-autorisé aux résultats d’analyse
Comme expliqué dans ce rapport, les chercheurs du milieu hospitalier demandent l’exécution d’un conteneur avec l’image Docker souhaitée et les résultats sont affichés sur l’interface Web. Il est donc recommandé de mettre en place un mécanisme d’authentification sur cette interface (lien avec la session de l’ordinateur professionnel, ajout d’une page de login) pour restreindre l’accès à ces résultats uniquement aux chercheurs concernés par la recherche.
3.2.2.
Solutions d’analyse / protection
La société Sysdig entre autres a établi une liste de 29 outils de sécurité (gratuits et payants).
23Nous en décrivons trois dans ce chapitre.
3.2.2.1.
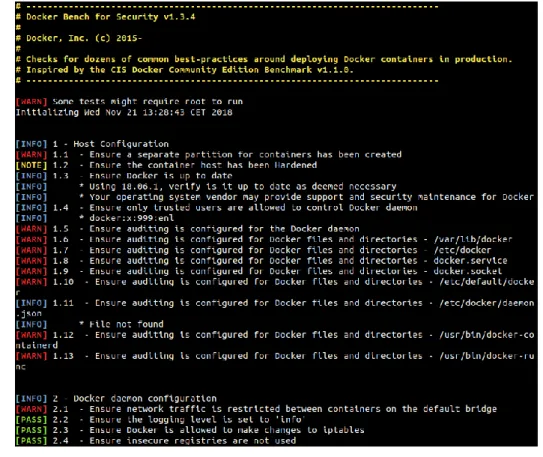
Docker bench security
Docker offre un script intéressant qui analyse la configuration sur une machine hôte en fonction de best practices : Docker-bench-security (Figure 15). Pour le lancement du script et des étapes pour corriger les avertissements, vous pouvez vous rendre sur
https://www.digitalocean.com/community/tutorials/how-to-audit-docker-host-security-with-docker-bench-for-security-on-ubuntu-16-04.
Nous nous basons sur des points de ce script pour mettre en place notre infrastructure Docker locale.
Figure 16 Début du script Docker-bench-security24
23https://sysdig.com/blog/20-docker-security-tools/, consulté le 27.11.2018
3.2.2.2.
Sysdig Secure
La compagnie Sysdig propose son produit Sysdig Secure qui permet de réaliser des audits de sécurité, une gestion des vulnérabilités, des scans d’images Docker, des analyses de performances et de conformité, des opérations forensiques (par exemple : reproduction d’intrusions, fuite de données). Vous trouvez plus d’informations sur
https://sysdig.com/products/secure/.
Vous pouvez leur demander une version Cloud ou logicielle (installation sur un serveur), les prix variant en fonction du contexte d’utilisation. D’après leur site, il faut souscrire pour un minimum d’une année. Nous ne testons donc pas ce logiciel dans ce travail.
3.2.2.3.
Sysdig et Sysdig Inspect
Le logiciel open-source gratuit Sysdig Inspect rend possible l’analyse des captures de performances, du trafic et de la sécurité de conteneurs Docker effectuées au préalable par l’outil Sysdig, qui peut être installé sur une machine hôte ou exécuté dans un conteneur. Plus d’informations sur :
• https://sysdig.com/opensource/inspect/
• https://github.com/draios/sysdig/wiki/How-to-Install-Sysdig-for-Linux
(installation de Sysdig)
• https://github.com/draios/sysdig-inspect/
Ce logiciel ne permet à priori pas d’effectuer un contrôle d’image Docker « en temps réel », avant le lancement de celle-ci. De plus, nous sommes obligés de posséder des fichiers de captures générés par sysdig, donc les analyses sont faites par après. Ceci est utile tout-de-même pour effectuer des analyses forensiques sur les conteneurs qui sont exécutés sur un hôte Docker et résoudre des problèmes éventuels.
3.2.2.4.
Anchore Engine
L’outil Anchore Engine est un outil personnalisable pour analyser des images Docker, leur contenu et leurs potentielles vulnérabilités, à partir de règles (policies) par défaut ou définies par l’utilisateur. Ces images sont contrôlées dans un registre ou avant qu’elles soient déployées dans des conteneurs. Nous ne testons pas en détail cet outil, par manque de temps, mais il peut se révéler pratique pour posséder des images saines. Pour installer l’outil, veuillez vous référer à https://github.com/anchore/anchore-engine. La documentation se trouve sur
3.3.
