Learned features versus engineered features for semantic video indexing
Texte intégral
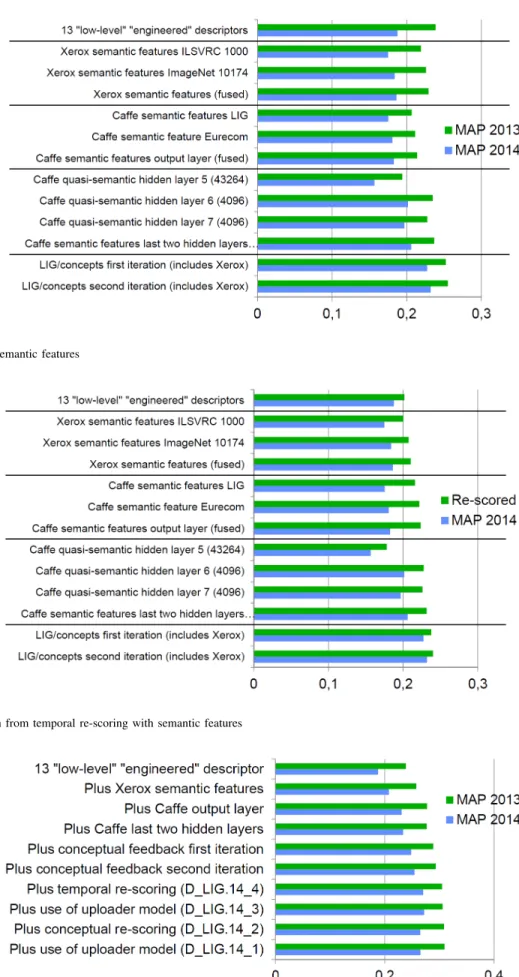
Figure

Documents relatifs
We have demonstrated how the UML and OCL modeling tool USE has been extended and improved recently by new visualization features for automatic object model layout and for
To capture these features, we collected our own dataset based on Spanish Tweets that is 16 times larger than the competition data set and allowed us to pre-train a language model.
Table 2: Precision, Recall and F1-score (in percent) average score on Bot vs Human Classification Task on the validation set using various classification methods..
Although fundamental low-level features such as color, edge, texture, motion and stereo have reported reasonable success, recent visual applica- tions using mobile devices and
They represent respectively the moments estimated directly on the images at resolution of 3.175m (the ground truth) and the extrapolation results obtained by using the scheme
T he current study exam ined the effects of the m anner (dichotic vs. m onaural) and the ear (left vs. right) of stim ulation on the m ism atch negativity (M M N ) for
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
The proposed approach obtains better results in 36 out of 54 queries (see Fig. The reason why our approach does not obtain good results in 18 queries is: the proposed approach uses