Implications légales
Le traitement de données personnelles (et sensibles) est, de nos jours, un sujet très important et récurrent et il est soumis aux lois de protection des données.
3.3.1.
Principes de base de protection des données
Comme indiqué par exemple par le Centre National de Recherche Scientifique (CNRS), il existe sept principes de base qui doivent être pris en compte lors d’un traitement des données :
• Finalité
• Proportionnalité
• Pertinence des données • Conservation
• Sécurité / confidentialité • Transparence
• Respect du droit des personnes
3.3.1.1.
Finalité
Les données recueillies doivent être traitées uniquement pour satisfaire les objectifs légitimes déterminés au moment de la collecte. (Engel, 2018)
3.3.1.2.
Proportionnalité et pertinence des données
Les données doivent être « nécessaires pour leur finalité […] adéquates, pertinentes et non
excessives au regard des objectifs poursuivis. » (CNRS, 2018)25
3.3.1.3.
Conservation des données
Il est possible de distinguer deux périodes : la conservation, durant laquelle les données sont accessibles en consultation et l’archivage des données, durant laquelle les données sont stockées ailleurs dans l’entreprise et ne sont en principe plus utilisées. Les durées définies peuvent varier selon les lois. (Engel, 2018)
3.3.1.4.
Sécurité et confidentialité
Les données doivent être sécurisées en fonction de leurs types et des risques, en mettant en place des accès réservés aux utilisateurs et services autorisés (internes ou externes à l’entreprise), une protection physique (sauvegardes, contre les dégâts d’eau et feu et autres), une couverture anti-virus et contre d’autres attaques (mots de passe complexes, cryptage). (Engel, 2018)
3.3.1.5.
Transparence
Une personne dont les données sont récoltées, traitées ou transmises à des tiers doit en être avertie de façon explicite. (Engel, 2018)
3.3.1.6.
Respect du droit des personnes
Les citoyens possèdent des droits relatifs à l’utilisation de leurs données, tels que le droit à l’information, le droit d’accès, le droit de rectification et le droit d’opposition au traitement de leurs données. (Engel, 2018)
3.3.2.
Lois concernées
Dans le cadre de la recherche sur des données médicales en Suisse, les quatre lois suivantes doivent être prises en compte:
• la loi fédérale suisse relative à la recherche sur l’être humain (LRH) • la loi cantonale concernée pour la protection des données
• la loi fédérale suisse pour la protection des données (LPD)
o Cette loi s’applique aux traitements effectués par un organe fédéral ou pour le compte de celui-ci
o « Les traitements de données effectués par des organes publics cantonaux ou communaux, tels les universités (à l’exception des EPF) et les hôpitaux cantonaux et universitaires, régionaux et communaux, ressortent de la compétence des autorités cantonales ou communales de protection des données »(Préposé fédéral à la protection des données et à la transparence,
2018)26. La LPD n’est donc pas concernée, ou du moins pas en priorité.
26
o Cette loi est en cours de révision par le gouvernement suisse (P-LPD) • le règlement européen sur la protection des données (RGPD)
o Le RGPD s’applique dans notre cas si la recherche concerne des patients résidant dans l’Union européenne et le suivi de leurs comportements sur ce territoire. Le contexte d’application pratique de cette loi est donc encore relativement « abstrait ».
3.3.3.
Anonymisation et pseudonymisation
La CNIL résume le principe d’anonymisation et pseudonymisation, repris ci-dessous. 27
Le procédé d’anonymisation de données personnelles vise à supprimer toute donnée permettant d’identifier directement un individu (nom, prénom, date de naissance, adresse, numéro AVS, etc.). En principe, les lois mentionnées plus haut ne s’applique pas aux données qui ont été totalement anonymisées. Cependant, comme indiqué par la CNIL, il est difficile à effectuer, car avec les quantités de données actuelles, une personne pourrait être identifiée par ses habitudes de vie et ses comportements.
Il est donc possible de réaliser une pseudonymisation, c’est-à-dire que les données directement liées à une personne sont séparées du reste et protégées avec une clé d’identification. Il faut toutefois être attentif à la protection optimale de ces données isolées et de leur clé.
3.3.4.
Conditions d’utilisation des données
Le patient a le droit d’être informé de manière claire et précise de l’utilisation de ses données personnelles, avec des indications comme le but du traitement, les acteurs et la durée et les chercheurs doivent être conscients et respecter les normes et conditions mises en place. C’est pourquoi il faut mettre en place un mécanisme de consentement affirmatif avec signature pour le patient et un contrat d’utilisation des données pour les chercheurs. Ceci est un objectif du cahier des charges de ce travail.
23.11.2018
3.3.5.
Fuite ou modification non-autorisée de données
En ce qui concerne la notification auprès des autorités en cas de faille sur les données personnelles, « L’art. 22 al. 1 nLPD prévoit que le responsable du traitement notifie sans délai
au Préposé fédéral à la protection des données et à la transparence suisse (PFPDT) tout traitement non autorisé ou toute perte de données personnelles. L’art. 33 RGPD prévoit une obligation similaire. Dans le cas d’un responsable du traitement établi en Suisse mais soumis au RGPD [18], l’annonce exigée par le RGPD devrait être faite non pas au PFPDT mais à l’autorité de contrôle compétente de chaque Etat membre où des personnes sont concernées par la faille [19]. Ce n’est que si la violation ne présente vraisemblablement pas de risques pour la personnalité et les droits fondamentaux des personnes concernées que le responsable du traitement peut y renoncer.» (Me Sylvain Métille, 2018)28
3.3.6.
Sanctions en cas de non-respect des lois
Le RGPD prévoit des sanctions allant d’un avertissement, une mise en demeure et des amendes pouvant monter jusqu’à 20 millions d’Euros ou 4% du chiffre d’affaire. La LPD, en revanche, ne prévoit pas de sanctions spécifiques, mise à part une amende pouvant aller jusqu’à CHF 10'000.- ou une procédure judiciaire en cas de non-respect par rapport à certaines décisions devant être prises par le préposé fédéral à la protection des données suisse.
28
4.
Choix effectués
4.1.
Méthodologie / planification
Pour la réalisation de ce projet, nous nous sommes basés sur la méthodologie Agile SCRUM. Etant donné que ceci est un travail individuel, nous ne pouvons pas utiliser cette méthodologie telle quelle et nous devons l’adapter.
Pour commencer, un cahier des charges (cf. Annexe I) est établi entre le professeur qui suit ce travail de Bachelor, le répondant technique (M. Ivan Eggel) et l’auteur de ce document, dans lequel les objectifs primaires (must have) et secondaires (nice to have) sont établis.
A partir de ce cahier des charges signé, un fichier Excel servant de Product Backlog est rédigé. Celui-ci contient les fonctionnalités / composantes du projet à réaliser sous forme d’User stories (selon la méthodologie Agile) et permet à l’étudiant de se repérer dans l’avancement du travail.
Chaque semaine, une rencontre a lieu entre le professeur, le répondant technique et l’étudiant afin d’assurer un suivi dans le déroulement du travail.
4.2.
Technique (matériel)
Un serveur virtuel avec comme système d’exploitation Linux Ubuntu 18.04 LTS est fourni par le Service informatique de la HES-SO Valais. Il contient une installation de Docker et le service Web et le site servant d’interface cliente (démonstration). Il permet également la réalisation des tests liés à l’analyse de Docker et aux développements.
Deux machines virtuelles locales Linux (sur l’ordinateur de développement) sont par ailleurs utilisées :
• La première afin d’ajouter un nœud dans le Docker Swarm local mis en place sur le serveur ;
4.3.
Technique (logiciel)
Les choix logiciels sont basés sur les connaissances déjà acquises, ainsi que les développements réalisés au préalable.
En ce qui concerne le service Web permettant la communication entre les interfaces clientes et l’API Docker, le choix se porte sur une application de type Spring Boot avec le protocole REST relativement facile à utiliser. L’application est réalisée dans le logiciel Eclipse (version Oxygen)29, puis déployée sur le serveur.
L’interface Web cliente est réalisée en NodeJS30 à l’aide du programme WebStorm31,
langage relativement récent et évolutif.
29https://www.eclipse.org/oxygen/
30https://nodejs.org/en/
5.
Résultats
5.1.
Architecture générale
Le schéma ci-dessous illustre l’architecture mise en place dans ce projet.
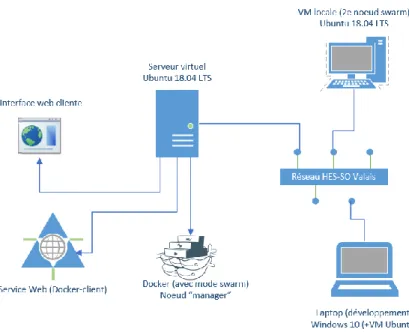
Figure 17 Architecture générale de ce projet32. Un serveur Ubuntu est configuré et connecté au réseau
informatique de la HES-SO Valais. Sur ce serveur, nous installons Docker avec le mode Swarm (il a ainsi le rôle de manager), nous mettons en place le service web qui utilise le client spotify/docker et nous configurons un conteneur Docker qui exécute notre interface web cliente. Comme indiqué dans les choix techniques de matériel,
nous avons sur ce réseau une machine virtuelle qui joue le rôle de nœud worker dans notre Swarm local. Enfin, nous rédigeons le rapport et nous effectuons les développements sur un ordinateur portable également connecté
sur le réseau.
5.2.
Installation Docker et mode Swarm
La réalisation pratique dans ce projet vise avant tout à installer Docker sur le serveur Ubuntu fourni et mettre en place le mode Swarm.
Comme indiqué précédemment, nous installons la version Community de Docker. Pour cela, nous suivons les instructions d’installation à partir d’un dépôt : Install using the repository33.
32 Diagramme réalisé à l’aide de Microsoft Visio par l’auteur de ce document 33 Consulté le 8 octobre 2018
Par la suite, nous initialisons le mode Swarm via la commande sudo docker swarm init. Cela a pour effet de créer ce mode et d’y ajouter le serveur en tant que nœud manager. Nous ajoutons ensuite un nœud worker sur lequel Docker est préalablement installé.
Nous pouvons voir ci-dessous que Docker est bien installé (Figure 17). Le mode Swarm est initialisé et il contient deux nœuds (Figure 18).
Figure 18 Commande pour ajout nœud Swarm
Figure 19 Affichage infos Docker
Figure 20 Affichage des nœuds du Swarm
Comme indiqué sur
https://www.digitalocean.com/community/tutorials/how-to-audit-docker-host-security-with-docker-bench-for-security-on-ubuntu-16-04, nous avons configuré
le daemon Docker pour que la communication entre conteneurs sur un réseau bridge (cf. point 5.6) soit restreinte par défaut, qu’un pilote de logs soit défini et qu’il ne puisse pas y avoir une augmentation des privilèges utilisateurs à l’intérieur d’un conteneur.
De plus, nous installons le trousseau de clés pass qui permet de stocker les mots de passe de façon plus sécurisée lors de la connexion sur Docker Hub (docker login).34 Remarque : si
la génération de clé GPG s’exécute dans le vide, installez rng-tools et exécutez la commande sudo rngd -r /dev/urandom.35
5.3.
Exécution de conteneurs (Service web)
Nous avons vu que des conteneurs peuvent être créés et démarrés en utilisant le client Docker en ligne de commande.
Or, un objectif du cahier des charges est d’utiliser le client Docker Java Spotify/docker-client dans un service Web pour permettre la communication avec l’API de l’instance Docker installée sur le serveur.
Comme nous l’avons dit, nous nous basons sur un modèle de Spring Boot Application, généré depuis l’adresse https://start.spring.io/, que nous développons par la suite via Eclipse.
Figure 21 Génération d'un modèle Spring Boot App36
34https://github.com/docker/docker-credential-helpers/issues/102, consulté le 26.11.2018
35 https://delightlylinux.wordpress.com/2015/07/01/is-gpg-hanging-when-generating-a-key/,
consulté le 26.11.2018
5.3.1.
Création de base d’un service Docker
Dans ce point, nous décrivons pas-à-pas la fonction que nous avons écrite dans le service Web. Par la suite, nous ajouterons des éléments à cette fonction (spécificités du conteneur, quotas RAM et CPU, définition du réseau, conditions de redémarrage) .
1) Nous définissons la fonction, ainsi que les variables qui seront passées en paramètre lors de l’appel de cette fonction. Dans notre cas, nous avons trois variables : le nom du service qui doit être créé (serviceName), l’identifiant de l’image Docker utilisée (imageId) et un type de nœud du Swarm sur lequel nous voulons que le conteneur soit exécuté (nodeLabel).
Figure 22 Création de la fonction serviceCreate (dans service Web)
2) Nous indiquons au client Docker du serveur (sur lequel notre service Web est déployé) qu’il doit télécharger l’image Docker souhaitée à partir du Hub. Nous définissons ensuite une variable containerSpecs qui contient les spécificités du conteneur créé, comme dans notre cas l’ identifiant de cette image, ainsi que les bind mount vers les points de montage souhaités.
Figure 23 Spécificités liées au conteneur (dans service Web)
3) Nous indiquons les spécificités de base liées à la tâche qui sera déployée par le service Docker créé :
a) la contrainte de placement placeConstraints avec placeSpecs (filtre que le Swarm utilisera pour déployer sur un type de nœud souhaité) à partir du paramètre
nodeLabel spécifique
b) les conditions de redémarrage de la tâche (en cas d’échec et jusqu’à cinq tentatives au maximum)
c) la variable taskSpecs reprend les spécificités du conteneur et les éléments de a) et b)
Figure 24 Spécificités liées à la tâche (dans service Web)
4) Nous indiquons les spécificités du service avec : le nom, les spécificités de la tâche définie ci-dessus et le mode de service (ici, répliqué une fois). Puis nous envoyons une requête de lancement du service sur le client Docker. La fonction nous renvoie en retour l’identifiant du nouveau service.
5.4.
Quotas RAM
Pour commencer, si un conteneur nécessite plus de mémoire RAM dans son fonctionnement que le système d’exploitation d’une machine ne le permet, ceci peut conduire à un arrêt non-désirable d’autres applications et de processus (par ex : Docker) commandé par le système pour libérer de l’espace ou dans le pire des cas un arrêt complet. Nous pouvons éviter ça en définissant un taux maximum de mémoire utilisable pour un conteneur avec l’option --memory.
En parallèle à cette option, le conteneur peut être autorisé à utiliser de l’espace disque dur pour l’excès de mémoire (swap), pour autant que le système d’exploitation le permette (ce qui n’est pas le cas par défaut sur notre serveur Linux).
Il est possible également de spécifier une limite inférieure à --memory (--memory-reservation) qui sera prise en compte par Docker si la quantité de mémoire disponible sur une machine est trop faible. Ceci permet au conteneur d’éviter si possible d’utiliser plus de mémoire que celle définie par cette limite.37
Si vous souhaitez plus d’informations, vous pouvez consulter le site
https://docs.docker.com/config/containers/resource_constraints/#memory.
37 https://docs.docker.com/config/containers/resource_constraints/#memory, consulté le
5.4.1.
Définition d’un quota dans le service Web
Dans notre service Web JAVA, nous définissons un quota de RAM comme illustré dans la figure 24 (par exemple 5*106, soit 4.7 MB en réalité après conversion en binaire).
Figure 26 Spécification de limite mémoire (dans service Web)
5.4.2.
Test d’exécution avec limite RAM
5.4.2.1.
Fonctionnement normal
Une fois le quota défini dans le service Web, nous pouvons effectuer des tests pour comprendre le comportement des conteneurs déployés avec cette limite.
Nous constatons qu’en créant un service avec une image qui contient une interface Web simple et qui utilise normalement environ 16 MB fonctionne (malgré quelques légères latences) et, avec cette limite, elle plafonne à 4.65 MB (Figures 27 et 28).
Figure 28 Exécution image Docker avec limite RAM
5.4.2.2.
Stress test
Les stress tests permettent de tester les performances d’un système ou d’un logiciel en augmentant l’utilisation de la mémoire, des processeurs et autres ressources.
Dans notre cas, nous utilisons l’outil stress sur un conteneur avec une image Docker Ubuntu qui contient un serveur Web Apache et dans laquelle nous avons installé cet outil. Le quota de RAM est fixé à 256 MB. La figure 29 illustre la tâche démarrée par notre service créé (stressram), ainsi que l’utilisation actualisée de la mémoire par le conteneur et ses processus qui sont en cours d’exécution.
Figure 29 Service Docker avec sa tâche, utilisation RAM et ses processus
Nous démarrons à présent un processus stress sur ce conteneur avec la commande docker exec <id du conteneur> stress -m 2G (pour forcer 2 GB d’utilisation de RAM). Nous constatons dans la figure 30 que la tâche « qcrlqw8jk48j » et son conteneur « 9005814de27f » illustrés ci-dessus sont arrêtés (erreur) et remplacés par de nouveaux.
Figure 30 Résultat stress test limite RAM
5.5.
Quotas CPU
Pour ce qui est du quota CPU, nous pouvons utiliser le CFS scheduler (Completely Fair
Scheduler) ou Linux real-time scheduler, qui permettent au noyau (kernel) Linux d’une
machine de prioriser le traitement de tâches pour chaque processeur.
5.5.1.
CFS scheduler
Le CFS scheduler permet un partage équitable des ressources de processeurs et de la période mise à disposition des tâches. Par exemple, si nous avons quatre processus dans une queue, chacun d’eux auraient droit à 25% de temps du processeur concerné.38
Le principe de base du côté de l’utilisateur est simple. Si nous utilisons docker run, nous définissons le nombre de processeurs qu’un conteneur peut utiliser avec l’option –cpus=XX (recommandé à partir de Docker 1.13). Docker calcule alors la période et le quota.39
38https://www.youtube.com/watch?v=MkJfuI5_hjc, consulté le 15.11.2018
https://docs.docker.com/config/containers/resource_constraints/#configure-the-default-cfs-5.5.2.
Real-time
Les processus real-time nécessitent un temps de traitement court avec un minimum de latence (par exemple : des applications de traitement vidéo ou audio). Ils ont ainsi la priorité dans une queue d’un processeur.
Ubuntu 18.04 (Bionic) ne prend pas en charge le real-time par défaut (comme indiqué par Docker lorsque nous essayons d’utiliser cette fonctionnalité en exécutant docker run).40 Il est
donc nécessaire d’installer et compiler un noyau (kernel) real-time pour effectuer une comparaison avec le CFS.
5.5.3.
Définition d’un quota CPU (service Web)
En ce qui concerne notre service Web, une limite en nanoCPU (10-9 nombre de
processeurs) est définie au niveau de la tâche du service Docker créé (Figure 30). Le quota est calculé par Docker de la manière suivante : Quota = nanoCPUs * périodeCPU / 10-9. Dans
notre situation, nous définissons 1.5 * 109 nanoCPU, donc 1.5 processeurs.
Figure 31 Spécification de limite CPU (dans service Web)
scheduler, consulté le 11.11.2018
5.5.4.
Tests d’exécution (CFS scheduler)
5.5.4.1.
Fonctionnement normal
En créant un service Docker depuis le Web, nous constatons, en inspectant le conteneur, que le quota de CPU a été calculé et attribué (Figure 31).
Figure 32 Propriétés conteneur: CPUQuota et CPUPeriod
5.5.4.2.
Stress test
Nous exécutons ensuite sur ce container défini un test de performance en utilisant le même outil stress que pour les tests de quotas RAM avec la commande docker exec <id du conteneur> stress -c 4 (pour utiliser 4 cpus).
La figure 32 illustre la tâche démarrée par notre service créé (stresscpu), ainsi que l’utilisation actualisée de la mémoire par le conteneur et ses processus qui sont en cours d’exécution. Comme nous pouvons le voir, l’utilisation de CPU augmente jusqu’à environ 100% d’utilisation.
Figure 33 Résultat stress test limite CPU
5.5.5.
Conclusion
Etant donné le manque de temps pour la compilation d’un noyau real-time, nous choisissons de conserver et tester le CFS, qui convient pour effectuer une analyse de données.